ShardingSphere-JDBC初探
引言
为什么使用分库分表?
数据量太大单表放不下,并且公司不希望切换产品,可选的方案不多,ShardingSphere就是不错的选择。
切换产品指的是换成es、clickhouse、hbase这种支持大数据,试想一下切换产品对整个项目的改动有多恐怖
注意:分库分表并不是为了提升性能!!!
数据在单表就能容纳的情况根本没必要分库分表,反而带来一系列问题,比如分布式事务、分片策略等
在什么情况下需要分库分表?
参考阿里巴巴的开发手册,单表数据量达到500w,或者单表数据容量达到2G(就是ibd文件大小达到两个G),这种情况就可以考虑分库分表。还可能和服务器的性能与CPU核数有关,这个考量的标准笔者就不清楚了,欢迎有经验的小伙伴分享。
一些中小的公司不建议分库分表,如果本身的技术深度不够,hold不住的话不如不用
思考日均两千万数据的情况要如何设计?
这里提供一种思路,对于一些实时性要求比较高的场景,比如说电商下单操作,可能需要随时查看订单状态,这部分数据就可以保存在实时性较好的库里面,比如MySQL、Oracle,另外实时性要求不高的场景,完全可以把数据转存到es、clickhouse、hbase等大数据组件中去,存进去后续想怎么玩都可以
思考在上一篇总结的多数据源场景下,如何在不依赖分布式事务组件的情况下支持分布式事务?
仍然提供一种思路,在dynamic-datasource的基础上做扩展,苞米豆提供的这个组件底层也是使用了Spring提供的AbstractRoutingDataSource(jdbc包下的),通过这个类来管理数据源,实现的思路就是获取到所管理的全部数据源,这样就可以拿到所有的连接,拿到连接以后就可以提交或者回滚,按照需求进行编排。这种思路笔者还没有真正的代码落实,后续如果实际落实了再提供具体实现。
接下来本篇文章的学习重点就是ShardingSphere,早期的时候是叫ShardingJdbc,实际上ShardingJdbc是ShardingSphere内部提供的一个服务,ShardingSphere的目标是要做一个生态,而不是一个简单的JDBC分库分表工具,从官网文档可以看出,ShardingSphere是想把一些周边的组件(MySQL、zk、Oracle等)作为其生态的一个支撑(目标很宏大),具体的看官网详细介绍。
ShardingSphere提供的产品
-
ShardingSphere-JDBC(灵活的胖子)
官方描述:ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务
-
ShardingSphere-Proxy(呆板的管家)
官方描述:ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
官方建议的部署方式:

-
对于应用来说,建议使用ShardingSphere-JDBC来做分库分表的业务开发
-
对于运维或者管理来说,建议部署一套同样的ShardingSphere-Proxy来做运维和基础数据的管理
-
这两个产品之间配置一个GovernanceCenter配置中心(或者nacos、zk、etcd统一管理)
这样可以形成一整个分库分表的生态
ShardingSphere-JDBC做了哪些事
简单理解:屏蔽了底层分库分表的细节,让应用像访问单库单表一样操作业务逻辑
(ShardingSphere-JDBC 伪装成一个数据库,应用程序把它当作MySQL进行连接使用)
根据ShardingSphere提供的策略,可以定制分库分表的规则,这里的策略是为sql语句服务的。
注意:
1、定制了分片策略以后,会导致某些sql不可用(不符合策略,还有一些复杂的)
2、ShardingSphere不负责分片表的创建,分片表也就是真实表需要手动创建好
3、ShardingSphere不关心真实表是否存在,也不关心sql是否能正确执行,其真正要做的是,当用户针对逻辑表操作时,底层会根据用户定制的策略,生成操作真实表的sql,当然也会根据策略定位到具体的库
ShardingSphere快速使用
单库分片等值操作
准备工作:
1、引入依赖,这里为了方便测试引入一些其他的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>2.5.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.5.9</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.7</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<version>2.6.13</version>
</dependency>2、创建测试的实体类和mapper
public class Course
{
private Long cid;
// private Long id;
private String cname;
private Long userId;
private String cstatus;
... ...
