【MySQL复合查询】
前言
| 剑指offer:一年又8天 |
|---|
前面我们讲解了表的操作以及常用函数的使用,本篇文章主要进行select练习,以及讲解子查询和多表笛卡尔积。
一、基本查询回顾
前期数据准备:
员工表:员工编号,姓名,工作,领导编号,入职时间,工资,奖金,部门编号;
部门表:部门编号,部门名称,部门所在地

工资等级表:等级,该等级最低工资,该等级最高工资

若需要表和数据,请在评论区扣1或私信。
查询工资高于4500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
没有说明需要那些信息,我们可以使用 select * 查询所有信息。
-- 姓名可以使用 like 模糊匹配
mysql> select * from emp where (sal > 4500 or job = 'Manager') and ename like 'J%';
+--------+------------+---------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+------------+---------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 5000.00 | 1000.00 | 100 |
+--------+------------+---------+--------+---------------------+---------+---------+--------+
1 row in set (0.00 sec)
-- 也可以使用截取子串进行比较
mysql> select * from emp where (sal > 4500 or job = 'Manager') and left(ename, 1) = 'J';
+--------+------------+---------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+------------+---------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 5000.00 | 1000.00 | 100 |
+--------+------------+---------+--------+---------------------+---------+---------+--------+
1 row in set (0.00 sec)
按照部门号升序而雇员的工资降序排序
-- 部门号升序,工资降序
mysql> select * from emp order by deptid asc, sal desc;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100004 | Emily Davis | Designer | 100001 | 2023-04-20 00:00:00 | 3800.00 | 760.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100009 | Sarah Thompson | Analyst | 100002 | 2023-06-18 00:00:00 | 3000.00 | 780.00 | 102 |
| 100006 | Jessica Martinez | Designer | 100003 | 2023-08-08 00:00:00 | 3700.00 | 740.00 | 103 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
| 100007 | Daniel Thomas | Analyst | 100010 | 2023-09-12 00:00:00 | 2000.00 | 800.00 | 104 |
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
10 rows in set (0.00 sec)
使用年薪进行降序排序
年薪 = 工资 * 12 + 奖金
-- 信息过多,提取一下需要的信息
mysql> select empid, ename, sal, bonus, sal*12+bonus 年薪 from emp;
+--------+----------------------+---------+---------+----------+
| empid | ename | sal | bonus | 年薪 |
+--------+----------------------+---------+---------+----------+
| 100001 | John Smith | 6000.00 | 1000.00 | 73000.00 |
| 100002 | Jane Doe | 4000.00 | 800.00 | 48800.00 |
| 100003 | Michael Johnson | 4500.00 | 900.00 | 54900.00 |
| 100004 | Emily Davis | 3800.00 | 760.00 | 46360.00 |
| 100005 | David Wilson | 4200.00 | 840.00 | 51240.00 |
| 100006 | Jessica Martinez | 3700.00 | 740.00 | 45140.00 |
| 100007 | Daniel Thomas | 2000.00 | 800.00 | 24800.00 |
| 100008 | Amanda Jackson | 1800.00 | 900.00 | 22500.00 |
| 100009 | Sarah Thompson | 3000.00 | 780.00 | 36780.00 |
| 100010 | Christopher Anderson | 4200.00 | 860.00 | 51260.00 |
+--------+----------------------+---------+---------+----------+
10 rows in set (0.00 sec)
-- 降序排序
mysql> select empid, ename, sal, bonus, sal*12+bonus 年薪 from emp order by 年薪 desc;
+--------+----------------------+---------+---------+----------+
| empid | ename | sal | bonus | 年薪 |
+--------+----------------------+---------+---------+----------+
| 100001 | John Smith | 6000.00 | 1000.00 | 73000.00 |
| 100003 | Michael Johnson | 4500.00 | 900.00 | 54900.00 |
| 100010 | Christopher Anderson | 4200.00 | 860.00 | 51260.00 |
| 100005 | David Wilson | 4200.00 | 840.00 | 51240.00 |
| 100002 | Jane Doe | 4000.00 | 800.00 | 48800.00 |
| 100004 | Emily Davis | 3800.00 | 760.00 | 46360.00 |
| 100006 | Jessica Martinez | 3700.00 | 740.00 | 45140.00 |
| 100009 | Sarah Thompson | 3000.00 | 780.00 | 36780.00 |
| 100007 | Daniel Thomas | 2000.00 | 800.00 | 24800.00 |
