1-03C语言超基础语法
一、概述
为了更好的进行后续的课程,避免出现"老师,我还没学过的东西,你怎么直接用?"诸如此类疑问,本小节就诞生了。
实际上,整个第一个大章节的所有小节都是"C语言基础语法",作为这些基础语法中的又"基础"语法,我给该小节起了一个名字——“C语言超基础语法”。
本小节主要涉及注释、函数、变量、printf函数等语法,其中部分语法我们仅做简单了解,后续小节会详细讲。
二、注释
**注释(comment)**对于任何编程语言来说,都是基本概念,C语言当然也不例外。
注释用于解释代码,使得代码更容易被理解。注释会被编译器自动忽略,所以任何注释都不会影响程序的输出或运行。C语言有两种类型的注释:
-
单行注释。使用"//" 开头。从双斜杠开始,直到该行结束的所有内容都会被视为注释。单行注释仅能使某一行成为注释。
代码块 1. 单行注释演示代码
// 这个函数用于计算两个整数的和 int add(int a, int b) { return a + b; // 返回两个整数的和 } -
**多行注释(也叫块注释)。从"/*“开始到”*/"**结束,中间的部分都属于注释。这种注释可以跨越多行。
代码块 2. 多行注释演示代码
/* * 这是一个多行注释。 * 这里可以写很多行的解释和描述。 */ int x = 5; /* 这也是一个多行注释,但多行注释尽量不要用于注释单行 */
注释本身是一个简单的语法,也不参与编译不影响程序执行,基本是一个随意使用的语法。下面提一些小的注意事项:
- 无论什么注释,写在代码上面的注释总是为了解释下面的一句或者一段代码。
- 单行注释通常用于解释一行代码或代码的一个小段。
- 多行注释通常用于解释一个代码块、一个结构,比如解释一个函数。
- 不要嵌套多行注释。
注意事项
-
单行注释实际上直到C99才成为C语言的官方标准语法,在较早的C标准中,如C90,单行注释并不是合法的C语言语法。所以如果你希望需要与旧版C标准兼容,最好避免使用单行注释,并使用多行注释来进行注释。(但一般不需要,我们前面提到过常用的C语言版本当中,最旧的就是C99)
-
多行注释推荐使用以下格式,可读性会更好:
代码块 3. 多行注释推荐形式
/* * 有星号 * 有星号 * 有星号 */不推荐下面的方式:
多行注释不推荐形式
代码块 4.
/* 没有星号 没有星号 没有星号 */当然两种方式都是符合语法的,即便用第二种方式也是完全正确的。
-
某些公司团队,在写单行注释时会在**“//双斜杠”**后面加一个空格再写注释信息。但也可以不加,这是根据个人或团队的编程风格和偏好而定的。
代码块 5. 单行注释的风格
// 这是一个单行注释,后面有空格 int x = 10; //这是一个单行注释,后面没有空格 int y = 20;
三、关键字与标识符
首先,我们要明确,C语言是严格区分大小写的编程语言。
关键字和标识符和注释一样,也几乎是所有编程语言都有的概念。
关键字(keyword):在语法标准中规定的,在代码中具有特殊意义和用途的一个单词,我们称之为关键字。
标识符(identifier):在代码中肯定会出现诸如变量名、函数名等字符串,这些字符串就是标识符。
简单来说,关键字就是代码中具有特殊语法含义的单词,而标识符就是代码中用于命名的字符串。
1. C语言常见关键字
C语言当中的常用关键字在C90版本就已经确定了,一共有32个,参考下列表格:
表 1. C语言常见关键字-表格(C90)
| 常见关键字 | |||
|---|---|---|---|
| auto | double | int | struct |
| break | else | long | switch |
| case | enum | register | typedef |
| char | extern | return | union |
| const | float | short | unsigned |
