以对象为中心的视频编辑;SDXL高质量缩小版;Transformer在FPGA上实现12.8倍速度提升;深入研究ViT固有问题
本文首发于公众号:机器感知
以对象为中心的视频编辑;SDXL高质量缩小版;Transformer在FPGA上实现12.8倍速度提升;深入研究ViT固有问题
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos

现有方法通过文生图模型来做视频编辑任务,然而这些方法大多使用文本编辑整个视频帧,其只专注于提高帧之间的时间一致性。本文引入了一个以对象为中心的框架,旨在控制对象的外观,特别是执行精确和明确的结构修改。此方法以预训练的图像条件扩散模型为基础,集成了处理时间维度的层,并给出了实现外观控制的训练策略和架构修改。该方法在图像驱动的视频编辑任务上具有与SOTA方案相似的性能,并展示了新颖的外观编辑功能。
FED-NeRF: Achieve High 3D Consistency and Temporal Coherence for Face Video Editing on Dynamic NeRF
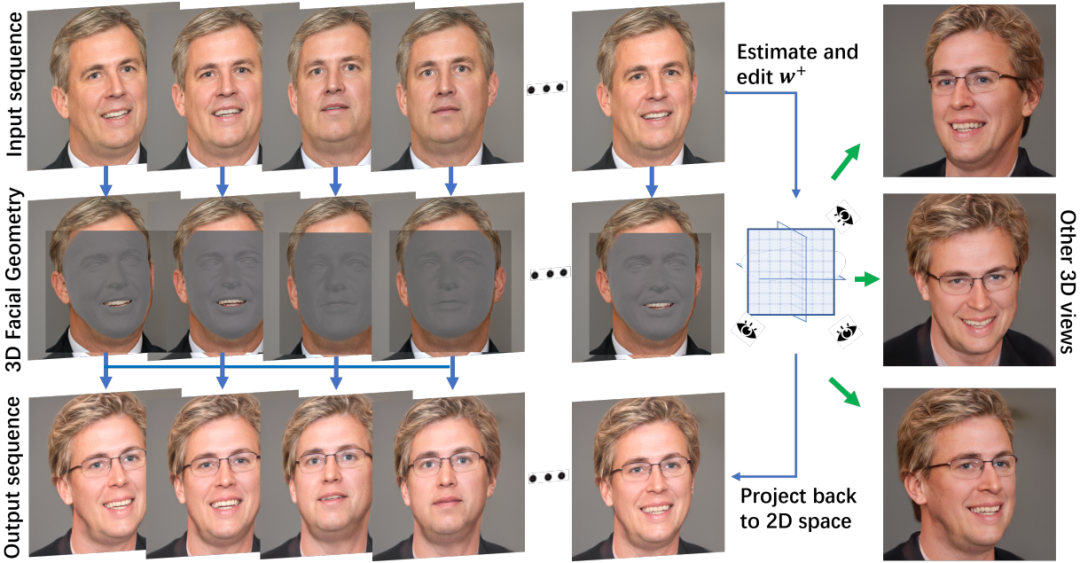
GAN-NeRF使得面部编辑能够保持3D视图一致性,但在编辑视频序列时同时实现多视图一致性和时间连贯性仍然是一个巨大的挑战。本文提出了一种基于动态面部GAN-NeRF结构的全新面部视频编辑架构,该架构利用视频序列来恢复潜码和3D面部几何形状。由于面部几何形状的估计是在逐帧基础上进行的,这可能会引入抖动问题,由此作者提出了一种稳定器来保持面部表情的平滑变化,进而维持时间连贯性。与现有的2D或3D方法相比,该方法作为开创性的4D面部视频编辑器达到了SOTA水平。
Progressive Knowledge Distillation Of Stable Diffusion XL Using Layer Level Loss