| 100008 | Amanda Jackson | 1800.00 | 900.00 | 22500.00 |
+--------+----------------------+---------+---------+----------+
10 rows in set (0.00 sec)
显示工资最高的员工的名字和工作岗位
-- 要找员工首先要知道最高工资是多少
mysql> select max(sal) from emp;
+----------+
| max(sal) |
+----------+
| 6000.00 |
+----------+
1 row in set (0.00 sec)
-- 查找员工信息
mysql> select ename, job from emp where sal = 6000;
+------------+---------+
| ename | job |
+------------+---------+
| John Smith | Manager |
+------------+---------+
1 row in set (0.00 sec)
查找两次可以达到目的,但是并不方便,MySQL允许在where中使用select查询(既:子查询)
-- 先执行子查询再执行where判断
mysql> select ename, job from emp where sal = (select max(sal) from emp);
+------------+---------+
| ename | job |
+------------+---------+
| John Smith | Manager |
+------------+---------+
1 row in set (0.00 sec)
显示工资高于平均工资的员工信息
-- 先查询平均工资
mysql> select avg(sal) from emp;
+-------------+
| avg(sal) |
+-------------+
| 3720.000000 |
+-------------+
1 row in set (0.00 sec)
-- 再查找工资高于平均工资的员工信息
mysql> select * from emp where sal > 3720;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100004 | Emily Davis | Designer | 100001 | 2023-04-20 00:00:00 | 3800.00 | 760.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
6 rows in set (0.00 sec)
-- 使用子查询
mysql> select * from emp where sal > (select avg(sal) from emp);
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100004 | Emily Davis | Designer | 100001 | 2023-04-20 00:00:00 | 3800.00 | 760.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
6 rows in set (0.00 sec)
显示每个部门的平均工资和最高工资
-- 整个公司的平均工资和最高工资
mysql> select avg(sal), max(sal) from emp;
+-------------+----------+
| avg(sal) | max(sal) |
+-------------+----------+
| 3720.000000 | 6000.00 |
+-------------+----------+
1 row in set (0.00 sec)
-- 按部门分组,再查询
mysql> select avg(sal), max(sal) from emp group by deptid;
+-------------+----------+
| avg(sal) | max(sal) |
+-------------+----------+
| 5000.000000 | 6000.00 | -- 遥遥领先
| 4150.000000 | 4500.00 |
| 3600.000000 | 4200.00 |
| 3700.000000 | 3700.00 |
| 2666.666667 | 4200.00 |
+-------------+----------+
5 rows in set (0.00 sec)
显示平均工资低于4000的部门号和它的平均工资
-- 查找各个部门的平均工资
mysql> select deptid, avg(sal) myavg from emp group by deptid;
+--------+-------------+
| deptid | myavg |
+--------+-------------+
| 100 | 5000.000000 |
| 101 | 4150.000000 |
| 102 | 3600.000000 |
| 103 | 3700.000000 |
| 104 | 2666.666667 |
+--------+-------------+
5 rows in set (0.00 sec)
-- 查找平均工资低于4000的
mysql> select deptid, avg(sal) myavg from emp group by deptid having myavg < 4000;
+--------+-------------+
| deptid | myavg |
+--------+-------------+
| 102 | 3600.000000 |
| 103 | 3700.000000 |
| 104 | 2666.666667 |
+--------+-------------+
3 rows in set (0.00 sec)
显示所有岗位以及每种岗位的雇员总数,平均工资
-- 整个公司的雇员总数,平均工资
mysql> select count(*), avg(sal) from emp;
+----------+-------------+
| count(*) | avg(sal) |
+----------+-------------+
| 10 | 3720.000000 |
+----------+-------------+
1 row in set (0.00 sec)
-- 按岗位分组
mysql> select job, count(*), avg(sal) from emp group by job;
+-----------+----------+-------------+
| job | count(*) | avg(sal) |
+-----------+----------+-------------+
| Analyst | 3 | 3000.000000 |
| Designer | 2 | 3750.000000 |
| Developer | 4 | 3675.000000 |
| Manager | 1 | 6000.000000 |
+-----------+----------+-------------+
4 rows in set (0.00 sec)
二、多表查询
实际开发中往往数据来自不同的表,所以需要多表查询。下面我们要用到上面的三张表来进行查询练习。
笛卡尔积
-- 看一下语句就行
mysql> select * from emp;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100004 | Emily Davis | Designer | 100001 | 2023-04-20 00:00:00 | 3800.00 | 760.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100006 | Jessica Martinez | Designer | 100003 | 2023-08-08 00:00:00 | 3700.00 | 740.00 | 103 |
