leecode-代码随想录-学习笔记1
编程语言基础课,重新学习
- 基础语法;
- ACM输入输出通用模板;
- 之前Java狂神说的学习笔记(但是还是按照编程习惯用了C++,感觉更底层好写代码)。
正式开始: 下面按照题目-我的解答思路和代码-代码随想录给出的讲解 的顺序写的,给出的讲解大部分是直接粘过来的,代码都是直接粘的,有的可能会加上自己的理解,当笔记记录的,欢迎讨论。
一、数组
思维上一般都不难,主要考察对代码的掌控能力。
1. 理论基础
- 数组在内存中的存储方式:是存放在连续内存空间上的相同类型数据的集合。
可以通过下标索引的方式获取到下标对应的数据。
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
(使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。)
-
数组的元素是不能删的,只能覆盖。
-
二维数组在内存的空间地址:
-
C++中二维数组在地址空间上是连续的。
-
像Java是没有指针的,同时也不对程序员暴露其元素的地址,寻址操作完全交给虚拟机。
2. 二分查找(二分法)
2.1 我的
题目很简单,但是太久不写了,还是有很多问题:
- 左右两个指向现在范围的应当是相等,而非相隔1,相等才能比较最后一个,因为最后这两个将指向同一个数。
- 因此下面通过的代码中对b==0也就是一个数的情况可以不考虑,因为包含在我们的判断中。
我的最终通过代码:
class Solution {
public:
int search(vector<int>& nums, int target) {
int flag=-1;
if(sizeof(nums)==0){
return flag;
}
int a=0;
int b=nums.size()-1;
int nb = b;
if(b==0){
if(target==nums[0]){
return 0;
}
}
// if(target<nums[a] or target>nums[b]){
// b=0;
// }
while(b>=a){
int mid=(b-a)/2+a;
if(target==nums[mid]){
flag = mid;
break;
}
else if(target>nums[mid]){
a=mid+1;
}else{
b=mid-1;
}
}
return flag;
}
};
2.2 随想录记录:
- 只知道必须是有序的,没有注意到元素必须是不重复的,二分查找不能返回;
- 大家写二分法经常写乱,主要是因为对区间的定义没有想清楚,区间的定义就是不变量。要在二分查找的过程中,保持不变量,就是在while寻找中每一次边界的处理都要坚持根据区间的定义来操作,这就是循环不变量规则。区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。
- [left, right] :
- while (left <= right) 要使用 <= ,因为left == right是有意义的,所以使用 <=
- if (nums[middle] > target) right 要赋值为 middle - 1,因为当前这个nums[middle]一定不是target,那么接下来要查找的左区间结束下标位置就是 middle - 1
- [left, right) :right初始等于长度值
- while (left < right),这里使用 < ,因为left == right在区间[left, right)是没有意义的
- if (nums[middle] > target) right 更新为 middle,因为当前nums[middle]不等于target,去左区间继续寻找,而寻找区间是左闭右开区间,所以right更新为middle,即:下一个查询区间不会去比较nums[middle]
- 两者的时间复杂度和空间复杂度相同:
- 时间复杂度:O(log n)
- 空间复杂度:O(1)
2.3 其他题目
2.3.1 搜索+插入
1. 我的
题目多了一个插入,也是有序无重复元素(符合二分法条件),也不太难
- 首先是正常二分法能找到的情况;
- 其次相当于目标是找到第一个比这个数大的数,区间左侧的数一定比这个值小,右侧的数一定比这个值大,因此只需要判断最后的值如果不相等,大于则返回当前位置,小于则需要加一。
- 最终还是忘了右值小于左值的情况,此时上一题中直接返回不存在,符合题意,但是这里需要将左值(这里是较大的值)返回。
最终通过的代码:
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int flag=0;
if(nums.size()==0){
return flag;
}
int a=0;
int b=nums.size()-1;
// if(target<nums[a] or target>nums[b]){
// b=0;
// }
while(b>a){
int mid=(b-a)/2+a;
if(target==nums[mid]){
flag = mid;
return flag;
}
else if(target>nums[mid]){
a=mid+1;
}else{
b=mid-1;
}
}
if(b==a){
if(target<=nums[b]){
flag = b;
}else{
flag = b+1;
}
}
else if(b<a){
flag = a;
}
return flag;
}
};
2. 代码随想录:
- 看到了题解的暴力方法才发现,如果不是放到二分法这里,直接看我肯定按照暴力方法写啊,暴力思路真简单,从头到尾找一遍,遇到大于等于的返回位置就行,都没有则应放最后。但是时间复杂度O(n),但是能通过给的样例。
- 以后大家只要看到面试题里给出的数组是有序数组,都可以想一想是否可以使用二分法。
- 同时题目还强调数组中无重复元素,因为一旦有重复元素,使用二分查找法返回的元素下标可能不是唯一的。
- 给的示例代码量更少,这里将思路精简了,要不返回等于的时候,要不返回right+1,因为如果没有相等的,right在最后会回到第一个比这个数小的位置(返回left-1不行,因为如果是比所有元素大,那么返回的应当是left本身,因此只能返回right,因为最小的可返回值是0)。
2.3.2 不止一个
1. 我的
首先第一个想法当然是暴力,有序的从头到尾来一遍就行。但是时间复杂度O(n),需要的是O(log n)。相当于先找区间所在的范围,然后分别在区间对半的两边找开始和结束,begin=end=mid:左边找开始,也就是第一个比这个数小的,小则移动left,相等则移动begin;右边找结束,也就是第一个比这个数大的,大则移动right,相等则移动end。
代码实现刚开始超出时间限制了,后来发现确实是有重复比较,因此设置两个_0来更新比较位置,已通过:
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int begin=-1;
int end=-1;
// if(nums.size()==0){
// return {begin, end};
// }
int a=0;
int b=nums.size()-1;
while(b>=a){
int mid=(b-a)/2+a;
if(target==nums[mid]){
begin=end=mid;
break;
}
else if(target>nums[mid]){
a=mid+1;
}else{
b=mid-1;
}
}
if(b==a){
return {begin, end};
}
else{
int begin0=begin-1;
int end0=end+1;
while(begin0>=a){
int mid=(begin0-a)/2+a;
if(target==nums[mid]){
begin=mid;
begin0=mid-1;
}
else{
a=mid+1;
}
}
while(b>=end0){
int mid=(b-end0)/2+end0;
if(target==nums[mid]){
end=mid;
end0=mid+1;
}else{
b=mid-1;
}
}
}
return {begin, end};
}
};
2. 代码随想录
- 扫描两遍,每次找一个边界,当不满足移动边界,满足则暂定当下值为边界,这样当得到的边界有正距离差那就证明存在。
- 但是给的方法找两遍欸,应该是不如我的方法快的吧,感觉还是我的方法好。
2.3.3 求整数平方根
1. 我的
- 相当于在一串升序且不重复数组中找到比目标值小一个的值
- 重点是考虑保留哪一个(下面是通过的代码,仔细想想其实保留left应该也是对的,方法2,证明了确实是对的,只是这样程序有不止一个出口)
# 方法1
class Solution {
public:
int mySqrt(int x) {
int flag=2;
if(x == 0){
return 0;
}else if(x<=3){
return 1;
}
long a=2;
long b=x/2;
while(b>a){
long mid=(b-a)/2+a;
if(x == mid * mid){
flag = mid;
break;
}
else if(x > mid * mid){
flag = mid;
a=mid+1;
}else{
b=mid-1;
}
}
if(a==b){
if(x >= a * a){
flag = a; //保留可能的最小的那一个
}
}
return flag;
}
};
# 方法2
class Solution {
public:
int mySqrt(int x) {
int flag=2;
if(x == 0){
return 0;
}else if(x<=3){
return 1;
}
long a=2;
long b=x/2;
while(b>=a){
long mid=(b-a)/2+a;
if(x == mid * mid){
flag = mid;
return flag;
}
else if(x > mid * mid){
flag = mid;
a=mid+1;
}else{
b=mid-1;
}
}
flag = b;
return flag;
}
};
2.3.4 完全平方数
1. 我的
- 比上一题还简单,考虑到0 1 2 3这几个,按特殊情况处理就好。
class Solution {
public:
bool isPerfectSquare(int num) {
if(num <= 1){
return true;
}else if(num<=3){
return false;
}
long a=2;
long b=num/2;
while(b>=a){
long mid=(b-a)/2+a;
if(num == mid * mid){
return true;
}
else if(num > mid * mid){
a=mid+1;
}else{
b=mid-1;
}
}
return false;
}
};
3. 移除元素(双指针法)
3.1题目
3.2 我的
思路是先排序后移动,但是这样也不快,因为位置都要换;
暴力就是找到一个移动一次,也不行;
之前学过类似的,已经忘了,确实记得有指针,忘了怎么用的了,看解析想起来了。
- 就是两个指针,一个指向当前需要被覆盖的,一个指向下一个需要检查的。
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int a=0;
int b=nums.size();
int num=0;
for(int i=0;i<b;i++){
if(nums[i]==val){
// a=i;
}else{
num++;
nums[a]=nums[i];
a++;
}
}
return num;
}
};
3.3 代码随想录
就是看解析想起来的方法
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
定义快慢指针
- 快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
- 慢指针:指向更新 新数组下标的位置
双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。
3.4 其他题目
3.4.1
1. 我的
和刚刚的方法一样,就是每一次循环换一下目标函数罢了。
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int a=1;
int b=nums.size();
int num=1;
int val=nums[0];
for(int i=1;i<b;i++){
if(nums[i]==val){
// a=i;
}else{
val=nums[i];
num++;
nums[a]=nums[i];
a++;
}
}
return num;
}
};
3.4.2
1. 我的
和之前的方法一样,就是将目标换为0,然后将后面的元素也换为0。
class Solution {
public:
void moveZeroes(vector<int>& nums) {
int a=0;
int b=nums.size();
int num=0;
for(int i=0;i<b;i++){
if(nums[i]==0){
num++;
// a=i;
}else{
nums[a]=nums[i];
a++;
}
}
for(int i=b-1;i>=b-num;i--){
nums[i]=0;
}
}
};
3.4.3
1. 我的
- 思路很简单,但是我忘了将num1>0加入第一个if如果不成功会运行下面的else!!不同要点的判别不要放在一个括号里。
class Solution {
public:
bool backspaceCompare(string s, string t) {
int num1=0;
int num2=0;
int a1=0;
int a2=0;
int b1=s.size();
int b2=t.size();
for(int i=0;i<b1;i++){
if(s[i]=='#'){
if(num1>0){
a1--;
num1--;
}
}else{
num1++;
s[a1]=s[i];
a1++;
}
}
for(int i=0;i<b2;i++){
// printf("%d,%d,%d",i,a2,num2);
if(t[i]=='#'){
if(num2>0){
a2--;
num2--;
}
}else{
num2++;
t[a2]=t[i];
a2++;
}
// printf("%d,%d,%d",i,a2,num2);
}
// printf("%d %d",num2,num1);
if(num1==num2){
for(int i=0;i<num1;i++){
if(s[i]!=t[i]){
return false;
}
}
}
else{
return false;
}
return true;
}
};
3.4.4
1. 我的
自己的方法可能导致负数里的大数字没有完全比较,看了一眼提示结合自己想的,应该在负数可能出现的范围内查找,也就是从0开始找到第一个比当前数小的停止,此前有比这个数大的就换回来,没有则这个数直接平方。
然后又思考了一下,我现在的想法是右边的一个一个往后移动,每一次放入应该的最大值,不是最大的就和最左的换,问题在于最左的换过一次后可能就不再是最大的了,因此应当在替换时替换到合适的位置。------超出时间限制。应该是插入到前面需要每次都测试一次的原因。
继续分析,后面几位比当前的值大,一定比之后的几个最右的数大,因此可以不移动而直接一同转移。------忽视了全是负数无法“掉头”的情况,分析半天,我这样的方法最终还是得排序。
不如空间换时间,直接构造一个新的数组,然后两头找大的放进去就行了。谁能想到想了这么久,是空间换时间呢
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
// // int b=0;
// int a=nums.size()-1;
// while(a>=0){
// if(abs(nums[a])>=abs(nums[0])){
// // printf("%d", nums[a]);
// nums[a] = pow(abs(nums[a]),2);
// // printf("%d", nums[a]);
// a--;
// }else{
// int temp=abs(nums[0]);
// int now=nums[a];
// nums[0]=nums[a];
// nums[a] = pow(temp,2);
// a--;
// int k=0;
// for(int b=1;b<a+1;b++){
// if(abs(now)<abs(nums[b])){
// k=b;
// }
// }
// //为了确保现在的0位就是最大的,还需要移过去k位
// for(int i=1;i<=k;i++){
// // temp=abs(nums[k]);
// // nums[k]=now;
// temp=abs(nums[i]);
// nums[i]=nums[a];
// now=nums[a];
// nums[a] = pow(temp,2);
// a--;
// //更新k值
// for(int j=k+1;j<a+1;j++){
// if(abs(now)<abs(nums[j])){
// k=j;
// }
// }
// }
// // nums[k]=now;
// }
// }
// return nums;
int n = nums.size();
vector<int>res(n);
int a=0;
int b=n-1;
for(int i=n-1;i>=0;i--){
if(abs(nums[a])<abs(nums[b])){
res[i]=pow(abs(nums[b]),2);
b--;
}else{
res[i]=pow(abs(nums[a]),2);
a++;
}
}
return res;
}
};
ps:复习排序方法
1.0 十大经典排序算法 | 菜鸟教程 (runoob.com)
4. 有序数组的平方(空间换时间)
4.1 我的
就还是上面那道题。
4.2 随想录记录
- 暴力:每个数平方之后,排个序。时间复杂度是 O(n + nlogn), 可以说是O(nlogn)的时间复杂度,但为了和下面双指针法算法时间复杂度有鲜明对比,我记为 O(n + nlog n)。
- 双指针法:数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。此时可以考虑双指针法了,i指向起始位置,j指向终止位置。时间复杂度为O(n),相对于暴力排序的解法O(n + nlog n)还是提升不少的。
- 不必太在意leetcode上执行用时,打败多少多少用户,这个就是一个玩具,非常不准确。
5. 长度最小的子数组(滑动窗口)
5.1 我的
- 第一想法是一个位置来,存放当前连续到的最大值,大于target了就找是不是最小长度。
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
int flag=0;
int num=n;
// vector<int>res(n);
for(int i=0;i<n;i++){
int now=0;
int sum=0;
for(int j=i;j<n;j++){
if(now>=num){
break;
}
sum+=nums[j];
now++;
if(sum>=target){
flag=1;
if(now<num){
num=now;
}
break;
}
}
}
if(flag==1){
return num;
}else{
return 0;
}
}
};
- 上述代码超出时间限制,因此先扫一遍,计算出加和的大小,这样之后就只需要两个相减就行了。
- 仔细一想也不对,因为这样最后还是要两个for循环扫一遍一样的时间,直接参考了解析。
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
int flag=0;
int num=n;
//初始化
int now=1;
int sum=nums[0];
if(sum>=target){
flag=1;
if(now<num){
num=now;
}
}
// 循环开始
for(int i=0;i<n;i++){
if(i!=0){ //每次更新窗户口头
sum-=nums[i-1];
now-=1;
if(sum>=target){ //多一个判断
flag=1;
if(now<num){
num=now;
}
continue;
}
}
//判断是否需要更新窗口尾
for(int j=i+now;j<n;j++){
if(now>=num){
break;
}
sum+=nums[j];
now++;
if(sum>=target){
flag=1;
if(now<num){
num=now;
}
break;
}
}
}
//判断窗口是否存在
if(flag==1){
return num;
}else{
return 0;
}
}
};
5.2 随想录记录
-
就是说不需要每次从头开始扫,只需要当前满足长度了,下一次减一,减去开头的长度,加上后面的看够不够就行,代码就是上面给的。
-
滑动窗口也可以理解为双指针法的一种!只不过这种解法更像是一个窗口的移动,所以叫做滑动窗口更适合一些。
在本题中实现滑动窗口,主要确定如下三点:
- 窗口内是什么?
- 如何移动窗口的起始位置?
- 如何移动窗口的结束位置?
-
窗口就是 满足其和 ≥ s 的长度最小的 连续 子数组。
-
窗口的起始位置如何移动:如果当前窗口的值大于s了,窗口就要向前移动了(也就是该缩小了)。
-
窗口的结束位置如何移动:窗口的结束位置就是遍历数组的指针,也就是for循环里的索引。
-
解题的关键在于 窗口的起始位置如何移动
-
发现**滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)暴力解法降为O(n)。**
-
不要以为for里放一个while就以为是O(n^2)啊, 主要是看每一个元素被操作的次数,每个元素在滑动窗后进来操作一次,出去操作一次,每个元素都是被操作两次,所以时间复杂度是 2 × n 也就是O(n)。
-
这个代码写的也非常好,就是一看就是理解透彻了写出来的,我自己的就是看明白了改出来的:(首先长度是计算出来的,其次for循环决定后面的长度,while决定开始的长度。)注意通过什么来控制窗口范围,这里是相加和
class Solution {
public:
int minSubArrayLen(int s, vector<int>& nums) {
int result = INT32_MAX;
int sum = 0; // 滑动窗口数值之和
int i = 0; // 滑动窗口起始位置
int subLength = 0; // 滑动窗口的长度
for (int j = 0; j < nums.size(); j++) {
sum += nums[j];
// 注意这里使用while,每次更新 i(起始位置),并不断比较子序列是否符合条件
while (sum >= s) {
subLength = (j - i + 1); // 取子序列的长度
result = result < subLength ? result : subLength;
sum -= nums[i++]; // 这里体现出滑动窗口的精髓之处,不断变更i(子序列的起始位置)
}
}
// 如果result没有被赋值的话,就返回0,说明没有符合条件的子序列
return result == INT32_MAX ? 0 : result;
}
};
- 但是刚开始这个代码我觉得是有一点问题的,就是如果从0到最后都没有满足sum大于s(第一个数极小-1000),而排除掉第一个是存在大于s的时候,这个代码会出错吧,相当于永远进入不了while,直接在for时退出了。然后这样细想了一下那我的代码也有问题了,i确实可以继续往后走但是j回不去啊,然后添加了个测试用例才发现n个正整数的意思是全部都是正整数,是我理解错题意了,以为其中有n个正整数,r-n个负数…不能怪我吧,这题目标的有问题啊。
5.3 其他题目
5.3.1
1.我的
一样的,就是要变成计算三个值,然后找其中两种和的最大值,多了一步。写了一圈错了,因为水果种类可以有无数种。直接去看题解了。
思路直接就错了,还是跟上一个一样,我是计算的长度,但是这道题里长度其实就是果子数量,因此应当保留长度,也就是通过窗口当前的果子种类,而不应当保存每种的数量去找。
下面是官方的代码,写的真好,简单明了,通过当前出现的果子类别的数量来控制滑动的窗口大小。等回来自己重写一下试试,主要是c++的其他数据结构怎么用早忘完了。
class Solution {
public:
int totalFruit(vector<int>& fruits) {
int n = fruits.size();
unordered_map<int, int> cnt;
int left = 0, ans = 0;
for (int right = 0; right < n; ++right) {
++cnt[fruits[right]];
while (cnt.size() > 2) {
auto it = cnt.find(fruits[left]);
--it->second;
if (it->second == 0) {
cnt.erase(it);
}
++left;
}
ans = max(ans, right - left + 1);
}
return ans;
}
};
- 窗口内就是当前选择采摘的果树,因此答案可以由窗口大小计算出来;
- 右侧移动限制是不能大于数组长度;
- 左侧移动限制是当前果树均可采摘,也就是只有两种。
5.3.2
1.我的
- 首先是可以两层循环结束,但是不想因此考虑滑动窗口;
- 窗口内是什么:是当前正在判断的子串,长度就是我们需要的,需要最小,每次满足包含关系时比较是否最小并更新;
- 右:s结束,当前不全部包含;
- 左:满足覆盖,全部包含。
- 但是没想到用什么数据结构来实现,看的解题思路,用哈希表,因为t中字符可以重复出现,还需要记录出现的次数。
- 还是不会,因为基础知识已经忘完了,因此这里只学习一下这个代码:
class Solution {
public:
unordered_map <char, int> ori, cnt;
bool check() { //比较是否完全包含
for (const auto &p: ori) {
if (cnt[p.first] < p.second) {
return false;
}
}
return true;
}
string minWindow(string s, string t) {
for (const auto &c: t) { //初始化,记录t中都有什么有多长
++ori[c];
}
int l = 0, r = -1;
int len = INT_MAX, ansL = -1, ansR = -1;
while (r < int(s.size())) {
if (ori.find(s[++r]) != ori.end()) { //find()在字符串中找对应的元素,没有则返回end()
++cnt[s[r]];
}
while (check() && l <= r) { //猜测没有数值时,check也可能返回true,因此需要有后面的条件?