| continue | for | signed | void |
| default | goto | sizeof | volatile |
| do | if | static | while |
除此之外,C99新增了5个关键字,但不太常用。
表 2. C99新关键字
| _Bool | _Complex | _Imaginary | inline | restrict |
|---|---|---|---|---|
总结:
- C语言的关键字基本都是小写的英文单词,它们都具有预定的特殊含义,不能被程序员私自使用(不能作为标识符)。
- main函数的main字符串不是关键字,只是一个普通的标识符。当然这是一个特殊的,作为程序入口的函数名标识符。
2. 标识符的命名规范
标识符既然用于命名变量、函数等,那么就一定需要遵循一些规则,也就是命名规范。
对于C语言而言,我们把标识符的命名规范又分为两部分:
- 语法标准的强制要求
- 约定要求,更好的习惯要求
1.语法标准的强制要求
C语言标准中明确对标识符的命名,做了以下强制要求:
- 关键字不能作为标识符。
- 首字符:标识符的第一个字符必须是一个字母(大小写都可以)或下划线(_)。
- 组成:标识符可以由字母、数字或下划线组成。
- 对大小写敏感。num和Num是两个完全不同的标识符。
补充:
随着C语言的发展,一些非英文字符也可以放入标识符当中了。比如下列代码是完全可以通过编译,正常运行的:
代码块 6. 使用中文作为标识符-演示代码
#include <stdio.h
int main() {
int 我 = 100;
printf("%d", 我);
return 0;
}
这是因为,很多现代的C语言编译器能够处理非英文字符,从而允许它们作为标识符的组成。
但是,这会带来一些问题:
- 可读性的问题。一堆英文代码中出现非英文字符总是违和的。
- 兼容性问题。跨平台运行时无法识别这些字符怎么办?
- 非英文字符经常会引起"乱码"问题。
总之,C语言代码中的标识符禁止出现字母、数字以及下划线以外的字符。
2. 标识符命名的好习惯
基于以上强制要求的前提下,标识符的命名还有一套约定俗成的好习惯。这些好习惯虽然不是语法层面上强制的,但是我们要求大家必须遵守这些好习惯。
“C程序员的第一步,养成一个好的标识符命名习惯!”
好习惯实际上很多,需要靠长久的学习、实践以及积累。但最起码的,应该遵循以下原则:
- 使用合法的英文单词,除非迫不得已,禁止使用汉语拼音(特殊情况如baidu)。
- **见名知意是标识符命名的核心原则。**标识符的目的是命名,这个名字显然应该是一个描述性强的、易于理解的字符串。
- 命名风格。如果出现多个单词,保持所有单词字母小写,然后用下划线分隔的方式以示区分。比如my_name、team_num等。
这里给出一些优秀的标识符命名范例以及一些反例,请大家参考:
- 标识符应当是一个有意义的名字,见名知意。
- 优秀:total_amount、student_name、calculate_tax
- 反例:a、b、z、x、y、z
- 使用下划线以增加可读性:
- 优秀:load_file、user_name
- 反例:loadfile、username
- 不因由于缩写、简写导致歧义:
- 优秀:file_name、product_list
- 反例:fn、pl
- …
后续随着学习的推荐,我们会讲解更多标识符命名的好习惯,遵循这些规范有助于代码的可读性和可维护性。
能把标识符写好体现的是一个程序员的内功,这就是我们常说的**“好的代码是不需要过多注释的,代码是自解释的。”**
补充:驼峰命名法
在上面,我们提到了"下划线法"的命名风格,实际上在编程领域还有一种非常经典的命名法——驼峰命名法(Camel Case)。
1. 大驼峰命名法:每个单词的首字母都大写,包括第一个单词。如:MyComputer、Name
