python学习2
大家好,这里是七七,这次学习的例子是一个数据清洗代码。完整代码在最后。
开始这次的内容
目录
代码一
xlsx_file = 'data/附件1.xlsx'
df_1 = pd.read_excel(xlsx_file)
xlsx_file = 'data/附件2.xlsx'
df = pd.read_excel(xlsx_file)
#将指定列转换为时间序列
df['销售日期']=pd.to_datetime(df['销售日期'])
df['扫码销售时间']=pd.to_datetime(df['销售日期'].astype(str)+' '+df['扫码销售时间'],errors='coerce',format='%Y-%m-%d %H:%M:%S.%F')只解释这段代码的最后一行:
这段代码的作用是将一个数据框(DataFrame)中的两列数据进行合并,得到一个新的日期时间列。具体来说,它将`销售日期`列和`扫码销售时间`列合并成一个新的列`扫码销售时间`。
这种合并需要按照特定的日期时间格式进行,因此需要指定这个格式。在代码中,指定的日期时间格式是`'%Y-%m-%d %H:%M:%S.%F'`。可以解释一下这个格式:
- `%Y`表示四位数的年份,例如2023年表示为'2023';
- `%m`表示两位数的月份,例如1月表示为'01',12月表示为'12';
- `%d`表示两位数的日期,例如1号表示为'01',31号表示为'31';
- `%H`表示两位数的小时,使用24小时制;
- `%M`表示两位数的分钟;
- `%S`表示两位数的秒;
- `%F`表示微秒(毫秒)。
pd.to_datetime()函数用于将指定的日期时间字符串转换为 DateTime 类型。然而,由于日期时间数据的多样性,有时候会遇到无法解析的字符串,这可能会导致转换错误。当参数
errors设置为’coerce’时,意味着将遇到的无法解析的字符串转换为缺失值(NaT,也即 Not a Time)。也就是说,如果在转换过程中出现无法解析的日期时间字符串,会将其转换为缺失值而不抛出错误。
.astype(str)是 pandas 中的一个方法,用于将数据类型转换为字符串类型。在这段代码中,
.astype(str)被应用于df['销售日期']这一列,将该列的数据类型从原始的日期类型转换为字符串类型。这是为了确保日期格式与扫码销售时间能够正确地进行字符串拼接。
代码二?
hist,bins=np.histogram(result['销售天数'],bins=10)
bin_centers=0.5*(bins[:1]+bins[1:])
cmap=plt.cm.coolwarm
norm=plt.Normalize(vmin=min(hist),vmax=max(hist))
colors=cmap(norm(hist))
plt.figure(figsize=(8,6))
bars=plt.bar(bin_centers,hist,width=bins[1]-bins[0],color=colors,edgecolor='k',alpha=0.7)这段代码是在使用 matplotlib 绘制直方图时常见的一部分。
首先,`result['销售天数']` 是一个包含销售天数数据的数组。通过使用 `np.histogram()` 函数,可以将这些数据分成 10 个 bins,并返回直方图数组 `hist` 和对应的 bin 边界数组 `bins`。
接着,我们计算每个 bin 的中心点坐标,并存储在 `bin_centers` 数组中。这可以通过取每个相邻 bin 边界的平均值来实现。
然后,`cmap` 是一个颜色映射对象,它在这里被指定为 `plt.cm.coolwarm`,表示使用 coolwarm 颜色映射。`norm` 是一个归一化器对象,它将直方图的取值范围归一化到 `vmin` 和 `vmax` 指定的范围内。
利用 `cmap` 对象和归一化后的直方图 `hist`,可以得到一组表示每个 bin 颜色的数组 `colors`。
接下来,`plt.figure(figsize=(8, 6))` 是创建一个新的图形对象,指定图形的大小为 `(8, 6)`。
最后,通过调用 `plt.bar()` 方法,根据 `bin_centers` 和 `hist` 数据创建直方图。使用 `width` 参数设置每个 bin 的宽度,使用 `color` 参数传递 `colors` 数组来设置每个 bin 的颜色,使用 `edgecolor` 参数设置直方图边缘的颜色,使用 `alpha` 参数设置直方图的透明度。
绘制完成后,可以通过 `bars` 变量引用各个直方柱子的对象,用于进一步的自定义设置或添加标签等操作。
代码三
for i,count in enumerate(hist):