if (r - l + 1 < len) { //更新
len = r - l + 1;
ansL = l;
}
if (ori.find(s[l]) != ori.end()) {
--cnt[s[l]];
} // 缩小窗口
++l;
}
}
return ansL == -1 ? string() : s.substr(ansL, len);
}
};
- 这里思考官方题解给出的解决方法中如何优化:
- 首先肯定是不能直接去掉无关元素的,可以在cnt中没有元素的时候,left和right一起移动,这样避免没有用的元素被多次判断。
6. 螺旋矩阵2(模拟行为)
6.1 我的
- 上下左右算了一圈,没发现什么方法,因此先看了一眼解析,就是不涉及算法,放心了,就先按照考察代码能力写:(顺利通过)
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
int ni=n,nj=n;
int ni0=0,nj0=0;
int num=1;
int i=0,j=0;
vector<vector<int>> res(n, vector<int>(n));
while(num<=n*n){
i=ni0;
j=nj0;
for(;j<nj;j++){
if(num>n*n){
break;
}
res[i][j]=num;
num++;
printf("%d %d %d",i,j,num);
}
j--;
ni0++;
for(i++;i<ni;i++){
if(num>n*n){
break;
}
res[i][j]=num;
num++;
printf("%d %d %d",i,j,num);
}
i--;
nj--;
for(j--;j>=nj0;j--){
if(num>n*n){
break;
}
res[i][j]=num;
num++;
printf("%d %d %d",i,j,num);
}
j++;
ni--;
for(i--;i>=ni0;i--){
if(num>n*n){
break;
}
res[i][j]=num;
num++;
printf("%d %d %d",i,j,num);
}
i++;
nj0++;
}
return res;
}
};
6.2 随想录记录
- 本题并不涉及到什么算法,就是模拟过程,但却十分考察对代码的掌控能力。
- 之前二分法有提到要写出正确的二分法一定要坚持循环不变量原则。
- 这也是坚持了每条边左闭右开的原则。(我们的代码坚持了左开右闭(第一个除外))
6.3 其他题目
6.3.1
1. 我的
很简单,上面代码复制过来就好。
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
int m=matrix.size(),n=matrix[0].size();
vector<int> res(m*n);
int now=0;
int ni=m,nj=n;
int ni0=0,nj0=0;
int i=0,j=0;
while(now<n*m){
i=ni0;
j=nj0;
for(;j<nj;j++){
if(now>=n*m){
break;
}
res[now++]=matrix[i][j];
// printf("%d %d %d",i,j,num);
}
j--;
ni0++;
for(i++;i<ni;i++){
if(now>=n*m){
break;
}
res[now++]=matrix[i][j];
// printf("%d %d %d",i,j,num);
}
i--;
nj--;
for(j--;j>=nj0;j--){
if(now>=n*m){
break;
}
res[now++]=matrix[i][j];
// printf("%d %d %d",i,j,num);
}
j++;
ni--;
for(i--;i>=ni0;i--){
if(now>=n*m){
break;
}
res[now++]=matrix[i][j];
// printf("%d %d %d",i,j,num);
}
i++;
nj0++;
}
return res;
}
};
6.3.2
LCR 146. 螺旋遍历二维数组 - 力扣(LeetCode)
1. 我的
和上题是一道题,区别在于存在0输入。
class Solution {
public:
vector<int> spiralArray(vector<vector<int>>& array) {
int m=array.size();
if(m==0){
vector<int> res(0);
return res;
}
int n=array[0].size();
vector<int> res(m*n);
int now=0;
int ni=m,nj=n;
int ni0=0,nj0=0;
int i=0,j=0;
while(now<n*m){
i=ni0;
j=nj0;
for(;j<nj;j++){
if(now>=n*m){
break;
}
res[now++]=array[i][j];
// printf("%d %d %d",i,j,num);
}
j--;
ni0++;
for(i++;i<ni;i++){
if(now>=n*m){
break;
}
res[now++]=array[i][j];
// printf("%d %d %d",i,j,num);
}
i--;
nj--;
for(j--;j>=nj0;j--){
if(now>=n*m){
break;
}
res[now++]=array[i][j];
// printf("%d %d %d",i,j,num);
}
j++;
ni--;
for(i--;i>=ni0;i--){
if(now>=n*m){
break;
}
res[now++]=array[i][j];
// printf("%d %d %d",i,j,num);
}
i++;
nj0++;
}
return res;
}
};
7. 总结
数组是非常基础的数据结构,在面试中,是必考的基础数据结构,考察数组的题目一般在思维上都不难,主要是考察对代码的掌控能力。数组的题目在思想上一般比较简单的,但是如果想高效,并不容易。
数组是存放在连续内存空间上的相同类型数据的集合。
需要两点注意的是
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。
数组的元素是不能删的,只能覆盖。
Java的二维数组在内存中不是 3*4 的连续地址空间,而是四条连续的地址空间组成!
-
二分法:可以使用暴力解法,通过这道题目,如果追求更优的算法,建议试一试用二分法,来解决这道题目
- 暴力解法时间复杂度:O(n)
- 二分法时间复杂度:O(logn)
在这道题目中我们讲到了循环不变量原则,只有在循环中坚持对区间的定义,才能清楚的把握循环中的各种细节。
二分法是算法面试中的常考题,建议通过这道题目,锻炼自己手撕二分的能力。
-
双指针法:(快慢指针法):通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
- 暴力解法时间复杂度:O(n^2)
- 双指针时间复杂度:O(n)
这道题目迷惑了不少同学,纠结于数组中的元素为什么不能删除,主要是因为以下两点:
- 数组在内存中是连续的地址空间,不能释放单一元素,如果要释放,就是全释放(程序运行结束,回收内存栈空间)。
- C++中vector和array的区别一定要弄清楚,vector的底层实现是array,封装后使用更友好。
双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。
-
滑动窗口:数组操作中的另一个重要思想
- 暴力解法时间复杂度:O(n^2)
- 滑动窗口时间复杂度:O(n)
本题中,主要要理解滑动窗口如何移动 窗口起始位置,达到动态更新窗口大小的,从而得出长度最小的符合条件的长度。
滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。
如果没有接触过这一类的方法,很难想到类似的解题思路,滑动窗口方法还是很巧妙的。
-
模拟行为:模拟类的题目在数组中很常见,不涉及到什么算法,就是单纯的模拟,十分考察大家对代码的掌控能力。
在这道题目中,我们再一次介绍到了循环不变量原则,其实这也是写程序中的重要原则。
真正解决题目的代码都是简洁的,或者有原则性的,大家可以在这道题目中体会到这一点。
二、链表
1. 链表理论基础
-
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
-
链表的入口节点称为链表的头结点也就是head。
-
单链表中的指针域只能指向节点的下一个节点。
-
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
-
双链表 既可以向前查询也可以向后查询。
-
循环链表,顾名思义,就是链表首尾相连。可以用来解决约瑟夫环问题。
-
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
-
链表的定义:
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};
//不定义构造函数,C++默认生成一个构造函数,这个构造函数不会初始化任何成员变量(因为无参)
-
删除节点:next指针 指向别的节点就可以了,在C++里最好是再手动释放这个节点,释放这块内存,其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
-
要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
-
添加节点:链表的增添和删除都是O(1)操作,也不会影响到其他节点。
-
链表操作中,可以使用原链表来直接进行删除操作,也可以设置一个虚拟头结点再进行删除操作。
2. 移除链表元素
2.1 我的
- 为了好想,我添加了一个指针用于指向结果的头节点,然后使用原来的链表进行删除操作(注意这里没有释放被删除节点的内存):
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* head_res = new ListNode(0);
do{ //首先找到第一个不等于val的节点
if(head == NULL){
return NULL;
}
if(head->val != val){
head_res->next=head;
break;
}
head=head->next;
}while(head_res->next==NULL);
while(head->next!=NULL){ //删除后面的元素
if(head->next->val==val){
head->next = head->next->next;
}else{
head=head->next;
}
}
return head_res->next;
}
};
2.2 随想录记录
- 如果使用C,C++编程语言的话,不要忘了还要从内存中删除这两个移除的节点, 清理节点内存。
- 移除一个节点之后,没有手动在内存中删除这个节点,leetcode依然也是可以通过的,只不过,内存使用的空间大一些而已,但建议依然要养成手动清理内存的习惯。
- 头节点因为没有前一个,处理不一样,就像我们上面的,但是可以加一个,一样处理流程。
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 删除头结点
while (head != NULL && head->val == val) { // 注意这里不是if
ListNode* tmp = head;
head = head->next;
delete tmp;
}
// 删除非头结点
ListNode* cur = head;
while (cur != NULL && cur->next!= NULL) {
if (cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
return head;
}
};
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方便后面做删除操作
ListNode* cur = dummyHead;
while (cur->next != NULL) {
if(cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
head = dummyHead->next;
delete dummyHead;
return head;
}
};
3. 设计链表
3.1 我的
没啥可说的,我的代码不如官方给的。
感觉很容易算错的就是现在应当是第几个,因为有头(虚拟的,只是提供一个指向),这样有时候不需要插入操作的需要额外判断(尤其注意方法:addAtIndex)。
class MyLinkedList {
public:
// 定义链表节点结构体
struct LinkedNode {
int val;
LinkedNode* next;
LinkedNode(int val):val(val), next(nullptr){}
};
// 初始化链表
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
}
int get(int index) {
LinkedNode* cur= _dummyHead;
for(int i=0;i<=index;i++){
if(cur->next==NULL){
return -1;
}
cur=cur->next;
}
return cur->val;
}
void addAtHead(int val) {
LinkedNode* newNode=new LinkedNode(val);
newNode->next=_dummyHead->next;
_dummyHead->next=newNode;
}
void addAtTail(int val) {
LinkedNode* newNode=new LinkedNode(val);
LinkedNode* cur=_dummyHead;
while(cur->next!=NULL){
cur=cur->next;
}
cur->next=newNode;
}
void addAtIndex(int index, int val) {
LinkedNode* newNode=new LinkedNode(val);
LinkedNode* cur=_dummyHead;
int i=0;
for(;i<index;i++){
if(cur->next==NULL){
break;
}
cur=cur->next;
}
if(i==index){ //需要注意不是全部时候都需要插入操作的!
newNode->next=cur->next;
cur->next=newNode;
}
}
void deleteAtIndex(int index) {
LinkedNode* cur=_dummyHead;
for(int i=0;i<index;i++){
if(cur->next==NULL){
break;
}
cur=cur->next;
}
LinkedNode* de=cur->next;
if(cur->next!=NULL){
cur->next=cur->next->next;
}
delete de;
}
private:
LinkedNode* _dummyHead;
};
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList* obj = new MyLinkedList();
* int param_1 = obj->get(index);
* obj->addAtHead(val);
* obj->addAtTail(val);
* obj->addAtIndex(index,val);
* obj->deleteAtIndex(index);
*/
3.2 随想录记录
直接看代码:
class MyLinkedList {
public:
// 定义链表节点结构体
struct LinkedNode {
int val;
LinkedNode* next;
LinkedNode(int val):val(val), next(nullptr){}
};
// 初始化链表
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
_size = 0;
}
// 获取到第index个节点数值,如果index是非法数值直接返回-1, 注意index是从0开始的,第0个节点就是头结点
int get(int index) {
if (index > (_size - 1) || index < 0) {
return -1;
}
LinkedNode* cur = _dummyHead->next;
while(index--){ // 如果--index 就会陷入死循环
cur = cur->next;
}
return cur->val;
}
// 在链表最前面插入一个节点,插入完成后,新插入的节点为链表的新的头结点
void addAtHead(int val) {
LinkedNode* newNode = new LinkedNode(val);
newNode->next = _dummyHead->next;
_dummyHead->next = newNode;
_size++;
}
// 在链表最后面添加一个节点
void addAtTail(int val) {
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(cur->next != nullptr){
cur = cur->next;
}
cur->next = newNode;
_size++;
}
// 在第index个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
// 如果index 等于链表的长度,则说明是新插入的节点为链表的尾结点
// 如果index大于链表的长度,则返回空
// 如果index小于0,则在头部插入节点
void addAtIndex(int index, int val) {
if(index > _size) return;
if(index < 0) index = 0;
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur->next;
}
newNode->next = cur->next;
cur->next = newNode;
_size++;
}
// 删除第index个节点,如果index 大于等于链表的长度,直接return,注意index是从0开始的
void deleteAtIndex(int index) {
if (index >= _size || index < 0) {
return;
}
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur ->next;
}
LinkedNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
//delete命令指示释放了tmp指针原本所指的那部分内存,
//被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后,
//如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针
//如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
tmp=nullptr;
_size--;
}
// 打印链表
void printLinkedList() {
LinkedNode* cur = _dummyHead;
while (cur->next != nullptr) {
cout << cur->next->val << " ";
cur = cur->next;
}
cout << endl;
}
private:
int _size;
LinkedNode* _dummyHead;
};
4. 翻转链表
4.1 我的
- 相当于从头部插入,注意,需要先判断当前head是否为NULL才能判断->next是否为NULL:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* head_re=new ListNode();
head_re->next=head;
if(head==NULL){ //需要先判断当前head是否为NULL才能判断->next是否为NULL
return head_re->next;
}
while(head->next!=NULL){
ListNode* cur=head->next;
head->next=head->next->next;
cur->next=head_re->next;
head_re->next=cur;
}
return head_re->next;
}
};
4.2 随想录记录
- 反转链表的写法很简单,一些同学甚至可以背下来但过一阵就忘了该咋写,主要是因为没有理解真正的反转过程。
- 解法1:双指针,一个指向当前反转“断开”的节点,一个指向下一个(保存节点位置的节点)。
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp; // 保存cur的下一个节点
ListNode* cur = head;
ListNode* pre = NULL;
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
cur->next = pre; // 翻转操作
// 更新pre 和 cur指针
pre = cur;
cur = temp;
}
return pre;
}
};
- 解法2:一样的思想可以按照递归的形式书写(很不好理解欸):
class Solution {
public:
ListNode* reverse(ListNode* pre,ListNode* cur){
if(cur == NULL) return pre;
ListNode* temp = cur->next;
cur->next = pre;
// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步
// pre = cur;
// cur = temp;
return reverse(cur,temp);
}
ListNode* reverseList(ListNode* head) {
// 和双指针法初始化是一样的逻辑
// ListNode* cur = head;
// ListNode* pre = NULL;
return reverse(NULL, head);
}
};
- 解法3:使用栈解决反转链表的问题,将所有的结点入栈,创建一个虚拟虚拟头结点,让cur指向虚拟头结点。然后开始循环出栈,每出来一个元素,就把它加入到以虚拟头结点为头结点的链表当中,最后返回即可。(创建一个虚拟虚拟头结点,让cur指向虚拟头结点。然后开始循环出栈,每出来一个元素,就把它加入到以虚拟头结点为头结点的链表当中,最后返回即可。)
- 解法4:我的方法,使用虚拟头结点,头插法实现链表的反转(不需要栈)。
5. 两两交换链表中的节点
5.1 我的
- 只有当还有两个的时候才交换,交换后切记前一对中后者的指向也需要更改。(心得:指针就是一定要:记住变化范围前的一个结点,记住头节点,这样才不会发生链表的丢失。)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head==NULL or head->next==NULL){
return head;
}
ListNode* head_re= new ListNode();//处理头节点
head_re->next=head;
ListNode* save= head_re;
while(head!=NULL and head->next!=NULL){//处理之后的
ListNode* pre=head;
ListNode* cur=head->next;
head=cur->next;
cur->next=pre;
pre->next=head;
save->next=cur;
save=pre;
}
return head_re->next;
}
};
5.2 随想录记录
- 正常模拟,建议使用虚拟头结点,这样会方便很多,要不然每次针对头结点(没有前一个指针指向头结点),还要单独处理。
- 交换相邻两个元素了,此时一定要画图,不画图,操作多个指针很容易乱,而且要操作的先后顺序。
- 做题的时候自己能分析出来时间复杂度就可以了,至于力扣上执行用时,大概看一下就行。力扣上的统计如果两份代码是 100ms 和 300ms的耗时,其实是需要注意的;如果一个是 4ms 一个是 12ms,看上去好像是一个打败了80%,一个打败了20%,其实是没有差别的。 只不过是力扣上统计的误差而已。
6. 删除链表的倒数第N个节点
19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode)
6.1 我的
- 先得到长度,然后计算正向位置
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* head_re=new ListNode();
head_re->next=head;
ListNode* len=head;
int num=0;
head=head_re;
while(len!=NULL){
len=len->next;
num++;
}
n = num-n;
for(int i=0;i<n;i++){
if(head->next==NULL){
return head_re->next;
}
head=head->next;
}
if(head->next==NULL){
return head_re->next;
}
ListNode* cur=head->next;
head->next=head->next->next;
delete cur;
return head_re->next;
}
};
6.2 随想录记录
- 这个是真的绝,仔分析,就是扫两遍,因此可以双指针法,快慢指针:
- 如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
- 首先这里我推荐大家使用虚拟头结点,这样方便处理删除实际头结点的逻辑,如果虚拟头结点不清楚,可以看这篇: 链表:听说用虚拟头节点会方便很多?(opens new window);
- 定义fast指针和slow指针,初始值为虚拟头结点;
- fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作,fast为n时,由于最后fast应当指向NULL,此时slow指向应当删除结点,因此fast应当再向后走一步);
- fast和slow同时移动,直到fast指向末尾(NULL);
- 删除slow指向的下一个节点。
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = dummyHead;
while(n-- && fast != NULL) {
fast = fast->next;
}
fast = fast->next; // fast再提前走一步,因为需要让slow指向删除节点的上一个节点
while (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
// ListNode *tmp = slow->next; C++释放内存的逻辑
// slow->next = tmp->next;
// delete nth;
return dummyHead->next;
}
};
7. 链表相交
面试题 02.07. 链表相交 - 力扣(LeetCode)
7.1 我的
- 结点是否相等比较的是本身而非数值或者指针,我寻思也没改进了,直接暴力,没想到有简单的方法,不知道为没想到。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// ListNode* node=new ListNode();
// node->next=NULL;
while(headA!=NULL and headB!=NULL){
ListNode* cur=headB;
while(cur!=NULL){
if(headA == cur){
return headA;
}
cur=cur->next;
}
headA=headA->next;
}
return NULL;
}
};
7.2 随想录记录
- 基本思路:相交后的长度相等。
- 我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置;
- 此时我们就可以比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到交点。
- 否则循环退出返回空指针。
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode* curA = headA;
ListNode* curB = headB;
int lenA = 0, lenB = 0;
while (curA != NULL) { // 求链表A的长度
lenA++;
curA = curA->next;
}
while (curB != NULL) { // 求链表B的长度
lenB++;
curB = curB->next;
}
curA = headA;
curB = headB;
// 让curA为最长链表的头,lenA为其长度
if (lenB > lenA) {
swap (lenA, lenB);
swap (curA, curB);
}
// 求长度差
int gap = lenA - lenB;
// 让curA和curB在同一起点上(末尾位置对齐)
while (gap--) {
curA = curA->next;
}
// 遍历curA 和 curB,遇到相同则直接返回
while (curA != NULL) {
if (curA == curB) {
return curA;
}
curA = curA->next;
curB = curB->next;
}
return NULL;
}
};
8. 环形链表2
8.1 我的
- 细想了一下,只想到了两重循环,实现很简单,因此直接看有没有别的方法了,果然有。
8.2 随想录记录
- 还是老套路,快慢指针解决双循环
- 主要考察两知识点:
- 判断链表是否环
- 如果有环,如何找到这个环的入口
8.2.1 判断链表是否有环
- 可以使用快慢指针法,分别定义 fast 和 slow 指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
- 为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢
- 首先第一点:fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
- 在环中:因为fast是走两步,slow是走一步,其实相对于slow来说,fast是一个节点一个节点的靠近slow的,所以fast一定可以和slow重合。
8.2.2 如何找到环的入口
此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。
-
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。
-
因为就按照一起进入环计算,慢的走一半的时候,快的肯定走完一圈了,那么慢的另外一半的时候,快的肯定还能再走一圈,因此如果有环那一定在慢的还没有走完第一圈时就能相遇。
-
也不可能跳过,跳过一定是fast在环内slow的后面,在后面两个时,下一步fast会走到当前slow的位置,然后slow向前走一步,fast变成在slow后面一个位置上,向前走两步,跨过slow一个,但是下一步slow向前走,两者正好遇上。(文章中解释的是相对于slow,fast是每次走一个位置,感觉不太好理解,简单模拟一下就好了)
-
现在就可以考虑计算环的入口了:
-
相遇时: slow指针走过的节点数为:
x + y, fast指针走过的节点数:x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。 -
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
(x + y) * 2 = x + y + n (y + z)两边消掉一个(x+y):
x + y = n (y + z)因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。所以要求x ,将x单独放在左面:
x = n (y + z) - y,再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:x = (n - 1) (y + z) + z注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。 -
当 n为1的时候,公式就化解为
x = z,这就意味着,从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。 -
n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
-
//我的复现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
//首先判断是否有环
ListNode* fast=head;
ListNode* slow=head;
do{
for(int i=0;i<2;i++){
if(fast==NULL){
return NULL;
}
fast=fast->next;
}
slow=slow->next;
}while(fast!=slow);
//找入口
slow=head;
while(slow!=fast){
slow=slow->next;
fast=fast->next;
}
return fast;
}
};
//代码随想录
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* fast = head;
ListNode* slow = head;
while(fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
// 快慢指针相遇,此时从head 和 相遇点,同时查找直至相遇
if (slow == fast) {
ListNode* index1 = fast;
ListNode* index2 = head;
while (index1 != index2) {
index1 = index1->next;
index2 = index2->next;
}
return index2; // 返回环的入口
}
}
return NULL;
}
};
9. 总结
-
虚拟头节点:链表操作中一个非常总要的技巧:虚拟头节点。链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点了。每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决这个问题。
-
链表的基本操作:设计链表把链表常见的五个操作练习了一遍,是练习链表基础操作的非常好的一道题目,可以说把这道题目做了,链表基本操作就OK了,再也不用担心链表增删改查整不明白了。
-
反转链表:两种反转的方式,迭代法和递归法。
建议大家先学透迭代法,然后再看递归法,因为递归法比较绕,如果迭代还写不明白,递归基本也写不明白了。
可以先通过迭代法,彻底弄清楚链表反转的过程!