2. 小驼峰命名法:第一个单词首字母小写,之后每个单词的首字母都大写。如:myComputer、name
驼峰命名的风格更多在具有面向对象特性的语言中流行,比如C++、C#、Java等。在C语言编程中,虽然也可以使用这种命名风格,但是:
1. 一方面,C语言的官方标准库中,采取的也是"全小写字母 + 下划线分隔"的命名方式。官方的做法肯定是标准做法。
2. 另一方面,在C语言的传统和约定中,大写字母通常用于其他特定目的。比如宏定义和常量定义,要求全部大写等。
总之,建议大家在进行C语言编程时,涉及命名的:如标识符、文件名等,都使用全小写字母 + 下划线分隔的形式。在后续课程学习C++时,我们再考虑使用"驼峰命名法"。
下面这张图是一张在网络上广为流传的大厂程序员,有关标识符命名的"笑料图":
图 1. 天猫付款页面报错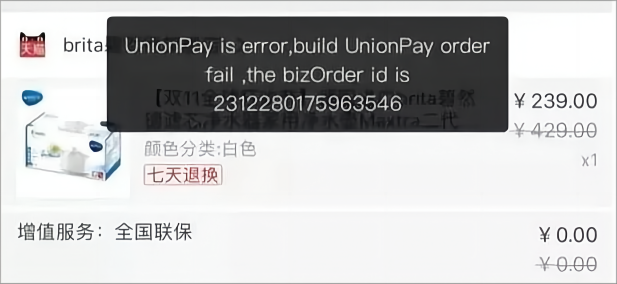
这是一个天猫商城结算时,合并订单联合支付的场景。这里程序员使用了一个标识符"UnionPay",其中Union有联合的意思,UnionPay表示联合支付。
但实际上UnionPay是一个专有名词,它专指中国银联支付。
显然这里程序员不是甩锅中国银联,而是错用了单词导致产生了误解,这里使用"CombinedPay"会更合适的。
四、常量与变量
很少有程序会像HelloWorld案例一样简单。大多数程序总会涉及到一些计算,计算就需要用到数据,因此程序需要能够存储和表示数据。和大多数编程一样,C语言中存储表示数据的方式即——常量与变量。其中:
- 常量指的是在程序运行过程中,取值绝不会发生改变的、甚至连改变可能性都没有的数据。
- 变量指的是在程序运行过程中,取值可以改变、具有改变可能性的数据。
1. 字面常量
在C语言当中,字面常量是常量的类型之一。
代码中直接出现的像"2,0.1"这样的数字以及双引号引起来的"hello world"字符串等,它们的取值可能改变吗?
完全不可能,所以它们就是常量,被称为"字面常量"。
字面常量可以用于给变量赋值,但它本身是不能赋值的。如:
代码块 7. 字面常量的使用
int num = 100;
// 2 = 3; 错误
// "Hello" = "World"; 错误
注意事项:
- 在C语言中,整数字面常量默认被视为
int类型。例如,5被视为int。 - 浮点数字面常量则默认被视为
double类型。例如,3.14被视为double。 - 这意味着在没有指定类型的情况下,整数和浮点数字面值会按照这些默认类型来处理。
- 一个浮点数字面值若希望被视为float,需要在字面值后面加一个"f"。
2. 变量
在上面我们已经给变量下了一个定义,但是一个比较抽象的概念定义。
为了让大家更好的理解变量,我们可以从计算机内存的角度理解变量:变量可以看成一个内存中存储数据的存储单元。
既然如此,那么一个变量就应该具有以下三要素:
- 为了方便程序员找到、使用这个存储单元,这个存储单元应该起个名字。这就是变量名,是标识符的一种。
- 存储单元中存储的取值到底是多少,如果不确定这一点变量毫无意义。这就是变量的取值。
- 存储单元"长"什么样子?在内存中占多少空间?存储数据,能存储什么数据?这就是变量的数据类型,数据类型决定了变量可以存储哪种类型的数据,以及存储这种数据会占用多少内存空间等。
所以变量的三要素就是:
- 变量名
- 取值
- 数据类型
1. 数据类型
数据类型的定义:
数据类型是编程语言中用于规范变量或表达式的性质的一个抽象概念。它确定了所存储数据的形式、大小和布局,并定义了可对该类型数据执行的操作集合。
这句话我们剥离本质,得到数据类型的定义:规定了一组合法的数据集合以及针对这组数据集合的合法操作。
数据类型 = 数据 + 操作。
在后续课程会详细讲解C语言的常用数据类型,本小节就以"int"和"float"为例子来帮助大家理解一下这个概念。
int(单词integer的缩写),是C语言当中常用的整数类型。一般而言,int类型的变量占用4个字节的内存空间,加上C语言中的整数默认是有符号整数,它的取值范围是**[-2^31, 2^31 - 1]**
