【数据库】MySQL锁
一、锁的基本概念
1、锁的定义
锁是协调多个进程或线程并发访问数据库资源的一种机制。
MySQL中的锁是在服务器层或者存储引擎层实现的,保证了数据访问的一致性与有效性。但加锁是消耗资源的,锁的各种操作,包括获得锁、检测锁是否已解除、释放锁等 ,都会增加系统的开销。
2、锁的分类
MySQL锁可以按模式分类为:乐观锁与悲观锁。按粒度分可以分为全局锁、表级锁、页级锁、行级锁。按属性可以分为:共享锁、排它锁。按状态分为:意向共享锁、意向排它锁。按算法分为:间隙锁、临键锁、记录锁。
二、全局锁
1、定义
全局锁就是对整个数据库实例加锁。
2、使用全局锁
要使用全局锁,则要执行这条命令:
flush tables with read lock?执行后,整个数据库就处于只读状态了,这时其他线程执行以下操作,都会被阻塞:
- 对数据的增删改操作,比如 insert、delete、update等语句;
- 对表结构的更改操作,比如 alter table、drop table 等语句。
3、释放全局锁
如果要释放全局锁,则要执行这条命令:
unlock tables当会话断开了,全局锁也会被自动释放。
4、应用场景
全局锁主要应用于做全库逻辑备份,这样在备份数据库期间,不会因为数据或表结构的更新,而出现备份文件的数据与预期的不一样。
假设如果在全库逻辑备份期间,有用户购买了一件商品,一般购买商品的业务逻辑是会涉及到多张数据库表的更新,比如在用户表更新该用户的余额,然后在商品表更新被购买的商品的库存。如果在备份用户表和商品表之间,有用户购买了商品。
这种情况下,备份的结果是用户表中该用户的余额并没有扣除,但是商品表中该商品的库存被减少了,如果后面用这个备份文件恢复数据库数据的话,用户钱没少,而库存少了,等于用户白嫖了一件商品。
所以,在全库逻辑备份期间,加上全局锁,就不会出现上面这种情况了。
【缺点】:
如果在主库上备份,那么在备份期间都不能执行更新,业务基本上就能停止。?
如果在从库上备份,那么备份期间从库不能执行主库同步过来的binlog,会导致主从延迟。
【全局锁影响业务的解决方案】:
如果数据库的引擎支持的事务支持可重复读的隔离级别,那么在备份数据库之前先开启事务,会先创建 Read View,然后整个事务执行期间都在用这个 Read View,而且由于 MVCC 的支持,备份期间业务依然可以对数据进行更新操作。
因为在可重复读的隔离级别下,即使其他事务更新了表的数据,也不会影响备份数据库时的 Read View,这就是事务四大特性中的隔离性,这样备份期间备份的数据一直是在开启事务时的数据。
备份数据库的工具是 mysqldump,在使用 mysqldump 时加上?–single-transaction?参数的时候,就会在备份数据库之前先开启事务。这种方法只适用于支持「可重复读隔离级别的事务」的存储引擎。
InnoDB 存储引擎默认的事务隔离级别正是可重复读,因此可以采用这种方式来备份数据库。
但是,对于 MyISAM 这种不支持事务的引擎,在备份数据库时就要使用全局锁的方法。
?三、表级锁
MySQL 里面表级别的锁有这几种:
- 表锁;
- 元数据锁(MDL);
- 意向锁;
- AUTO-INC 锁;
1、表锁
表锁是指对一整张表加锁。MyISAM (默认锁)与 InnoDB 都支持表级锁定。
- 读锁(read lock),也叫共享锁(shared lock)
针对同一份数据,多个读操作(select)可以同时进行而不会互相影响
- 写锁(write lock),也叫排他锁(exclusive lock)
当前操作没完成之前,会阻塞其它读(select)和写操作(update、insert、delete)
【表锁的创建】
//表级别的共享锁,也就是读锁;
lock table t_student read;
//表级别的独占锁,也就是写锁;
lock table t_stuent write;【表锁的释放】
unlock tables?此命令会释放当前会话的所有表锁。
【优缺点】
优点:开销小、加锁快、无死锁
缺点:表锁的粒度大,发生锁冲突概率大,会影响并发性能(低)。