| 100007 | Daniel Thomas | Analyst | 100010 | 2023-09-12 00:00:00 | 2000.00 | 800.00 | 104 |
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 |
| 100009 | Sarah Thompson | Analyst | 100002 | 2023-06-18 00:00:00 | 3000.00 | 780.00 | 102 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
10 rows in set (0.00 sec)
mysql> select * from dept;
+--------+-------------+---------------+
| deptid | dname | loc |
+--------+-------------+---------------+
| 100 | Sales | New York |
| 101 | Marketing | Los Angeles |
| 102 | Development | San Francisco |
| 103 | Design | Chicago |
| 104 | Finance | Boston |
+--------+-------------+---------------+
5 rows in set (0.00 sec)
-- 同时从两张表中查找
mysql> select * from emp, dept;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+--------+-------------+---------------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid | deptid | dname | loc |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+--------+-------------+---------------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 100 | Sales | New York |
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 101 | Marketing | Los Angeles |
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 102 | Development | San Francisco |
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 103 | Design | Chicago |
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 104 | Finance | Boston |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 100 | Sales | New York |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 101 | Marketing | Los Angeles |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 102 | Development | San Francisco |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 103 | Design | Chicago |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 104 | Finance | Boston |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 100 | Sales | New York |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 101 | Marketing | Los Angeles |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 102 | Development | San Francisco |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 103 | Design | Chicago |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 104 |
-- 省略。。。
50 rows in set (0.00 sec)
可以看出:使用笛卡尔积聚合数据太多,为了提高查询效率我们一般会使用内外连接来连接多张表(重要,下一篇文章会讲)。
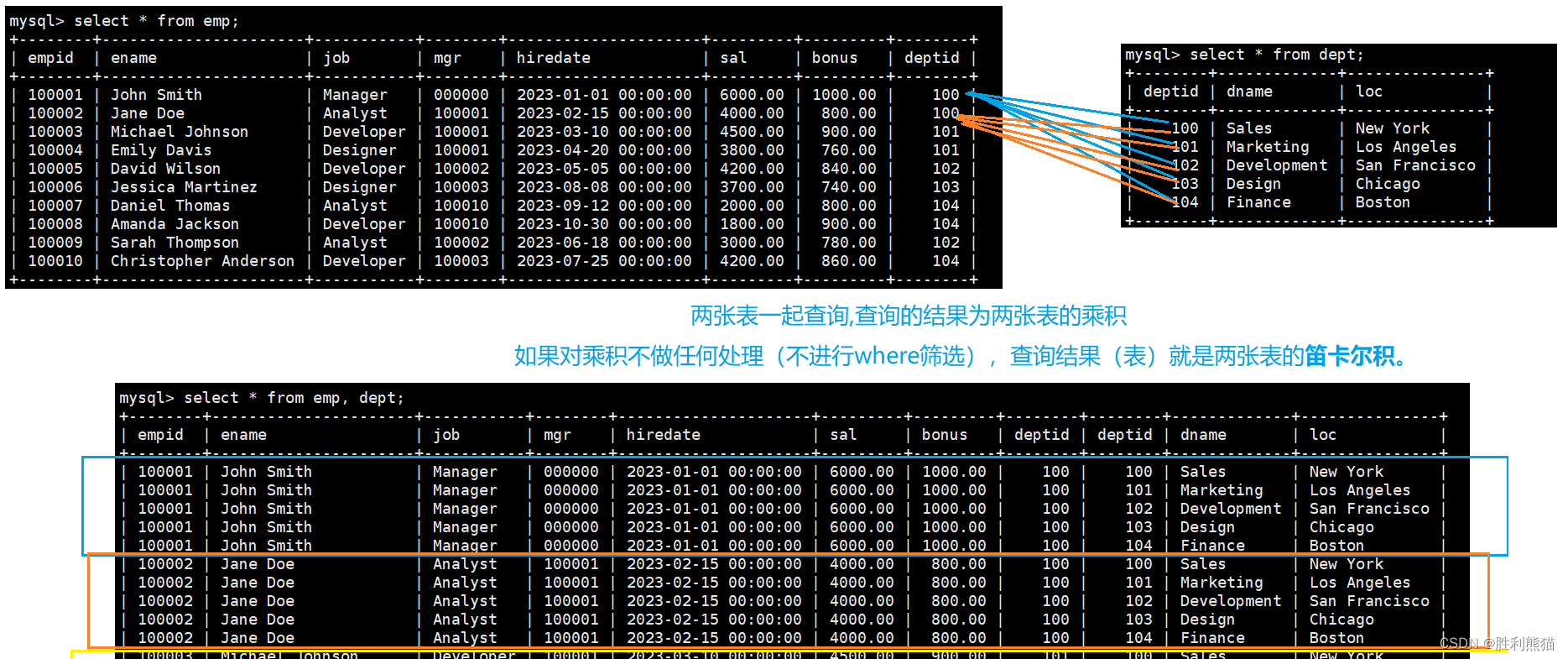
显示部门号为100的部门名,员工名和工资
-- 笛卡尔积:先将部门名,员工名和工资整合到一个表
-- where emp.deptid = dept.deptid 员工与部门相对应
mysql> select * from emp, dept where emp.deptid = dept.deptid;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+--------+-------------+---------------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid | deptid | dname | loc |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+--------+-------------+---------------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 100 | Sales | New York |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 100 | Sales | New York |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 101 | Marketing | Los Angeles |
| 100004 | Emily Davis | Designer | 100001 | 2023-04-20 00:00:00 | 3800.00 | 760.00 | 101 | 101 | Marketing | Los Angeles |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 | 102 | Development | San Francisco |
| 100006 | Jessica Martinez | Designer | 100003 | 2023-08-08 00:00:00 | 3700.00 | 740.00 | 103 | 103 | Design | Chicago |
| 100007 | Daniel Thomas | Analyst | 100010 | 2023-09-12 00:00:00 | 2000.00 | 800.00 | 104 | 104 | Finance | Boston |