除此之外,int还规定了该变量可以做加减乘除等操作,但显然没有求长度,求重量这样的操作。
float(单精度浮点数),是C语言当中常用的浮点数类型。简单来说,它可以存储带小数位的数,比如0.1,123.6,-0.123等。浮点数通常遵循IEEE754标准,float占用4个字节的内存空间。同时,float类型的变量也可以执行加减乘除等操作,当然也没有求长度,求重量这样的操作。
2. 变量的声明
要想在程序中使用一个变量,首先需要声明变量。声明变量的意义是确定变量的数据类型以及变量名。
局部变量的概念
在当下,我们只会使用一种在函数内部定义的变量——局部变量(Local Variables),关于局部变量我们在后面还会详细讲解它。
目前你仅需要知道:
1. 在C语言中,函数内部定义的变量就是局部变量。
2. 在C语言中,局部变量仅在定义它的"{}"内部生效。
3. 同一个"{}"内部不允许定义同名局部变量。
我们今天讲解的变量的声明,实际上是**“局部变量的声明”**。声明的语法实际上很简单:
代码块 8. 声明变量语法
int length;
float width;
第一条声明说明length是一个int类型变量,可以存储整数值,同时它还可以执行一些整型int可以执行的操作。
第二条声明说明width是一个float类型变量,可以存储浮点数值,同时它还可以执行一些浮点型float可以执行的操作。
从内存的角度来理解变量的声明(重要)
在一个C程序的编译阶段(程序未执行),当编译器编译到变量声明的语句时,编译器会识别变量的类型、名字等属性。待到程序运行,则会虚拟内存空间中为变量分配实际的空间。
对于一个局部变量而言,它是没有默认值的,如果不手动对它进行赋值,那么它的值是随机的、未定义的。也就是说,它的值究竟是多少,谁也不知道。
所以在C语言中,一个局部变量如果仅有声明,是不可用的。使用一个仅声明的局部变量,就是使用随机的、未定义的值,将会产生随机的、未定义的行为。
未定义行为对C程序而言是非常严重的错误,C程序员要十分小心,规避程序中的未定义行为。
3. 变量初始化
仅声明的局部变量是不可用的,在使用该局部变量之前,还需要初始化局部变量。**变量的初始化,可以视为第一次给变量赋值。**在C语言中,某些变量类型在编译过程会被赋予默认零值,具有默认初始化。但局部变量,并没有默认初始化,必须进行手动初始化赋值。
一个手动初始化的语法参考如下:
代码块 9. 变量初始化语法
int length = 100;
float width = 0.1f;
声明是,编译器为变量预分配了内存空间,而变量初始化是在程序运行时给予了变量一个初始值。
4. 变量的赋值
给变量赋值,最简单的做法,就是用一个赋值运算符"="连接一个字面常量取值,比如:
代码块 10. 变量的赋值语法(接上面)
// 给int类型的变量length赋值为100
length = 100;
// 给float类型的变量width赋值为0.1,注意float类型的浮点数常量需要后面加"f"
width = 0.1f;
5. 声明、初始化、赋值和定义(重要)
在C语言中,变量的声明、初始化、赋值和定义都有严格的定义,它们是截然不同的几个概念。在这里,我们做一下区分:
- 变量的声明:声明是给编译器看的,告诉编译器变量的类型和名字等信息,但变量的具体内存分配发生在运行时期。
- 变量的初始化:初始化是变量的第一次赋值。
- 变量的赋值:初始化一定是赋值,但赋值不是初始化。C语言中的赋值专指在变量已经初始化赋值以后,再次赋值。
变量的定义
1. 变量的定义是声明一个变量,并且为之分配内存空间的组合动作。
2. 变量的定义意味着,告诉编译器变量的类型和名称,而且在程序运行时要确定给此变量分配内存空间。
3. 很多同学,会被"变量的定义"这个概念搞混淆,它和"变量的声明"有什么区别呢?