【建议】
MyISAM的读写锁调度是写优先,这也是MyISAM不适合做写为主表的引擎,因为写锁以后,其它线程不能做任何操作,大量的更新使查询很难得到锁,从而造成永远阻塞。
【示例演示】
(1) 表锁的读锁示例
| session01?? ? | session02 |
| lock table t_student read;// 上读锁 | |
| select * from t_student; // 可以正常读取 | select * from t_student;// 可以正常读取 |
| update t_student set name = 3 where id =2; // 报错,因被上读锁不能写操作 | update t_student set name = 3 where id =2; // 被阻塞 |
| unlock tables;// 解锁 | |
| update teacher set name = 3 where id =2;// 更新操作成功 |
(2) 表锁的写锁示例
| session01? | ? ?session02 |
| lock table t_student ?write;// 上写锁 | |
| select * from t_student ; // 可以正常读取 | select * from t_student ;// 被阻塞 |
| update t_student set name = 3 where id =2; // 可以正常更新操作?? | update t_student set name = 4 where id =2; // 被阻塞 |
| unlock tables;// 解锁 | |
| select * from t_student ;// 读取成功 | |
| update t_student set name = 4 where id =2; // 更新操作成功 |
2、元数据锁(MDL,metadata lock)
MDL主要作用是维护表元数据的数据一致性,在表上有活动事务(显式或隐式)的时候,不可以对元数据进行写入操作。因此从MySQL5.5版本开始引入了MDL锁,来保护表的元数据信息,用于解决或者保证DDL操作与DML操作之间的一致性。
我们不需要显式的使用 MDL,因为当我们对数据库表进行操作时,会自动给这个表加上 MDL:
- 对一张表进行 DML操作时,加的是?MDL 读锁;
- 对一张表进行 DDL操作(表结构变更操作)时,加的是?MDL 写锁;
总结:读读共享,读写互斥,写写互斥
当有线程在执行 select 语句( 加 MDL 读锁)的期间,如果有其他线程要更改该表的结构( 申请 MDL 写锁),那么将会被阻塞,直到执行完 select 语句( 释放 MDL 读锁)。
反之,当有线程对表结构进行变更( 加 MDL 写锁)的期间,如果有其他线程执行了 CRUD 操作( 申请 MDL 读锁),那么就会被阻塞,直到表结构变更完成( 释放 MDL 写锁)。
MDL 不需要显式调用,那它是在什么时候释放的?
MDL 是在事务提交后才会释放,这意味着事务执行期间,MDL 是一直持有的。
那如果数据库有一个长事务(所谓的长事务,就是开启了事务,但是一直还没提交),那在对表结构做变更操作的时候,可能会发生意想不到的事情,比如下面这个顺序的场景:
- 首先,线程 A 先启用了事务(但是一直不提交),然后执行一条 select 语句,此时就先对该表加上 MDL 读锁;
- 然后,线程 B 也执行了同样的 select 语句,此时并不会阻塞,因为「读读」并不冲突;
- 接着,线程 C 修改了表字段,此时由于线程 A 的事务并没有提交,也就是 MDL 读锁还在占用着,这时线程 C 就无法申请到 MDL 写锁,就会被阻塞,
那么在线程 C 阻塞后,后续有对该表的 select 语句,就都会被阻塞,如果此时有大量该表的 select 语句的请求到来,就会有大量的线程被阻塞住,这时数据库的线程很快就会爆满了。
为什么线程 C 因为申请不到 MDL 写锁,而导致后续的申请读锁的查询操作也会被阻塞?