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 | 104 | Finance | Boston |
| 100009 | Sarah Thompson | Analyst | 100002 | 2023-06-18 00:00:00 | 3000.00 | 780.00 | 102 | 102 | Development | San Francisco |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 | 104 | Finance | Boston |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+--------+-------------+---------------+
10 rows in set (0.00 sec)
-- 筛选部门号为100
mysql> select * from emp, dept where emp.deptid = dept.deptid and emp.deptid = 100;
+--------+------------+---------+--------+---------------------+---------+---------+--------+--------+-------+----------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid | deptid | dname | loc |
+--------+------------+---------+--------+---------------------+---------+---------+--------+--------+-------+----------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 100 | Sales | New York |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 100 | Sales | New York |
+--------+------------+---------+--------+---------------------+---------+---------+--------+--------+-------+----------+
2 rows in set (0.00 sec)
-- 单表操作:筛选我们需要信息
mysql> select dname, ename, sal from emp, dept where emp.deptid = dept.deptid and emp.deptid = 100;
+-------+------------+---------+
| dname | ename | sal |
+-------+------------+---------+
| Sales | John Smith | 6000.00 |
| Sales | Jane Doe | 4000.00 |
+-------+------------+---------+
2 rows in set (0.00 sec)
显示各个员工的姓名,工资,及工资级别
-- 先将员工的姓名,工资,及工资级别放在一张表
-- where sal between losal and hisal:员工工资与级别相对应才有意义
mysql> select * from emp, salgrade where sal between losal and hisal;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+-------+-------+-------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid | grade | losal | hisal |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+-------+-------+-------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 | 5 | 5001 | 6000 |
| 100002 | Jane Doe | Analyst | 100001 | 2023-02-15 00:00:00 | 4000.00 | 800.00 | 100 | 3 | 3001 | 4000 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 | 4 | 4001 | 5000 |
| 100004 | Emily Davis | Designer | 100001 | 2023-04-20 00:00:00 | 3800.00 | 760.00 | 101 | 3 | 3001 | 4000 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 | 4 | 4001 | 5000 |
| 100006 | Jessica Martinez | Designer | 100003 | 2023-08-08 00:00:00 | 3700.00 | 740.00 | 103 | 3 | 3001 | 4000 |
| 100007 | Daniel Thomas | Analyst | 100010 | 2023-09-12 00:00:00 | 2000.00 | 800.00 | 104 | 1 | 1000 | 2000 |
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 | 1 | 1000 | 2000 |
| 100009 | Sarah Thompson | Analyst | 100002 | 2023-06-18 00:00:00 | 3000.00 | 780.00 | 102 | 2 | 2001 | 3000 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 | 4 | 4001 | 5000 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+-------+-------+-------+
-- 单表操作:筛选员工的姓名,工资,及工资级别
10 rows in set (0.00 sec)
mysql> select ename, sal, grade from emp, salgrade where sal between losal and hisal;
+----------------------+---------+-------+
| ename | sal | grade |
+----------------------+---------+-------+
| John Smith | 6000.00 | 5 |
| Jane Doe | 4000.00 | 3 |
| Michael Johnson | 4500.00 | 4 |
| Emily Davis | 3800.00 | 3 |
| David Wilson | 4200.00 | 4 |
| Jessica Martinez | 3700.00 | 3 |
| Daniel Thomas | 2000.00 | 1 |
| Amanda Jackson | 1800.00 | 1 |
| Sarah Thompson | 3000.00 | 2 |
| Christopher Anderson | 4200.00 | 4 |
+----------------------+---------+-------+
10 rows in set (0.00 sec)
三、自连接
上面我们看了对不同的表求笛卡尔积,那么同一张表能否对自己求笛卡尔积?
