【Datawhale 大模型基础】第十章 大模型的 Adaptation
第十章 大模型的 Adaptation
This blog is based on datawhale files and a nice survey.
Following pre-training, LLMs can develop general capabilities for addressing various tasks. However, an increasing body of research indicates that the abilities of LLMs can be further tailored to specific objectives. This blog will present two primary methods for adapting pre-trained LLMs: instruction tuning and alignment tuning. The former primarily seeks to enhance or unlock the capabilities of LLMs, while the latter aims to align the behaviors of LLMs with human values or preferences. Additionally, this blog will also explore efficient tuning and quantization for model adaptation in resource-constrained environments. And this topic contains so much knowledge that for further study, can see the survey.
10.1 Instruction Tuning
Essentially, instruction tuning involves fine-tuning pre-trained LLMs using a set of formatted instances in natural language, which is closely related to supervised fine-tuning and multi-task prompted training. To carry out instruction tuning, the first step is to gather or create instances formatted as instructions. These formatted instances are then used to fine-tune LLMs in a supervised learning manner, such as training with sequence-to-sequence loss. Following instruction tuning, LLMs can exhibit enhanced abilities to generalize to unseen tasks, even in multilingual settings.
And Instruction Tuning contains:
-
Formatted Instance Construction
- Formatting NLP Task Datasets
- Formatting Daily Chat Data
- Formatting Synthetic Data
- Key Factors for Instance Construction
- Scaling the instructions
- Formatting design
-
Instruction Tuning Strategies
- Balancing the Data Distribution
- Combining Instruction Tuning and Pre-Training
- Multi-stage Instruction Tuning
- Other Practical Tricks
- Efficient training for multi-turn chat data
- Establishing self-identification for LLM
-
The Effect of Instruction Tuning
- Performance Improvement
- Task Generalization
- Domain Specialization
-
Empirical Analysis for Instruction Tuning
- Task-specific instructions are better suited for the QA environment but may not be applicable in a chat context
- Increasing the intricacy and variety of instructions results in enhanced model performance
- A larger model size results in improved performance in following instructions
10.2 Alignment Tuning
This section initially provides an overview of alignment, including its definition and criteria, then delves into the acquisition of human feedback data for aligning LLMs, and ultimately explores the pivotal technique of reinforcement learning from human feedback (RLHF) for alignment tuning.
Alignment Tuning contains:
-
Alignment Criteria
- Helpfulness
- Honesty
- Harmlessness
-
Collecting Human Feedback
- Human Labeler Selection
- Human Feedback Collection
- Ranking-based approach
- Question-based approach
- Rule-based approach
-
Reinforcement Learning from Human Feedback
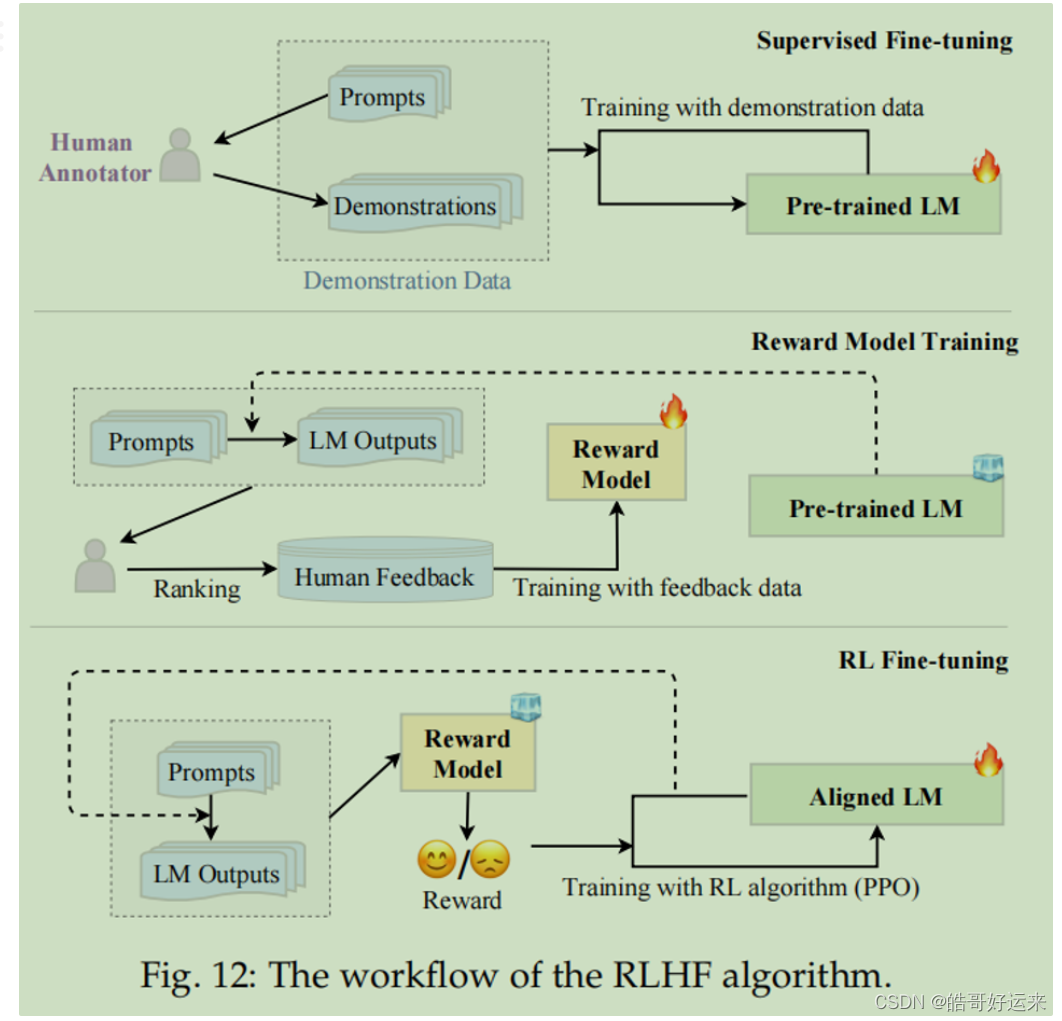
10.3 Parameter-Efficient Fine-Tuning
In prior research, there has been significant focus on parameter-efficient fine-tuning, which seeks to minimize the number of trainable parameters while maintaining optimal performance.