-
删除倒数第N个节点:结合虚拟头结点 和 双指针法来移除链表倒数第N个节点
-
链表相交:用双指针来找到两个链表的交点(引用完全相同,即:内存地址完全相同的交点)
-
环形链表:在链表如何找环,以及如何找环的入口位置
三、哈希表
1. 哈希表(散列表)理论基础
-
哈希表是根据关键码的值而直接进行访问的数据结构。其实直白来讲其实数组就是一张哈希表。
-
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素
-
哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现集合里,枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
-
将元素映射到哈希表上就涉及到了hash function ,也就是哈希函数。
-
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
-
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
-
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
-
此时问题又来了,哈希表我们刚刚说过,就是一个数组。如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。小李和小王都映射到了索引下标 1 的位置,这一现象叫做哈希碰撞。一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
-
拉链法:发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了。(数据规模是dataSize, 哈希表的大小为tableSize)
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
-
线性探测法:使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
-
-
想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1 |
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
- 集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
- 虽然std::set、std::multiset 的底层实现是红黑树,不是哈希表,std::set、std::multiset 使用红黑树来索引和存储,不过给我们的使用方式,还是哈希法的使用方式,即key和value。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。 map也是一样的道理。
那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
其他语言例如:java里的HashMap ,TreeMap 都是一样的原理。可以灵活贯通。
- 一些C++的经典书籍上 例如STL源码剖析,说到了hash_set hash_map,这个与unordered_set,unordered_map又有什么关系呢?
- 实际上功能都是一样一样的, 但是unordered_set在C++11的时候被引入标准库了,而hash_set并没有,所以建议还是使用unordered_set比较好,这就好比一个是官方认证的,hash_set,hash_map 是C++11标准之前民间高手自发造的轮子。
2. 有效字母异位词
2.1 我的
- 因为字母是固定数量的,因此可以直接使用字母的序号作为哈希函数,而且值比较数量,因此只需记录出现次数:
class Solution {
public:
bool isAnagram(string s, string t) {
vector<int> s_(26);
vector<int> t_(26);
for(int i=0;i<26;i++){
s_[i]=t_[i]=0;
}
for(int i=0;i<s.size();i++){
s_[s[i]-'a']++;
}
for(int i=0;i<t.size();i++){
t_[t[i]-'a']++;
}
for(int i=0;i<26;i++){
if(s_[i]!=t_[i]){
return false;
}
}
return true;
}
};
2.2 随想录记录
-
暴力的解法,两层for循环,同时还要记录字符是否重复出现,很明显时间复杂度是 O(n^2)。
-
数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
-
定义一个数组叫做record用来上记录字符串s里字符出现的次数。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
-
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作(这样更优,因为只需要定义一个哈希表)。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
-
-
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
2.3 相关题目
2.3.1
1. 我的
-
没思路,看的题解:
- 个人觉得最好的方法:排序,首先将三个字母进行排序,这样字母一样的字符串也一样,然后用字符串使用map进行哈希表(官方题解代码):
class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { unordered_map<string, vector<string>> mp; for (string& str: strs) { string key = str; sort(key.begin(), key.end()); mp[key].emplace_back(str);//vector 容器中添加了新的方法:emplace_back() ,和 push_back() 一样的是都是在容器末尾添加一个新的元素进去,不同的是 emplace_back() 在效率上相比较于 push_back() 有了一定的提升。 } vector<vector<string>> ans; for (auto it = mp.begin(); it != mp.end(); ++it) { ans.emplace_back(it->second); } return ans; } };代码注释:C++中push_back和emplace_back的区别 - 知乎 (zhihu.com)
- 方法二:按照字母出现次数进行哈希查找:
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
// 自定义对 array<int, 26> 类型的哈希函数
auto arrayHash = [fn = hash<int>{}] (const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {
return (acc << 1) ^ fn(num);
});
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
for (string& str: strs) {
array<int, 26> counts{};
int length = str.length();
for (int i = 0; i < length; ++i) {
counts[str[i] - 'a'] ++;
}
mp[counts].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};
2.3.2
438. 找到字符串中所有字母异位词 - 力扣(LeetCode)
1. 我的
- 这题第一想法就是滑动窗口和排序,目标先排序,滑动一个同样数量的窗口,排序后比较窗口内字符与目标字符是否相同。(C++代码掌握的不好,就直接搬官方代码了,官方代码更简单一些)
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int sLen = s.size(), pLen = p.size();
if (sLen < pLen) {
return vector<int>();
}
vector<int> ans;
vector<int> sCount(26);
vector<int> pCount(26);
for (int i = 0; i < pLen; ++i) {
++sCount[s[i] - 'a'];
++pCount[p[i] - 'a'];
}
if (sCount == pCount) {
ans.emplace_back(0);
}
for (int i = 0; i < sLen - pLen; ++i) {
--sCount[s[i] - 'a'];
++sCount[s[i + pLen] - 'a'];
if (sCount == pCount) {
ans.emplace_back(i + 1);
}
}
return ans;
}
};
- 给的题解的方法更好:优化的画的那个窗口,就是记录窗口中相同字符的数量,全部相同时记录下来。
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int sLen = s.size(), pLen = p.size();
if (sLen < pLen) {
return vector<int>();
}
vector<int> ans;
vector<int> count(26);
for (int i = 0; i < pLen; ++i) {
++count[s[i] - 'a'];
--count[p[i] - 'a'];
}
int differ = 0;
for (int j = 0; j < 26; ++j) {
if (count[j] != 0) {//这里的物理含义并非有几个不相同,而是一共有多少不同,因为两个字符串中的字符都会被算上
++differ;
}
}
if (differ == 0) {
ans.emplace_back(0);
}
for (int i = 0; i < sLen - pLen; ++i) {
if (count[s[i] - 'a'] == 1) { // 窗口中字母 s[i] 的数量与字符串 p 中的数量从不同变得相同
--differ;
} else if (count[s[i] - 'a'] == 0) { // 窗口中字母 s[i] 的数量与字符串 p 中的数量从相同变得不同
++differ;
}
--count[s[i] - 'a'];
if (count[s[i + pLen] - 'a'] == -1) { // 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从不同变得相同
--differ;
} else if (count[s[i + pLen] - 'a'] == 0) { // 窗口中字母 s[i+pLen] 的数量与字符串 p 中的数量从相同变得不同
++differ;
}
++count[s[i + pLen] - 'a'];
if (differ == 0) {
ans.emplace_back(i + 1);
}
}
return ans;
}
};
3. 两个数组的交集
- 如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费!
3.1 我的
- 数字本身作为哈希函数,使用map,因为数字可以出现的范围太大了:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int, int> mp;
for(int i=0;i<nums1.size();i++){
mp[nums1[i]]=1;
}
vector<int> ans;
for(int i=0;i<nums2.size();i++){
if(mp.find(nums2[i]) != mp.end()){ //存在
if(--mp[nums2[i]]==0){
// printf("%d",nums2[i]);
ans.emplace_back(nums2[i]);
}
}
}
return ans;
}
};
3.2 随想录记录
-
这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
-
用数组来做哈希表也是不错的选择,使用数组来做哈希的题目,是因为题目都限制了数值的大小。
-
而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了,set ,关于set,C++ 给提供了如下三种可用的数据结构:
- std::set:底层实现都是红黑树
- std::multiset:底层实现都是红黑树
- std::unordered_set:底层实现是哈希表(读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。)
-
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());//更为简洁的代码
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
3.3 相关题目
350. 两个数组的交集 II - 力扣(LeetCode)
3.3.1
1. 我的
- 将上面我们的代码稍微改一下就好了:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int, int> mp;
for(int i=0;i<nums1.size();i++){
if(mp.find(nums1[i]) == mp.end()){
mp[nums1[i]]=1;
}else{
mp[nums1[i]]++;
// printf("%d %d",nums1[i], mp[nums1[i]]);
}
}
vector<int> ans;
for(int i=0;i<nums2.size();i++){
if(mp.find(nums2[i]) != mp.end()){ //存在
if(--mp[nums2[i]]>=0){
ans.emplace_back(nums2[i]);
}
}
}
return ans;
}
};
4. 快乐数
- 该用set的时候,还是得用set
4.1 我的
- 没有思路,直接去看的答案,下面是学会后自己的代码:
class Solution {
public:
bool isHappy(int n) {
unordered_map<int, int> mp;
mp[n]=1;
int res=n;
while(n!=1){
int n1=0;
int k;
while(n!=0){//计算下一个结果
k=n%10;
n=int(n/10);
n1+=k*k;
}
// printf("%d", n1);
n=n1;
if(mp.find(n) != mp.end()){
return false;
}else{
mp[n]=1;
}
}
return true;
}
};
4.2 随想录记录
- 一下子就说中了,我看成数学题了,不是的!认真读题,无限循环,也就是说会出现重复的数字,记录一下就好。
- 题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
- 当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
官方代码:
class Solution {
public:
// 取数值各个位上的单数之和
int getSum(int n) {
int sum = 0;
while (n) {
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while(1) {
int sum = getSum(n);
if (sum == 1) {
return true;
}
// 如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
if (set.find(sum) != set.end()) {
return false;
} else {
set.insert(sum);
}
n = sum;
}
}
};
5. 两数之和
5.1 我的
- 首先将整个数组放入哈希表中,数值为索引,存放在数组中的位置,然后查找[target-当前值是否存在],存在且非当前数值,则返回:
- 随想录给的代码更简单,相当于每次加入的时候看一下有没有和当前元素匹配的,这样都不用对比这两个元素是否都出现过了。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> mp;
for(int i=0;i<nums.size();i++){
mp[nums[i]]=i;
}
vector<int> ans(2);
for(int i=0;i<nums.size();i++){
if(mp.find(target - nums[i])!=mp.end() and mp[target - nums[i]]!=i){
ans[0]=i;
ans[1]=mp[target - nums[i]];
return ans;
}
}
return ans;
}
};
5.2 随想录记录
-
再强调一下 什么时候使用哈希法,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
本题呢,我就需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。
-
不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
-
使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
-
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value再保存数值所在的下标。
-
这道题目中并不需要key有序,选择std::unordered_map 效率更高! 使用其他语言的录友注意了解一下自己所用语言的数据结构就行。
接下来需要明确两点:
- map用来做什么
- map中key和value分别表示什么
-
map目的用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
接下来是map中key和value分别表示什么。
这道题 我们需要 给出一个元素,判断这个元素是否出现过,如果出现过,返回这个元素的下标。
那么判断元素是否出现,这个元素就要作为key,所以数组中的元素作为key,有key对应的就是value,value用来存下标。
所以 map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
-
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素匹配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map <int,int> map;
for(int i = 0; i < nums.size(); i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
auto iter = map.find(target - nums[i]);
if(iter != map.end()) {
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};
本题其实有四个重点:
- 为什么会想到用哈希表
- 哈希表为什么用map
- 本题map是用来存什么的
- map中的key和value用来存什么的
把这四点想清楚了,本题才算是理解透彻了。
6. 四数相加2
- 需要哈希的地方都能找到map的身影
6.1 我的
- 想法是map: [key:数值][value:<第几个数组,下标>],排序,然后分别从两头取不同数组中的值,求和,好像不对,四个指针不好移动。
- 数组两个二重循环,将两个分别相加,然后记录对应的数值,然后两个和就能直接查找有没有合适的了。
- 因为多少有点复杂,所以先看了解析再敲代码,问题在于不需要保证两个数组中的元素不重复出现,因此不需要记录其在数组中的位置,但是需要记录该加和值出现的次数,而且和上一题犯的错一样,就是不需要第二个记录,只需要记录一个,第二个在算的时候直接就比较出来了(根本原因是第二个不需要用到第二次,也就是不需要重复查找,因此不需要记录)。
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int, int> mp;
for(int i =0;i<nums1.size();i++){
for(int j=0;j<nums2.size();j++){
mp[nums1[i]+nums2[j]]++;//不需要先判断再加入
}
}
int count=0;
for(int i =0;i<nums3.size();i++){
for(int j=0;j<nums4.size();j++){
if (mp.find(0-(nums3[i]+nums4[j])) != mp.end()) {
count+=mp[0-(nums3[i]+nums4[j])];
}
}
}
return count;
}
};
6.2 随想录记录
-
上面的代码就是我们参考这里给的思路,反思写上面了,这里不放了。
-
本题是使用哈希法的经典题目,这道题目是四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑有重复的四个元素相加等于0的情况。
-
如果本题想难度升级:就是给出一个数组(而不是四个数组),在这里找出四个元素相加等于0,答案中不可以包含重复的四元组,大家可以思考一下,后续的文章我也会讲到的。
-
本题解题步骤:
- 首先定义 一个unordered_map,key放a和b两数之和,value 放a和b两数之和出现的次数。
- 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
- 定义int变量count,用来统计 a+b+c+d = 0 出现的次数。
- 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
- 最后返回统计值 count 就可以了
-
给的代码总是更简洁:
class Solution {
public:
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int> umap; //key:a+b的数值,value:a+b数值出现的次数
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
umap[a + b]++;
}
}
int count = 0; // 统计a+b+c+d = 0 出现的次数
// 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (umap.find(0 - (c + d)) != umap.end()) {
count += umap[0 - (c + d)];
}
}
}
return count;
}
};
7. 赎金信
- 在哈希法中有一些场景就是为数组量身定做的
7.1 我的
- 很简单,拿出来magazine中的,记录字符(受限因此可以是数组)和出现次数,ransom note中逐个剪掉,没有出现或者数量不够就不行,否则行。
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
vector<int> mp(26);
for(int i=0;i<26;i++){
mp[i]=0;
}
for(int i=0;i<magazine.size();i++){
mp[magazine[i]-'a']++;
}
for(int i=0;i<ransomNote.size();i++){
if(--mp[ransomNote[i]-'a']<0){
return false;
}
}
return true;
}
};
7.2 随想录记录
-
这道题目和242.有效的字母异位词 (opens new window)很像,242.有效的字母异位词 (opens new window)相当于求 字符串a 和 字符串b 是否可以相互组成 ,而这道题目是求 字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
本题判断第一个字符串ransom能不能由第二个字符串magazines里面的字符构成,但是这里需要注意两点。
- 第一点“为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思” 这里说明杂志里面的字母不可重复使用。
- 第二点 “你可以假设两个字符串均只含有小写字母。” 说明只有小写字母,这一点很重要*第二点忽略掉了
-
暴力解法就忽视了,两层for还需要擦除动作。
-
题目说只有小写字母,那可以采用空间换取时间的哈希策略,用一个长度为26的数组来记录magazine里字母出现的次数。
然后再用ransomNote去验证这个数组是否包含了ransomNote所需要的所有字母。
-
一些同学可能想,用数组干啥,都用map完事了,其实在本题的情况下,使用map的空间消耗要比数组大一些的,因为map要维护红黑树或者哈希表,而且还要做哈希函数,是费时的!数据量大的话就能体现出来差别了。 所以数组更加简单直接有效!
-
学习一下简洁的代码:
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int record[26] = {0};
//add
if (ransomNote.size() > magazine.size()) {
return false;
}
for (int i = 0; i < magazine.length(); i++) {
// 通过record数据记录 magazine里各个字符出现次数
record[magazine[i]-'a'] ++;
}
for (int j = 0; j < ransomNote.length(); j++) {
// 遍历ransomNote,在record里对应的字符个数做--操作
record[ransomNote[j]-'a']--;
// 如果小于零说明ransomNote里出现的字符,magazine没有
if(record[ransomNote[j]-'a'] < 0) {
return false;
}
}
return true;
}
};
8. 三数之和
8.1 我的
- 首先找到两个数量相对少的,进行相加,key为加和值,value为一个指针,指向各个当前的加和组成元素,然后遍历后者查找是否有匹配项。看了一眼解析,我理解错了,是给出一个数组,判断是否存在三数之和。
- 然后想到的方法是,对数组进行排序,然后a从开头,b在a之后,c在b之后,这样因为求和为0,a b c一定不会完全相同,但是难不保一个数多次出现,因此首先去重,每个数最多出现2次,0可以出现三次。写了一下发现不会,还是不能保证无重复,而且没有哈希表,是一个三重循环,因此c的范围一直在变。
8.2 随想录记录
- 哈希:两层for循环就可以确定 a 和b 的数值了,可以使用哈希法来确定 0-(a+b) 是否在 数组里出现过,其实这个思路是正确的,但是我们有一个非常棘手的问题,就是题目中说的不可以包含重复的三元组。
- 下面的思路:a一直想右走,不会重复,b是最左的元素,c在a b中间,并且c不等于b,这样c的哈希表范围是可控的,一直在变大。去重就是每次a一定不一样,因为a一样时的b c应当都遍历过了,而当a一样时,b c可以一样,但是只能一样一次,因此出现过的c需要排除掉,因为此时c和b确定一个另一个就确定了,因此b需要控制只能有两个一样的,剩下的要跳过。
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[j], c = -(a + b)
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么不可能凑成三元组
if (nums[i] > 0) {
break;
}
if (i > 0 && nums[i] == nums[i - 1]) { //三元组元素a去重
continue;
}
unordered_set<int> set;
for (int j = i + 1; j < nums.size(); j++) {
if (j > i + 2
&& nums[j] == nums[j-1]
&& nums[j-1] == nums[j-2]) { // 三元组元素b去重
continue;
}
int c = 0 - (nums[i] + nums[j]);
if (set.find(c) != set.end()) {
result.push_back({nums[i], nums[j], c});
set.erase(c);// 三元组元素c去重
} else {
set.insert(nums[j]);
}
}
}
return result;
}
};
-
双指针: 其实这道题目使用哈希法并不十分合适,因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。而且使用哈希法 在使用两层for循环的时候,能做的剪枝操作很有限,虽然时间复杂度是O(n^2),也是可以在leetcode上通过,但是程序的执行时间依然比较长 。
接下来我来介绍另一个解法:双指针法,这道题目使用双指针法 要比哈希法高效一些,那么来讲解一下具体实现的思路。
-
首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上。相当于 a = nums[i],b = nums[left],c = nums[right]。
- 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些。
- 如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
- 下面的代码中去重操作,实现了自己思考过程中失败的地方。
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
// 错误去重a方法,将会漏掉-1,-1,2 这种情况
/*
if (nums[i] == nums[i + 1]) {
continue;
}
*/
// 正确去重a方法
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
/*
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
*/
if (nums[i] + nums[left] + nums[right] > 0) right--;
else if (nums[i] + nums[left] + nums[right] < 0) left++;
else {
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
return result;
}
};
-
补充:两数之和 就不能使用双指针法,因为两数之和要求返回的是索引下标, 而双指针法一定要排序,一旦排序之后原数组的索引就被改变了。
如果两数之和要求返回的是数值的话,就可以使用双指针法了。
-
去重:
-
a的去重:a 如果重复了怎么办,a是nums里遍历的元素,那么应该直接跳过去。
-
但这里有一个问题,是判断 nums[i] 与 nums[i + 1]是否相同,还是判断 nums[i] 与 nums[i-1] 是否相同。都是和 nums[i]进行比较,是比较它的前一个,还是比较它的后一个。
-
比较它的后一个:就把 三元组中出现重复元素的情况直接pass掉了。 例如{-1, -1 ,2} 这组数据,当遍历到第一个-1 的时候,判断 下一个也是-1,那这组数据就pass了。
我们要做的是 不能有重复的三元组,但三元组内的元素是可以重复的!