本文介绍了两种Stable Diffusion XL(SDXL)缩小的变体,Segmind Stable Diffusion(SSD-1B)和Segmind-Vega,分别通过渐进式移除具有1.3B和0.74B参数的UNets实现,并在减少模型大小的同时并保持生成质量。该方法涉及消除U-Net结构中的残差网络和transformer块,从而显著减少参数和延迟。小模型通过知识迁移模拟原始SDXL,取得了与数十亿参数的SDXL相当的结果。
A Cost-Efficient FPGA Implementation of Tiny Transformer Model using Neural ODE
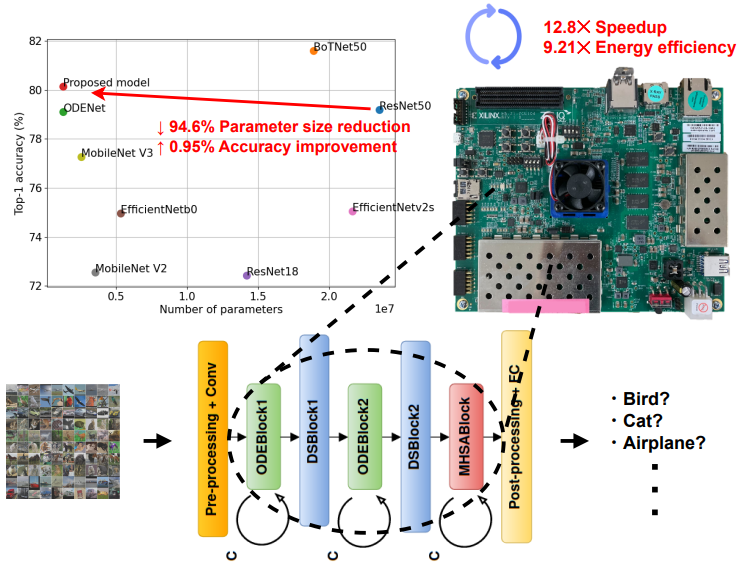
Transformer取得了优于CNN和RNN的准确率,但许多Transformer模型需要大量的参数,增加了计算复杂性。为此,本文提出了一种基于Neural ODE的混合模型,相比基于ResNet的模型,参数大小减少了94.6%,且准确率没有下降。在FPGA设备上部署该模型后,通过QAT量化方案进一步减少FPGA资源占用,实现了超轻量级的Transformer模型。此外,该模型还通过在FPGA上存储网络的权重来最小化内存传输开销,实现了更快的推理速度。最终,该FPGA实现相对于ARM Cortex-A53 CPU实现了12.8倍的速度提升和9.21倍的能效提升。
Diffusion Variational Inference: Diffusion Models as Expressive Variational Posteriors
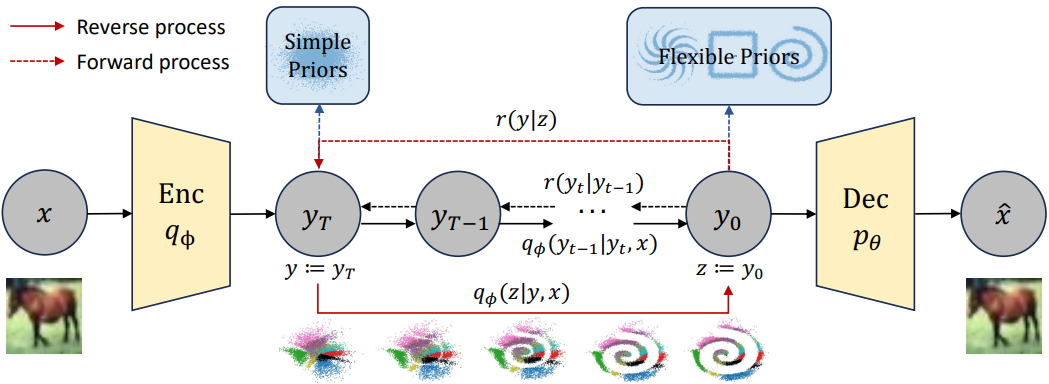
本文提出了一种名为“denoising diffusion variational inference (DDVI)”的近似推断算法,该算法依赖于扩散模型作为变分后验,并通过引入辅助潜在变量来增强变分后验。该方法易于实现,适合于黑盒变分推断,并且优于基于归一化流或对抗网络的替代类近似后验。当应用于深度潜在变量模型时,该方法变成了去噪扩散VAE(DD-VAE)算法,该算法应用在生物学Thousand Genomes数据集上时超过了强大的基线。
Diffbody: Diffusion-based Pose and Shape Editing of Human Images
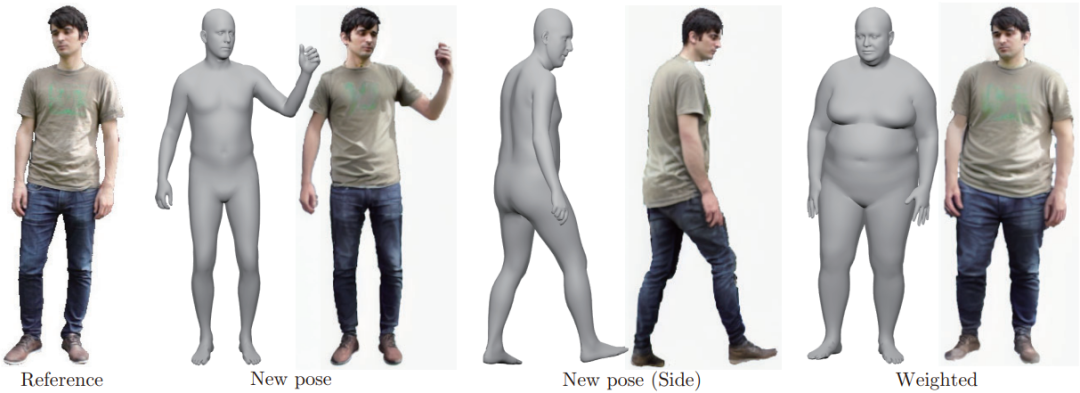
当前的人体姿态和体型编辑方法存在数据集偏差和身份失真问题,本文提出了一种能够进行高强度编辑且保留身份的方法。该方法首先将输入图像投影到3D模型上,然后改变身体姿态和体型。由于初始的纹理化身体模型存在遮挡和体型不准确的问题,本文提出了一种迭代细化方法,首先对整个身体进行弱噪声处理,然后对脸部进行弱噪声处理。此外,还通过自监督学习对text embeddings进行微调,以增强真实感。
Denoising Vision Transformers

本文针对Vision Transformers(ViTs)中存在的固有问题进行了深入研究:这些模型的特征图展现出网格状伪影,对下游任务中的ViTs性能造成不利影响。研究发现,这一根本问题源自输入阶段的postional embeddings。为了解决这一问题,作者提出了一种新型噪声模型,该模型可广泛应用于所有ViTs。具体来说,噪声模型将ViT输出分解为三个部分:一个不受噪声伪影影响的语义项和两个依赖于像素位置的伪影相关项,这种分解通过在每个图像的基础上强制实施交叉视图的特征一致性来实现。该方法称为Denoising Vision Transformers(DVT),不需要重新训练现有的预训练ViTs,并且可立即应用于任何基于Transformer的架构。作者在各种代表性ViTs(DINO、MAE、DeiT-III、EVA02、CLIP、DINOv2、DINOv2-reg)上评估了该方法,实验表明,DVT在语义和几何任务中的多个数据集上取得了一致且显著地效果提升。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!