语音神经科学—03.A high-performance speech neuroprosthesis
A high-performance speech neuroprosthesis(高性能的语音神经假肢)
专业术语
neuroprosthesis 神经假肢
brain–computer interfaces 脑机接口
neural activity 神经活动
cortex 大脑皮层
intracortical microelectrode arrays 皮质内微电极阵
motor cortex 运动皮质
orofacial movement 口腔面部运动
microelectrode array 微电极阵列
ventral premotor cortex 腹侧前运动皮质
Broca’s area 布罗卡区、
phoneme 音素
anterior 前方
posterior 后方
dorsal 背部
ventral 腹部
spiking activity 尖峰活动
amyotrophic lateral sclerosis (ALS) 肌萎缩侧索硬化症
resting state network 静息状态网络
speech articulation 语音表达
articulatory representation 发音表征
概述
本文提出了一个高效的语音到文本的脑机接口,针对无法清晰说话的病人,记录来自皮质内微阵电极的峰值活动并转录成想要表达的文本。并且作者从实验中强调了对语音BCI有利的两个方面:混合编码到语音发音器官的空间分布,(1)使得
仅从大脑皮层的一个小区域就能进行准确解码,(2)并在瘫痪多年后仍保持对音位的详细发音表征。
Q:
混合编码到语音发音器官的空间分布表示什么?
A: 指在大脑皮层的特定区域,神经元对语音发音器官(如舌头、嘴唇等)的活动表现出混合编码。这意味着一个小区域的神经元可以对多个语音发音器官的活动产生响应。这种混合编码的特性使得从仅一个小区域的神经活动中就能准确解码语音信息。
Q:
详细的音位发音表征在瘫痪多年后仍持续存在表示什么?
A: 指即使在长时间的瘫痪状态下,大脑皮层仍能保持对语音音位(语音中的最小单位)的详细发音表征。这意味着即使肌肉无法正常运动,大脑皮层中与发音相关的神经编码仍然存在,并且可以被利用来解码和还原语音信息。
背景
现在的语音脑机接口有可能通过尝试使用的语音引起的神经活动解码为文本或声音,来恢复与瘫痪患者的快速交流。但是没有达到对来自大量词汇量的无约束句子的交流的的高准确性。
因此作者想要提出一个更加高效的语音BCI,不仅达高准确性,还能快速解码,速度接近自然对话。
单神经元分辨率
运动皮质(motor cortex)是大脑中负责控制肌肉运动的区域之一,其中包括了与口腔面部运动(orofacial movement)和语音产生相关的神经元。然而,尽管我们对运动皮质在整体上的功能和组织有一定的了解,但目前对于口腔面部运动和语音产生在单个神经元(single-neuron)级别上的组织和编码方式尚不清楚。
确定区域
为了研究这个问题,作者记录了四个微电极阵列(microelectrode array)的神经活动。其中有两个在大脑6v区域(ventral premotor cortex腹侧前运动皮质),还有两个在大脑44区域(Broca’s area布罗卡区)。这两个区域在大脑中的位置如下图所示。
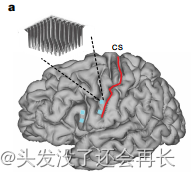
在BrainGate2试验的初步临床试验中,研究参与者尝试根据计算机显示的提示进行口腔面部的个别运动、发出单个音素或单词的口语表达。
从每个微电极阵列中记录的尖峰活动如下图所示:
Q:
尖峰活动代表什么?有什么用?
