【深度学习:数据增强】计算机视觉中数据增强的完整指南

【深度学习:数据增强】计算机视觉中数据增强的完整指南
为什么要做数据增强?
可能面临的一个常见挑战是模型的过拟合。这种情况发生在模型记住了训练样本的特征,但却无法将其预测能力应用到新的、未见过的图像上。过拟合在计算机视觉中尤为重要,在计算机视觉中,我们处理高维图像输入和大型、过度参数化的深度网络。有许多现代建模技术可以解决这个问题,包括基于丢弃的方法、标签平滑或架构,这些方法可以减少所需的参数数量,同时仍能保持拟合复杂数据的能力。但是,对抗过拟合的最有效方法之一是数据本身。
深度学习模型通常需要大量数据,而提高模型性能的一种有效方法是提供更多数据,这是深度学习的核心要素。这可以通过两种方式完成:
- 增加原始数据量。这是通过增加数据集中的图像数量来实现的,从而扩充了图像的基本分布,并有助于优化模型的决策边界,对抗过拟合。您拥有的样本越多(比如来自分类问题的特定类别),您就能更准确地描述该类别的特征。
- 增加数据集的多样性。值得一提的是,无法泛化到新数据也可能是由数据集/分布偏移引起的。想象一下,使用一组训练后的狗在公园里的图像对狗品种进行分类,但在生产中的其他地方看到狗。扩大训练数据集以包含这些类型的图像可能会对模型的泛化能力产生巨大影响。(但大多数时候,图像增强将无法解决这个问题)。
然而,收集数据通常既昂贵又耗时。例如,在医疗保健应用中,收集更多数据通常需要接触患有特定疾病的患者,熟练的医疗专业人员花费大量时间和精力来收集和注释数据,并且通常使用昂贵的成像和诊断设备。在许多情况下,“获取更多数据”的解决方案将非常不切实际。此外,除了在迁移学习中使用之外,公共数据集通常并不适用于定制的计算机视觉问题。如果有某种方法可以在不返回数据收集阶段的情况下增加数据集的大小,那不是很好吗?这就是数据增强。
等等,什么是数据增强?
数据增强是通过各种转换从现有训练样本中生成新的训练样本。它是一种非常有效的正则化工具,几乎所有 CV 问题和模型的专家都在使用它。数据增强可以以一种非常简单有效的方式将几乎任何图像训练集的大小增加 10 倍、100 倍甚至无限大。从数学上讲:
更多的数据=更好的模型。数据增强 = 更多数据。因此,数据增强 = 更好的机器学习模型。
数据增强技术

上图所示的方法列表绝不是详尽无遗的。还有无数其他方法可以操作图像和创建增强数据。你只受限于自己的创造力!
也不要觉得只限于孤立地使用每种技术。您可以(并且应该)将它们链接在一起,如下所示:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
{kind=link}

数据增强的注意事项和潜在陷阱
- 毋庸置疑,在将数据集拆分为训练、验证和测试子集后,应该进行任何数据增强。否则,您将在模型中造成重大数据泄漏,并且您的测试结果将毫无用处。
- 如果您正在执行基于本地化的任务(如对象检测或分割),则在应用几何变换(如反射(翻转)、旋转、平移和裁剪)时,您的标签将发生变化。因此,您还需要将相同的转换应用于标签注释。
- 裁剪图像时,会更改模型输入的大小和形状。对于卷积神经网络模型,您需要所有输入(包括测试集)具有相同的维度。处理此问题的常用方法是将裁剪转换也应用于测试集和验证集。调整图像大小是另一种选择。
- 其中一些转换(如平移、旋转或缩放)可能会导致“空白区域”,即转换后的图像未完全覆盖输入模型的网格空间。在这些情况下,您可以使用恒定的黑/白/灰像素、随机噪声或扩展原始图像内容的插值来填充多余的像素。
- 注意不要裁剪或平移太多,以免从图像中完全删除相关对象。当您知道对象检测任务中的边界框时,这很容易检测到,但如果完全裁剪掉与标签对应的对象,则可能会成为图像分类的问题。
- 数据增强通常只在训练集上执行。虽然它也可以用作在非常小的验证甚至测试集中减少方差的策略,但在对测试集进行任何更改时应始终非常小心。您希望测试数据是对推理时间分布中看不见的示例的性能的无偏估计,而增强数据集可能与该分布不同。
- 不建议同时使用过多的增强技术。你可能会想通过组合所有列出的转换来一次把所有东西都扔进去,厨房水槽,但这会很快使生成的图像变得非常不真实,人类无法识别,并且还会导致上述点中概述的潜在问题。使用所有这些转换并没有错,只是不要一次组合所有这些转换。
话虽如此,转换后的图像并不需要完美才能有用。数据量往往会超过数据质量。示例越多,异常值/错误图像对模型的不利影响就越小,数据集的多样性就越大。
尽管数据增强几乎总是对模型性能有积极影响,但它并非解决所有与数据集大小相关问题的灵丹妙药。你不能指望使用50张图像的微小数据集,使用上述技术将其放大到50,000张,并获得50,000张数据集的所有好处。数据增强可以帮助使模型对旋转、平移、照明和相机伪影等内容更加鲁棒,但不适用于其他变化,例如不同的背景、透视、对象外观的变化、场景中的相对位置等。
什么时候应该做数据增强?