这是因为申请 MDL 锁的操作会形成一个队列,队列中写锁获取优先级高于读锁,一旦出现 MDL 写锁等待,会阻塞后续该表的所有 DML操作。
所以为了能安全的对表结构进行变更,在对表结构变更前,先要看看数据库中的长事务,是否有事务已经对表加上了 MDL 读锁,如果可以考虑 kill 掉这个长事务,然后再做表结构的变更。
3、意向锁
为了支持在不同粒度上进行加锁操作,InnoDB存储引擎支持一种额外的锁方式,称之为意向锁。意向锁是将锁定的对象分为多个层次,意向锁意味着事务希望在更细粒度上进行加锁。
InnoDB存储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁。设计目的主要是为了在一个事务中揭示下一行将被请求的锁类型。其支持两种意向锁:
-
意向共享锁(IS Lock),事务想要获得一张表中某几行的共享锁。
-
意向排他锁(IX Lock),事务想要获得一张表中某几行的排他锁。
如果没有「意向锁」,那么加「排他表锁」时,就需要遍历表里所有记录,查看是否有记录存在行排他锁,这样效率会很慢。
那么有了「意向锁」,由于在对记录加行排他锁前,先会加上表级别的意向排他锁,那么在加「独占表锁」时,直接查该表是否有意向排他锁,如果有就意味着表里已经有记录被加了行排他锁,这样就不用去遍历表里的记录。
所以,意向锁的目的是为了快速判断表里是否有记录被加锁。
由于InnoDB存储引擎默认支持的是行级别的锁,因此意向锁其实不会阻塞除全表扫以外的任何请求。故表级意向锁与行级锁的兼容性如下图所示。
| 表级IS | 表级IX | 表级S | 表级X | |
| 表级IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| 表级IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| 行级S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| 行级X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
快速记忆:意向锁之间不会发生冲突,表锁和行锁满足读读共享、读写互斥、写写互斥。
4、自增锁(AUTO-INC)
表里的主键通常都会设置成自增的,这是通过对主键字段声明?AUTO_INCREMENT?属性实现的。
之后可以在插入数据时,可以不指定主键的值,数据库会自动给主键赋值递增的值,这主要是通过?AUTO-INC 锁实现的。
AUTO-INC 锁是特殊的表锁机制,锁不是再一个事务提交后才释放,而是再执行完插入语句后就会立即释放。
在插入数据时,会加一个表级别的 AUTO-INC 锁,然后为被?AUTO_INCREMENT?修饰的字段赋值递增的值,等插入语句执行完成后,才会把 AUTO-INC 锁释放掉。
那么,一个事务在持有 AUTO-INC 锁的过程中,其他事务的如果要向该表插入语句都会被阻塞,从而保证插入数据时,被?AUTO_INCREMENT?修饰的字段的值是连续递增的。
但是, AUTO-INC 锁在对大量数据进行插入的时候,会影响插入性能,因为另一个事务中的插入会被阻塞。
因此, 在 MySQL 5.1.22 版本开始,InnoDB 存储引擎提供了一种轻量级的锁来实现自增。