A: “spiking activity” 是指神经元产生的·电活动中的尖峰信号·。当神经元兴奋时,会发出电脉冲或称为尖峰。这些尖峰信号通过神经元之间的连接进行信息传递和通信。
尖峰活动是神经元活动的基本单位,它反映了神经元的兴奋状态和信息处理过程。神经元通过产生和调节尖峰活动来编码和传递信息。尖峰活动的频率、时序和模式可以提供关于神经元网络功能和信息处理的重要信息。
为每个点击绘制了在10s的时间窗内检测到的尖峰波形的示例(数据记录与植入后第119天)。每个8x8网格对应一个64个电极阵列,所以每个矩形对应一个单个电极。每个蓝色轨迹显示了峰值波形(持续时间为2.1微秒),神经活动经过一个非因果、4阶Butterworth滤波器进行带通滤波(250-5000 Hz)。尖峰事件使用 -4.5均方根(RMS)阈值进行检测,从而排除了几乎所有的背景活动。可以看到所有的点击记录到了大的尖峰波形。

tips:
在神经解中,“anterior”、“dorsal”、"posterior"和"ventral"是用来描述大脑或其他神经结构的方向和位置的术语。(可以将大脑看做一个趴着的老鼠,腹部就是老鼠的肚子,背部就是老鼠的后背)
"Anterior"(前方)指的是相对于特定结构的前面或前部。在大脑中,前方通常指向面部方向,即大脑的前部或前额叶区域。"Dorsal"(背部)指的是相对于特定结构的背面或上部。在大脑中,背部通常指向头顶方向,即大脑的顶部或顶叶区域。"Posterior"(后方)指的是相对于特定结构的后面或后部。在大脑中,后方通常指向后脑或后颅窝方向,即大脑的后部或枕叶区域。"Ventral"(腹部)指的是相对于特定结构的下面或下部。在大脑中,腹部通常指向面部下方或颅底方向,即大脑的底部或颞叶区域。
下图a具体展示了电极植入大脑皮层中的样子
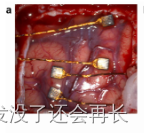
此外,参与者(T12)患有球部起病型肌萎缩侧索硬化症(ALS),保留了一些有限的口腔面部运动和发声能力,但无法产生可理解的言语。
对实验中采集的脑电信号分析,作者发现,6v区域对所有类别的运动都有很强的调节能力。下图展示了一个电极响应的例子。描绘了电极在6v区域对不同条件下的平均阈值穿越率(threshlod crossing rate)的响应。这些条件可能包括口腔面部运动、不同的音素和单词。每一行代表一个条件,描述了该条件下的阈值穿越率的平均值。通过阴影区域显示了95%的置信区间,用于表示结果的可靠性。
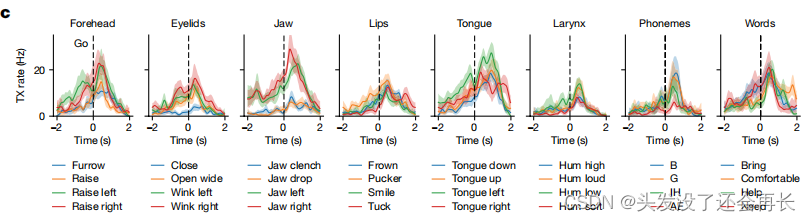
什么是
Threshold crossing rate (TX rate)?
Threshold crossing rate (TX rate)是指信号在某一设定阈值上方或下方的穿越次数,用于描述信号的变化速率。它是一种常用的信号特征,可以用于分析和描述信号的动态特性。