1. 实际上,变量的定义一定是变量的声明。
2. 但变量的声明不一定就是变量的定义。也就是说,某些特殊的变量声明,在程序运行时期不会为此变量分配内存空间。(这里我们先挖个坑,随后课程填坑)
6. 一行执行多个操作
C语言允许一行声明多个变量,一行给多个变量赋值,一行进行多个变量的初始化。参考下面代码:
代码块 11. C语言一行操作多个变量
// 一行声明多个变量,表示这些变量的数据类型一致,但变量名不同
int height, length, width, volume;
float profit, loss;
// C语言允许一行给多个变量赋值(前提是已声明)
height = 100,loss = 100.1;
// C语言允许一行初始化多个变量,这些变量声明一致,所以数据类型一致
int a = 8, b = 12, c = 10;
这种一行执行多个操作,好处是简化代码,使得代码更紧凑。缺点是可读性不好,有时也会影响程序的Debug调试。
3. 变量的使用
以上概念理解后,我们就可以声明,赋值或者初始化一个变量,然后使用这个变量了。
基于int和float类型的变量,我们可以执行一些运算操作,比如:
代码块 13. 变量的使用
int height = 8;
int length = 12;
int width = 10;
// 计算体积
int volume = height * length * width;
4. 显示变量的取值
要想显示变量的取值,目前我们的做法是使用"printf"函数将变量的取值打印在控制台上。这个函数显然不是我们定义的,它来自C语言标准输入/输出库。
1. 预处理指令
细心的你应该早就发现了,我们上面写得所有代码的第一行都有一条:
1
#include <stdio.h
**在C程序当中,该行代码被称之为"预处理指令"。**它的作用是:为程序引入C语言标准输入/输出库的相关信息。
简单来说,没有这一行代码,代码当中的"printf"函数就不可用。
库(Library,一般简称lib)在任何编程语言当中都是很重要的概念。它通常就是由预先定义的数据、数据结构以及操作等组成的集合,使用者可以在不关心"库"内部设计细节的前提下,直接使用库中的资源。库的存在加速了开发过程,提高代码的可重用性和维护性。
在 C 语言中,库指的是一组预编译的代码片段,这些代码可以被用于执行特定的任务或者功能。
在C语言当中,头文件(.h文件)是库的主要存在形式之一,其中stdio.h(standard input/output,缩写成stdio),表示标准输入/输出库,它是一种函数库,包含但不仅限于以下内容:
1. 预定义的函数操作:"printf" 格式化输出,"scanf" 格式化输入等。
2. 预定义流:"stdin"标准输入流,通常关联到键盘,"stdout"标准输出流,通常关联到终端或命令行窗口(控制台)等。
不同编程语言的库肯定是不同的,使用方式也大相径庭。那么在C语言当中,如何使用库呢?