一样也是在插入数据的时候,会为被?AUTO_INCREMENT?修饰的字段加上轻量级锁,然后给该字段赋值一个自增的值,就把这个轻量级锁释放了,而不需要等待整个插入语句执行完后才释放锁。
InnoDB 存储引擎提供了个 innodb_autoinc_lock_mode 的系统变量,是用来控制选择用 AUTO-INC 锁,还是轻量级的锁。
- 当 innodb_autoinc_lock_mode = 0,就采用 AUTO-INC 锁,语句执行结束后才释放锁;
- 当 innodb_autoinc_lock_mode = 2,就采用轻量级锁,申请自增主键后就释放锁,并不需要等语句执行后才释放。
- 当 innodb_autoinc_lock_mode = 1:
- 普通 insert 语句,自增锁在申请之后就马上释放;
- 类似 insert … select 这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
当 innodb_autoinc_lock_mode = 2 是性能最高的方式,但是当搭配 binlog 的日志格式是 statement 一起使用的时候,在「主从复制的场景」中会发生数据不一致的问题。
举个例子,考虑下面场景:
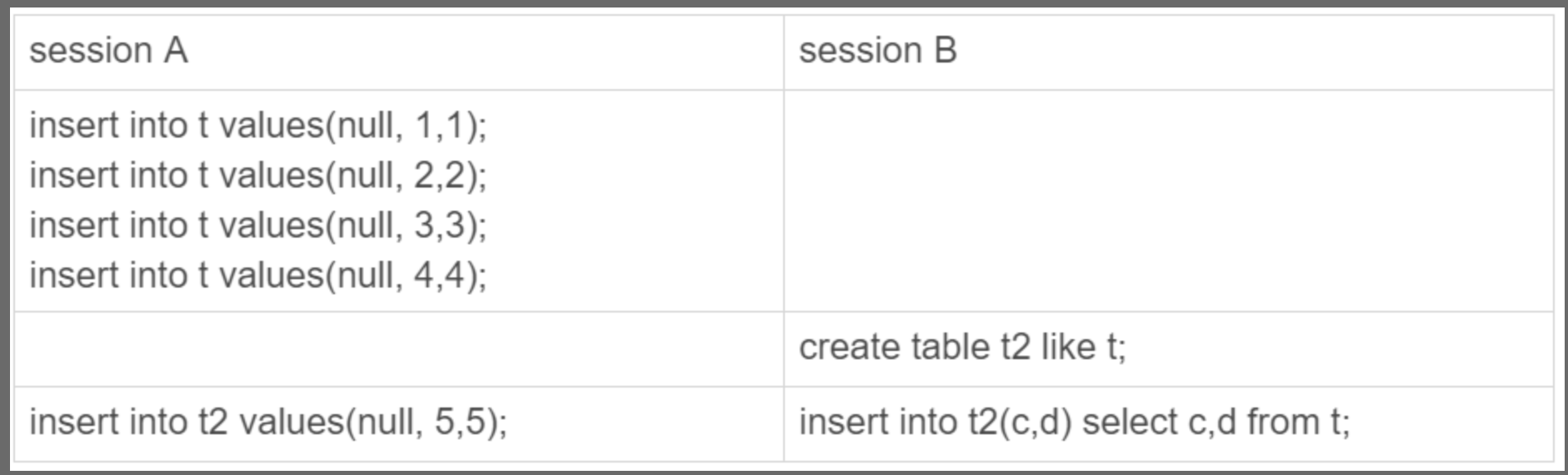
session A 往表 t 中插入了 4 行数据,然后创建了一个相同结构的表 t2,然后两个 session 同时执行向表 t2 中插入数据。
如果 innodb_autoinc_lock_mode = 2,意味着「申请自增主键后就释放锁,不必等插入语句执行完」。那么就可能出现这样的情况:
- session B 先插入了两个记录,(1,1,1)、(2,2,2);
- 然后,session A 来申请自增 id 得到 id=3,插入了(3,5,5);
- 之后,session B 继续执行,插入两条记录 (4,3,3)、 (5,4,4)。
可以看到,session B 的 insert 语句,生成的 id 不连续。
当「主库」发生了这种情况,binlog 面对 t2 表的更新只会记录这两个 session 的 insert 语句,如果 binlog_format=statement,记录的语句就是原始语句。记录的顺序要么先记 session A 的 insert 语句,要么先记 session B 的 insert 语句。
但不论是哪一种,这个 binlog 拿去「从库」执行,这时从库是按「顺序」执行语句的,只有当执行完一条 SQL 语句后,才会执行下一条 SQL。因此,在从库上「不会」发生像主库那样两个 session 「同时」执行向表 t2 中插入数据的场景。所以,在备库上执行了 session B 的 insert 语句,生成的结果里面,id 都是连续的。这时,主从库就发生了数据不一致。
要解决这问题,binlog 日志格式要设置为 row,这样在 binlog 里面记录的是主库分配的自增值,到备库执行的时候,主库的自增值是什么,从库的自增值就是什么。
所以,当 innodb_autoinc_lock_mode = 2 时,并且 binlog_format = row,既能提升并发性,又不会出现数据一致性问题。
四、行级锁
1、行锁
行锁就是锁住表里面的一行数据。
行级锁是粒度最低的锁,发生锁冲突的概率也最低、并发度最高。但是加锁慢、开销大,容易发生死锁现象。
