基于YOLOv5的行人检测系统
若需要完整工程源代码,请私信作者
目标检测在计算机视觉领域中的重要性,特别是在人群流量监测方面的应用。其中,YOLO(You Only Look Once)系列算法在目标检测领域取得了显著的进展,从YOLO到YOLOv5的发展历程表明其在算法性能上的不断优化。文中提到了基于YOLOv5设计的人口密度检测系统,该系统通过深度学习算法对人群进行检测和计数,主要应用于商场、路口等需要控制人流的场所。
系统通过YOLOv5算法实现人群检测和计数,具体使用Python实现了该算法,并通过PyQt创建了用户界面,实现了对行人数目和人群密度的监测。该系统可以处理图片、视频以及摄像设备得到的图像,自动标记和记录检测结果。初始界面如下图:
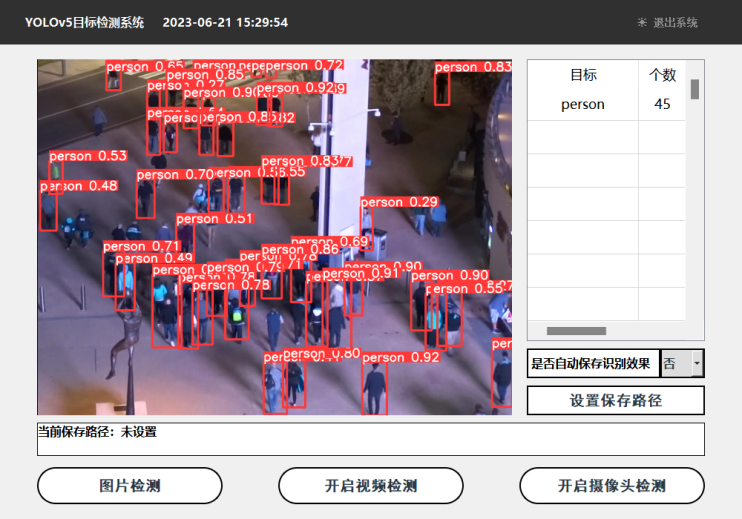
(一)系统介绍
????????基于深度学习的花卉检测与识别系统主要用于常见行人的智能识别,对于采集到的花卉图像,基于深度学习技术识别多种不同的行人,在图像中标记行人检测框和对应类别,以帮助人们辨认和识别行人;软件能有效识别相机拍摄的图片、视频等文件,准确检测区域并记录识别结果在界面表格中方便查看;支持开启摄像头设备实时检测和统计画面中的行人,支持结果记录、展示和保存,对各类型行人数目实时可视化显示。
(二)技术特点
?????????(1)训练YoloV5算法识别花卉,模型支持更换;
?????????(2)摄像头实时检测行人图像,展示、记录和保存识别结果;
?????????(3)检测图片、视频等图像中的花朵位置等;
?????????(4)支持用户登录、注册,检测结果可视化功能;
(三)选择图片识别
????????系统允许选择图片文件进行识别,点击图片选择按钮图标选择图片后,显示所有识别的结果,可通过下拉选框查看单个结果,以便具体判断某一特定目标。
(四)视频识别效果展示
????????很多时候我们需要识别一段视频中的行人,这里设计了视频选择功能。点击视频按钮可选择待检测的视频,系统会自动解析视频逐帧识别多个行人,并将行人的分类结果记录在右方表格中 。
(五)摄像头检测效果展示
????????在真实场景中,我们往往利用摄像头获取实时画面,同时需要对行人进行识别,因此本文考虑到此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的花卉
数据集的获取与处理
在日常生活中,由于行人的不一致性、尺度大小变化等情况,行人检测面临较大的挑战。为了有效解决这些问题,作者采用基于深度学习的方法进行行人检测。本文的主要目标是针对公共场合中人口较为密集的情境,进行行人个数的估计,并进一步估计人口密度。为了应对复杂情况,作者使用了公共数据集和自制数据集,用于训练和测试模型,并通过可视化方法对模型的效果进行评估。这一研究旨在应对实际场景中行人检测的挑战,提供对人口密度进行可靠估计的解决方案。
?数据集采集
在大多数公开数据集中,行人的种类相对较为单一,难以满足密集型行人检测的需求。由于在实际场景中,个人采集数据相对困难,因此作者通过在百度上搜索并整理图片,并进行人为标注,成功创建了一个自制数据集。该自制数据集包含了更为多样化的行人图像,旨在更好地满足密集型行人检测的训练和测试需求。在本论文中,作者将自制数据集与公开数据集进行统一使用,用于模型的全面训练和测试。这一方法旨在提高模型的泛化性能,使其更适用于真实场景中的行人检测任务。
数据集处理
本文针对行人种类,各种大小的行人,处于站立、行走等,下图是示例图片,对效果进行可视化。此数据集采用平常的生活场景的行人图片如图3-1,图3-2。