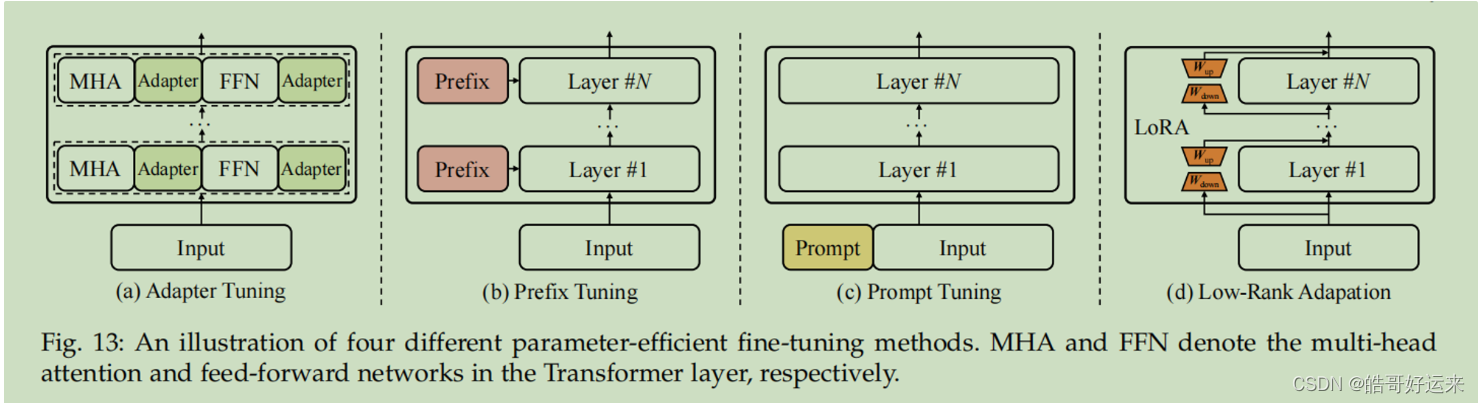
- Adapter Tuning
- Prefix Tuning
- Prompt Tuning
- Low-Rank Adaptation (LoRA)
10.4 Memory-Efficient Model Adaptation
Because of the substantial quantity of model parameters, LLMs require a significant memory footprint for inference, rendering deployment in real-world applications costly.
- Post-Training Quantization (PTQ)
- Mixed-precision decomposition
- Fine-grained quantization
- Balancing the quantization difficulty
- Layerwise quantization
- Other Quantization Methods
- Efficient fine-tuning enhanced quantization
- Quantization-aware training (QAT) for LLMs
- Important Findings from Existing Work
- INT8 weight quantization frequently produces excellent results for LLMs, whereas the effectiveness of lower precision weight quantization relies on specific methods.
- Quantizing activations is more challenging than quantizing weights
- Efficient fine-tuning enhanced quantization is a good option to enhance the performance of quantized LLMs
In the end, I collect some surveys about this topic, readers interested in this field can further read:
| Domain | Title | Paper URL | Project URL | Release Month |
|---|---|---|---|---|
| Instruction Tuning | Are Prompts All the Story? No. A Comprehensive and Broader View of Instruction Learning | https://arxiv.org/pdf/2303.10475.pdf | https://github.com/RenzeLou/awesome-instruction-learning | 2023.03 |
| Instruction Tuning | Instruction Tuning for Large Language Models: A Survey | https://arxiv.org/pdf/2308.10792.pdf | None | 2023.08 |
| Instruction Tuning | Vision-Language Instruction Tuning: A Review and Analysis | https://arxiv.org/pdf/2311.08172.pdf | https://github.com/palchenli/VL-Instruction-Tuning | 2023.11 |
| Human Alignment for LLM | Aligning Large Language Models with Human: A Survey | https://arxiv.org/pdf/2307.12966.pdf | https://github.com/GaryYufei/AlignLLMHumanSurvey | 2023.07 |
| Human Alignment for LLM | From Instructions to Intrinsic Human Values – A Survey of Alignment Goals for Big Model | https://arxiv.org/pdf/2308.12014.pdf | https://github.com/ValueCompass/Alignment-Goal-Survey | 2023.08 |
| Human Alignment for LLM | Large Language Model Alignment: A Survey | https://arxiv.org/pdf/2309.15025.pdf | None | 2023.09 |
| Human Alignment for LLM | AI Alignment: A Comprehensive Survey | https://arxiv.org/pdf/2310.19852 | https://www.alignmentsurvey.com/ | 2023.10 |
| Efficient LLMs | The Efficiency Spectrum of Large Language Models: An Algorithmic Survey | https://arxiv.org/pdf/2310.10844.pdf | https://github.com/tding1/Efficient-LLM-Survey | 2023.12 |
| Efficient LLMs | Efficient Large Language Models: A Survey | https://arxiv.org/pdf/2312.03863 | https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey | 2023.12 |
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!