使用预处理指令:#include <xxx.h
2. printf函数
printf实际上并不是一个单词,而是词组"print formatted"的缩写,意为"格式化打印"。这个函数的主要任务是按照指定的格式输出数据,默认情况下是输出到控制台。在代码的首行使用对应预处理指令即可使用该函数。
该函数的具体使用,后续课程还会专门讲解,这里我们先讲两个基础的用法。
若想要显示一个int类型的数据,可以用:
代码块 14. printf显示整数数据
int num = 100;
printf("num = %d", num);
其中**%d**是占位符,它用来表示变量num的取值在前面字符串的位置。
上述代码运行的结果是:
num = 100
若想要显示一个float类型的数据,可以用:
代码块 15. printf显示浮点数数据
float num = 0.1;
printf("num = %f", num);
此时占位符就需要使用**%f**。
在默认情况下,"%f"会显示小数点后6位。也就是这段代码的结果是:
num = 0.100000
这在很多时候都不是我们想看到的,如果希望指定保留p位小数位数,可以把**“.p”**放在%和f的中间。
如希望保留两位小数位,可以写:
代码块 16. printf显示浮点数数据-保留2位小数
float num = 0.1;
printf("num = %.2f", num);
C 语言并没有限制printf可以显示变量的数量,我们可以同时显示多个变量的值:
代码块 17. printf输出多个变量值
int height = 10,length = 20, width = 30;
printf("Height: %d Length: %d Width: %d\n", height, length, width);
输出结果是:
Height: 10 Length: 20 Width: 30
五、函数简介
关于函数,后续会有专门的一个章节来详细讲解,在这里我们先了解一些基础的使用。
1. 什么是函数?
几乎所有的编程语言都有函数(或方法)的概念,在C程序中,函数尤为重要,因为C程序就是函数的集合。
那么什么是函数呢?
简单地说,函数可以看作是一个程序的子程序,一台大型机器中的“微型执行单元”:
- 输入:当你启动一个函数时,你通常会传递给它一些数据,这些数据被称为**“参数”**或“输入参数”。
- 处理:函数一旦接收到这些输入,它会根据内部的指令和逻辑进行处理和运算。
- 输出:处理完成后,函数通常会提供一个结果,这就是我们所说的**“返回值”**。
如下图所示:
图 2. 编程语言中的函数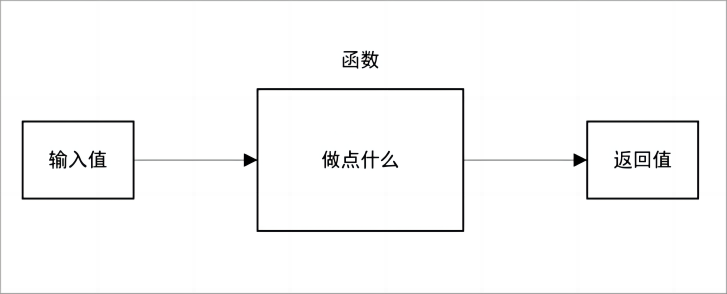
这实际上就是函数的三个基本特征:参数输入、功能执行以及输出返回值。
总之,函数是C语言编程中的基本组成单位。它是一个代码块,用于执行特定的任务,可以接收参数并返回一个值。
C语言中的函数分类
在C语言中,根据函数的来源,函数可以分为两大类:
1. **标准库函数**:这些函数属于C语言的标准库,例如 printf(), scanf(), sqrt() 等。为了调用这些函数,必须首先引入相应的头文件。
2. **用户定义函数**:由C程序员手动编写代码实现的函数。
但不论是来源于标准库还是由用户自定义,所有的函数在C语言中都遵循相同的基本原则和语法结构。
2. 函数的定义公式
通过上面的讲解,我们可以总结一下函数的写法公式:
代码块 18. 函数的定义公式
返回值类型 函数名(形参列表){
// 函数体
}
其中:
- 函数的返回值类型就填一个数据类型,比如我们上面提到的int和float。如果函数不需要返回值,可以用void作为返回值类型。
- 函数名是一个标识符,遵循命名规则即可。函数名是函数的唯一标识,这也是C语言比较特殊的地方。
- “(形参列表)“里的内容用于确定此函数需要什么参数数据输入。比如需要两个整数输入,就写”(int a, int b)”。同时在大括号里面还可以用a和b来使用传入函数的参数数据。
- 如果函数有返回值,那么"return + 返回值"会结束函数,并给出函数的返回值。注意函数返回值要和函数定义时的返回值类型对应。
记住以下几个概念:
- **函数体:**被"{}"包裹的就是函数体,注意此大括号不可省略。函数体就是函数实现的具体逻辑,函数做了什么。
- 函数头:身体上面的就是头,包括"返回值类型 函数名(形参列表)"统称函数头。函数头是函数定义的起始部分。
3. 写一个自己的函数
定义一个函数,求两个整数的和,并将这个和返回。怎么写呢?