-- 好像不可以?
mysql> select * from salgrade, salgrade;
ERROR 1066 (42000): Not unique table/alias: 'salgrade'
-- 不是不可以,而是两张表同名,MySQL无法区分,因此只要对一张表重命名即可
mysql> select * from salgrade, salgrade tb2;
+-------+-------+-------+-------+-------+-------+
| grade | losal | hisal | grade | losal | hisal |
+-------+-------+-------+-------+-------+-------+
| 1 | 1000 | 2000 | 1 | 1000 | 2000 |
| 2 | 2001 | 3000 | 1 | 1000 | 2000 |
| 3 | 3001 | 4000 | 1 | 1000 | 2000 |
| 4 | 4001 | 5000 | 1 | 1000 | 2000 |
| 5 | 5001 | 6000 | 1 | 1000 | 2000 |
| 1 | 1000 | 2000 | 2 | 2001 | 3000 |
| 2 | 2001 | 3000 | 2 | 2001 | 3000 |
| 3 | 3001 | 4000 | 2 | 2001 | 3000 |
| 4 | 4001 | 5000 | 2 | 2001 | 3000 |
| 5 | 5001 | 6000 | 2 | 2001 | 3000 |
| 1 | 1000 | 2000 | 3 | 3001 | 4000 |
| 2 | 2001 | 3000 | 3 | 3001 | 4000 |
| 3 | 3001 | 4000 | 3 | 3001 | 4000 |
| 4 | 4001 | 5000 | 3 | 3001 | 4000 |
| 5 | 5001 | 6000 | 3 | 3001 | 4000 |
| 1 | 1000 | 2000 | 4 | 4001 | 5000 |
| 2 | 2001 | 3000 | 4 | 4001 | 5000 |
| 3 | 3001 | 4000 | 4 | 4001 | 5000 |
| 4 | 4001 | 5000 | 4 | 4001 | 5000 |
| 5 | 5001 | 6000 | 4 | 4001 | 5000 |
| 1 | 1000 | 2000 | 5 | 5001 | 6000 |
| 2 | 2001 | 3000 | 5 | 5001 | 6000 |
| 3 | 3001 | 4000 | 5 | 5001 | 6000 |
| 4 | 4001 | 5000 | 5 | 5001 | 6000 |
| 5 | 5001 | 6000 | 5 | 5001 | 6000 |
+-------+-------+-------+-------+-------+-------+
25 rows in set (0.00 sec)
以上就是自连接,就是在同一张表连接查询。
那么自连接有什么意义呢?下面我们根据示例来了解
显示员工Amanda Jackson的上级领导的编号和姓名(mgr是员工领导的编号–empno)
-- 自连接
-- where t1.mgr = t2.empid: 员工与自己的领导信息放到一张表
mysql> select * from emp t1, emp t2 where t1.mgr = t2.empid;
-- 单表查询:筛选员工
mysql> select * from emp t1, emp t2 where t1.mgr = t2.empid and t1.ename = 'Amanda Jackson';
+--------+----------------+-----------+--------+---------------------+---------+--------+--------+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid | empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------+-----------+--------+---------------------+---------+--------+--------+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 | 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------+-----------+--------+---------------------+---------+--------+--------+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
1 row in set (0.00 sec)
-- 单表查询:筛选需要的信息
mysql> select t2.empid, t2.ename from emp t1, emp t2 where t1.mgr = t2.empid and t1.ename = 'Amanda Jackson';
+--------+----------------------+
| empid | ename |
+--------+----------------------+
| 100010 | Christopher Anderson |
+--------+----------------------+
1 row in set (0.00 sec)
-- 当然这里也可以使用子查询
mysql> select empid from emp where ename = 'Amanda Jackson';
+--------+
| empid |
+--------+
| 100008 |
+--------+
1 row in set (0.00 sec)
mysql> select empid, ename from emp where empid = (select empid from emp where ename = 'Amanda Jackson');
+--------+----------------+
| empid | ename |
+--------+----------------+
| 100008 | Amanda Jackson |
+--------+----------------+
1 row in set (0.00 sec)
四、子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
单行子查询
子查询结果为单列中的一行
显示Amanda Jackson同一部门的员工
mysql> select * from emp where deptid = (select deptid from emp where ename = 'Amanda Jackson');
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| 100007 | Daniel Thomas | Analyst | 100010 | 2023-09-12 00:00:00 | 2000.00 | 800.00 | 104 |
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
3 rows in set (0.00 sec)
-- 子查询结果为一列中的一行
mysql> select deptid from emp where ename = 'Amanda Jackson';