此外,作者发现在6v区域的神经活动在不同运动之间具有高度可分性:使用简单的朴素贝叶斯分类器对每个试验的1秒神经群体活动进行应用,我们能够以92%的准确率对33个口腔面部运动进行解码,以62%的准确率对39个音素进行解码,以94%的准确率对50个单词进行解码。(这个实验我的理解是这样的:训练数据来源于我们实验中的神经活动,对神经活动进行提取,得到口腔运动的、音素的、单词相关的神经活动特征,然后进行标注,去训练贝叶斯分类器。然后测试集是真实的来自这些类别的神经活动,使用训练好的分类器进行分类,准确率高说明6v区域的神经活动确实包含了这些类别的神经活动特征,且是高度可分的。)
下图是两个区域在三个类别特征上面的混淆矩阵,可以看出贝叶斯分类器的分类准确性。(a、b对应movements,c、d对应音素,e、f对应words。混淆矩阵是一个二维表格,其行和列分别代表真实类别和预测类别。矩阵中的每个条目 (i,j)根据在所有以动作i为提示的试验中解码为动作j的比例进行着色 。)
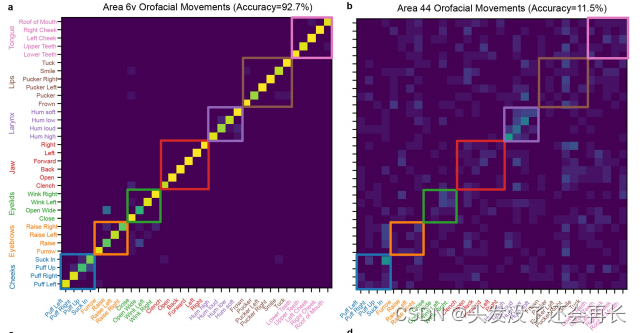
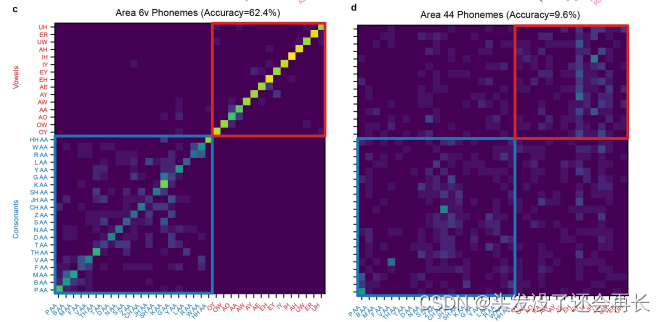
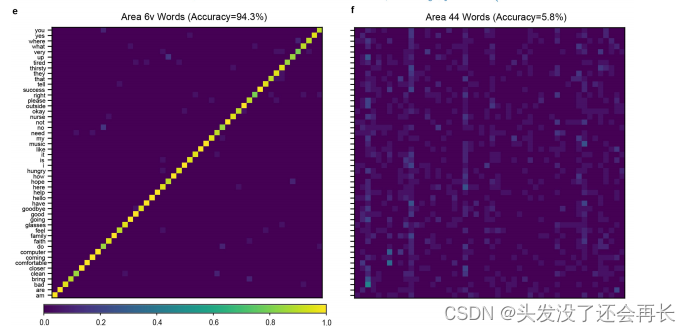
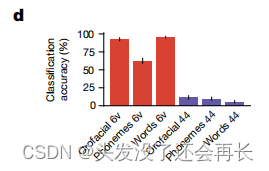
分类的准确率的统计数据如下图所示,所以不难看出,6v区域包含了丰富的口腔运动、音素、单词的相关信息。但是44区域几乎没有这些相关信息。所以确定了与语音相关的神经活动在6v区域。
确定运动信息的分布
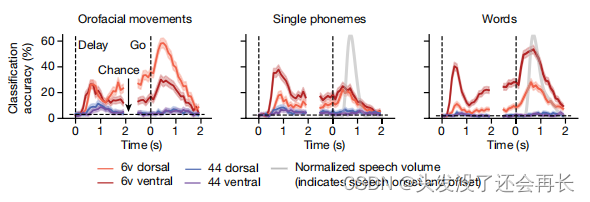
作者研究了关于每个运动类别的信息是如何在区域6v中分布的。针对四个电极的分类准确性如下图所示,可以发现,从腹侧(ventral)神经阵列中,尤其是在指示的延迟期间,语音可以更准确地解码,而背侧(dorsal)神经阵列则包含更多关于口腔面部运动的信息。
这个结果与人类连接组计划(Human Connectome Project)和T12的静息态功能磁共振成像(fMRI)数据一致,这些数据将6v的腹侧区域定位为与语言相关的网络的一部分。如下图所示,在人类连接组计划的数据中,发现了一个与语言相关的静息态网络(Resting state network),并将其与T12的大脑进行对齐。这个静息态网络在T12的个体扫描中显示出相同的模式。具体来说,6v区域的腹侧部分似乎与这个静息态网络有关,而背侧部分则没有参与。这个静息态网络包括与语言相关的55b区域、Broca区和Wernicke区。
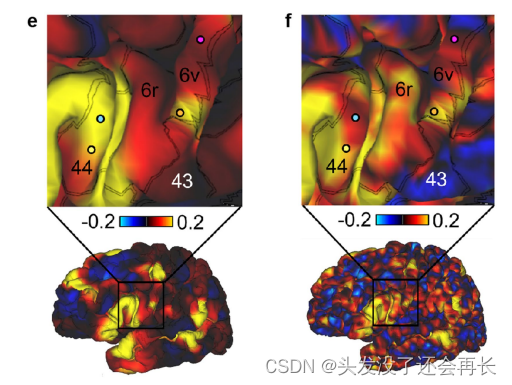
什么是静息状态网络?