您可能想知道“我应该在什么时候使用数据增强?什么时候有好处?答案是:总是!数据增强通常有助于规范化和改进您的模型,如果您以合理的方式应用它,则不太可能有任何缺点。唯一可以跳过它的情况是,如果你的数据集非常庞大和多样化,以至于增强不会为其增加任何有意义的多样性。但是我们大多数人都没有奢侈地使用这样的童话数据集🙂。
类不平衡的数据增强
扩增法也可用于处理类不平衡问题。与使用基于抽样或加权的方法相比,你可以简单地增加较小的类,使所有类的大小相同。
那么我应该选择哪些转换呢?
没有一个确切的答案,但你应该从思考自己的问题开始。转换生成的图像是否完全超出了现实世界的支持范围?即使公园里一棵树的倒立图像不是你在现实生活中会看到的,你也可能会看到一棵倒下的树的类似方向。不过,有些变换可能需要重新考虑,例如:
- 垂直反射(倒置)十字路口的停车标志,用于自动驾驶中的物体识别。
- 倒置的身体部位或模糊/彩色图像,用于放射学图像,其方向、光照和清晰度始终保持 一致。
- 道路和社区卫星图像上的网格失真。(尽管这可能是应用轮换的最佳位置之一)。
- 数字分类 (MNIST) 的 180 度旋转。这种转换将使您的 6 看起来像 9,反之亦然,同时保留原始标签。
你的转换不一定是完全现实的,但你绝对应该使用在实践中可能发生的任何转换。
除了对任务和领域的了解,对数据集的了解也很重要。更好地了解数据集中图像的分布情况,可以让您更好地选择哪种增强技术能为您带来合理的结果,甚至可能帮助您填补数据集中的空白。Encord Active 是帮助您探索数据集、可视化图像属性分布和检查图像数据质量的一个很好的工具。
然而,我们是工程师和数据科学家。我们不只是根据猜想做出决定,我们还要尝试和进行实验。我们拥有久经考验的模型验证和超参数调整技术。我们可以简单地尝试不同的技术,并选择在验证集上性能最大化的组合。
如果您需要一个良好的起点:水平反射(水平翻转)、裁剪、模糊、噪点和图像擦除方法(如剪切或随机擦除)是一个良好的基础。然后,你可以尝试将它们组合在一起,并添加亮度和色彩变化。
视频数据增强
视频数据的增强技术与图像数据非常相似,但有一些区别。通常,所选的变换将以相同的方式应用于视频中的每一帧(噪点除外)。修剪视频以创建较短的片段也是一种流行的技术(时间裁剪)。
如何实现数据增强
实施的具体细节取决于硬件、所选的深度学习库、所选的转换等。但通常有两种策略可以实现数据增强:离线和在线。
离线增强: 离线数据增强是指计算一个新的数据集,其中包括所有原始图像和转换后的图像,并将其保存到磁盘中。然后像往常一样,使用增强数据集而不是原始数据集来训练模型。这可能会大大增加所需的磁盘存储空间,因此我们不建议您这样做,除非您有特殊原因(如验证增强图像的质量或控制训练过程中显示的准确图像)。
在线扩增: 这是最常见的数据增强方法。在在线增强中,每次加载图像时都会对图像进行转换。在这种情况下,模型在每个时间点都会看到不同的图像变换,变换结果不会保存到磁盘中。通常情况下,变换会在每个纪元随机应用于图像。例如,您将在每个时区随机决定是否翻转图像、执行随机裁剪、采样模糊/锐化量等。

专业人士使用哪些技术?