+--------+
| deptid |
+--------+
| 104 |
+--------+
1 row in set (0.00 sec)
多行子查询
子查询结果为单列中的多行
in关键字: 查询和100号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含100号部门自己的
-- 子查询结果为一列中的多行
mysql> select job from emp where deptid = 100;
+---------+
| job |
+---------+
| Manager |
| Analyst |
+---------+
2 rows in set (0.00 sec)
-- 使用 in 关键字判断 job 是否在select查询的结果表中
mysql> select ename, job, sal, deptid from emp where job in (select job from emp where deptid = 100);
+----------------+---------+---------+--------+
| ename | job | sal | deptid |
+----------------+---------+---------+--------+
| John Smith | Manager | 6000.00 | 100 |
| Jane Doe | Analyst | 4000.00 | 100 |
| Daniel Thomas | Analyst | 2000.00 | 104 |
| Sarah Thompson | Analyst | 3000.00 | 102 |
+----------------+---------+---------+--------+
4 rows in set (0.00 sec)
-- 不包含100号部门自己
mysql> select ename, job, sal, deptid from emp where job in (select job from emp where deptid = 100) and deptid <>100;
+----------------+---------+---------+--------+
| ename | job | sal | deptid |
+----------------+---------+---------+--------+
| Daniel Thomas | Analyst | 2000.00 | 104 |
| Sarah Thompson | Analyst | 3000.00 | 102 |
+----------------+---------+---------+--------+
2 rows in set (0.00 sec)
all关键字: 显示工资比部门104的所有员工的工资高的员工的姓名、工资和部门号
-- 可以是max函数求出104部门所有员工最高工资
mysql> select max(sal) from emp where deptid = 104;
+----------+
| max(sal) |
+----------+
| 4200.00 |
+----------+
1 row in set (0.00 sec)
-- 下面sal直接判断大小
mysql> select ename, sal, deptid from emp where sal > (select max(sal) from emp where deptid = 104);
+-----------------+---------+--------+
| ename | sal | deptid |
+-----------------+---------+--------+
| John Smith | 6000.00 | 100 |
| Michael Johnson | 4500.00 | 101 |
+-----------------+---------+--------+
2 rows in set (0.00 sec)
-- 也可以先查询104部门所有员工工资:单列多行结果
mysql> select sal from emp where deptid = 104;
+---------+
| sal |
+---------+
| 2000.00 |
| 1800.00 |
| 4200.00 |
+---------+
3 rows in set (0.00 sec)
-- 使用 all 关键字, 也就是所有的, 这里表示sal > select查询结果表中的所有列
mysql> select ename, sal, deptid from emp where sal > all(select sal from emp where deptid = 104);
+-----------------+---------+--------+
| ename | sal | deptid |
+-----------------+---------+--------+
| John Smith | 6000.00 | 100 |
| Michael Johnson | 4500.00 | 101 |
+-----------------+---------+--------+
2 rows in set (0.00 sec)
any关键字: 显示工资比部门104的任一员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
(注意注意注意:任一,所有选项中任何一个成立)
-- 先查询104部门所有员工工资:单列多行结果
mysql> select sal from emp where deptid = 104;
+---------+
| sal |
+---------+
| 2000.00 |
| 1800.00 |
| 4200.00 |
+---------+
3 rows in set (0.00 sec)
-- 比任何一个大就可以
mysql> select ename, sal, deptid from emp where sal > any(select sal from emp where deptid = 104);
+----------------------+---------+--------+
| ename | sal | deptid |
+----------------------+---------+--------+
| John Smith | 6000.00 | 100 | -- > 4200
| Jane Doe | 4000.00 | 100 | -- > 2000
| Michael Johnson | 4500.00 | 101 |
| Emily Davis | 3800.00 | 101 |
| David Wilson | 4200.00 | 102 |
| Jessica Martinez | 3700.00 | 103 |
| Daniel Thomas | 2000.00 | 104 | -- > 1800
| Sarah Thompson | 3000.00 | 102 |
| Christopher Anderson | 4200.00 | 104 |
+----------------------+---------+--------+
9 rows in set (0.00 sec)
多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句
查询和Amanda Jackson的部门和岗位完全相同的所有雇员,不含Amanda Jackson本人
-- 多列单行子查询:部门,岗位