-
所以这里是有两个重复的维度,比较它的前一个:就是当前使用 nums[i],我们判断前一位是不是一样的元素,在看 {-1, -1 ,2} 这组数据,当遍历到 第一个 -1 的时候,只要前一位没有-1,那么 {-1, -1 ,2} 这组数据一样可以收录到 结果集里。
这是一个非常细节的思考过程。
-
-
b c的去重:去重的逻辑多加了 对right 和left 的去重:
while (right > left) { if (nums[i] + nums[left] + nums[right] > 0) { right--; // 去重 right while (left < right && nums[right] == nums[right + 1]) right--; } else if (nums[i] + nums[left] + nums[right] < 0) { left++; // 去重 left while (left < right && nums[left] == nums[left - 1]) left++; } else { } }-
这种去重其实对提升程序运行效率是没有帮助的。
拿right去重为例,即使不加这个去重逻辑,依然根据
while (right > left)和if (nums[i] + nums[left] + nums[right] > 0)去完成right-- 的操作。多加了
while (left < right && nums[right] == nums[right + 1]) right--;这一行代码,其实就是把 需要执行的逻辑提前执行了,但并没有减少 判断的逻辑。最直白的思考过程,就是right还是一个数一个数的减下去的,所以在哪里减的都是一样的。
所以这种去重 是可以不加的。 仅仅是 把去重的逻辑提前了而已。
-
9. 四数之和
- 一样的道理,能解决四数之和 那么五数之和、六数之和、N数之和呢?
9.1 我的
- 比较直接的想法就是先做一个数组中两两相加结果的有序的哈希表(这里面的两个相加值各不相同,也就是b一定在a后面,然后求a+b,后面是一个链表指向一个个下标值对),然后对于得到的哈希表左右加上指针进行查找。但是看了一眼示例才发现,返回的还是不是下标,是元素值。本来以为是元素可以一样,但是元素下标不能相同,但是给的示例2又不是,所以还是每个元组中的元素不能完全相同。
- 然后发现这道题之前写过…怎么说呢还是用指针法,就是前面的一直向后走的指针从一个变成两个(因此更多数求和也是,前面固定的一定的数量,后面两个指针,注意前面固定相后移动的,每次不能相同):
- 要注意不再全部正整数了,剪枝方法需要更新;而且每次改变数组下标都需要判断是否超出范围。
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
sort(nums.begin(),nums.end());
vector<vector<int>> result;
if(nums.size()<4){
return result;
}
for(int i=0;i<nums.size()-3;i++){
// printf("%d %d",i, nums.size()-3);
//不能再加下面的判断了,因为不是每一个数都是正整数,因此当是负数时出错
// if(nums[i]>target){
// return result;
// }
if(nums[i]>=0 and nums[i]>target){
continue;
}
while(i>0 and nums[i]==nums[i-1]){
i++;
}
for(int j=i+1;j<nums.size()-2;j++){
while(j>i+1 and j<nums.size()-2 and nums[j]==nums[j-1]){
j++;
}
int left=j+1;
int right=nums.size()-1;
while(right>left){
// if(nums[i]+nums[j]+nums[left]+nums[right])>long(INT_MAX)){
// continue;
// }
if((long) nums[i]+nums[j]+nums[left]+nums[right]==target){
result.push_back(vector<int>{nums[i],nums[j], nums[left], nums[right]});
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
right--;
left++;
}else if((long) nums[i]+nums[j]+nums[left]+nums[right]>target){
right--;
}else if((long) nums[i]+nums[j]+nums[left]+nums[right]<target){
left++;
}
}
}
}
return result;
}
};
9.2 随想录记录
-
四数之和,和三数之和是一个思路,都是使用双指针法, 基本解法就是在三数之和 的基础上再套一层for循环
-
但是有一些细节需要注意,例如: 不要判断
nums[k] > target就返回了,三数之和 可以通过nums[i] > 0就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值。比如:数组是[-4, -3, -2, -1],target是-10,不能因为-4 > -10而跳过。但是我们依旧可以去做剪枝,逻辑变成nums[i] > target && (nums[i] >=0 || target >= 0)就可以了。 -
四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下标作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。
那么一样的道理,五数之和、六数之和等等都采用这种解法。
-
之前我们讲过哈希表的经典题目:454.四数相加II (opens new window),相对于本题简单很多,因为本题是要求在一个集合中找出四个数相加等于target,同时四元组不能重复。
而四数相加II是四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑有重复的四个元素相加等于0的情况,所以相对于本题还是简单了不少!
-
下面的代码还有很多需要学习的细节:比如二级剪枝;一级剪枝的方法;防止溢出的方法。
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for (int k = 0; k < nums.size(); k++) {
// 剪枝处理
if (nums[k] > target && nums[k] >= 0) {
break; // 这里使用break,统一通过最后的return返回
}
// 对nums[k]去重
if (k > 0 && nums[k] == nums[k - 1]) {
continue;
}
for (int i = k + 1; i < nums.size(); i++) {
// 2级剪枝处理
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
// 对nums[i]去重
if (i > k + 1 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// nums[k] + nums[i] + nums[left] + nums[right] > target 会溢出
if ((long) nums[k] + nums[i] + nums[left] + nums[right] > target) {
right--;
// nums[k] + nums[i] + nums[left] + nums[right] < target 会溢出
} else if ((long) nums[k] + nums[i] + nums[left] + nums[right] < target) {
left++;
} else {
result.push_back(vector<int>{nums[k], nums[i], nums[left], nums[right]});
// 对nums[left]和nums[right]去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
}
return result;
}
};
-
补充:二级剪枝的部分:
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) { break; }可以优化为:
if (nums[k] + nums[i] > target && nums[i] >= 0) { break; }因为只要 nums[k] + nums[i] > target,那么 nums[i] 后面的数都是正数的话,就一定 不符合条件了。
不过这种剪枝 其实有点 小绕,大家能够理解 文章给的完整代码的剪枝 就够了。
10. 总结
本篇我们从哈希表的理论基础到数组、set和map的经典应用,把哈希表的整个全貌完整的呈现给大家。
同时也强调虽然map是万能的,详细介绍了什么时候用数组,什么时候用set。
一般来说哈希表都是用来快速判断一个元素是否出现集合里。
对于哈希表,要知道哈希函数和哈希碰撞在哈希表中的作用。
哈希函数是把传入的key映射到符号表的索引上。
哈希碰撞处理有多个key映射到相同索引上时的情景,处理碰撞的普遍方式是拉链法和线性探测法。
接下来是常见的三种哈希结构:
- 数组
- set(集合)
- map(映射)
在C++语言中,set 和 map 都分别提供了三种数据结构,每种数据结构的底层实现和用途都有所不同,在关于哈希表,你该了解这些! (opens new window)中我给出了详细分析,这一知识点很重要!
例如什么时候用std::set,什么时候用std::multiset,什么时候用std::unordered_set,都是很有考究的。
只有对这些数据结构的底层实现很熟悉,才能灵活使用,否则很容易写出效率低下的程序。
-
数组作为哈希表:数组就是简单的哈希表,但是数组的大小是受限的。
- 包含小写字母,那么使用数组来做哈希最合适不过。
- 本题和242.有效的字母异位词 (opens new window)很像,242.有效的字母异位词 (opens new window)是求 字符串a 和 字符串b 是否可以相互组成,在383.赎金信 (opens new window)中是求字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
- 上面两道题目用map确实可以,但使用map的空间消耗要比数组大一些,因为map要维护红黑树或者符号表,而且还要做哈希函数的运算。所以数组更加简单直接有效!
-
set作为哈希表:题目没有限制数值的大小,就无法使用数组来做哈希表了。主要因为如下两点:
-
数组的大小是有限的,受到系统栈空间(不是数据结构的栈)的限制。
-
如果数组空间够大,但哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
-
做映射的话,就可以使用set了。关于set,C++ 给提供了如下三种可用的数据结构:(详情请看关于哈希表,你该了解这些! (opens new window))
- std::set
- std::multiset
- std::unordered_set
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希, 使用unordered_set 读写效率是最高的,本题并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
-
-
map作为哈希表:map是一种
<key, value>的结构,本题可以用key保存数值,用value在保存数值所在的下标。所以使用map最为合适。使用数组和set来做哈希法的局限:-
数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
-
set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
-
C++提供如下三种map:(详情请看关于哈希表,你该了解这些! (opens new window))
- std::map
- std::multimap
- std::unordered_map
std::unordered_map 底层实现为哈希,std::map 和std::multimap 的底层实现是红黑树。
同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解),1.两数之和 (opens new window)中并不需要key有序,选择std::unordered_map 效率更高!
-
-
在454.四数相加 (opens new window)中我们提到了其实需要哈希的地方都能找到map的身影。
本题咋眼一看好像和18. 四数之和 (opens new window),15.三数之和 (opens new window)差不多,其实差很多!**关键差别是本题为四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑重复问题,而18. 四数之和 (opens new window),15.三数之和 (opens new window)是一个数组(集合)里找到和为0的组合,可就难很多了!**用哈希法解决了两数之和,很多同学会感觉用哈希法也可以解决三数之和,四数之和。其实是可以解决,但是非常麻烦,需要去重导致代码效率很低。
在15.三数之和 (opens new window)中我给出了哈希法和双指针两个解法,大家就可以体会到,使用哈希法还是比较麻烦的。所以18. 四数之和,15.三数之和都推荐使用双指针法!
四、字符串
1. 反转字符串
- 打基础的时候,不要太迷恋于库函数。
1.1 我的
- 很简单,就是原地替换就行
class Solution {
public:
void reverseString(vector<char>& s) {
char temp;
for(int i=0,j=s.size()-1;i<j;i++,j--){
temp=s[i];
s[i]=s[j];
s[j]=temp;
}
return ;
}
};
1.2 随想录
-
用C++里的一个库函数 reverse,调一下直接完事了, 相信每一门编程语言都有这样的库函数。
-
**如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。**毕竟面试官一定不是考察你对库函数的熟悉程度, 如果使用python和java 的同学更需要注意这一点,因为python、java提供的库函数十分丰富。
-
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
-
字符串也是一种数组,所以元素在内存中是连续分布,这就决定了反转链表和反转字符串方式上还是有所差异的。
-
循环里只要做交换s[i] 和s[j]操作就可以了,那么我这里使用了swap 这个库函数。大家可以使用。swap可以有两种实现:
-
一种就是常见的交换数值:
int tmp = s[i];
s[i] = s[j];
s[j] = tmp;
- 一种就是通过位运算:(这个以前学过但是现在忘了,就是A=A^B,然后A表示该位置上两者是否相等,【相等用0表示,这样原来是1还是1,原来是0还是0;需要变化用1表示,这样原来是1就变成了0 ,原来是0就变成了1】,B=A^B,这样经过A的指导,原来的B就成了A,然后A=A^B,相当于原来的A(现在在B中)接受A指导,变成原来的B)。
s[i] ^= s[j];
s[j] ^= s[i];
s[i] ^= s[j];
- 在字符串相关的题目中,库函数对大家的诱惑力是非常大的,因为会有各种反转,切割取词之类的操作,这也是为什么字符串的库函数这么丰富的原因。
2.反转字符串2
2.1 我的
- 也很简单,就是前k个反转,后k个跳过,不够了前者直接反转,后者直接退出:
class Solution {
public:
string reverseStr(string s, int k) {
int i=0;
while(i<s.size()){
if(i+k<s.size()){
reverse(s.begin()+i,s.begin()+i+k);
}else{
reverse(s.begin()+i,s.end());
}
i=i+k;
if(i+k<s.size()){
i+=k;
}else{
break;
}
}
return s;
}
};
2.2 随想录
- 是模拟,实现题目中规定的反转规则就可以了。
- 在遍历字符串的过程中,只要让 i += (2 * k),i 每次移动 2 * k 就可以了,然后判断是否需要有反转的区间。因为要找的也就是每2 * k 区间的起点,这样写,程序会高效很多。所以当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
class Solution {
public:
void reverse(string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
string reverseStr(string s, int k) {
for (int i = 0; i < s.size(); i += (2 * k)) {
// 1. 每隔 2k 个字符的前 k 个字符进行反转
// 2. 剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符
if (i + k <= s.size()) {
reverse(s, i, i + k - 1);
continue;
}
// 3. 剩余字符少于 k 个,则将剩余字符全部反转。
reverse(s, i, s.size() - 1);
}
return s;
}
};
- 还有一种方法,和我们的方法类似,启发在于后半段中不需要判断,因为会直接退出,直接加2k就行了:
class Solution {
public:
string reverseStr(string s, int k) {
int n = s.size(),pos = 0;
while(pos < n){
//剩余字符串大于等于k的情况
if(pos + k < n) reverse(s.begin() + pos, s.begin() + pos + k);
//剩余字符串不足k的情况
else reverse(s.begin() + pos,s.end());
pos += 2 * k;
}
return s;
}
};
3. 替换数字
3.1 我的
- 逐个判断,因为不需要返回只需要输出,因此检测到数字就输出number就行了;如果要返回那就设计一个新的字符串存放新的字符串,因此需要先扫描一遍来确定新字符串的大小。感觉我的方法应该不是最好的,没什么写出来的意义。
- 下面给的方法更好,原地更新大小,直接将字符串大小resize,然后从后向前填充。
#include<iostream>
using namespace std;
int main(){
string s;
cin>>s;
int count=0;
int nows=s.size();
for(int i=0;i<nows;i++){
if(s[i]>='0' and s[i]<='9'){//别忘了等于
count++;
}
}
// if(count==0){ //小心这个输出格式会重复输出,输完要直接return
// cout<<s<<endl;
// }
s.resize(nows+count*5);//因为本身就有一个大小,只需要再扩大5个
int news=s.size();
for(int i=nows-1,j=news-1;j>i;j--,i--){//别忘了是size()-1
if(s[i]>='0' and s[i]<='9'){
s[j] = 'r';
s[j - 1] = 'e';
s[j - 2] = 'b';
s[j - 3] = 'm';
s[j - 4] = 'u';
s[j - 5] = 'n';
j -= 5;
}else{
s[j]=s[i];
}
}
cout<<s<<endl;
}
3.2 随想录
-
首先扩充数组到每个数字字符替换成 “number” 之后的大小,从后向前填充,也就是双指针法,过程如下:i指向新长度的末尾,j指向旧长度的末尾。
-
从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素整体向后移动。其实很多数组填充类的问题,其做法都是先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
这么做有两个好处:
- 不用申请新数组。
- 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
-
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,在C语言中,把一个字符串存入一个数组时,也把结束符 ‘\0’存入数组,并以此作为该字符串是否结束的标志;在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用’\0’来判断是否结束。
-
那么vector< char > 和 string 又有什么区别呢?其实在基本操作上没有区别,但是 string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。所以想处理字符串,我们还是会定义一个string类型。
-
不知道为啥会用一个while输入,上面测试了去掉也能通过:
#include<iostream>
using namespace std;
int main() {
string s;
while (cin >> s) {
int count = 0; // 统计数字的个数
int sOldSize = s.size();
for (int i = 0; i < s.size(); i++) {
if (s[i] >= '0' && s[i] <= '9') {
count++;
}
}
// 扩充字符串s的大小,也就是每个空格替换成"number"之后的大小
s.resize(s.size() + count * 5);
int sNewSize = s.size();
// 从后先前将空格替换为"number"
for (int i = sNewSize - 1, j = sOldSize - 1; j < i; i--, j--) {
if (s[j] > '9' || s[j] < '0') {
s[i] = s[j];
} else {
s[i] = 'r';
s[i - 1] = 'e';
s[i - 2] = 'b';
s[i - 3] = 'm';
s[i - 4] = 'u';
s[i - 5] = 'n';
i -= 5;
}
}
cout << s << endl;
}
}
4. 翻转字符串里的单词
- 综合考察字符串操作的好题。
4.1 我的
- 新建一个一样大小的字符串,然后一个从前向后(找到每个单词),一个从后向前(也是每个单词放入)。感觉也没有用代码实现的必要。
class Solution {
public:
string reverseWords(string s) {
if(s.size()==0){
return s;
}
int i=0,j=0;
if(s[i]==' '){ //处理开头空格
while(j<s.size() and s[j]==' '){
j++;
}
s[i]=s[j++];
}
for(;j<s.size();j++){ //处理中间空格
if(i!=j and (s[i]!=' ' or s[j]!=' ')){
s[++i]=s[j];
}
}
if(s[i]==' '){ //处理结尾空格
i--;
}
printf("%s",s.c_str());
s.resize(i+1);
for(int j=0,k=i;j<k;j++,k--){
s[k]^=s[j];
s[j]^=s[k];
s[k]^=s[j];
}
for(int j=0;j<=i;j++){
int m,k;
if(s[j]!=' '){
m=j;
while(j<=i and s[j]!=' '){
j++;
}
k=j-1;
for(;m<k;m++,k--){
s[k]^=s[m];
s[m]^=s[k];
s[k]^=s[m];
}
}
}
return s;
}
};
4.2 随想录
-
综合考察了字符串的多种操作。
-