静息状态网络(Resting state network)是指在没有特定任务或刺激的情况下,大脑区域之间存在的同步活动模式。这种同步活动可在静息状态下通过脑成像技术(如功能磁共振成像)观察到。语音产生和理解是复杂的神经过程,涉及多个大脑区域之间的协同活动。静息状态网络提供了一种观察大脑功能连接和内部通信的方式,因此可以揭示与语音相关的大脑活动模式。
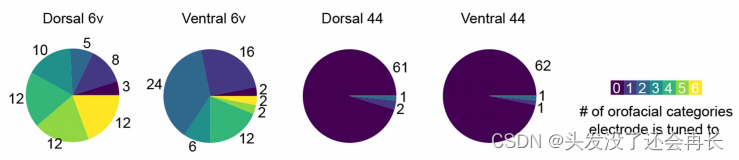
关于语音发音器官(下颌(jaw)、喉部(larynx)、唇部(lips)或舌头(tongue))在单电极水平上的调节。研究发现,这些语音发音器官的调节是混合在一起的,即在单个电极上可以同时检测到对多个发音器官的调节响应。
如下图所示,饼状图显示了每个可能的运动类别具有统计显著调谐的电极数量。可以看到6v区域的阵列,许多电极被谐调到多个类别的口腔面部运动。
下面的条形图统计了每个运动类别和每个阵列的调谐电极的数量。腹侧6v阵列包含更多的针对音素和单词的电极,而背侧6v阵列包含更多的针对口面部运动类别的电极。然而,这两个6v阵列都包含了可调谐到所有运动类别的电极。
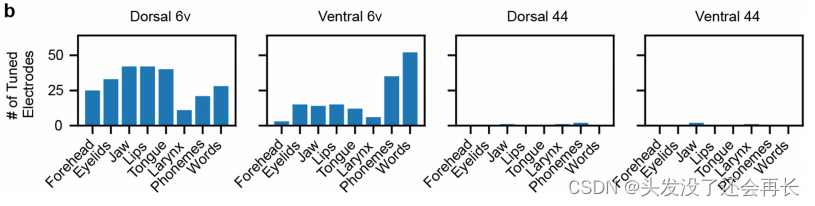
另外,研究还指出,在两个尺寸为3.2×3.2 mm2的阵列中,所有的语音发音器官都能够得到明确的表示。这意味着无论是下颌、喉部、唇部还是舌头,它们在这两个阵列中都有独立的、可辨识的电信号表示。
这项研究结果表明,在单个电极水平上,语音发音器官的调节可以同时存在,并且可以在较小的电极阵列中进行有效的检测和表示。
以上的研究表明,在所有测试的运动中,大脑区域对其表现出强大且空间混合的调谐。 这表明大脑对语音发音的表示可能足够强大,足以支持言语脑机接口(BCI)的实现。由于44区域几乎没有对语音提供有帮助的信息,所以接下来的研究数据都来自6v区域。
解码试图言语(Decoding attempted speech)
Q: 如何理解
试图言语?