您可能仍然想知道:"训练最先进模型的人是如何使用图像增强技术的?让我们一起来看看:
| 论文 | 数据增强技术 |
|---|---|
| LeNet-5 | Translate, Scale, Squeeze, Shear |
| AlexNet | Translate, Flip, Intensity Changing |
| ResNet | Crop, Flip |
| MobileNet | Flip, Crop, Translate |
| NasNet | Crop, Elastic distortion |
| ResNeSt | AutoAugment, Mixup, Crop |
| DeiT | AutoAugment, RandAugment, Random erasing, Mixup, CutMix |
| Swin Transformer | RandAugment, Mixup, CutMix, Random erasing |
| U-Net | Translate, Rotate, Gray value variation, Elastic deformation |
| Faster R-CNN | Flip |
| YOLO | Scale, Translate, Color space |
| SSD | Crop, Resize, Flip, Color Space, Distortion |
| YOLOv4 | Mosaic, Distortion, Scale, Color space, Crop, Flip, Rotate, Random erase, Cutout, Hide and Seek, GridMask, Mixup, CutMix, StyleGAN |
Erasing/Cutout: 等等,这些剪切-混合-然后-修改的东西是什么?其中一些像剪切、随机擦除和网格掩码都是图像擦除方法。执行擦除时,您可以在图像中剪切出正方形、不同形状的矩形,甚至多个单独的剪切/蒙版。还有多种方法可以使该过程随机化。擦除是一种流行的策略,例如,在图像分类的背景下,可以迫使模型学习识别每个单独部分的对象,而不仅仅是通过擦除最独特的部分来识别最独特的部分(例如学习识别狗)通过爪子和尾巴,而不仅仅是脸)。擦除可以被认为是一种“输入空间中的丢失”。
Mixing: 数据增强中的另一种流行技术是混合。混合涉及组合单独的示例(通常属于不同类别)以创建新的训练图像。混合比我们见过的其他方法不太直观,因为生成的图像看起来不真实。让我们看一下几种常用的技术:
Mixup: Mixup 通过两个图像的线性插值(加权平均)来组合两个图像。然后将相同的插值应用于类标签。

混合图像的示例。具有标签(狗、猫)的二值图像分类问题中相应的图像标签将为(0.52,0.48)。
什么?这看起来像是模糊的废话!这些标签值是什么?为什么这有效?