plt.text(bin_centers[i],count+5,str(count),ha='center',va='bottom')
plt.xlabel('销售天数')
plt.ylabel('单品数')
plt.title('销售天数分布直方图')
plt.grid(True)
sm=ScalarMappable(cmap=cmap,norm=norm)
sm.set_array([])
cbar=plt.colorbar(sm,ax=plt.gca(),orientation='vertical')
cbar.set_label('计数',rotation=90,labelpad=15)
plt.show()这段代码是在对已绘制的直方图进行一些自定义设置和添加文本标签的操作,并且还添加了一个颜色条(colorbar)。
首先,使用 `enumerate(hist)` 遍历直方图的每个 bin,其中 `i` 是索引,`count` 是每个 bin 的计数值。通过 `plt.text()` 函数,在每个 bin 的中心点位置 `(bin_centers[i], count+5)` 处添加一个文本标签,文本内容为对应的计数值 `count`,`ha='center'` 表示水平居中对齐,`va='bottom'` 表示垂直底部对齐。
然后,使用 `plt.xlabel()` 和 `plt.ylabel()` 分别设置 x 轴和 y 轴的标签,`plt.title()` 设置图表的标题为 '销售天数分布直方图',`plt.grid(True)` 添加网格线。
接下来,创建一个 `ScalarMappable` 对象 `sm`,并将它与之前定义的颜色映射 `cmap` 和归一化器 `norm` 相关联。使用 `sm.set_array([])` 设置颜色条的值为空,`cbar=plt.colorbar(sm,ax=plt.gca(),orientation='vertical')` 创建一个颜色条并将其添加到当前图形对象的轴上,`orientation='vertical'` 表示颜色条的垂直方向。
使用 `cbar.set_label()` 设置颜色条的标签为 '计数', `rotation=90` 表示将标签旋转 90 度, `labelpad=15` 表示将标签与颜色条之间的间距设置为 15。
最后,通过 `plt.show()` 显示绘制的图表,展示直方图和颜色条。
enumerate(hist)?是一个用于在每次迭代中同时获取索引和元素的内置函数。在这种情况下,它用于遍历直方图的每个 bin。代码中的?
hist?变量被假设为一个包含直方图数据的数组。对于每个 bin,enumerate(hist)?返回一个元组?(index, value),其中?index?是当前 bin 的索引,从0开始,value?是对应 bin 的值。通过使用?
enumerate(hist),可以在每次迭代中获取到?index?和?value?这两个变量的值,从而对直方图的每个 bin 进行处理或操作。例如,在代码中,利用?enumerate?遍历直方图的每个 bin,并使用?bin_centers[i]?和?count?来进行文本标签的添加操作。
输出如下: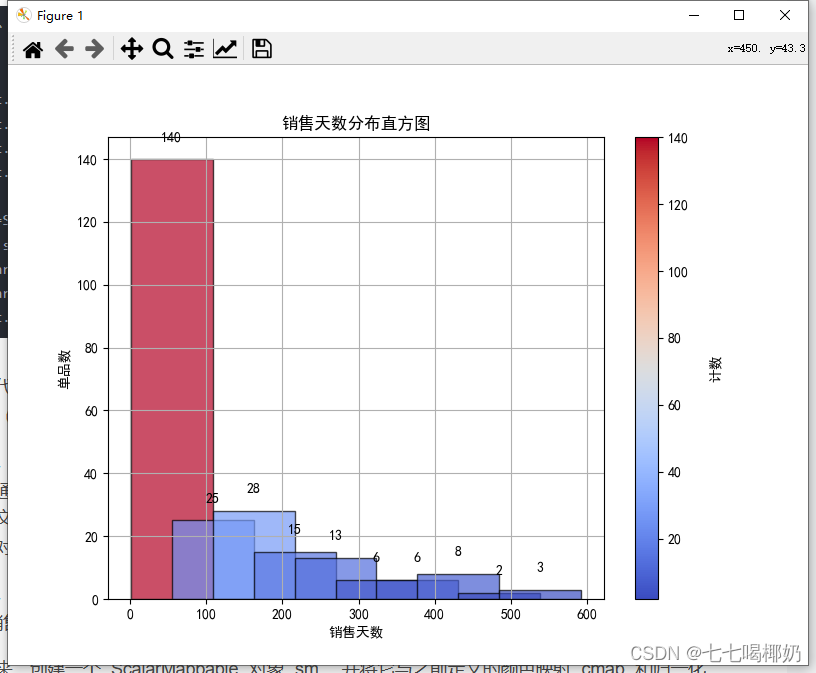
?代码四
filtered_result=result[result['销售天数']<=threshold_1]
count=filtered_result.shape[0]
list_1=[]
for index,row in filtered_result.iterrows():
if row["销售天数"]<=threshold_1:
list_1.append(row["单品编码"])
print(f'\n阈值为{threshold_1}时被筛除的单品数量:{count}')
print("分别是:")
print(list_1)这段代码在对结果进行筛选,并统计被筛选掉的单品数量。然后打印出被筛选掉的单品编码列表。
首先,根据条件 `result['销售天数']<=threshold_1` 对结果进行过滤,创建一个新的 DataFrame `filtered_result` 来保存筛选后的数据。
接着,通过 `filtered_result.shape[0]` 获取 `filtered_result` 的行数,即被筛选掉的单品数量,并将结果赋值给变量 `count`。
然后,创建一个空列表 `list_1`,用于存储符合筛选条件的单品编码。
使用 `filtered_result.iterrows()` 遍历 `filtered_result` 的每一行数据。在每次迭代中,`index` 是行索引,`row` 是对应行的数据。