mysql> select deptid, job from emp where ename = 'Amanda Jackson';
+--------+-----------+
| deptid | job |
+--------+-----------+
| 104 | Developer |
+--------+-----------+
1 row in set (0.00 sec)
-- 使用 in 关键字判断(也可以使用 = )
mysql> select * from emp where (deptid, job) in (select deptid, job from emp where ename = 'Amanda Jackson');
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
2 rows in set (0.00 sec)
-- 由于只有一行,可以使用 = 判断多列相等
mysql> select * from emp where (deptid, job) = (select deptid, job from emp where ename = 'Amanda Jackson');
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| 100008 | Amanda Jackson | Developer | 100010 | 2023-10-30 00:00:00 | 1800.00 | 900.00 | 104 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
2 rows in set (0.00 sec)
mysql> select * from emp where (deptid, job) in (select deptid, job from emp where ename = 'Amanda Jackson') and ename <> 'Amanda Jackson';
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+--------+--------+
1 row in set (0.00 sec)
在from子句中使用子查询
子查询语句出现在from子句中。我们把一个子查询当做一个临时表使用。
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
-- 查找各个部门的平均工资:子查询结果不就是一张表吗(逻辑上,看起来)
mysql> select deptid, avg(sal) from emp group by deptid;
+--------+-------------+
| deptid | avg(sal) |
+--------+-------------+
| 100 | 5000.000000 |
| 101 | 4150.000000 |
| 102 | 3600.000000 |
| 103 | 3700.000000 |
| 104 | 2666.666667 |
+--------+-------------+
5 rows in set (0.00 sec)
-- 多表笛卡尔积,将员工信息与平均工资放到一张表(同一行)
-- where emp.deptid = tmp.deptid:与自己的部门相对应(每次求笛卡尔积都需要这样判断一次,否则查询出来的结果大多是无意义的)
mysql> select ename, emp.deptid, sal, myavg
-> from emp, (select deptid, avg(sal) myavg from emp group by deptid) tmp
-> where emp.deptid = tmp.deptid;
+----------------------+--------+---------+-------------+
| ename | deptid | sal | myavg |
+----------------------+--------+---------+-------------+
| John Smith | 100 | 6000.00 | 5000.000000 |
| Jane Doe | 100 | 4000.00 | 5000.000000 |
| Michael Johnson | 101 | 4500.00 | 4150.000000 |
| Emily Davis | 101 | 3800.00 | 4150.000000 |
| David Wilson | 102 | 4200.00 | 3600.000000 |
| Jessica Martinez | 103 | 3700.00 | 3700.000000 |
| Daniel Thomas | 104 | 2000.00 | 2666.666667 |
| Amanda Jackson | 104 | 1800.00 | 2666.666667 |
| Sarah Thompson | 102 | 3000.00 | 3600.000000 |
| Christopher Anderson | 104 | 4200.00 | 2666.666667 |
+----------------------+--------+---------+-------------+
10 rows in set (0.00 sec)
-- 筛选工资 > 部门平均工资的员工
mysql> select ename, emp.deptid, sal, myavg
-> from emp, (select deptid, avg(sal) myavg from emp group by deptid) tmp
-> where emp.deptid = tmp.deptid and sal > myavg;
+----------------------+--------+---------+-------------+
| ename | deptid | sal | myavg |
+----------------------+--------+---------+-------------+
| John Smith | 100 | 6000.00 | 5000.000000 |
| Michael Johnson | 101 | 4500.00 | 4150.000000 |
| David Wilson | 102 | 4200.00 | 3600.000000 |
| Christopher Anderson | 104 | 4200.00 | 2666.666667 |
+----------------------+--------+---------+-------------+
4 rows in set (0.00 sec)
-- myavg小数位过多,可以 format 格式化一下
mysql> select ename, emp.deptid, sal, format(myavg, 2) salavg
-> from emp, (select deptid, avg(sal) myavg from emp grouup by deptid) tmp
-> where emp.deptid = tmp.deptid and sal > myavg;
+----------------------+--------+---------+----------+
| ename | deptid | sal | salavg |
+----------------------+--------+---------+----------+
| John Smith | 100 | 6000.00 | 5,000.00 |
| Michael Johnson | 101 | 4500.00 | 4,150.00 |