A: 这个短语指的是对试图言语的内容进行解码。在脑机接口的研究中,当人们试图产生言语时,可以使用神经信号解码出他们试图表达的内容。这种解码的目标是将神经信号转化为可理解的语言或文本。这种解码的应用可以有助于帮助那些由于瘫痪或其他原因无法通过自然语言进行交流的人们,实现他们的思想和意图与外界的沟通。
解码器设计
作者设计了如下图所示的解码器,使用RNN解码器,在每80ms时间步长中,发出当时每个音素被说出的概率。然后,将这些概率与一个语言模型(language model)相结合,以推断出最可能的潜在单词序列,同时给定音素概率和英语语言的统计数据。
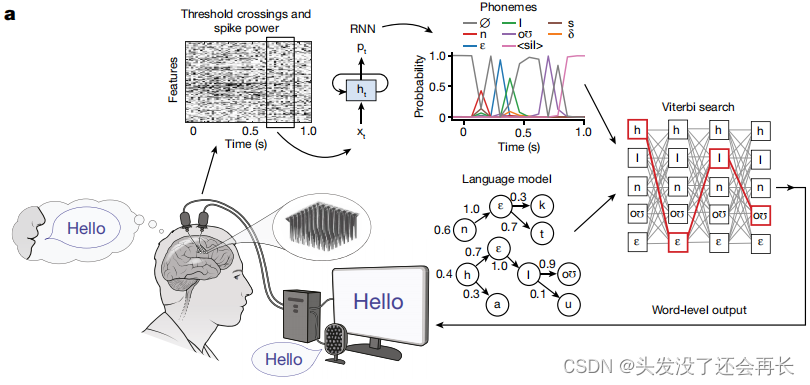
训练
在每个RNN性能评估日的开始,我们首先记录了训练数据,期间T12以自己的节奏试图说出260至480个句子(共计41±3.7分钟的数据;句子是从switchboard语料库20中随机选择的英语口语)。
T12是根据电脑显示器的提示说出指定的句子。
然后RNN在这些记录的训练数据上进行训练,具体而言,作者对每一天使用了独特的输入层,以考虑跨天神经活动的变化,并使用滚动特征适应(rolling feature adaptation) 来考虑一天内的变化。
到最后一天,练数据集总共包含了10,850个句子。数据收集和RNN训练平均每天持续140 min(包括休息时间)。
Q: 什么是
滚动特征适应?
A: 在滚动特征适应中,数据被分割成不重叠的时间窗口,每个窗口内的数据被视为一个观察点。然后,针对每个观察点,特征的计算方式会根据窗口内的数据进行调整。这种调整通常基于窗口内的统计信息,如均值、标准差或其他相关度量。
通过滚动特征适应,可以捕捉到时间序列数据中的变化趋势和模式。例如,在语音识别中,声音信号的频谱特征可能会随着时间的推移而发生变化,因为说话者的发音、语速或环境条件可能会改变。通过使用滚动特征适应,可以根据当前时间窗口内的数据调整特征的计算方式,使其更好地适应当前的声学环境。
证明上述方法有效性的实验数据在补充数据图5里,我没有仔细研究,这里就不再具体描述。
测试
训练之后,作者使用在训练集中从未重复过的保留的句子(held-out sentences)进行实时评估。
Q: 什么是held-out sentences?
A: 从训练集中保留的一部分句子,这些句子不会在训练过程中被使用。这些保留的句子被用于评估模型在未见过的数据上的性能。
测试步骤:对于每个句子,T12首先在指示的延迟期间准备着要说出的句子。当"go"信号被发出时,神经解码自动触发开始。当T12试图说话时,经过神经解码的单词实时地出现在屏幕上,反映了语言模型当前的最佳猜测。当T12说完,她会按下一个按钮完成解码输出。
作者使用了两个语言模型(language model): 一个拥有125000个单词的大词汇量模型(large-vocabulary model);一个用过50个单词的小词汇量模型(small-vocabularymodel)。使用switchboard语料库的句子来评估具有125,000词汇量的RNN模型。对于50个单词的词汇量,我们使用了Moses等人的单词集和测试句子。
性能评估是在尝试言语的5天中进行的,其中包括使用声音进行言语的5天,以及尝试无声言语(即通过嘴唇运动单词而没有声音发出,T12报告说她更喜欢这种方式,因为它更不累人)的3天。
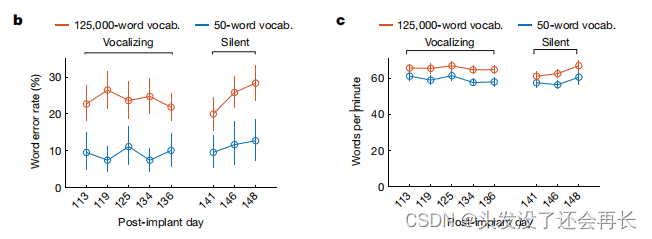
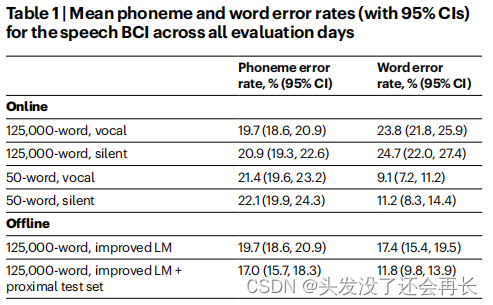
评估的结果如下图b、c和表1所示,两种方式都取得了较好的性能。在发声评估的5五天里,在59个词汇量的模型中,T12的单词错误率为9.1%;在125000词汇量的模型中,T12的单词错误率为23.8%。
这是大词汇表解码的第一次成功演示,也是在小词汇表的准确性方面的一个重大进步!