对于每一行数据,如果 `row["销售天数"]` 小于等于 `threshold_1`,则将 `row["单品编码"]` 加入到 `list_1` 中。
接下来,使用 f-string 格式化字符串,打印出阈值 `threshold_1` 时被筛选掉的单品数量:`count`。
然后,打印 "分别是:" ,表示即将打印单品编码列表。
最后,通过 `print(list_1)` 打印出 `list_1` 中的单品编码列表。
在最后一行,`threshold_2` 被赋值为 0.00003。但是这里没有对 `threshold_2` 进行任何处理或使用,所以它可能是一个定义但未使用的变量。
.shape?是 Pandas DataFrame 和 NumPy 数组对象的一个属性,用于获取数据对象的形状信息,返回一个元组?(行数, 列数)。在这里,.shape[0]?表示 DataFrame 的行数,即数据框中的记录数。例如,对于一个大小为 (100, 5) 的 DataFrame,使用?
.shape?得到的结果将是?(100, 5), 表明该 DataFrame 有100条记录和5个变量。如果在此 DataFrame 上使用?.shape[0],则返回结果 100,表示该 DataFrame 有100条记录。因此,
filtered_result.shape[0]?这个语句用于获取 DataFrame?filtered_result?的行数,即数据框中记录的数量。在该代码段中,它被用于获取被筛选掉的单品的数量。
输出如下:
?全部代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = [u'simHei']
plt.rcParams['axes.unicode_minus'] = False
#数据读入
xlsx_file = 'data/附件1.xlsx'
df_1 = pd.read_excel(xlsx_file)
xlsx_file = 'data/附件2.xlsx'
df = pd.read_excel(xlsx_file)
#将指定列转换为时间序列
df['销售日期']=pd.to_datetime(df['销售日期'])
df['扫码销售时间']=pd.to_datetime(df['销售日期'].astype(str)+' '+df['扫码销售时间'],errors='coerce',format='%Y-%m-%d %H:%M:%S.%F')
#计算销售金额
df['销售金额']=df['销量(千克)']*df['销售单价(元/千克)']
#分品类
mapping_dict=df_1.set_index('单品编码')['分类名称'].to_dict()
df['品类']=df['单品编码'].map(mapping_dict)
print(df.head(5))
##第一步:处理没有销量的数据
unique_values_df=df['单品编码'].unique()
unique_values_df_1=df_1['单品编码'].unique()
values_only_in_df_1=set(unique_values_df_1)-set(unique_values_df)
count_values_only_in_df_1=len(values_only_in_df_1)
print("df列'单品编码的唯一值个数: ",len(unique_values_df))
print("df_1列'单品编码的唯一值个数: ",len(unique_values_df_1))
print("df_1中有但是df中没有的值: ",values_only_in_df_1)
print("这些值的个数:",count_values_only_in_df_1)
#第二步:销量天数少(阈值10)的单品找出来
threshold_1=10
import numpy as np
from matplotlib.cm import ScalarMappable
result=df.groupby('单品编码')['销售日期'].nunique().reset_index()
result.rename(columns={'销售日期':'销售天数'},inplace=True)
hist,bins=np.histogram(result['销售天数'],bins=10)
bin_centers=0.5*(bins[:1]+bins[1:])
cmap=plt.cm.coolwarm
norm=plt.Normalize(vmin=min(hist),vmax=max(hist))
colors=cmap(norm(hist))
plt.figure(figsize=(8,6))
