批量归一化
2024-01-09 10:55:12
参考李沐老师的动手深度学习,只作为个人笔记.
文章目录
前言
训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手。 本节将介绍批量规范化(batch normalization),这是一种流行且有效的技术,可持续加速深层网络的收敛速度。?
一、为什么要批量归一化
- 损失函数出现最后,后面的层训练较快.
- 数据在最底部
- 底部的层训练较慢
- 底部层一变化,所有都得跟着变
- 最后的那些层需要重新学习多次
- 导致收敛变慢
1.为什么底部训练模型较慢?
答:因为随着神经网络的加深,数据在下面损失函数在上面,在反向传播时,从上面开始往下传,
梯度在上面的时候比较大越往下,梯度就越容易变小,这就导致上面层的梯度相对于下面层的梯度大,则上面的层收敛更快,下面的层收敛更慢。
2.为什么底部层一变话,所有都得跟着变?
答:因为模型开始是先前向传播在后向传播,下面层权重更新,上面的层就得更新。
3.为什么最后的那些层需要重新学习多次?
答:跟问题1一样.
4.导致收敛变慢?
答:跟问题1一样。
我们可以在学习底部层的时候避免变化顶部层吗?
二、批量归一化
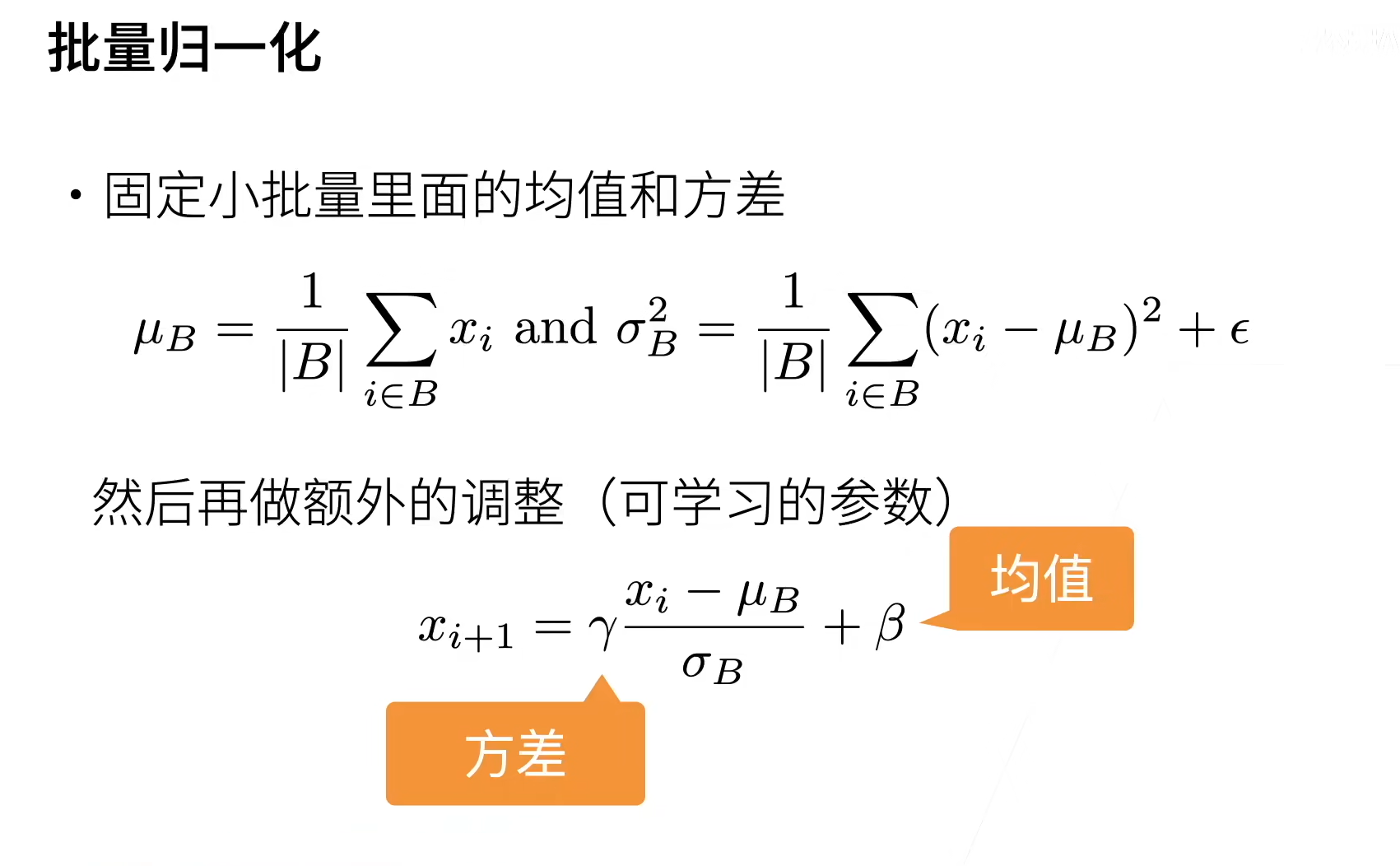
三、批量归一化层

我个人的理解就是把每个特征归一化,对于全连接每列就是特征,对于卷积我们是图片所以特征就是通道维,每个像素点就是一个特征。
总结
- 批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加快收敛速度,但一般不改变模型精度
文章来源:https://blog.csdn.net/qq_55383558/article/details/135470953
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!