但是,RNN存在一种弊端,发音相似的因素容易被混淆,下图是在所有实时评价句子中观察到的音素替换错误。
矩阵中的条目(i.j)表示对真实的音素i和已解码的音素j所观察到的替换计数。使用编辑距离算法来识别替换,该算法确定了使解码的音素序列与真实音素序列匹配所需的插入、删除和替换的最小数量。大多数替换似乎发生在发音相似的音素之间。
说明解码器很容易混淆相同或相似的音素。
这个结果说明好的解码器不应该完全依赖于一个语言模型。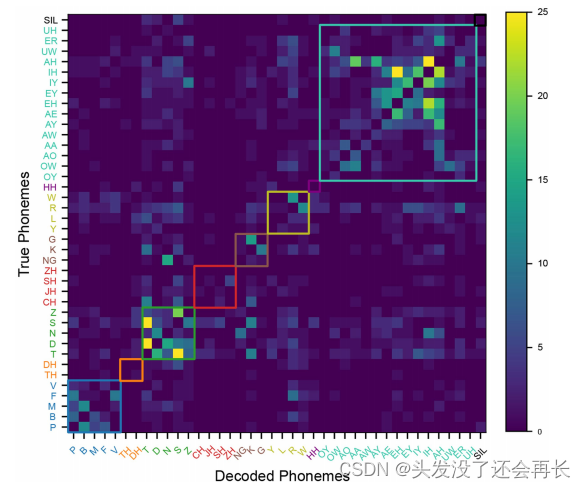
语音产生的电极阵列分布
作者还研究了语音产生的信息是如何在电极阵列中分布的。(离线分析)下图显示了每个阵列和微电极对解码性能的贡献。使用仅有腹侧6v阵列(左列)、仅有背侧6v阵列(中列)或两个阵列(右列)进行回顾性离线解码分析的词错误率。每个圆圈表示10个RNN种子中的一个种子的词错误率。词错误率是在400个试验中聚合的。水平线表示所有10个种子的平均值。
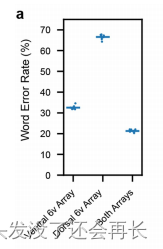
可以得出结论,两个点击阵列对解码都是有帮助的,并且只有当两个阵列都参与时才能达到最好的解码效果。
离线解码性能上限
为了探索如何能够提高解码器的性能,作者在以下两个方面进行了改进:(1)对语言模型进行进一步改进(2)在接近训练句子的时间上对解码器进行评估。(在测试句子上对解码器进行评估,而这些测试句子与训练句子在时间上更加接近。目的是减轻时间上的日内变化对神经特征的影响。)实验的效果见上表1。
语音中的保留表示(Preserved representation of speech)
接下来,作者研究了在试图说话时6v区域对音素的表征。但由于T12 无法表达可理解的语言,我们无法知道每一个音素在何时被说出的。
为了估计每个音素的神经表征,作者分析了我们的递归神经网络(RNN)解码器,提取了神经活动的向量('显著性'向量‘saliency’ vectors),这些向量最大化了RNN对每个音素的输出概率。然后,我们探究这些显著性向量是否编码了关于音素发音方式的详细信息。
辅音(consonant)的发音表征
作者将辅音的神经表征与通过电磁式口腔运动追踪技术在一个健全说话者中测得的发音表征(articulatory representation)进行比较。两者都对比各自的辅音相似性,得到相似性矩阵,如下图所示,结果发现,当按照发音位置的顺序对辅音进行排序,神经数据和发音数据的表征相似性方面存在一定的一致性。
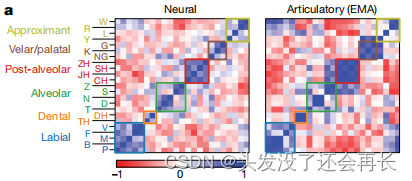
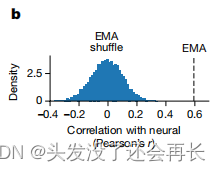