一些同学会使用split库函数,分隔单词,然后定义一个新的string字符串,最后再把单词倒序相加,那么这道题题目就是一道水题了,失去了它的意义。
-
所以这里我还是提高一下本题的难度:**不要使用辅助空间,空间复杂度要求为O(1)。**不能使用辅助空间之后,那么只能在原字符串上下功夫了。想一下,我们将整个字符串都反转过来,那么单词的顺序指定是倒序了,只不过单词本身也倒序了,那么再把单词反转一下,单词不就正过来了。
-
所以解题思路如下:
- 移除多余空格
- 将整个字符串反转
- 将每个单词反转
-
遇到空格了就erase。如果不仔细琢磨一下erase的时间复杂度,还以为以上的代码是O(n)的时间复杂度呢。想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作。erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
-
有的同学可能发现用erase来移除空格,在leetcode上性能也还行。主要是以下几点;:
- leetcode上的测试集里,字符串的长度不够长,如果足够长,性能差距会非常明显。
- leetcode的测程序耗时不是很准确的。
-
移除多余空格:这部分和27.移除元素 (opens new window)的逻辑是一样一样的,本题是移除空格,而 27.移除元素 就是移除元素。
-
将每个单词反转:这个实现我们分别在344.反转字符串 (opens new window)和541.反转字符串II (opens new window)里已经讲过了。
class Solution {
public:
void reverse(string& s, int start, int end){ //翻转,区间写法:左闭右闭 []
for (int i = start, j = end; i < j; i++, j--) {
swap(s[i], s[j]);
}
}
void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
int slow = 0; //整体思想参考https://programmercarl.com/0027.移除元素.html
for (int i = 0; i < s.size(); ++i) { //
if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
s[slow++] = s[i++];
}
}
}
s.resize(slow); //slow的大小即为去除多余空格后的大小。
}
string reverseWords(string s) {
removeExtraSpaces(s); //去除多余空格,保证单词之间之只有一个空格,且字符串首尾没空格。
reverse(s, 0, s.size() - 1);
int start = 0; //removeExtraSpaces后保证第一个单词的开始下标一定是0。
for (int i = 0; i <= s.size(); ++i) {
if (i == s.size() || s[i] == ' ') { //到达空格或者串尾,说明一个单词结束。进行翻转。
reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
start = i + 1; //更新下一个单词的开始下标start
}
}
return s;
}
};
- 可以学习的有对于空格的处理过程:
- 快指针直接跳过所有的空格,每当遇见非空格相当于找到单词,将该单词(空格前且不超出数组范围加入到慢指针中);
- 若是当前慢指针不是空格,那就需要补一个空格,当然开头不需要补空格,这样还可以跳过开头的空格;
- 快指针的直接跳过避免了处理末尾空格,避免结尾控股的加入。
5. 右旋转字符串
5.1 我的
- 我想到的还是模拟的方法,没有意义。
- 参考给出的方法(相当于题目加了一条要求:只在本字符串内进行),两段反转,先整体反转,然后两部分分别反转就好:
#include<iostream>
using namespace std;
int main(){
string s;
int k;
cin>>k;
cin>>s;
for(int i=0,j=s.size()-1;i<j;j--,i++){
s[i]^=s[j];
s[j]^=s[i];
s[i]^=s[j];
}
for(int i=0,j=k-1;i<j;i++,j--){ //注意前半段需要反转的范围才是原来在后面的需要旋转的范围
s[i]^=s[j];
s[j]^=s[i];
s[i]^=s[j];
}
for(int i=k,j=s.size()-1;i<j;i++,j--){
s[i]^=s[j];
s[j]^=s[i];
s[i]^=s[j];
}
cout<<s<<endl;
return 0;
}
5.2 随想录
- 为了让本题更有意义,提升一下本题难度:不能申请额外空间,只能在本串上操作。 (Java不能在字符串上修改,所以使用java一定要开辟新空间)
- 我们需要将字符串右移n位,字符串相当于分成了两个部分,如果n为2,符串相当于分成了两个部分。右移n位, 就是将第二段放在前面,第一段放在后面,先不考虑里面字符的顺序,是不是整体倒叙不就行了。此时第一段和第二段的顺序是我们想要的,但里面的字符位置被我们倒叙,那么此时我们在把 第一段和第二段里面的字符再倒叙一把,这样字符顺序不就正确了。
- 思路就是 通过 整体倒叙,把两段子串顺序颠倒,两个段子串里的的字符在倒叙一把,负负得正,这样就不影响子串里面字符的顺序了。
- 那么整体反正的操作放在下面,先局部反转行不行?可以的,不过,要记得 控制好 局部反转的长度,如果先局部反转,那么先反转的子串长度就是 len - n。
- 大家在做剑指offer的时候,会发现 剑指offer的题目是左反转,那么左反转和右反转 有什么区别呢?其实思路是一样一样的,就是反转的区间不同而已。
// 版本一
#include<iostream>
#include<algorithm>
using namespace std;
int main() {
int n;
string s;
cin >> n;
cin >> s;
int len = s.size(); //获取长度
reverse(s.begin(), s.end()); // 整体反转
reverse(s.begin(), s.begin() + n); // 先反转前一段,长度n
reverse(s.begin() + n, s.end()); // 再反转后一段
cout << s << endl;
}
// 版本二
#include<iostream>
#include<algorithm>
using namespace std;
int main() {
int n;
string s;
cin >> n;
cin >> s;
int len = s.size(); //获取长度
reverse(s.begin(), s.begin() + len - n); // 先反转前一段,长度len-n ,注意这里是和版本一的区别
reverse(s.begin() + len - n, s.end()); // 再反转后一段
reverse(s.begin(), s.end()); // 整体反转
cout << s << endl;
}
6. 实现strStr()
28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
- 在一个串中查找是否出现过另一个串,这是KMP的看家本领。
6.1 我的
- 重新拾起了KMP算法,代码随想录文字版有点太长了,看的视频版本的,详见另一篇笔记~
class Solution {
public:
void get_next(int* next, string needle){
int j=0;
next[0]=0;
for(int i=1;i<needle.size();i++){
while(j>0 and needle[j]!=needle[i]){
j=next[j-1];
}
if(needle[j]==needle[i]){
j++;
}
next[i]=j;
}
}
int strStr(string haystack, string needle) {
// int flag=-1;
int next[needle.size()];
get_next(next, needle);
int i=0,j=0;
for(;i<haystack.size();i++){//不能用while因为这样可能导致i不会向后推移,最终陷入死循环
while(j>0 and needle[j]!=haystack[i]){
j=next[j-1];
}
if(needle[j]==haystack[i]){
j++;
if(j==needle.size()){
return i-j+1;
}
}
}
return -1;
}
};
6.2 随想录
-
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
-
把KMP的每一个细微的细节都扣了出来
class Solution {
public:
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
int next[needle.size()];
getNext(next, needle);
int j = 0;
for (int i = 0; i < haystack.size(); i++) {
while(j > 0 && haystack[i] != needle[j]) {
j = next[j - 1];
}
if (haystack[i] == needle[j]) {
j++;
}
if (j == needle.size() ) {
return (i - needle.size() + 1);
}
}
return -1;
}
};
6.2.1 什么是KMP(这里文字版太长了,等回来再看吧,看完视频就能自己敲出来代码了)
视频版学习笔记放到另一篇中了。
7. 重复的子字符串
7.1 我的
- 最直接的想法是暴力,但是肯定有更好的方法,标题下有提到用kmp,自己先想想,kmp的好处是避免重复判断,这正是我们需要的,因此感觉是将整个字符串作为模式串来计算next数组。
- 因为这里的重复构成是指的只有字串,因此计算整个字符串的next数组,然后检查next数组是否满足:第一个非0位-1为子串长度,然后每隔这么多检查对应位置的next数组是否为该值的倍数。
- 可以通过部分测试用例,但是对于字串本身存在一定重复的用例无法处理,仔细看应当是一连串增加的,也就是恒增才是子重复的本质,也就是要从后向前找到,字符串的长度减去最后一个的next的长度剩下的应该是子串的长度,然后查找对应位置是否满足倍数规律。通过!(看了下面的讲解突然发现,如果是单调增的,那么一定满足倍数关系,而最大前缀一定是一点一点增出来的,因此不需要检查是否满足倍数关系)
class Solution {
public:
void get_next(int* next, string needle){
int j=0;
next[0]=0;
for(int i=1;i<needle.size();i++){
while(j>0 and needle[j]!=needle[i]){
j=next[j-1];
}
if(needle[j]==needle[i]){
j++;
}
next[i]=j;
}
}
bool repeatedSubstringPattern(string s) {
int next[s.size()];
get_next(next, s);
int i=s.size()-next[s.size()-1];
// int i=0;
// for(;i<s.size();i++){
// if(next[i]!=0){
// break;
// }
// }
if(i==0 or s.size()%i!=0){//表示没有重复的或者长度不是子串的倍数
return false;
}
for(int k=1,j=(k+1)*i-1;j<s.size();k++,j=(k+1)*i-1){
if(next[j]!=k*i){
return false;
}
}
return true;
}
};
7.2 随想录
-
暴力的解法, 就是一个for循环获取 子串的终止位置, 然后判断子串是否能重复构成字符串,又嵌套一个for循环,所以是O(n^2)的时间复杂度。我们只需要判断,以第一个字母为开始的子串就可以,所以一个for循环获取子串的终止位置就行了。 而且遍历的时候 都不用遍历结束,只需要遍历到中间位置,因为子串结束位置大于中间位置的话,一定不能重复组成字符串。
-
移动匹配法:如果是子串,从中间开始一定是一样的(不是指偶数情况,这里指的是将整个字符串看成一个S,然后在S+S(掐头去尾后)中查找S,出现则证明有重复,因为S+S中表示S的尾串也可以作为头串,但是下面的例子给的不太恰当吧,但是很好理解)。
-
当一个字符串s:abcabc,内部由重复的子串组成,那么这个字符串的结构由前后相同的子串组成。
-
既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s,
-
我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符,这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
-
不过这种解法还有一个问题,就是 我们最终还是要判断 一个字符串(s + s)是否出现过 s 的过程,大家可能直接用contains,find 之类的库函数。 却忽略了实现这些函数的时间复杂度(暴力解法是m * n,一般库函数实现为 O(m + n))。
如果我们做过 28.实现strStr (opens new window)题目的话,其实就知道,实现一个 高效的算法来判断 一个字符串中是否出现另一个字符串是很复杂的,这里就涉及到了KMP算法。
class Solution { public: bool repeatedSubstringPattern(string s) { string t = s + s; t.erase(t.begin()); t.erase(t.end() - 1); // 掐头去尾 if (t.find(s) != std::string::npos) return true; // r return false; } };
-
-
KMP法:在一个串中查找是否出现过另一个串,这是KMP的看家本领。那么寻找重复子串怎么也涉及到KMP算法了呢?
KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一个匹配过的位置继续匹配,靠的是有计算好的前缀表。 前缀表里,统计了各个位置为终点字符串的最长相同前后缀的长度。
那么 最长相同前后缀和重复子串的关系又有什么关系呢。
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串,这里拿字符串s:abababab 来举例,ab就是最小重复单位,为啥一定是开头的ab呢。 其实最关键还是要理解 最长相等前后缀:
-
步骤一:因为 这是相等的前缀和后缀,t[0] 与 k[0]相同, t[1] 与 k[1]相同,所以 s[0] 一定和 s[2]相同,s[1] 一定和 s[3]相同,即:,s[0]s[1]与s[2]s[3]相同 。
-
步骤二: 因为在同一个字符串位置,所以 t[2] 与 k[0]相同,t[3] 与 k[1]相同。
-
步骤三: 因为 这是相等的前缀和后缀,t[2] 与 k[2]相同 ,t[3]与k[3] 相同,所以,s[2]一定和s[4]相同,s[3]一定和s[5]相同,即:s[2]s[3] 与 s[4]s[5]相同。
-
步骤四:循环往复。
所以字符串s,s[0]s[1]与s[2]s[3]相同, s[2]s[3] 与 s[4]s[5]相同,s[4]s[5] 与 s[6]s[7] 相同。
正是因为 最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串(也就是长度减去最大值剩下的部分)。
-
-
数学推理:
- 假设字符串s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。
- 因为字符串s的最长相同前后缀的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且 n - m = 1,(这里如果不懂,看上面的推理)
- 所以如果 nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
- next 数组记录的就是最长相同前后缀,如果 next[len - 1] != -1,则说明字符串有最长相同的前后缀。
- 最长相等前后缀的长度为:next[len - 1] + 1。(这里的next数组是以统一减一的方式计算的,因此需要+1)
- 数组长度为:len。如果len % (len - (next[len - 1] + 1)) == 0 ,则说明数组的长度正好可以被 (数组长度-最长相等前后缀的长度) 整除 ,说明该字符串有重复的子字符串。
- 数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。
-
强烈建议大家把next数组打印出来,看看next数组里的规律,有助于理解KMP算法
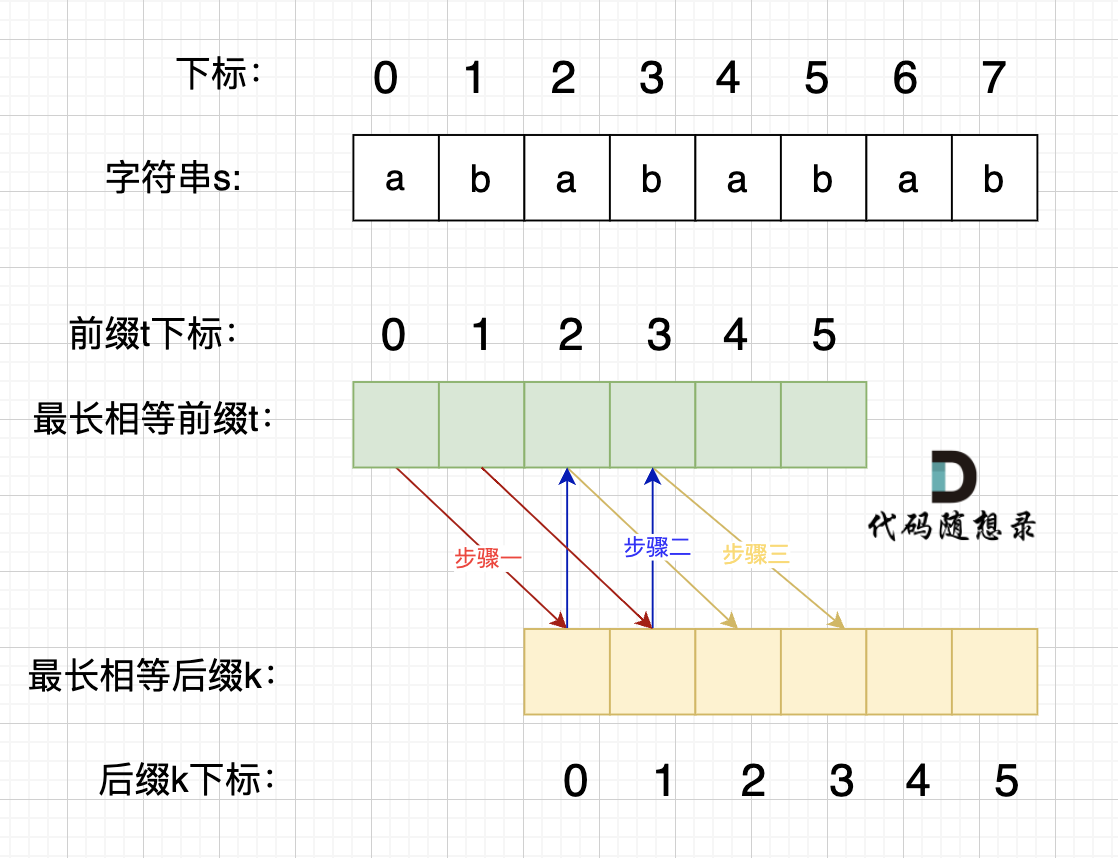
class Solution {
public:
void getNext (int* next, const string& s){
next[0] = 0;
int j = 0;
for(int i = 1;i < s.size(); i++){
while(j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if(s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern (string s) {
if (s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if (next[len - 1] != 0 && len % (len - (next[len - 1] )) == 0) {
return true;
}
return false;
}
};
8. 总结篇
-
字符串类类型的题目,往往想法比较简单,但是实现起来并不容易,复杂的字符串题目非常考验对代码的掌控能力。字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定:
- 在C语言中,把一个字符串存入一个数组时,也把结束符 '\0’存入数组,并以此作为该字符串是否结束的标志。
- vector< char > 和 string 又有什么区别:在基本操作上没有区别,但是 string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。
-
强调了打基础的时候,不要太迷恋于库函数。
-
**双指针法在数组,链表和字符串中很常用。**双指针法是字符串处理的常客。
- 在字符串:替换空格 (opens new window),同样还是使用双指针法在时间复杂度O(n)的情况下完成替换空格。其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
- 一些同学会使用for循环里调用库函数erase来移除元素,这其实是O(n^2)的操作,因为erase就是O(n)的操作,所以这也是典型的不知道库函数的时间复杂度,上来就用的案例了。
-
反转:
-
在反转上还可以在加一些玩法,其实考察的是对代码的掌控能力。
541. 反转字符串II (opens new window)中,一些同学可能为了处理逻辑:每隔2k个字符的前k的字符,写了一堆逻辑代码或者再搞一个计数器,来统计2k,再统计前k个字符。
其实当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。要找的也就是每2 * k 区间的起点,这样写程序会高效很多。
-
在151.翻转字符串里的单词 (opens new window)中要求翻转字符串里的单词,这道题目可以说是综合考察了字符串的多种操作。是考察字符串的好题。
这道题目通过 先整体反转再局部反转,实现了反转字符串里的单词。
后来发现反转字符串还有一个牛逼的用处,就是达到左旋的效果。
-
-
KMP算法是字符串查找最重要的算法,但彻底理解KMP并不容易,我们已经写了五篇KMP的文章,不断总结和完善,最终才把KMP讲清楚。KMP的主要思想是**当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。**KMP的精髓所在就是前缀表,在KMP精讲 (opens new window)中提到了,什么是KMP,什么是前缀表,以及为什么要用前缀表。前缀表:起始位置到下标i之前(包括i)的子串中,有多大长度的相同前缀后缀。
- 那么使用KMP可以解决两类经典问题:
- 匹配问题:28. 实现 strStr()(opens new window)
- 重复子串问题:459.重复的子字符串
- 然后针对前缀表到底要不要减一,这其实是不同KMP实现的方式
- 其中主要理解j=next[x]这一步最为关键!
- 那么使用KMP可以解决两类经典问题:
五、双指针法
其实题目已经全部写过了,因此这里只是再总结一下
1. 移除元素
2. 反转字符串
3. 替换数字
4. 翻转字符串里的单词
5.翻转链表
6. 删除链表的倒数第N个节点
19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode)
7. 链表相交
面试题 02.07. 链表相交 - 力扣(LeetCode)
8. 环形链表2
https://leetcode.cn/problems/reverse-linked-list/description/
9. 三数之和
https://leetcode.cn/problems/reverse-linked-list/description/
10. 四数之和
https://leetcode.cn/problems/reverse-linked-list/description/
11. 数字那个指针总结
- 双指针法并不隶属于某一种数据结构,我们在讲解数组,链表,字符串都用到了双指针法,所有有必要针对双指针法做一个总结。
- 本文中一共介绍了leetcode上九道使用双指针解决问题的经典题目,除了链表一些题目一定要使用双指针,其他题目都是使用双指针来提高效率,一般是将O(n^2)的时间复杂度,降为 O ( n ) O(n) O(n)。
11.1 数组
-
在数组:就移除个元素很难么? (opens new window)中,原地移除数组上的元素,我们说到了数组上的元素,不能真正的删除,只能覆盖。
-
一些同学可能会写出如下代码(伪代码):
for (int i = 0; i < array.size(); i++) { if (array[i] == target) { array.erase(i); } }这个代码看上去好像是O(n)的时间复杂度,其实是O(n^2)的时间复杂度,因为erase操作也是O(n)的操作。
所以此时使用双指针法才展现出效率的优势:通过两个指针在一个for循环下完成两个for循环的工作。
11.2 字符串
在字符串:这道题目,使用库函数一行代码搞定 (opens new window)中讲解了反转字符串,注意这里强调要原地反转,要不然就失去了题目的意义。
使用双指针法,定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。,时间复杂度是O(n)。
在替换空格 (opens new window)中介绍使用双指针填充字符串的方法,如果想把这道题目做到极致,就不要只用额外的辅助空间了!
思路就是首先扩充数组到每个空格替换成"%20"之后的大小。然后双指针从后向前替换空格。
有同学问了,为什么要从后向前填充,从前向后填充不行么?
从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
其实很多数组(字符串)填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。
那么在字符串:花式反转还不够! (opens new window)中,我们使用双指针法,用O(n)的时间复杂度完成字符串删除类的操作,因为题目要删除冗余空格。
在删除冗余空格的过程中,如果不注意代码效率,很容易写成了O(n^2)的时间复杂度。其实使用双指针法O(n)就可以搞定。
主要还是大家用erase用的比较随意,一定要注意for循环下用erase的情况,一般可以用双指针写效率更高!
