Gemini:定义下一代人工智能的里程碑
Google最近发布号称世界最强的大模型"Gemini",其强大多模态LLM,标志着AI技术的一个新时代。
Gemini作为"迄今为止最强大的AI模型"之一,其独特之处在于它融合了多种模式的处理能力,能够同时理解和生成文本、代码、音频、图像和视频。
多模态的深度融合
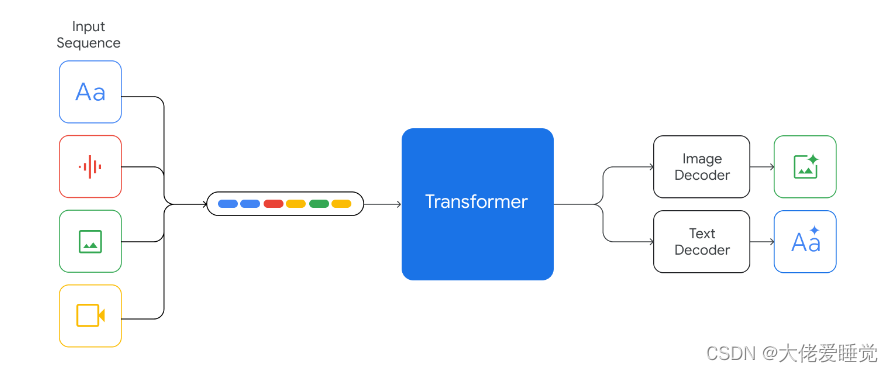
Gemini的核心创新是它的「原生多模态」架构。
不同于传统的多模态模型,它不是简单地将文本、视觉和音频模型拼接在一起,而是从一开始就在不同模态上进行训练,实现了对各种模态输入内容的「无缝」理解和推理。
也就是说,他直接把音频,图片,文本,视频等直接投喂,而不是将其转换为文本再头尾
这意味着Gemini能以类似于人类的方式理解我们周围的世界,无论是处理文字、代码、音频、图像还是视频。
Gemini的三个版本:Ultra、Pro和Nano
Gemini分为三个版本,每个版本针对不同的应用场景进行了优化:
- Gemini Ultra(超大杯):用于高度复杂的任务,主要面向数据中心和企业级应用。
- Gemini Pro(大杯):适用于广泛的任务,将成为许多Google AI服务的动力源。
- Gemini Nano(中杯):用于设备端任务,能在移动设备上本地运行,如Android设备。
目前我们能用的是Gemini Pro ,但是官方演示的碾压GPT4的,是Gemini Ultra
性能的突破
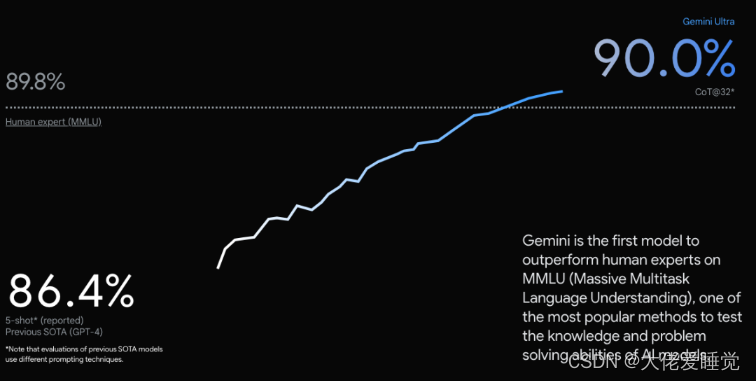