其次,如下图所示,作者发现,“电磁式口腔运动追踪(EMA)” 和神经数据之间的相关性为0.61,远高于随机水平。这个结果表明,在这项研究中,电磁式口腔运动追踪(EMA)测量的口腔运动数据与神经数据之间存在显著的相关性。这意味着通过电磁式口腔运动追踪仪(EMA)测量的口腔运动数据可以反映出神经系统中与辅音产生相关的活动。这种相关性远高于随机水平,进一步支持了神经系统与辅音产生之间的联系。
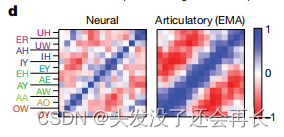
元音(vowel)的发音表征
元音具有二维的发音结构:一个高低轴(舌在口腔中的位置,对应第一共振峰频率)和一个前后轴(舌是向前还是向后卷曲,对应第二共振峰频率)。
如下图所示,和辅音做了相同的实验,元音的显著性向量也反映了这种结构,而元音的发音相似,具有相似的神经表征。作者也使用额外的估计神经和发音结构的方法,以及其他健全说话者来验证这些结果,实验结果在补充数据图8中。
脑机接口设计的考虑因素(Design considerations for speech BCIs)
作者认为在设计提高语音BCI的准确率和可用性的时候,应该考虑三个因素:语言模型的词汇量大小、微电极阵列个数、数据集大小。
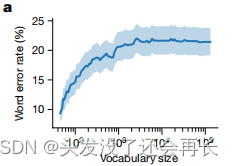
词汇量大小
实验结果如下图所示,通过使用词汇量越来越大的语言模型来重新处理RNN输出,从而重新分析了50个单词集的数据。结果发现,只有非常小的词汇量(例如50-100个单词)相对于大词汇量模型才能保持较大的准确性改进。随着词汇量增加,词错误率在约1000个单词左右趋于饱和,这表明使用中等词汇量大小可能不是增加准确性的可行策略。
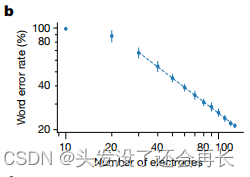
电极数量
从下图的试验结果可以看出,使用更多的电极便会获得更高的准确性,但是这种下降趋势在多大程度上矩形下去仍有待观察。
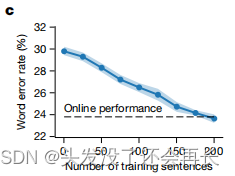
训练句子数量
随着训练句子数量的增加,单词错误率会逐渐减小。
总结
- 本文作者提出了一个高效的解码器。使用单神经元进行解码,并通过研究与发音相关的神经区域和运动信息分布相关的信息确定了单神经元分辨率。
- 解码器设计是结合了RNN和一个语言模型,语言模型作者采用了一个50词汇量的,一个125000词汇量的进行实验。并探究了语言产生的电极阵列分布,发现6v的腹侧和背侧电极阵列都对解码性能有很大帮助,并且只有两个同时参与到解码才会取得最好的解码性能。
- 为了性能评估,作者分析了语音中的保留表示,探究了辅音和元音的神经活动是否和发音数据有相同的特征表示。
- 最后作者给出了脑机接口几个考虑因素的灵敏度实验。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!