| David Wilson | 102 | 4200.00 | 3,600.00 |
| Christopher Anderson | 104 | 4200.00 | 2,666.67 |
+----------------------+--------+---------+----------+
4 rows in set (0.00 sec)
查找每个部门工资最高的人的姓名、工资、部门、最高工资
-- 子查询:查找deptid, maxsal
-- 笛卡尔积:将员工信息与最高工资放到一张表中进行查询,通过where进行筛选
mysql> select ename, sal, emp.deptid, maxsal
-> from emp, (select deptid, max(sal) maxsal from emp group by deptid) as tmp
-> where emp.deptid = tmp.deptid and sal = maxsal;
+----------------------+---------+--------+---------+
| ename | sal | deptid | maxsal |
+----------------------+---------+--------+---------+
| John Smith | 6000.00 | 100 | 6000.00 |
| Michael Johnson | 4500.00 | 101 | 4500.00 |
| David Wilson | 4200.00 | 102 | 4200.00 |
| Jessica Martinez | 3700.00 | 103 | 3700.00 |
| Christopher Anderson | 4200.00 | 104 | 4200.00 |
+----------------------+---------+--------+---------+
5 rows in set (0.00 sec)
显示每个部门的信息(部门名,编号,地址)和人员数量
-- dept.* : dept表的所有列
mysql> select dept.*, 人员数量
-> from dept, (select deptid, count(*) 人员数量 from emp group by deptid) tmp
-> where dept.deptid = tmp.deptid;
+--------+-------------+---------------+--------------+
| deptid | dname | loc | 人员数量 |
+--------+-------------+---------------+--------------+
| 100 | Sales | New York | 2 |
| 101 | Marketing | Los Angeles | 2 |
| 102 | Development | San Francisco | 2 |
| 103 | Design | Chicago | 1 |
| 104 | Finance | Boston | 3 |
+--------+-------------+---------------+--------------+
5 rows in set (0.00 sec)
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
将工资大于4000或职位是MANAGER的人找出来
-- 工资大于4000
mysql> select * from emp where sal > 4000;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
4 rows in set (0.00 sec)
-- 职位是MANAGER
mysql> select * from emp where job = 'Manager';
+--------+------------+---------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+------------+---------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 000000 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
+--------+------------+---------+--------+---------------------+---------+---------+--------+
1 row in set (0.00 sec)
-- union:求并集,去重
mysql> select * from emp where job = 'Manager' union select * from emp where sal > 4000;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 0 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
4 rows in set (0.00 sec)
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
-- union all :求并集,不去重
mysql> select * from emp where job = 'Manager' union all select * from emp where sal > 4000;
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| empid | ename | job | mgr | hiredate | sal | bonus | deptid |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
| 100001 | John Smith | Manager | 0 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100001 | John Smith | Manager | 0 | 2023-01-01 00:00:00 | 6000.00 | 1000.00 | 100 |
| 100003 | Michael Johnson | Developer | 100001 | 2023-03-10 00:00:00 | 4500.00 | 900.00 | 101 |
| 100005 | David Wilson | Developer | 100002 | 2023-05-05 00:00:00 | 4200.00 | 840.00 | 102 |
| 100010 | Christopher Anderson | Developer | 100003 | 2023-07-25 00:00:00 | 4200.00 | 860.00 | 104 |
+--------+----------------------+-----------+--------+---------------------+---------+---------+--------+
5 rows in set (0.00 sec)
总结
MySQL下一切皆表,select查询结果也可以当做一张表,多表查询结果同样是一张表,因此只要掌握了单表查询并且能够合理得将多表合并为单表,查询就会十分简单。
需要查询的信息在多张表中:使用笛卡尔积将多表合并为单表,然后在单表中查找。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!