11.3 链表
翻转链表是现场面试,白纸写代码的好题,考察了候选者对链表以及指针的熟悉程度,而且代码也不长,适合在白纸上写。
在链表:听说过两天反转链表又写不出来了? (opens new window)中,讲如何使用双指针法来翻转链表,只需要改变链表的next指针的指向,直接将链表反转 ,而不用重新定义一个新的链表。
思路还是很简单的,代码也不长,但是想在白纸上一次性写出bugfree的代码,并不是容易的事情。
在链表中求环,应该是双指针在链表里最经典的应用,在链表:环找到了,那入口呢? (opens new window)中讲解了如何通过双指针判断是否有环,而且还要找到环的入口。
使用快慢指针(双指针法),分别定义 fast 和 slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
那么找到环的入口,其实需要点简单的数学推理,我在文章中把找环的入口清清楚楚的推理的一遍,如果对找环入口不够清楚的同学建议自己看一看链表:环找到了,那入口呢? (opens new window)。
11.4 N数和
在哈希表:解决了两数之和,那么能解决三数之和么? (opens new window)中,讲到使用哈希法可以解决1.两数之和的问题
其实使用双指针也可以解决1.两数之和的问题,只不过1.两数之和求的是两个元素的下标,没法用双指针,如果改成求具体两个元素的数值就可以了。
使用了哈希法解决了两数之和,但是哈希法并不使用于三数之和!
使用哈希法的过程中要把符合条件的三元组放进vector中,然后在去去重,这样是非常费时的,很容易超时,也是三数之和通过率如此之低的根源所在。去重的过程不好处理,有很多小细节,如果在面试中很难想到位。时间复杂度可以做到O(n^2),但还是比较费时的,因为不好做剪枝操作。
所以这道题目使用双指针法才是最为合适的,用双指针做这道题目才能就能真正体会到,通过前后两个指针不算向中间逼近,在一个for循环下完成两个for循环的工作。
只用双指针法时间复杂度为O(n^2),但比哈希法的O(n^2)效率高得多,哈希法在使用两层for循环的时候,能做的剪枝操作很有限。
在双指针法:一样的道理,能解决四数之和 (opens new window)中,讲到了四数之和,其实思路是一样的,**在三数之和的基础上再套一层for循环,依然是使用双指针法。**对于三数之和使用双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。同样的道理,五数之和,n数之和都是在这个基础上累加。
六、栈与队列
1. 栈与队列理论基础
-
队列是先进先出,栈是先进后出。
-
四个关于栈的问题,以下是以C++为例,使用其他编程语言的同学也对应思考一下,自己使用的编程语言里栈和队列是什么样的。
- C++中stack 是容器么?
- 我们使用的stack是属于哪个版本的STL?
- 我们使用的STL中stack是如何实现的?
- stack 提供迭代器来遍历stack空间么?
-
栈和队列是STL(C++标准库)里面的两个数据结构。C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。那么来介绍一下,三个最为普遍的STL版本:
- HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
- P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
- SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
-
接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。
-
栈先进后出,栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。
-
那么STL 中栈是用什么容器实现的?从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为缺省情况下栈的底层结构。deque是一个双向队列,只要封住一段,只开通另一端就可以实现栈的逻辑了。
-
**SGI STL中 队列底层实现缺省情况下一样使用deque实现的。**我们也可以指定vector为栈的底层实现,初始化语句如下:
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈 -
对应的队列的情况是一样的。队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器, **SGI STL中队列一样是以deque为缺省情况下的底部结构。**也可以指定list 为起底层实现,初始化queue的语句如下:
std::queue<int, std::list<int>> third; // 定义以list为底层容器的队列所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
我这里讲的都是C++ 语言中的情况, 使用其他语言的同学也要思考栈与队列的底层实现问题, 不要对数据结构的使用浅尝辄止,而要深挖其内部原理,才能夯实基础。
2. 用栈实现队列
- 工作上一定没人这么搞,但是考察对栈、队列理解程度的好题
2.1 我的
- 设置两个栈A和B,当需要加入时,保证数据在A中,向A末尾加入,当需要弹出时,保证数据在B中(数据一定是从A中弹出放入进来的),头元素代表表示数据在B中则返回第一个,当A和B都是空时返回true。
class MyQueue {
public:
stack<int> A;
stack<int> B;
int flag=0;
MyQueue() {
}
void push(int x) {
if(flag==0){
A.push(x);
}else{
while(!B.empty()){
int y=B.top();
B.pop();
A.push(y);
}
flag=0;
A.push(x);
}
}
int pop() {
if(flag==0){
while(!A.empty()){
int y=A.top();
A.pop();
B.push(y);
}
flag=1;
}
int y=B.top();
B.pop();
return y;
}
int peek() {
if(flag==0){
while(!A.empty()){
int y=A.top();
A.pop();
B.push(y);
}
flag=1;
}
int y=B.top();
return y;
}
bool empty() {
return A.empty() && B.empty();
}
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/
2.2 随想录笔记
-
模拟题,不涉及到具体算法,考察的就是对栈和队列的掌握程度。
使用栈来模式队列的行为,如果仅仅用一个栈,是一定不行的,所以需要两个栈一个输入栈,一个输出栈,这里要注意输入栈和输出栈的关系。
-
在push数据的时候,只要数据放进输入栈就好,但在pop的时候,操作就复杂一些,输出栈如果为空(相比我们的方法这样可以减少栈间的移动,相当于将队列分开存放了),就把进栈数据全部导入进来(注意是全部导入),再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
最后如何判断队列为空呢?如果进栈和出栈都为空的话,说明模拟的队列为空了。
-
代码非常漂亮:
class MyQueue {
public:
stack<int> stIn;
stack<int> stOut;
/** Initialize your data structure here. */
MyQueue() {
}
/** Push element x to the back of queue. */
void push(int x) {
stIn.push(x);
}
/** Removes the element from in front of queue and returns that element. */
int pop() {
// 只有当stOut为空的时候,再从stIn里导入数据(导入stIn全部数据)
if (stOut.empty()) {
// 从stIn导入数据直到stIn为空
while(!stIn.empty()) {
stOut.push(stIn.top());
stIn.pop();
}
}
int result = stOut.top();
stOut.pop();
return result;
}
/** Get the front element. */
int peek() {
int res = this->pop(); // 直接使用已有的pop函数
stOut.push(res); // 因为pop函数弹出了元素res,所以再添加回去
return res;
}
/** Returns whether the queue is empty. */
bool empty() {
return stIn.empty() && stOut.empty();
}
};
-
可以看出peek()的实现,直接复用了pop(), 要不然,对stOut判空的逻辑又要重写一遍。再多说一些代码开发上的习惯问题,在工业级别代码开发中,最忌讳的就是 实现一个类似的函数,直接把代码粘过来改一改就完事了。这样的项目代码会越来越乱,一定要懂得复用,功能相近的函数要抽象出来,不要大量的复制粘贴,很容易出问题!(踩过坑的人自然懂)
-
工作中如果发现某一个功能自己要经常用,同事们可能也会用到,自己就花点时间把这个功能抽象成一个好用的函数或者工具类,不仅自己方便,也方便了同事们。
3. 用队列实现栈
- 用队列实现栈还是有点别扭。
3.1 我的
- 还是两个队列,一个负责压入,一个复制输出。
class MyStack {
public:
queue<int> A;
queue<int> B;
int flag=0;
MyStack() {
}
void push(int x) {
if(flag==0){
B.push(x);
while(!A.empty()){
int y=A.front();
A.pop();
B.push(y);
}
flag=1;
}else{
A.push(x);
while(!B.empty()){
int y=B.front();
B.pop();
A.push(y);
}
flag=0;
}
}
int pop() {
int y;
if(flag==0 and !A.empty()){
y=A.front();
A.pop();
}else if(flag==1 and !B.empty()){
y=B.front();
B.pop();
}
return y;
}
int top() {
int y;
if(flag==0 and !A.empty()){
y=A.front();
}else if(flag==1 and !B.empty()){
y=B.front();
}
return y;
}
bool empty() {
return B.empty() and A.empty();
}
};
/**
* Your MyStack object will be instantiated and called as such:
* MyStack* obj = new MyStack();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->top();
* bool param_4 = obj->empty();
*/
3.2 随想录笔记
- 有的同学可能疑惑这种题目有什么实际工程意义,其实很多算法题目主要是对知识点的考察和教学意义远大于其工程实践的意义,所以面试题也是这样!
- 队列模拟栈,其实一个队列就够了,那么我们先说一说两个队列来实现栈的思路。队列是先进先出的规则,把一个队列中的数据导入另一个队列中,数据的顺序并没有变,并没有变成先进后出的顺序。(感觉这个方法不如我的清晰)
- 其实这道题目就是用一个队列就够了。一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时再去弹出元素就是栈的顺序了。
class MyStack {
public:
queue<int> que;
/** Initialize your data structure here. */
MyStack() {
}
/** Push element x onto stack. */
void push(int x) {
que.push(x);
}
/** Removes the element on top of the stack and returns that element. */
int pop() {
int size = que.size();
size--;
while (size--) { // 将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部
que.push(que.front());
que.pop();
}
int result = que.front(); // 此时弹出的元素顺序就是栈的顺序了
que.pop();
return result;
}
/** Get the top element. */
int top() {
return que.back();
}
/** Returns whether the stack is empty. */
bool empty() {
return que.empty();
}
};
4. 有效的括号
- 数据结构与算法应用往往隐藏在我们看不到的地方
4.1 我的
- 其实没看懂({})这种属于对还是错,感觉的意思是不用管,需要的话在押入的时候后多加些判断就好。
class Solution {
public:
bool isValid(string s) {
int n=s.size();
stack<int> ss;
for(int i=0;i<n;i++){
if(s[i]=='(' or s[i]=='[' or s[i]=='{'){
ss.push(s[i]);
}else{
if(s[i]==')'){
if(!ss.empty() and ss.top()=='('){
ss.pop();
}else{
return false;
}
}else if(s[i]==']'){
if(!ss.empty() and ss.top()=='['){
ss.pop();
}else{
return false;
}
}else if(s[i]=='}'){
if(!ss.empty() and ss.top()=='{'){
ss.pop();
}else{
return false;
}
}
}
}
if(!ss.empty()){
return false;
}
return true;
}
};
4.2 随想录笔记
-
扩展:**括号匹配是使用栈解决的经典问题。**题意其实就像我们在写代码的过程中,要求括号的顺序是一样的,有左括号,相应的位置必须要有右括号。如果还记得编译原理的话,编译器在 词法分析的过程中处理括号、花括号等这个符号的逻辑,也是使用了栈这种数据结构。再举个例子,linux系统中,cd这个进入目录的命令我们应该再熟悉不过了。
cd a/b/c/../../这个命令最后进入a目录,系统是如何知道进入了a目录呢 ,这就是栈的应用(其实可以出一道相应的面试题了)。所以栈在计算机领域中应用是非常广泛的。所以数据结构与算法的应用往往隐藏在我们看不到的地方!
-
由于栈结构的特殊性,非常适合做对称匹配类的题目。首先要弄清楚,字符串里的括号不匹配有几种情况。一些同学,在面试中看到这种题目上来就开始写代码,然后就越写越乱。建议在写代码之前要分析好有哪几种不匹配的情况,如果不在动手之前分析好,写出的代码也会有很多问题。
-
先来分析一下 这里有三种不匹配的情况,我们的代码只要覆盖了这三种不匹配的情况,就不会出问题,可以看出 动手之前分析好题目的重要性。
- 第一种情况,字符串里左方向的括号多余了 ,所以不匹配。已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false
- 第二种情况,括号没有多余,但是 括号的类型没有匹配上。遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false
- 第三种情况,字符串里右方向的括号多余了,所以不匹配。遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false
-
字符串遍历完之后,栈是空的,就说明全都匹配了。分析完之后,代码其实就比较好写了,但还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了!
class Solution {
public:
bool isValid(string s) {
if (s.size() % 2 != 0) return false; // 如果s的长度为奇数,一定不符合要求
stack<char> st;
for (int i = 0; i < s.size(); i++) {
if (s[i] == '(') st.push(')');
else if (s[i] == '{') st.push('}');
else if (s[i] == '[') st.push(']');
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
else if (st.empty() || st.top() != s[i]) return false;
else st.pop(); // st.top() 与 s[i]相等,栈弹出元素
}
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
return st.empty();
}
};
5. 删除字符串中的所有相邻重复项
1047. 删除字符串中的所有相邻重复项 - 力扣(LeetCode)
- 匹配问题都是栈的强项
5.1 我的
- 用栈来解决,当前字母与栈顶相同则弹出,否则加入,最后要返回字符串,因此将原字符串resize并返回即可:
class Solution {
public:
string removeDuplicates(string s) {
stack<char> st;
int length=0;
if(s.size()==0){
return s;
}
st.push(s[0]);
length++;
for(int i=1;i<s.size();i++){
if(!st.empty() and s[i]==st.top()){
st.pop();
length--;
}else{
st.push(s[i]);
length++;
}
}
s.resize(length);
for(int i=s.size()-1;i>=0;i--){
s[i]=st.top();
st.pop();
}
return s;
}
};
5.2 随想录笔记
- 本题要删除相邻相同元素,相对于20. 有效的括号 (opens new window)来说其实也是匹配问题,20. 有效的括号 是匹配左右括号,本题是匹配相邻元素,最后都是做消除的操作。
- 在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
- 当然可以拿字符串直接作为栈,这样省去了栈还要转为字符串的操作。
class Solution {
public:
string removeDuplicates(string S) {
string result;
for(char s : S) {
if(result.empty() || result.back() != s) {
result.push_back(s);
}
else {
result.pop_back();
}
}
return result;
}
};
- 这道题目就像是我们玩过的游戏对对碰,如果相同的元素挨在一起就要消除。游戏开发可能使用栈结构,编程语言的一些功能实现也会使用栈结构,实现函数递归调用就需要栈,但不是每种编程语言都支持递归,例如:递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
- 相信大家应该遇到过一种错误就是栈溢出,系统输出的异常是
Segmentation fault(当然不是所有的Segmentation fault都是栈溢出导致的) ,如果你使用了递归,就要想一想是不是无限递归了,那么系统调用栈就会溢出。 - 而且在企业项目开发中,尽量不要使用递归!在项目比较大的时候,由于参数多,全局变量等等,使用递归很容易判断不充分return的条件,非常容易无限递归(或者递归层级过深),造成栈溢出错误(这种问题还不好排查!)
6. 逆波兰表达式求值
- 这不仅仅是一道好题,也展现出计算机的思考方式
6.1 我的
- 用栈的经典题型,但是注意两个数之间的前后顺序,尤其是减法和除法:
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<long long> st;
for(int i=0;i<tokens.size();i++){
if(tokens[i]=="+"){
long long a=st.top();
st.pop();
long long b=st.top();
st.pop();
a=a+b;
// printf("%ld+%ld=%ld",a,b,a);
st.push(a);
}else if(tokens[i]=="-"){
long long a=st.top();
st.pop();
long long b=st.top();
st.pop();
a=b-a;
// printf("%ld-%ld=%ld",a,b,a);
st.push(a);
}else if(tokens[i]=="*"){
long long a=st.top();
st.pop();
long long b=st.top();
st.pop();
a=a*b;
// printf("%ld*%ld=%ld",a,b,a);
st.push(a);
}else if(tokens[i]=="/"){
long long a=st.top();
st.pop();
long long b=st.top();
st.pop();
a=b/a;//注意a b之间的顺序
// printf("%ld/%ld=%ld",a,b,a);
st.push(a);
}else{
st.push(stoll(tokens[i]));
}
}
int a=st.top();
st.pop();
return a;
}
};
6.2 随想录笔记
- 在上一篇文章中1047.删除字符串中的所有相邻重复项 (opens new window)提到了 递归就是用栈来实现的。==所以栈与递归之间在某种程度上是可以转换的!==这一点我们在后续讲解二叉树的时候,会更详细的讲解到。
- 那么来看一下本题,其实逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后序遍历的方式把二叉树序列化了,就可以了。
- 在进一步看,本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这岂不就是一个相邻字符串消除的过程
class Solution {
public:
int evalRPN(vector<string>& tokens) {
// 力扣修改了后台测试数据,需要用longlong
stack<long long> st;
for (int i = 0; i < tokens.size(); i++) {
if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {
long long num1 = st.top();
st.pop();
long long num2 = st.top();
st.pop();
if (tokens[i] == "+") st.push(num2 + num1);
if (tokens[i] == "-") st.push(num2 - num1);
if (tokens[i] == "*") st.push(num2 * num1);
if (tokens[i] == "/") st.push(num2 / num1);
} else {
st.push(stoll(tokens[i]));
}
}
int result = st.top();
st.pop(); // 把栈里最后一个元素弹出(其实不弹出也没事)
return result;
}
};
- 我们习惯看到的表达式都是中缀表达式,因为符合我们的习惯,但是中缀表达式对于计算机来说就不是很友好了。
- 将中缀表达式,转化为后缀表达式之后就不一样了,计算机可以利用栈来顺序处理,不需要考虑优先级了。也不用回退了, **所以后缀表达式对计算机来说是非常友好的。**可以说本题不仅仅是一道好题,也展现出计算机的思考方式。在1970年代和1980年代,惠普在其所有台式和手持式计算器中都使用了RPN(后缀表达式),直到2020年代仍在某些模型中使用了RPN。
7. 滑动窗口最大值
7.1 我的
- 用的队列,会超时:
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
int max=nums[0];
queue<int> que;
int n=nums.size()-k+1;
vector<int> max_nums(n);
int num_max=0;
for(int i=0;i<k;i++){
que.push(nums[i]);
if(nums[i]>max){
max=nums[i];
}
}
max_nums[num_max++]=max;
for(int i=k;i<nums.size();i++){
int nn=que.front();
printf("%d: %d ",i, nn);
que.pop();//front会直接pop出来
que.push(nums[i]);
if(nums[i]>max){
max=nums[i];
}else if(max==nn){
max=que.front();
que.pop();
printf(" max:%d ", max);
que.push(max);
for(int j=0;j<k-1;j++){
int nx=que.front();
if(max<nx){
max=nx;
}
que.pop();
que.push(nx);
}
}
max_nums[num_max++]=max;
}
return max_nums;
}
};
- 参考给的方法进行修改:
class Solution {
private:
class MyQueue { //单调队列(从大到小)
public:
deque<int> que; // 使用deque来实现单调队列
void pop() {
if (!que.empty()) {
que.pop_front();
}
}
void push(int value) {
que.push_back(value);
}
int front() {
return que.front();
}
int back() {
return que.back();
}
void pop_back() {
que.pop_back();
}
bool empty(){
return que.empty();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
int max=nums[0];
MyQueue que;
int n=nums.size()-k+1;
vector<int> max_nums(n);
int num_max=0;
for(int i=0;i<k;i++){
while(!que.empty() and nums[i]>que.back()){
que.pop_back();
}
que.push(nums[i]);
if(nums[i]>max){
max=nums[i];
}
}
max_nums[num_max++]=max;
for(int i=k;i<nums.size();i++){
// int nn=que.front();
// printf("%d: %d ",i, nn);
// que.pop();//front会直接pop出来
if(nums[i-k]==que.front()){
que.pop();
}
while(!que.empty() and nums[i]>que.back()){
que.pop_back();
}
que.push(nums[i]);
if(nums[i]>max){
max=nums[i];
}else if(max==nums[i-k]){
max=que.front();
// que.pop();
// printf(" max:%d ", max);
// que.push(max);
// for(int j=0;j<k-1;j++){
// int nx=que.front();
// if(max<nx){
// max=nx;
// }
// que.pop();
// que.push(nx);
// }
}
max_nums[num_max++]=max;
}
return max_nums;
}
};
7.2 随想录笔记
-
这是使用单调队列的经典题目。
-
暴力方法,遍历一遍的过程中每次从窗口中再找到最大的数值,这样很明显是O(n × k)的算法。有的同学可能会想用一个大顶堆(优先级队列)来存放这个窗口里的k个数字,这样就可以知道最大的最大值是多少了, 但是问题是这个窗口是移动的,而大顶堆每次只能弹出最大值,我们无法移除其他数值,这样就造成大顶堆维护的不是滑动窗口里面的数值了。所以不能用大顶堆。
-
此时我们需要一个队列,这个队列呢,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
-
其实在C++中,可以使用 multiset 来模拟这个过程,文末提供这个解法仅针对C++,以下讲解我们还是靠自己来实现这个单调队列。
-
队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。那么问题来了,已经排序之后的队列 怎么能把窗口要移除的元素(这个元素可不一定是最大值)弹出呢。
-
其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来实现一个单调队列
不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
-
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口进行滑动呢?