bars=plt.bar(bin_centers,hist,width=bins[1]-bins[0],color=colors,edgecolor='k',alpha=0.7)
for i,count in enumerate(hist):
plt.text(bin_centers[i],count+5,str(count),ha='center',va='bottom')
plt.xlabel('销售天数')
plt.ylabel('单品数')
plt.title('销售天数分布直方图')
plt.grid(True)
sm=ScalarMappable(cmap=cmap,norm=norm)
sm.set_array([])
cbar=plt.colorbar(sm,ax=plt.gca(),orientation='vertical')
cbar.set_label('计数',rotation=90,labelpad=15)
plt.show()
filtered_result=result[result['销售天数']<=threshold_1]
count=filtered_result.shape[0]
list_1=[]
for index,row in filtered_result.iterrows():
if row["销售天数"]<=threshold_1:
list_1.append(row["单品编码"])
print(f'\n阈值为{threshold_1}时被筛除的单品数量:{count}')
print("分别是:")
print(list_1)
threshold_2=0.00003
#第三步:销量低(阈值2)的单品找出来
grouped=df.groupby('单品编码')['销量(千克)'].sum().reset_index()
print(len(grouped))
total_sales=grouped['销量(千克)'].sum()
grouped['销量占比']=grouped['销量(千克)']/total_sales
low_percentage_groups=grouped[grouped['销量占比']<threshold_2]['单品编码']
list_2=low_percentage_groups.to_list()
print("\n所有组的销量总和:",total_sales)
print(f"销量占比低于{threshold_2}的组的单品编码:")
print(list_2)
print(f"总数是:{len(low_percentage_groups)}")
data_g=[]
for i in grouped['销量占比']:
if i<=threshold_2:
data_g.append(i)
bins=10
n,bins,patches=plt.hist(data_g,bins=bins,edgecolor='k')
plt.xlabel('销量占比')
plt.ylabel('频数')
plt.title('销量占比直方图')
plt.grid()
for i, rect in enumerate(patches):
height=rect.get_height()
plt.annotate(f'{height}',xy=(rect.get_x()+rect.get_width()/2,height),xytext=(0,5),textcoords='offset points',ha='center',va='bottom')
plt.show()
#第四步:取交集
intersection=list(set(list_1)&set(list_2))
print(f"\n交集数量为:{len(intersection)}")
print(intersection)
#第五步:查看
#选择特定的单品编码
target_item=intersection[1]
grouped=df.groupby(['单品编码','销售日期'])['销量(千克)'].sum().reset_index()
filtered_df=grouped[grouped['单品编码']==target_item]
print(filtered_df)
#绘制折线图
plt.figure(figsize=(10,6))
plt.plot(filtered_df['销售日期'],filtered_df['销量(千克)'],marker='o',linestyle='-')
plt.title(f'单品编码{target_item} 的销售日期和销售折线图')
plt.xlabel('销售日期')
plt.ylabel('销售金额')
plt.grid(True)
#显示折线图
plt.show()最后一张结果
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!