MySQL中只有InnoDB支持行级锁(默认锁),而 MyISAM 引擎并不支持行级锁。
行级锁分为共享锁(S,读锁)和排他锁(X,写锁)。
- 读锁(read lock),也叫共享锁(shared lock)
允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
- 写锁(write lock),也叫排他锁(exclusive lock)
允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享锁和排他锁
//对读取的记录加共享锁
select ... lock in share mode;
//对读取的记录加独占锁
select ... for update;【示例演示】
(1)行级读锁示例
| session01?? | ?session02 |
| begin; | |
| select * from t_student where id = 2 lock in share mode;// 上读锁 | |
| select * from t_student where id = 2; // 可以正常读取 | |
| update t_student set name = 3 where id =2; // 可以更新操作 | ?updatet_student set name = 5 where id =2; // 被阻塞 |
| commit; | |
| update t_student set name = 5 where id =2;// 更新操作成功 |
(2)行级写锁示例
| session01? | ?session02 |
| begin; | |
| select * from t_student where id = 2 for update; // 上写锁 | |
| select * from t_student? where id = 2; // 可以正常读取 | |
| update t_student set name = 3 where id =2; // 可以更新操作? | update t_student set name = 5 where id =2; // 被阻塞 |
| rollback; | |
| update t_student set name = 5 where id =2; // 更新操作成功 |
【行级锁算法】
行级锁的类型主要有三类(或者说是三种行级锁的算法):
- Record Lock,记录锁,也就是仅仅把一条记录锁上;
- Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身;
- Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身
2、?Record Lock(记录锁)
单个行记录上的锁。Record Lock总是会去锁住索引记录,如果InnoDB存储引擎表建立的时候没有设置任何一个索引,这时InnoDB存储引擎会使用隐式的主键来进行锁定
select * from t_test where id = 1 for update;上述就是对 t_test 表中主键 id 为 1 的这条记录加上 X 型的记录锁,这样其他事务就无法对这条记录进行修改了。
【注意】
id?列必须为唯一索引列或主键列,否则上述语句加的锁就会变成临键锁。