-
设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
-
那么我们用什么数据结构来实现这个单调队列呢?
使用deque最为合适,在文章栈与队列:来看看栈和队列不为人知的一面 (opens new window)中,我们就提到了常用的queue在没有指定容器的情况下,deque就是默认底层容器。
-
相当于队列并不是为了记录当前的窗口,当前的窗口直接在数组中看就行,没必要记录,需要记录到队列中的是当前最大的数也就是在一个数(未被弹出)前,前面所有小于这个数的都被弹出。
-
再来看一下时间复杂度,使用单调队列的时间复杂度是 O(n)。
有的同学可能想了,在队列中 push元素的过程中,还有pop操作呢,感觉不是纯粹的O(n)。
其实,大家可以自己观察一下单调队列的实现,nums 中的每个元素最多也就被 push_back 和 pop_back 各一次,没有任何多余操作,所以整体的复杂度还是 O(n)。
空间复杂度因为我们定义一个辅助队列,所以是O(k)
-
题解中单调队列里的pop和push接口,仅适用于本题哈。单调队列不是一成不变的,而是不同场景不同写法,总之要保证队列里单调递减或递增的原则,所以叫做单调队列。 不要以为本题中的单调队列实现就是固定的写法哈。
-
大家貌似对deque也有一些疑惑,C++中deque是stack和queue默认的底层实现容器(这个我们之前已经讲过啦),deque是可以两边扩展的,而且deque里元素并不是严格的连续分布的。
-
注意deque需要自己进行实现:
class Solution {
private:
class MyQueue { //单调队列(从大到小)
public:
deque<int> que; // 使用deque来实现单调队列
// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
// 同时pop之前判断队列当前是否为空。
void pop(int value) {
if (!que.empty() && value == que.front()) {
que.pop_front();
}
}
// 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
// 这样就保持了队列里的数值是单调从大到小的了。
void push(int value) {
while (!que.empty() && value > que.back()) {
que.pop_back();
}
que.push_back(value);
}
// 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
int front() {
return que.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MyQueue que;
vector<int> result;
for (int i = 0; i < k; i++) { // 先将前k的元素放进队列
que.push(nums[i]);
}
result.push_back(que.front()); // result 记录前k的元素的最大值
for (int i = k; i < nums.size(); i++) {
que.pop(nums[i - k]); // 滑动窗口移除最前面元素
que.push(nums[i]); // 滑动窗口前加入最后面的元素
result.push_back(que.front()); // 记录对应的最大值
}
return result;
}
};
8. 前k个高频元素
8.1 我的
- 没有思路:直接看下面的吧,代码也没写过类似的不会,我的C++真的忘完了啊。
8.2 随想录笔记
- 这道题目主要涉及到如下三块内容:
- 要统计元素出现频率:这一类的问题可以使用map来进行统计。
- 对频率排序:对频率进行排序,这里我们可以使用一种 容器适配器就是优先级队列。
- 就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
- 优先级队列内部元素是自动依照元素的权值排列。
- 缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。(大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。)
- 堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
- 使用优先级队列来对部分频率进行排序。使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。此时要思考一下,是使用小顶堆呢,还是大顶堆?题目要求前 K 个高频元素,那么果断用大顶堆啊。那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
- 所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
- 找出前K个高频元素
class Solution {
public:
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 要统计元素出现频率
unordered_map<int, int> map; // map<nums[i],对应出现的次数>
for (int i = 0; i < nums.size(); i++) {
map[nums[i]]++;
}
// 对频率排序
// 定义一个小顶堆,大小为k
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
// 用固定大小为k的小顶堆,扫面所有频率的数值
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
pri_que.push(*it);
if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
pri_que.pop();
}
}
// 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
vector<int> result(k);
for (int i = k - 1; i >= 0; i--) {
result[i] = pri_que.top().first;
pri_que.pop();
}
return result;
}
};
-
对这个比较运算在建堆时是如何应用的,为什么左大于右就会建立小顶堆,反而建立大顶堆比较困惑。
确实 例如我们在写快排的cmp函数的时候,
return left>right就是从大到小,return left<right就是从小到大。优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关(我没有仔细研究),我估计是底层实现上优先队列队首指向后面,队尾指向最前面的缘故!
9. 总结
-
在栈与队列系列中,我们强调栈与队列的基础,也是很多同学容易忽视的点。使用抽象程度越高的语言,越容易忽视其底层实现,而C++相对来说是比较接近底层的语言。
-
灵魂四问:
- C++中stack,queue 是容器么?
- 我们使用的stack,queue是属于那个版本的STL?
- 我们使用的STL中stack,queue是如何实现的?
- stack,queue 提供迭代器来遍历空间么?
-
栈与队列是我们熟悉的不能再熟悉的数据结构,但它们的底层实现,很多同学都比较模糊,这其实就是基础所在。可以出一道面试题:栈里面的元素在内存中是连续分布的么?这个问题有两个陷阱:
- 陷阱1:栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中不一定是连续分布的。
- 陷阱2:缺省情况下,默认底层容器是deque,那么deque在内存中的数据分布是什么样的呢? 答案是:不连续的,下文也会提到deque。
-
一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时在去弹出元素就是栈的顺序了。
-
**栈在系统中的应用:**如果还记得编译原理的话,编译器在词法分析的过程中处理括号、花括号等这个符号的逻辑,就是使用了栈这种数据结构。递归的实现是栈:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。数据结构与算法的应用往往隐藏在我们看不到的地方!
-
**括号匹配是使用栈解决的经典问题。**建议要写代码之前要分析好有哪几种不匹配的情况,如果不动手之前分析好,写出的代码也会有很多问题。这里还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了!
-
除字符串中的所有相邻重复项:思路就是可以把字符串顺序放到一个栈中,然后如果相同的话 栈就弹出,这样最后栈里剩下的元素都是相邻不相同的元素了。
-
求逆波兰表达式。本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这岂不就是一个相邻字符串消除的过程,和栈与队列:匹配问题都是栈的强项 (opens new window)中的对对碰游戏是不是就非常像了。
-
滑动窗口最大值问题:讲解了一种数据结构:单调队列。这道题目还是比较绕的,如果第一次遇到这种题目,需要反复琢磨。主要思想是队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来一个单调队列。而且**不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。**设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列出口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。一些同学还会对单调队列都有一些困惑,首先要明确的是,题解中单调队列里的pop和push接口,仅适用于本题。单调队列不是一成不变的,而是不同场景不同写法,总之要保证队列里单调递减或递增的原则,所以叫做单调队列。**不要以为本地中的单调队列实现就是固定的写法。**我们用deque作为单调队列的底层数据结构,C++中deque是stack和queue默认的底层实现容器(这个我们之前已经讲过),deque是可以两边扩展的,而且deque里元素并不是严格的连续分布的。
-
求前 K 个高频元素:通过求前 K 个高频元素,引出另一种队列就是优先级队列。就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。本题就要使用优先级队列来对部分频率进行排序。 注意这里是对部分数据进行排序而不需要对所有数据排序!所以排序的过程的时间复杂度是 O ( log ? k ) O(\log k) O(logk),整个算法的时间复杂度是 O ( n log ? k ) O(n\log k) O(nlogk)。
七、单调栈
1. 每日温度
1.1 我的
- 从后向前,构造一个栈,栈顶小于当前元素则出栈,栈空则赋值0,栈中有比当前的元素大的则设置其为对应的下一个高温日期,然后当前温度入栈。
- 但是怎么算出来是后面的第几天呢,第一个想法就是压入栈的是一个键值对,记录上下标,然后一分析发现,当前栈头元素(一定是下一个因为当前元素一定会压入栈)不是合适的时候访问其对应的answer数组就是下一个栈中的值的下标。
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
stack<int> ss;
vector<int> answer(temperatures.size());
for(int i=temperatures.size()-1;i>=0;i--){
if(ss.empty()){
answer[i]=0;
ss.push(temperatures[i]);
}else{
// int top=ss.top();
if(ss.top()>temperatures[i]){
answer[i]=1;
ss.push(temperatures[i]);
}else{
int tag=answer[i+1]+1;
ss.pop();
while(!ss.empty() and temperatures[i]>=ss.top()){
ss.pop();
tag+=answer[i+tag];
}
if(ss.empty()){
answer[i]=0;
ss.push(temperatures[i]);
}else{
ss.push(temperatures[i]);
answer[i]=tag;
}
}
}
}
return answer;
}
};
1.2 随想录笔记
-
首先想到的当然是暴力解法,两层for循环,把至少需要等待的天数就搜出来了。时间复杂度是O(n^2)
-
我怎么能想到用单调栈呢? 什么时候用单调栈呢?通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。时间复杂度为O(n)。
-
那么单调栈的原理是什么呢?为什么时间复杂度是O(n)就可以找到每一个元素的右边第一个比它大的元素位置呢?单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素高的元素,优点是整个数组只需要遍历一次。更直白来说,就是用一个栈来记录我们遍历过的元素,因为我们遍历数组的时候,我们不知道之前都遍历了哪些元素,以至于遍历一个元素找不到是不是之前遍历过一个更小的,所以我们需要用一个容器(这里用单调栈)来记录我们遍历过的元素。
-
在使用单调栈的时候首先要明确如下几点:
- 单调栈里存放的元素是什么?单调栈里只需要存放元素的下标i就可以了,如果需要使用对应的元素,直接T[i]就可以获取(好有道理!我的方法是计算出来下标确实更复杂了一点)。
- 单调栈里元素是递增呢? 还是递减呢?注意以下讲解中,顺序的描述为 从栈头到栈底的顺序,因为单纯的说从左到右或者从前到后,不说栈头朝哪个方向的话,大家一定比较懵。这里我们要使用递增循序(再强调一下是指从栈头到栈底的顺序),因为只有递增的时候,栈里要加入一个元素i的时候,才知道栈顶元素在数组中右面第一个比栈顶元素大的元素是i。(即:如果求一个元素右边第一个更大元素,单调栈就是递增的,如果求一个元素右边第一个更小元素,单调栈就是递减的。)
-
使用单调栈主要有三个判断条件。
- 当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
把这三种情况分析清楚了,也就理解透彻了。
-
定义result数组的时候,就应该直接初始化为0,如果result没有更新,说明这个元素右面没有更大的了,也就是为0。通过以上过程,大家可以自己再模拟一遍,就会发现:只有单调栈递增(从栈口到栈底顺序),就是求右边第一个比自己大的,单调栈递减的话,就是求右边第一个比自己小的。(这里的方法是正向放入数据的,感觉更难理解欸:就是正向放入(比前面的数小则直接放入),当需要弹出时更新result值(更新为当前准备压入的值,也就是当前值更大的意思),最后未被弹出的直接赋值为0(因为后面没有值能将其弹出)。)
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
stack<int> st; // 递增栈
vector<int> result(T.size(), 0);
for (int i = 0; i < T.size(); i++) {
while (!st.empty() && T[i] > T[st.top()]) { // 注意栈不能为空
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
return result;
}
};
2. 下一个更大元素1
2.1 我的
- 相当于计算出上一题的内容,而且不需要管下标,正向计算,当弹出时比较该元素是否在nums 1中出现过,然后哈希表记录nums 1中的下标,进行更新,直接将vector初始化为-1,这样
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
vector<int> result(nums1.size(), -1);
stack<int> ss;
unordered_map<int, int> st;
for(int i=0;i<nums1.size();i++){
st[nums1[i]]=i;
}
for(int i=0;i<nums2.size();i++){
while(!ss.empty() and nums2[i]>ss.top()){
if(st.find(ss.top()) != st.end()){
result[st[ss.top()]]=nums2[i];
}
ss.pop();
}
ss.push(nums2[i]);
}
return result;
}
};
2.2 随想录笔记
-
本题则是说nums1 是 nums2的子集,找nums1中的元素在nums2中下一个比当前元素大的元素。从题目示例中我们可以看出最后是要求nums1的每个元素在nums2中下一个比当前元素大的元素,那么就要定义一个和nums1一样大小的数组result来存放结果。题目说如果不存在对应位置就输出 -1 ,所以result数组如果某位置没有被赋值,那么就应该是是-1,所以就初始化为-1。
-
在遍历nums2的过程中,我们要判断nums2[i]是否在nums1中出现过,因为最后是要根据nums1元素的下标来更新result数组。注意题目中说是两个没有重复元素 的数组 nums1 和 nums2。没有重复元素,我们就可以用map来做映射了。根据数值快速找到下标,还可以判断nums2[i]是否在nums1中出现过。
-
C++中,当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的。我在关于哈希表,你该了解这些! (opens new window)中也做了详细的解释。
-
使用单调栈,首先要想单调栈是从大到小还是从小到大。栈头到栈底的顺序,要从小到大,也就是保持栈里的元素为递增顺序。只要保持递增,才能找到右边第一个比自己大的元素。其实递减栈就是求右边第一个比自己小的元素了。
-
接下来就要分析如下三种情况,一定要分析清楚。
- 情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
此时满足递增栈(栈头到栈底的顺序),所以直接入栈。
- 情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
如果相等的话,依然直接入栈,因为我们要求的是右边第一个比自己大的元素,而不是大于等于!
- 情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
此时如果入栈就不满足递增栈了,这也是找到右边第一个比自己大的元素的时候。
判断栈顶元素是否在nums1里出现过,(注意栈里的元素是nums2的元素),如果出现过,开始记录结果。记录结果这块逻辑有一点小绕,要清楚,此时栈顶元素在nums2数组中右面第一个大的元素是nums2[i](即当前遍历元素)。(这道题和nums 2的下标又没什么关系为什么要记录下标啊?我的代码更好理解一点吧)
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
stack<int> st;
vector<int> result(nums1.size(), -1);
if (nums1.size() == 0) return result;
unordered_map<int, int> umap; // key:下标元素,value:下标
for (int i = 0; i < nums1.size(); i++) {
umap[nums1[i]] = i;
}
st.push(0);
for (int i = 1; i < nums2.size(); i++) {
while (!st.empty() && nums2[i] > nums2[st.top()]) {
if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素
int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标
result[index] = nums2[i];
}
st.pop();
}
st.push(i);
}
return result;
}
};
3. 下一个更大元素2
503. 下一个更大元素 II - 力扣(LeetCode)
3.1 我的
- 感觉可以正向找一遍,反向找一遍,返向的时候只对正向没有找到的赋值。不对反向找找的是循环后距离最近的最大值,然而应当找距离最远的最大值。所有应当是不清空时正向扫描两遍,但是第二遍只更新部分值。
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
vector<int> result(nums.size(), -1);
stack<int> ss;
for(int i=0;i<nums.size();i++){
while(!ss.empty() and nums[i]>nums[ss.top()]){
result[ss.top()]=nums[i];
ss.pop();
}
ss.push(i);
}
// while(!ss.empty()){
// ss.pop();
// }
for(int i=0;i<nums.size();i++){
while(!ss.empty() and nums[i]>nums[ss.top()]){
if(result[ss.top()]==-1){
result[ss.top()]=nums[i];
}
ss.pop();
}
ss.push(i);
}
return result;
}
};
3.2 随想录笔记
- 如何处理循环数组。相信不少同学看到这道题,就想那我直接把两个数组拼接在一起,然后使用单调栈求下一个最大值不就行了!确实可以!将两个nums数组拼接在一起,使用单调栈计算出每一个元素的下一个最大值,最后再把结果集即result数组resize到原数组大小就可以了。
- 这种写法确实比较直观,但做了很多无用操作,例如修改了nums数组,而且最后还要把result数组resize回去。resize倒是不费时间,是O(1)的操作,但扩充nums数组相当于多了一个O(n)的操作。其实也可以不扩充nums,而是在遍历的过程中模拟走了两边nums。
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
vector<int> result(nums.size(), -1);
if (nums.size() == 0) return result;
stack<int> st;
for (int i = 0; i < nums.size() * 2; i++) {
// 模拟遍历两边nums,注意一下都是用i % nums.size()来操作
while (!st.empty() && nums[i % nums.size()] > nums[st.top()]) {
result[st.top()] = nums[i % nums.size()];
st.pop();
}
st.push(i % nums.size());
}
return result;
}
};
4. 接雨水
- 这个图就是大厂面试经典题目,接雨水! 最常青藤的一道题,面试官百出不厌!