Gemini在多个领域实现了对现有技术的超越。它在32个广泛使用的学术基准测试中的30个上超越了现有技术,并且是第一个在大规模多任务语言理解(MMLU)测试中超越人类专家的模型。
应用范围
Gemini的应用范围极为广泛,从改善Google自家产品(如搜索引擎、广告产品、Chrome浏览器)到提供给开发者和企业客户的API服务。其多模态能力特别适合处理复杂的科学问题,如数学和物理的推理问题,以及高质量的编程语言代码生成。
之后我们日常所使用的大部分的生态,都将接入(比如最新安卓系统,Google浏览器等一系列Google家的产品)
同时也会逐步开放APi,就像GPT的浪潮一样,Google的AI浪潮,才刚刚开始而已。
强大的训练基础
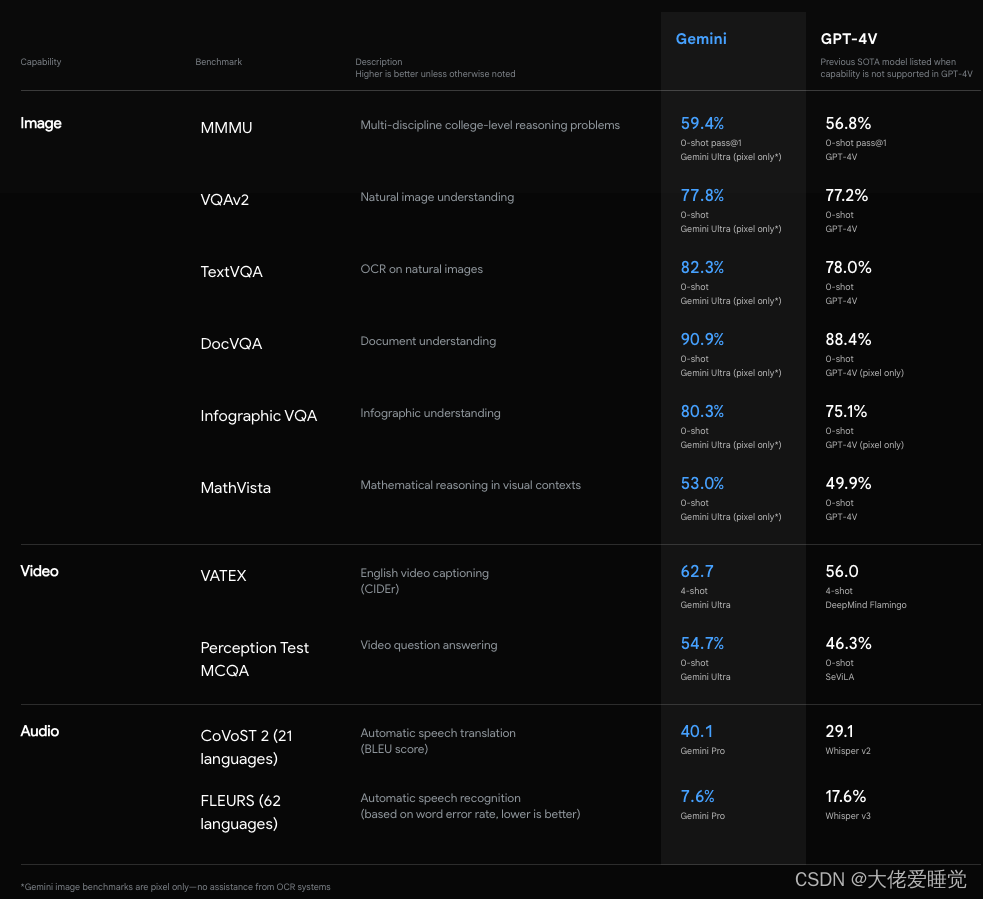
Google利用其AI优化基础设施和自家设计的Tensor Processing Units(TPUs)v4和v5e对Gemini进行了大规模训练。此外,Google还发布了Cloud TPU v5p系统,专为训练尖端AI模型而设计。
这样就意味着,Google完全有机会可以打破目前英伟达对芯片的垄断

总结:Gemini是Google对现有AI技术的一次重大提升,也是其憋了这么久的大招,通过其多模态融合能力,Gemini有望在各种领域实现革命性的变革
但是基于Google的强大的地位,其实没有人会怀疑Google的实力,毕竟一开始马斯克等人投资openai就是为了打破Google的垄断地位
但是具体表现如何,其实还是要让子弹飞一会儿,才能看出端倪
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!