从本质上讲,这里的目标是鼓励我们的模型学习不同类别之间更平滑的线性过渡,而不是振荡或行为不稳定。这有助于在推理时稳定模型在未见过的示例上的行为。
CutMix: CutMix 是 Cutout 和 Mixup 方法的组合。如前所述,混合图像看起来非常不自然,并且在执行本地化时可能会让模型感到困惑。 CutMix 不是在两个图像之间进行插值,而是简单地裁剪一个图像并将其粘贴到第二个图像上。与剪切相比,这也有一个好处,即剪切区域不仅会被丢弃并用垃圾替换,而且会被替换为实际信息。标签权重类似 - 对于分类问题,标签对应于增强图像中存在的相应类图像的像素百分比。为了定位,我们在合成图像的各自部分中保留与原始图像相同的边界框或分割。

AugMix: Augmix 与上面的例子有点不同,但这里也值得一提。 AugMix 不会将不同的训练图像混合在一起 - 相反,它混合同一图像的不同变换。通过探索图像之间的输入空间,这保留了混合的一些好处,并减少了对同一图像应用多次变换带来的退化影响。混合计算如下:
- 创建多个(默认为 3 个)增强图像。每个增强图像都是使用 1-3 种不同的变换创建的。
- 3个增强图像通过加权平均混合
- 通过加权平均将所得图像与原始图像混合
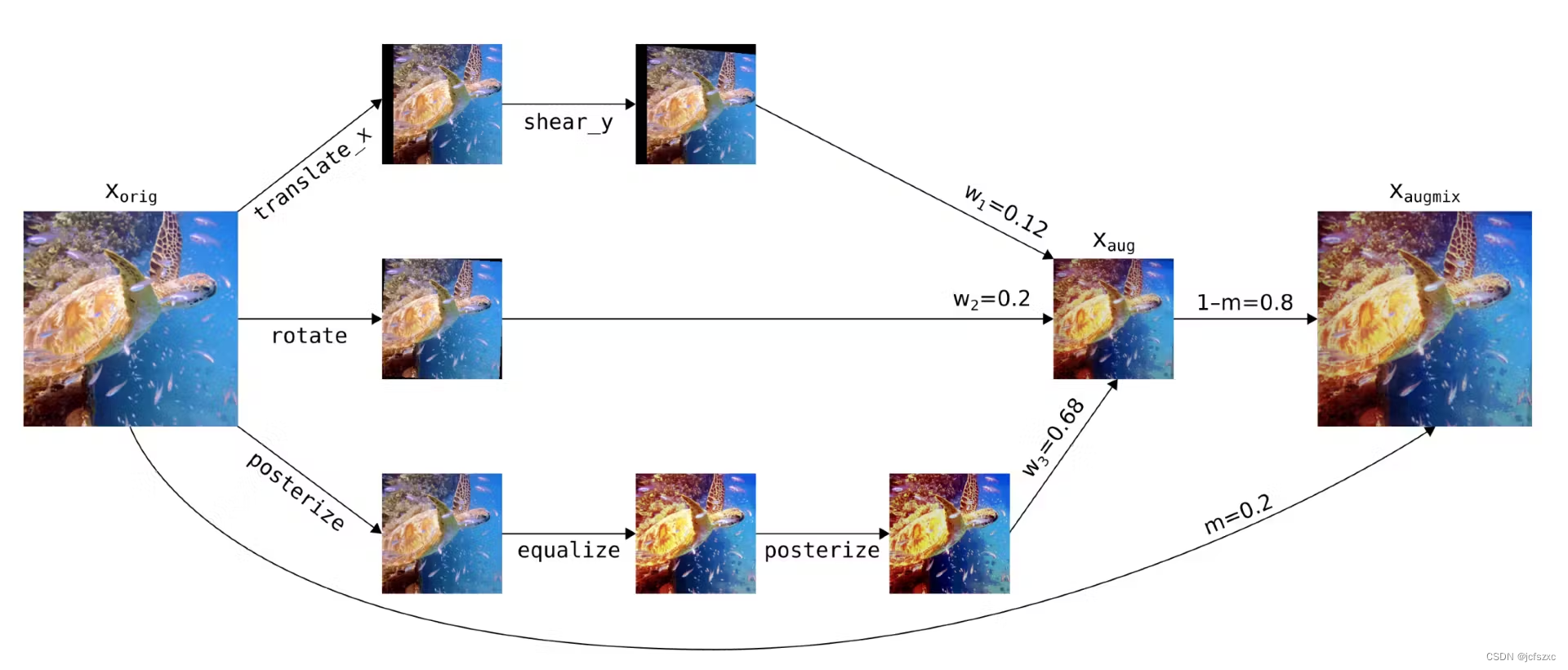
AugMix增强过程。整个方法还包括其他部分,例如特定的损失函数。
高级技术,即“我不能使用 GAN 生成完全独特的数据吗”?
图像增强仍然是一个活跃的研究领域,还有一些更先进的方法需要注意。以下技术更为复杂(尤其是最后两种),并不总是最实用或最有效的实施策略。为了完整起见,我们列出了这些内容。
特征空间增强: 特征空间增强包括在训练期间对隐藏层表示而不是原始图像执行增强。这个想法是,与通过输入空间相比,您更有可能遇到遍历特征空间的随机图像。这可以通过向隐藏的表示添加噪声、对它们执行混合或其他方法来完成。
GAN: 另一种方法是使用生成模型(通常是 GAN)生成新的合成图像,该模型学习底层数据生成分布。这可以无条件地完成,也可以从现有的训练示例开始,例如,使用样式转移。对于视频数据,可以使用仿真技术来合成帧序列。
自动增强: 为给定问题找到增强技术的最佳组合可能非常耗时,并且需要领域和特定数据集方面的专业知识。如果计算机能为我们完成所有这些工作,那不是很好吗?自动增强算法在可能的增强空间中搜索,以找到性能最佳的增强。像 AutoAugment 这样的强化学习方法可以找到高性能的增强策略。还存在基于对抗性学习的方法,这些方法会产生难以分类的转换。
结论
现在您知道什么是数据增强,以及它如何通过填写数据集来帮助解决过拟合问题。您知道应该将数据增强用于所有计算机视觉任务。你对最重要的数据增强转换和技术有一个很好的概述,你知道要注意什么,并且你已经准备好将数据增强添加到你自己的预处理和训练管道中。祝你好运!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!