如下:
代码块 19. 自定义一个函数求和
// 定义了一个叫add的函数,求两个整数的和
int add(int a, int b){
return a + b;
}
4. 注意事项
在当前,请大家把你自定义的函数,写在main函数代码位置的上面。具体原因我们后续课程再讲。
5. 调用函数
上面我们已经自己定义好了一个add函数 ,那我们需要怎样来使用它呢? add函数能直接运行嘛?
答案是不行的。
C程序的运行是从main函数开始的,所以必须在主函数中调用其他函数,此函数才能够执行。
add函数的签名是**“add(int a, int b)”**,所以我们在调用它时需要传入两个整数作为参数,代码如下:
代码块 20. 函数调用语法
#include <stdio.h
int add(int a, int b){
return a + b;
}
int main(void){
int result;
// 在main函数中调用
result = add(2, 3);
printf("result = %d", result);
return 0;
}
程序最终运行的结果是:
result = 5
六、主函数
在C语言中,主函数是一个特殊的函数,比如下面一个main函数:
代码块 21. 主函数的定义
int main() {
printf("hello world!\n");
return 0;
}
关于主函数,我们需要知道以下几点:
- **主函数是程序的入口,任何C程序的运行都是从主函数开始的。**C语言的这种设计在编程领域引领潮流,被许多后来的编程语言采用,例如C++、Java、C#以及Go等。
- 主函数在C程序执行时由操作系统自动调用,main虽然不是关键字,但此函数名是固定的,不能被修改。
- int 是 main 函数的返回值类型,表示该函数执行完毕后将返回一个整数值给操作系统。按照C语言标准,main函数应返回int类型的值,不要更改。
- 我们约定,main函数的返回值是0时表示程序正常终止,非0则表示程序意外终止。
- return表示终止函数。而main函数是程序的入口函数,终止它就意味着整个程序终止。
1. 关于main函数的形参
大家可以看到我们这里给出的main函数的定义为:
代码块 22. 无参main函数-代码示例
int main() {
// 函数体
}
但相信很多同学会在书籍、博客等地方看到以下定义:
代码块 23. void做形参的main函数-代码示例
int main(void) {
// 函数体
}
它们都用于定义C程序入口的主函数,那么它们有什么区别呢?
实际上就单纯的C语言环境而言,它们是一样的。但在C++当中,两者是有区别的:
int main():
1. 在C语言中,这种写法表示主函数不接受任何参数数据。
2. **在C++中,它表示主函数可以接受任意数量和类型的参数(这是C++的独特之处)。**
int main(void):
在C和C++中,都明确表示主函数不接受任何参数。
综上所述,我们给出以下结论和建议:
- 单纯的C语言代码中,二者没什么区别。
- 但考虑到C程序经常在C++编译器中编译运行,所以如果你的代码是纯粹的C语言,并且你明确知道 main 函数不应接收任何参数,应该使用 int main(void)。
- 这样做不仅符合C语言的标准,还能消除任何关于函数参数的歧义,特别是当你的代码在C++编译器中编译时。
- 在后续的课程中,一个C语言的函数,如果确定它不需要任何参数传入,请使用"(void)"!
关于main函数形参的补充:
操作系统在调用main函数时,是可以给main函数传参的,这就是命令行参数。当然若想要在调用main函数时,给main函数传参,main函数的形参就不能再使用void了。
这是后续课程一个非常重要的知识点,我们先挖个坑,后续课程再讲。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!