行人图片1

?行人图片2
公共数据集和自制数据集的处理过程,主要包括对VOC格式数据集的划分、转化为YOLO格式数据集,以及自制数据集的标注、格式转换和数据增强过程。
-
对VOC格式数据集的处理:
- 数据集为VOC格式,包含Annotations文件夹和JPEGImages文件夹。
- Annotations中存放XML文件,包含图片宽高、物体种类、框的坐标信息。
- JPEGImages存放所有XML文件对应的图片。
- 针对公共数据集,需要进行训练集和验证集的划分。
- 转化为YOLO格式数据集,即生成对应的txt文件,包含物体标签和边界框坐标信息。
-
自制数据集的处理:
- 自制数据集使用Labelme软件进行标注,生成JSON格式数据,包含物体标签和边界框的坐标信息。
- JSON数据转换为txt格式,存放在Annotations文件夹中,对应的原图像存放在JPGImages文件夹。
- 80%的图像用于训练,20%用于测试,以验证模型的性能。
-
数据增强过程:
- 为了提高模型的泛化性能,采用数据增强方法对行人检测数据集进行扩展。
- 数据增强方法包括亮度调节、缩放、翻转和Mosaic。
- 通过对图像进行变换,扩充数据集,以提高模型对不同场景和变化的适应能力。
| 数据增强策略 | 具体方法 |
| 亮度调整 | 将原始图片的亮度提高或降低10% |
| 缩放 | 将原始图像中行人目标放大或缩小10% |
| 翻转 | 将原始图像水平翻转 |
| Mosaic | 将四张图片随机进行翻转、缩放、色域变化后,并且按照四个方向位置摆好,进行图片的组合和框的组合 |
?数据增强实现方法
(二)基于YoloV5的识别系统
?????????以上提及的方法虽然具有不错的精度,但仅仅是分类网络,不能实现目标的定位,于是乎本文使用了基于YoloV5的目标检测网络对花进行定位以及类别的检测。YOLOv5的调用、训练和预测都十分方便,并且它为不同的设备需求和不同的应用场景提供了大小和参数数量不同的网络。
????????这里我们开始训练和测试自己的数据集,在cmd终端中运行train.py进行训练,以下是训练过程中的结果截图。
????????在深度学习中,我们通常通过损失函数下降的曲线来观察模型训练的情况。而YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),在训练结束后,我们也可以在logs目录下找到生成对若干训练过程统计图。下图为博主训练行人识别的模型训练曲线图。?

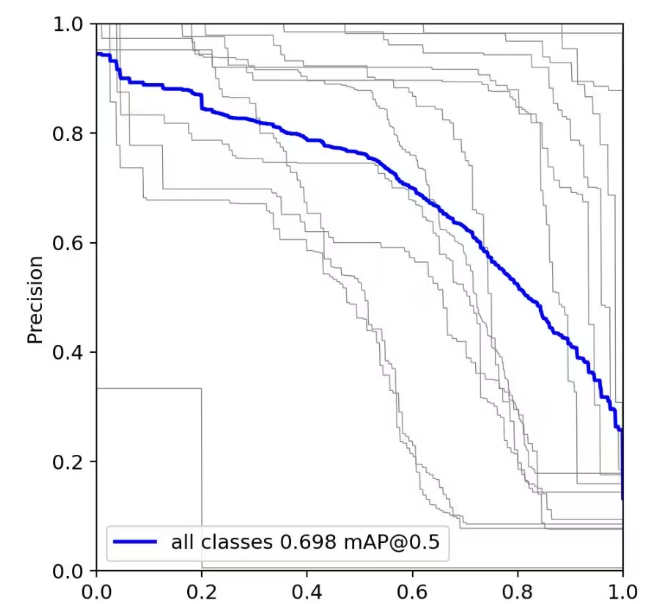
在目标检测中常用的两个性能评估指标,即召回率(recall)和精度(precision)。这两个指标都是介于0到1之间的数值,表示模型在不同方面的性能。召回率和精度越接近1,模型性能越好;越接近0,性能越差。为了综合评估目标检测的性能,通常采用均值平均密度(mean average precision,mAP)来进一步评估模型的好坏。
在计算mAP时,可以通过设定不同置信度的阈值,得到模型在不同阈值下计算出的精度和召回率。一般来说,精度和召回率存在负相关关系。通过绘制精度-召回率曲线,其中曲线下的面积被称为AP(average precision),每个目标都有一个相应的AP值。对所有目标的AP值求平均,得到模型的mAP值,从而全面评估目标检测模型在不同条件下的性能表现。这种评估方法有助于更全面地了解模型的鲁棒性和泛化能力。
结束语
?????????由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
? ? ? ? 若需要完整工程源代码,请私信作者
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!