同时查询语句必须为精准匹配(=),不能为?>、<、like等,否则也会退化成临键锁
3、Gap Lock(间隙锁)
当我们用范围条件而不是等值条件检索数据,并请求共享或排他锁时,InnoDB对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”加锁,这种锁机制就是所谓的间隙锁。
SELECT * FROM table WHERE id BETWEN 1 AND 10 FOR UPDATE;上述所有 id 在(1,10)区间内的记录行都会被锁住,所有id 为 2、3、4、5、6、7、8、9 的数据行的插入会被阻塞,但是 1 和 10 两条记录行并不会被锁住。
间隙锁用于解决并发访问的幻读问题。
4、Next-Key Lock(临键锁)
临键锁,是记录锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。
每个数据行上的非唯一索引列上都会存在一把临键锁,当某个事务持有该数据行的临键锁时,会锁住一段左开右闭区间的数据。需要强调的一点是,InnoDB 中行级锁是基于索引实现的,临键锁只与非唯一索引列有关,在唯一索引列(包括主键列)上不存在临键锁。
InnoDB 在Repeatable Read隔离级别下,Next-key Lock 算法是默认的行记录锁定算法。
5、行级锁加锁规则(难点)
MySQL 行级锁的加锁规则。
【唯一索引等值查询】
- 当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。
- 当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会退化成「间隙锁」。
【非唯一索引等值查询】
- 当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。
- 当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
非唯一索引和主键索引的范围查询的加锁规则不同之处在于:
- 唯一索引在满足一些条件的时候,索引的 next-key lock 退化为间隙锁或者记录锁。
- 非唯一索引范围查询,索引的 next-key lock 不会退化为间隙锁和记录锁。
五、死锁
死锁指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。
死锁产生的条件:
1. 互斥条件:一个资源每次只能被一个进程使用
2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放
3. 不剥夺条件:进程已获得的资源,在没有使用完之前,不能强行剥夺
4. 循环等待条件:多个进程之间形成的一种互相循环等待的资源的关系
解决方法:
1. 查看死锁:show engine innodb status \G
2. 自动检测机制,超时自动回滚代价较小的事务(innodb_lock_wait_timeout 默认50s)
3. 人为解决,kill阻塞进程(show processlist)
4. wait for graph 等待图(主动检测)
六、总结
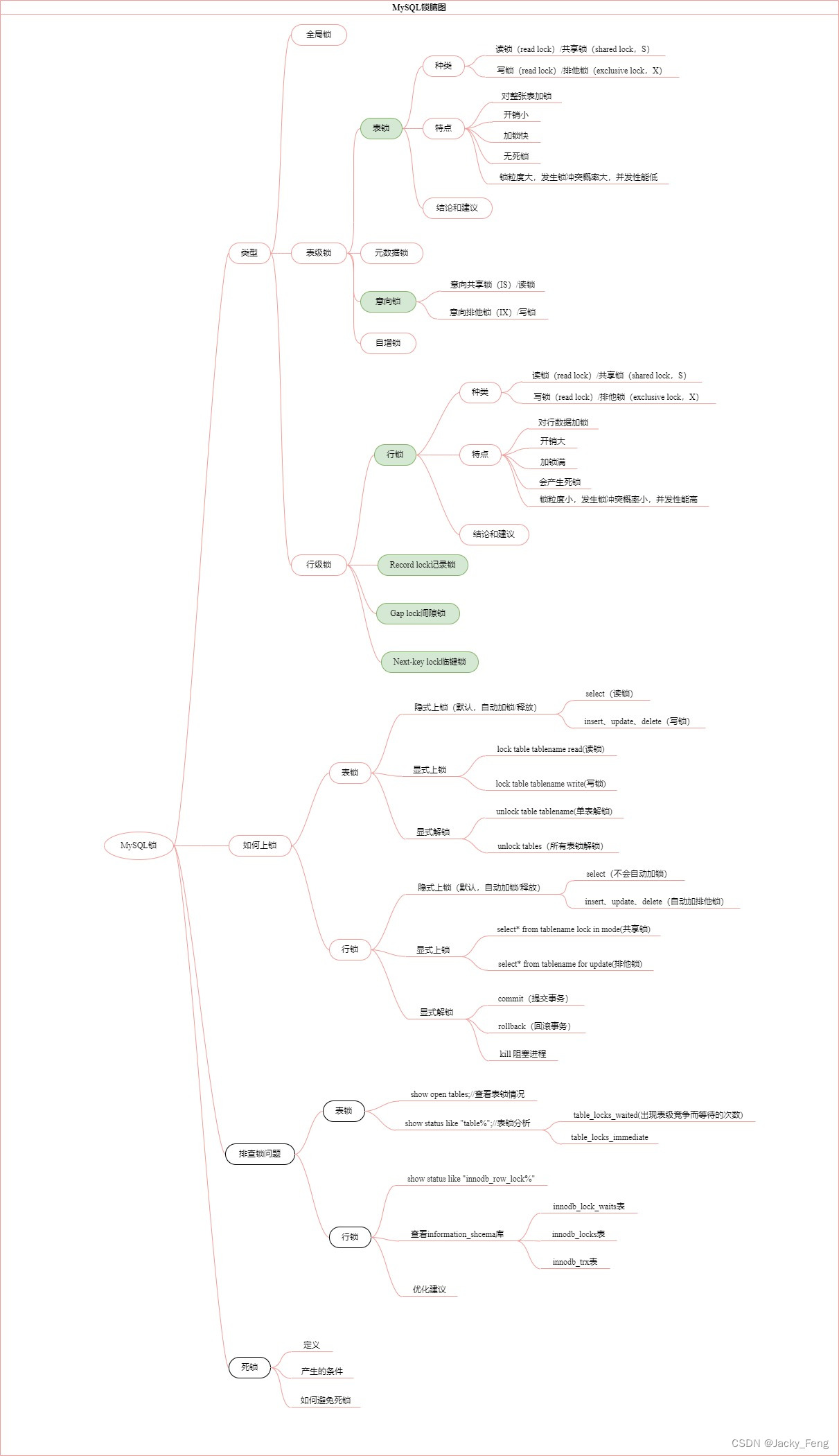
参考链接:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!