4.1 我的
- 首先就是向后蓄水:首先找到下一个大于等于当前值的,然后这里可以蓄水,首先最高高度是两边的最小值,中间的蓄水量是高度减去中间值。
- 然后就是向前蓄水,前面的大后面的小一点也能蓄上水,因此要找到前面大后面小但是后面小的是最大的,相对后面的值来说就是找到前一个更大的,也就是反向来一遍就行了呗,我真是傻了!但是这不意味着每个值都需要改变,反向时只需要改变那些可以将后面的值弹出,但是正向时没有值比他们大的数就行,而且这些大的数记录下的应当是它们能弹出的最大数值。也就是说只有正向后面没有最大值了才需要反向寻找,而且反向时寻找其能弹出的最大数值。
- 然后正向扫描一遍计算就行,注意i要一直往后走,避免重复计算。
- 整理下思路,总的来说,能蓄水说明两边高中间低:
- 右边更高,或者一样高—》也就是找到其右边的更大或相等的数;(正向+单调栈)
- 左边更高—》也就是找到其右边数中比其小的最大的数;(反向+单调栈,但是只需要更新正向未被更新到的,因为这里处理的是左边更高,正向处理到的说明其右边存在比其更高的台阶,不是我们要处理的情况;而且要找最大的,栈底的才是最大的)
- 为了方便计算,避免重复计算,正向扫描一遍就行,i跟着计算过的位置向后变化。
- 我的代码是在示例中不断完善的,因此感觉思路没有非常清晰,但是肯定是没错的:
class Solution {
public:
int trap(vector<int>& height) {
vector<int> result(height.size(), 0);
stack<int> ss;
int sum=0;
for(int i=0;i<height.size();i++){
while(!ss.empty() and height[i]>=height[ss.top()]){
result[ss.top()]=i;
ss.pop();
}
ss.push(i);
}
while(!ss.empty()){
ss.pop();
}
for(int i=height.size()-1;i>=0;i--){
int flag=0;
if(result[i]==0){
flag=1;
}
while(!ss.empty() and height[i]>height[ss.top()]){
if(flag){
result[i]=ss.top();//保证这是能弹出的后面的值中未被弹出的最大的
}
ss.pop();
}
ss.push(i);
}
for(int i=0;i<height.size();i++){
printf("%d ", result[i]);
}
for(int i=0;i<height.size();i++){
int high;
if(result[i]>i){
if(height[i]>height[result[i]]){
high=height[result[i]];
}else{
high=height[i];
}
for(int j=i+1;j<result[i];j++){
if(high>height[j]){
sum+=high-height[j];
}
}
i=result[i]-1; //避免重复计算
}
}
return sum;
}
};
4.2 随想录笔记
-
暴力:本题暴力解法也是也是使用双指针。首先要明确计算面积是要按照行来计算,还是按照列来计算。按照列来计算,比较容易理解:**如果按照列来计算的话,宽度一定是1了,我们再把每一列的雨水的高度求出来就可以了。**每一列雨水的高度,取决于,该列 左侧最高的柱子和右侧最高的柱子中最矮的那个柱子的高度。
- 只要从头遍历一遍所有的列,然后求出每一列雨水的体积(寻找两侧中高度最大的列),相加之后就是总雨水的体积了。
- 首先从头遍历所有的列,并且要注意第一个柱子和最后一个柱子不接雨水,在for循环中求左右两边最高柱子,最后,计算该列的雨水高度
- 因为每次遍历列的时候,还要向两边寻找最高的列,所以时间复杂度为O(n^2),空间复杂度为O(1)。力扣后面修改了后台测试数据,所以暴力解法超时了。
class Solution { public: int trap(vector<int>& height) { int sum = 0; for (int i = 0; i < height.size(); i++) { // 第一个柱子和最后一个柱子不接雨水 if (i == 0 || i == height.size() - 1) continue; int rHeight = height[i]; // 记录右边柱子的最高高度 int lHeight = height[i]; // 记录左边柱子的最高高度 for (int r = i + 1; r < height.size(); r++) { if (height[r] > rHeight) rHeight = height[r]; } for (int l = i - 1; l >= 0; l--) { if (height[l] > lHeight) lHeight = height[l]; } int h = min(lHeight, rHeight) - height[i]; if (h > 0) sum += h; } return sum; } }; -
双指针优化:为了得到两边的最高高度,使用了双指针来遍历,每到一个柱子都向两边遍历一遍,这其实是有重复计算的。我们把每一个位置的左边最高高度记录在一个数组上(maxLeft),右边最高高度记录在一个数组上(maxRight),这样就避免了重复计算。当前位置,左边的最高高度是前一个位置的左边最高高度和本高度的最大值。
- 即从左向右遍历:maxLeft[i] = max(height[i], maxLeft[i - 1]);
- 从右向左遍历:maxRight[i] = max(height[i], maxRight[i + 1]);
class Solution { public: int trap(vector<int>& height) { if (height.size() <= 2) return 0; vector<int> maxLeft(height.size(), 0); vector<int> maxRight(height.size(), 0); int size = maxRight.size(); // 记录每个柱子左边柱子最大高度 maxLeft[0] = height[0]; for (int i = 1; i < size; i++) { maxLeft[i] = max(height[i], maxLeft[i - 1]); } // 记录每个柱子右边柱子最大高度 maxRight[size - 1] = height[size - 1]; for (int i = size - 2; i >= 0; i--) { maxRight[i] = max(height[i], maxRight[i + 1]); } // 求和 int sum = 0; for (int i = 0; i < size; i++) { int count = min(maxLeft[i], maxRight[i]) - height[i]; if (count > 0) sum += count; } return sum; } }; -
单调栈:单调栈就是保持栈内元素有序。和栈与队列:单调队列 (opens new window)一样,需要我们自己维持顺序,没有现成的容器可以用。通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。而接雨水这道题目,我们正需要寻找一个元素,右边最大元素以及左边最大元素,来计算雨水面积。
-
那么本题使用单调栈有如下几个问题:
-
首先单调栈是按照行方向来计算雨水
-
使用单调栈内元素的顺序,从大到小还是从小到大呢?从栈头(元素从栈头弹出)到栈底的顺序应该是从小到大的顺序。因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。关于单调栈的顺序给大家一个总结: 739. 每日温度 (opens new window)中求一个元素右边第一个更大元素,单调栈就是递增的,84.柱状图中最大的矩形 (opens new window)求一个元素右边第一个更小元素,单调栈就是递减的。
-
遇到相同高度的柱子怎么办。遇到相同的元素,更新栈内下标,就是将栈里元素(旧下标)弹出,将新元素(新下标)加入栈中。因为我们要求宽度的时候 如果遇到相同高度的柱子,需要使用最右边的柱子来计算宽度。
-
栈里要保存什么数值:使用单调栈,也是通过 长 * 宽 来计算雨水面积的。长就是通过柱子的高度来计算,宽是通过柱子之间的下标来计算,那么栈里有没有必要存一个pair<int, int>类型的元素,保存柱子的高度和下标呢。其实不用,栈里就存放下标就行,想要知道对应的高度,通过height[stack.top()] 就知道弹出的下标对应的高度了。
-
-
-
以下逻辑主要就是三种情况(和我的方法思路不同,这里是在对每一个凹点找两边,我的是在找每一个凸点的另一边)
- 情况一:当前遍历的元素(柱子)高度小于栈顶元素的高度 height[i] < height[st.top()]------如果当前遍历的元素(柱子)高度小于栈顶元素的高度,就把这个元素加入栈中,因为栈里本来就要保持从小到大的顺序(从栈头到栈底)。
- 情况二:当前遍历的元素(柱子)高度等于栈顶元素的高度 height[i] == height[st.top()]------如果当前遍历的元素(柱子)高度等于栈顶元素的高度,要跟更新栈顶元素,因为遇到相相同高度的柱子,需要使用最右边的柱子来计算宽度。
- 情况三:当前遍历的元素(柱子)高度大于栈顶元素的高度 height[i] > height[st.top()]------如果当前遍历的元素(柱子)高度大于栈顶元素的高度,此时就出现凹槽了,取栈顶元素,将栈顶元素弹出,这个就是凹槽的底部,也就是中间位置,下标记为mid,对应的高度为height[mid](就是图中的高度1)。此时的栈顶元素st.top(),就是凹槽的左边位置,下标为st.top(),对应的高度为height[st.top()](就是图中的高度2)。当前遍历的元素i,就是凹槽右边的位置,下标为i,对应的高度为height[i](就是图中的高度3)。
- 此时大家应该可以发现其实就是**栈顶和栈顶的下一个元素以及要入栈的元素,三个元素来接水!(因为这里是按行求的,也就是说只要能满足当前行就行,这样就不需要找该凹点两边的最大高度来求列,也就是说行的计算方法更适合找凹点,列的计算方法更适合找凸点)**那么雨水高度是 min(凹槽左边高度, 凹槽右边高度) - 凹槽底部高度,代码为:
int h = min(height[st.top()], height[i]) - height[mid];雨水的宽度是 凹槽右边的下标 - 凹槽左边的下标 - 1(因为只求中间宽度),代码为:int w = i - st.top() - 1 ;当前凹槽雨水的体积就是:h * w。
class Solution {
public:
int trap(vector<int>& height) {
stack<int> st;
st.push(0);
int sum = 0;
for (int i = 1; i < height.size(); i++) {
while (!st.empty() && height[i] > height[st.top()]) {
int mid = st.top();
st.pop();
if (!st.empty()) {
int h = min(height[st.top()], height[i]) - height[mid];
int w = i - st.top() - 1;
sum += h * w;
}
}
st.push(i);
}
return sum;
}
};
5. 柱状图中最大的矩形
5.1 我的
- 第一反应双重循环:找当前元素开始的话哪儿结束最大。
- 然后看来一眼提示,说实话这种题还是没明确的思路,找右边第一个小的,也就是一个柱子找其两边第一个更小的,最小的其实就是全部长度的面积,最高的就是单列最高的面积,找到两边更小的意味着当前柱子可以取自己为高度时,长度就是变小的值的距离,也就是需要找到一个凸起,每一个凸起都能计算一次面积。每一个凸起有两种方法,一是只计算凸起中间部分的面积,也就是高度乘以1;二是寻找凸起边缘相对高的位置计算面积,第二高乘以2;三是寻找整个凸起最低点,乘以3,并且弹出比当前高度高的全部高度。
- 维护一个从底到顶端单调递增的栈,(右边新加入的值更小说明高度要变低了):
- 最大值赋0,首先记录当前高度和当前面积,也就是第一个数据的信息;压入栈的是键值对,一个代表横向位置一个代表高度。(也可以只使用int数据,然后更改数组中相应位置的值即可)
- 当右边的比当前高度小:也就是出现凸起,进行计算(这一步是一个while,直到栈空或者符合单调增)
- 首先弹出当前栈顶,乘以与新栈顶的横向距离(不包括新栈顶本身),作为面积最大值选项进行比较,大则保存,然后将当前栈顶的键值对大小与准备入栈大小再比较,还是新的大则还有凸起,位置改为弹出值的横向位置,继续循环;若是新加入的元素更小则直接压入栈。
- 右边高度一样:将栈顶弹出压入新值,相当于横向位置加一。
- 右边元素比当前大:没有出现凸起,直接压入。
- **测试时发现如何最后栈非空要按照最后元素是0,计算一下!**这时只会出现小于前面元素的情况,因为柱子可能等于0,会无穷无尽的。
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> st;
st.push(0);
int max=heights[0];
for(int i=1;i<heights.size();i++){
while(!st.empty() and heights[i]<heights[st.top()]){
int high=st.top();
st.pop();
int length;
if(!st.empty()){
length=high-st.top();
}else{
length=high+1;
}
int now=heights[high] * length;
if(now>max){
max=now;
}
if(!st.empty() and heights[i]<heights[st.top()]){
int x=st.top();
st.pop();
st.push(high);
heights[high]=heights[x];
}
}
if(!st.empty() and heights[i]==heights[st.top()]){
st.pop();
}
st.push(i);
}
while(!st.empty()){
int high=st.top();
st.pop();
int length;
if(!st.empty()){
length=high-st.top();
}else{
length=high+1;
}
int now=heights[high] * length;
if(now>max){
max=now;
}
if(!st.empty()){
int x=st.top();
st.pop();
st.push(high);
heights[high]=heights[x];
}
}
return max;
}
};
5.2 随想录笔记
-
本题和42. 接雨水 (opens new window),是遥相呼应的两道题目,建议都要仔细做一做,原理上有很多相同的地方,但细节上又有差异,更可以加深对单调栈的理解!
-
暴力解法不能通过会超时。(很神奇的是暴力解法好像让我更明白了,就是只需要找两边小于该值的就行,因为最小值也会去两边找,不用像我之前想的分那么多的情况(上面的代码已经是我简化后的,刚开始想复杂了),因此是不会错过什么可能能取到的值的。)
-
双指针的写法:整体思路和42. 接雨水 (opens new window)是一致的,但要比42. 接雨水 (opens new window)难一些。难就难在本题要记录记录每个柱子 左边第一个小于该柱子的下标,而不是左边第一个小于该柱子的高度。所以需要循环查找,也就是下面在寻找的过程中使用了while。
class Solution { public: int largestRectangleArea(vector<int>& heights) { vector<int> minLeftIndex(heights.size()); vector<int> minRightIndex(heights.size()); int size = heights.size(); // 记录每个柱子 左边第一个小于该柱子的下标 minLeftIndex[0] = -1; // 注意这里初始化,防止下面while死循环 for (int i = 1; i < size; i++) { int t = i - 1; // 这里不是用if,而是不断向左寻找的过程 while (t >= 0 && heights[t] >= heights[i]) t = minLeftIndex[t]; minLeftIndex[i] = t; } // 记录每个柱子 右边第一个小于该柱子的下标 minRightIndex[size - 1] = size; // 注意这里初始化,防止下面while死循环 for (int i = size - 2; i >= 0; i--) { int t = i + 1; // 这里不是用if,而是不断向右寻找的过程 while (t < size && heights[t] >= heights[i]) t = minRightIndex[t]; minRightIndex[i] = t; } // 求和 int result = 0; for (int i = 0; i < size; i++) { int sum = heights[i] * (minRightIndex[i] - minLeftIndex[i] - 1); result = max(sum, result); } return result; } }; -
单调栈:解法和接雨水的题目是遥相呼应的。本题是找每个柱子左右两边第一个小于该柱子的柱子。这里就涉及到了单调栈很重要的性质,就是单调栈里的顺序,是从小到大还是从大到小。因为本题是要找每个柱子左右两边第一个小于该柱子的柱子,所以从栈头(元素从栈头弹出)到栈底的顺序应该是从大到小的顺序!只有栈里从大到小的顺序,才能保证栈顶元素找到左右两边第一个小于栈顶元素的柱子。此时大家应该可以发现其实就是栈顶和栈顶的下一个元素以及要入栈的三个元素组成了我们要求最大面积的高度和宽度。主要就是分析清楚如下三种情况:
- 情况一:当前遍历的元素heights[i]大于栈顶元素heights[st.top()]的情况
- 情况二:当前遍历的元素heights[i]等于栈顶元素heights[st.top()]的情况
- 情况三:当前遍历的元素heights[i]小于栈顶元素heights[st.top()]的情况
- 我在 height数组上后,都加了一个元素0, 为什么这么做呢?首先来说末尾为什么要加元素0?如果数组本身就是升序的,例如[2,4,6,8],那么入栈之后 都是单调递减,一直都没有走 情况三 计算结果的哪一步,所以最后输出的就是0了。那么结尾加一个0,就会让栈里的所有元素,走到情况三的逻辑。(我的代码在最后加了一个单独的循环处理,模拟后面有个0。)
- 开头为什么要加元素0?如果数组本身是降序的,例如 [8,6,4,2],在 8 入栈后,6 开始与8 进行比较,此时我们得到 mid(8),rigt(6),但是得不到 left。(mid、left,right 都是对应版本一里的逻辑)因为 将 8 弹出之后,栈里没有元素了,那么为了避免空栈取值,直接跳过了计算结果的逻辑。之后又将6 加入栈(此时8已经弹出了),然后 就是 4 与 栈口元素 8 进行比较,周而复始,那么计算的最后结果resutl就是0。 所以我们需要在 height数组前后各加一个元素0。(我的代码在这里单独判断了一下,模拟前面有个0。)
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> st;
heights.insert(heights.begin(), 0); // 数组头部加入元素0
heights.push_back(0); // 数组尾部加入元素0
st.push(0);
int result = 0;
for (int i = 1; i < heights.size(); i++) {
while (heights[i] < heights[st.top()]) {
int mid = st.top();
st.pop();
int w = i - st.top() - 1;
int h = heights[mid];
result = max(result, w * h);
}
st.push(i);
}
return result;
}
};
sum = 0;
for (int i = 1; i < height.size(); i++) {
while (!st.empty() && height[i] > height[st.top()]) {
int mid = st.top();
st.pop();
if (!st.empty()) {
int h = min(height[st.top()], height[i]) - height[mid];
int w = i - st.top() - 1;
sum += h * w;
}
}
st.push(i);
}
return sum;
}
};
5. 柱状图中最大的矩形
5.1 我的
- 第一反应双重循环:找当前元素开始的话哪儿结束最大。
- 然后看来一眼提示,说实话这种题还是没明确的思路,找右边第一个小的,也就是一个柱子找其两边第一个更小的,最小的其实就是全部长度的面积,最高的就是单列最高的面积,找到两边更小的意味着当前柱子可以取自己为高度时,长度就是变小的值的距离,也就是需要找到一个凸起,每一个凸起都能计算一次面积。每一个凸起有两种方法,一是只计算凸起中间部分的面积,也就是高度乘以1;二是寻找凸起边缘相对高的位置计算面积,第二高乘以2;三是寻找整个凸起最低点,乘以3,并且弹出比当前高度高的全部高度。
- 维护一个从底到顶端单调递增的栈,(右边新加入的值更小说明高度要变低了):
- 最大值赋0,首先记录当前高度和当前面积,也就是第一个数据的信息;压入栈的是键值对,一个代表横向位置一个代表高度。(也可以只使用int数据,然后更改数组中相应位置的值即可)
- 当右边的比当前高度小:也就是出现凸起,进行计算(这一步是一个while,直到栈空或者符合单调增)
- 首先弹出当前栈顶,乘以与新栈顶的横向距离(不包括新栈顶本身),作为面积最大值选项进行比较,大则保存,然后将当前栈顶的键值对大小与准备入栈大小再比较,还是新的大则还有凸起,位置改为弹出值的横向位置,继续循环;若是新加入的元素更小则直接压入栈。
- 右边高度一样:将栈顶弹出压入新值,相当于横向位置加一。
- 右边元素比当前大:没有出现凸起,直接压入。
- **测试时发现如何最后栈非空要按照最后元素是0,计算一下!**这时只会出现小于前面元素的情况,因为柱子可能等于0,会无穷无尽的。
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> st;
st.push(0);
int max=heights[0];
for(int i=1;i<heights.size();i++){
while(!st.empty() and heights[i]<heights[st.top()]){
int high=st.top();
st.pop();
int length;
if(!st.empty()){
length=high-st.top();
}else{
length=high+1;
}
int now=heights[high] * length;
if(now>max){
max=now;
}
if(!st.empty() and heights[i]<heights[st.top()]){
int x=st.top();
st.pop();
st.push(high);
heights[high]=heights[x];
}
}
if(!st.empty() and heights[i]==heights[st.top()]){
st.pop();
}
st.push(i);
}
while(!st.empty()){
int high=st.top();
st.pop();
int length;
if(!st.empty()){
length=high-st.top();
}else{
length=high+1;
}
int now=heights[high] * length;
if(now>max){
max=now;
}
if(!st.empty()){
int x=st.top();
st.pop();
st.push(high);
heights[high]=heights[x];
}
}
return max;
}
};
5.2 随想录笔记
-
本题和42. 接雨水 (opens new window),是遥相呼应的两道题目,建议都要仔细做一做,原理上有很多相同的地方,但细节上又有差异,更可以加深对单调栈的理解!
-
暴力解法不能通过会超时。(很神奇的是暴力解法好像让我更明白了,就是只需要找两边小于该值的就行,因为最小值也会去两边找,不用像我之前想的分那么多的情况(上面的代码已经是我简化后的,刚开始想复杂了),因此是不会错过什么可能能取到的值的。)
-
双指针的写法:整体思路和42. 接雨水 (opens new window)是一致的,但要比42. 接雨水 (opens new window)难一些。难就难在本题要记录记录每个柱子 左边第一个小于该柱子的下标,而不是左边第一个小于该柱子的高度。所以需要循环查找,也就是下面在寻找的过程中使用了while。
class Solution { public: int largestRectangleArea(vector<int>& heights) { vector<int> minLeftIndex(heights.size()); vector<int> minRightIndex(heights.size()); int size = heights.size(); // 记录每个柱子 左边第一个小于该柱子的下标 minLeftIndex[0] = -1; // 注意这里初始化,防止下面while死循环 for (int i = 1; i < size; i++) { int t = i - 1; // 这里不是用if,而是不断向左寻找的过程 while (t >= 0 && heights[t] >= heights[i]) t = minLeftIndex[t]; minLeftIndex[i] = t; } // 记录每个柱子 右边第一个小于该柱子的下标 minRightIndex[size - 1] = size; // 注意这里初始化,防止下面while死循环 for (int i = size - 2; i >= 0; i--) { int t = i + 1; // 这里不是用if,而是不断向右寻找的过程 while (t < size && heights[t] >= heights[i]) t = minRightIndex[t]; minRightIndex[i] = t; } // 求和 int result = 0; for (int i = 0; i < size; i++) { int sum = heights[i] * (minRightIndex[i] - minLeftIndex[i] - 1); result = max(sum, result); } return result; } }; -
单调栈:解法和接雨水的题目是遥相呼应的。本题是找每个柱子左右两边第一个小于该柱子的柱子。这里就涉及到了单调栈很重要的性质,就是单调栈里的顺序,是从小到大还是从大到小。因为本题是要找每个柱子左右两边第一个小于该柱子的柱子,所以从栈头(元素从栈头弹出)到栈底的顺序应该是从大到小的顺序!只有栈里从大到小的顺序,才能保证栈顶元素找到左右两边第一个小于栈顶元素的柱子。此时大家应该可以发现其实就是栈顶和栈顶的下一个元素以及要入栈的三个元素组成了我们要求最大面积的高度和宽度。主要就是分析清楚如下三种情况:
- 情况一:当前遍历的元素heights[i]大于栈顶元素heights[st.top()]的情况
- 情况二:当前遍历的元素heights[i]等于栈顶元素heights[st.top()]的情况
- 情况三:当前遍历的元素heights[i]小于栈顶元素heights[st.top()]的情况
- 我在 height数组上后,都加了一个元素0, 为什么这么做呢?首先来说末尾为什么要加元素0?如果数组本身就是升序的,例如[2,4,6,8],那么入栈之后 都是单调递减,一直都没有走 情况三 计算结果的哪一步,所以最后输出的就是0了。那么结尾加一个0,就会让栈里的所有元素,走到情况三的逻辑。(我的代码在最后加了一个单独的循环处理,模拟后面有个0。)
- 开头为什么要加元素0?如果数组本身是降序的,例如 [8,6,4,2],在 8 入栈后,6 开始与8 进行比较,此时我们得到 mid(8),rigt(6),但是得不到 left。(mid、left,right 都是对应版本一里的逻辑)因为 将 8 弹出之后,栈里没有元素了,那么为了避免空栈取值,直接跳过了计算结果的逻辑。之后又将6 加入栈(此时8已经弹出了),然后 就是 4 与 栈口元素 8 进行比较,周而复始,那么计算的最后结果resutl就是0。 所以我们需要在 height数组前后各加一个元素0。(我的代码在这里单独判断了一下,模拟前面有个0。)
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> st;
heights.insert(heights.begin(), 0); // 数组头部加入元素0
heights.push_back(0); // 数组尾部加入元素0
st.push(0);
int result = 0;
for (int i = 1; i < heights.size(); i++) {
while (heights[i] < heights[st.top()]) {
int mid = st.top();
st.pop();
int w = i - st.top() - 1;
int h = heights[mid];
result = max(result, w * h);
}
st.push(i);
}
return result;
}
};
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!