}
public interface CourseMapper extends BaseMapper<Course> {
}
@SpringBootApplication
@MapperScan("com.sharding.demo.mapper")
public class ShardingJDBCApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJDBCApplication.class,args);
}
}3、添加配置文件,先实现最简单的一种
spring.shardingsphere.datasource.names=m0
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123666
#字段中间的course是一个逻辑表名,可自定义;$->{}是固定的写法,大括号里面是Grovvy表达式;这里的含义是m0.course_1和m0.course_2这样两个真实表
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m0.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
#键生成的算法,shardingsphere内部支持了雪花算法,也可以是UUID
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#可选项
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
#表分片策略,cid取模2再加一。cid递增的情况下可以保证均匀的把数据保存到1号表和2号表中
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}表分片策略inline的这种方式,适合一些等值操作的sql,这种策略使用范围查询会报错:
Inline strategy cannot support this type sharding:RangeRouteValue
测试结果:
@SpringBootTest
@RunWith(SpringRunner.class)
public class ShardingTest {
@Resource
CourseMapper courseMapper;
@Test
public void test()
{
for(int i=0;i < 10; ++i){
Course course = new Course();
// course.setCid(Long.valueOf(i+"")); //cid使用了雪花算法
course.setCname("gao");
course.setCstatus("ojbk");
course.setUserId(100L);
courseMapper.insert(course);
}
}
}
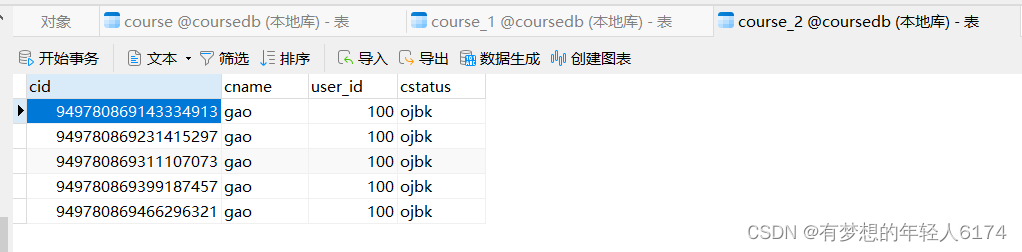
从测试结果可以看出,分片策略已经成功了,cid奇数的存在一张表,偶数的存另一张表
多库分片等值操作
在上面简单分片的基础上,升级为多库:
#修改
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123666
#新增
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123666
#修改
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#新增库策略
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{cid%2}
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}上面这种简单修改,测试时会发现问题:表分片策略算出偶数的数据都插入m0库的1表里面,基数的数据都插入m1库的2表里面,也就是数据分配不均匀
所以优化分片策略的算法:
course_$->{(cid%4).intdiv(2)+1}分析:当前有两个库,每个库有两个分片,也就是一共4个分片。所以取模4均分数据;每个库只有两个分片,所以除2。取模后得到的结果是0-3,除2后结果为0或1,因为表分片是从1开始的,所以最后加一
业务上也有这种算法:
course_$->{((cid+1)%4).intdiv(2)+1}个人理解先加1是可以打乱顺序,使数据更随机,试想原本分给4号表的数据加一后就分给了1号表。(如果库1负责表1和表2,库2负责表3和表4,这种情况下递增的数据使用这种写法可以一定程度上增加随机性)
多库分片范围操作
基于上面提到的inline这种策略不支持范围查询,那么要怎么解决呢?
ShardingSphere同样提供了支持范围的标准策略,修改配置文件:
#新增打印SQL,调试方便
spring.shardingsphere.props.sql.show=true
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123666
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123666
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#新增
spring.shardingsphere.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.sharding.tables.course.database-strategy.standard.range-algorithm-class-name=com.sharding.demo.algorithm.MyRangeDBAlgorithm
spring.shardingsphere.sharding.tables.course.database-strategy.standard..precise-algorithm-class-name=com.sharding.demo.algorithm.MyPreciseDBAlgorithm
#新增
spring.shardingsphere.sharding.tables.course.table-strategy.standard.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.standard.range-algorithm-class-name=com.sharding.demo.algorithm.MyRangeAlgorithm
spring.shardingsphere.sharding.tables.course.table-strategy.standard.precise-algorithm-class-name=com.sharding.demo.algorithm.MyPreciseAlgorithm注意:使用standard这种方式,需要配置范围策略和精确策略(库策略和表策略都需要)
自定义策略的简单实现:
//表策略-范围,getLogicTableName获得逻辑表名,lowerEndpoint为输入范围的下限 根据需求定制..
public class MyRangeAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Long lowerEndpoint = rangeShardingValue.getValueRange().lowerEndpoint();
Long upperEndpoint = rangeShardingValue.getValueRange().upperEndpoint();
System.out.println(lowerEndpoint + " : " + upperEndpoint);
return Arrays.asList(rangeShardingValue.getLogicTableName() + "_1", rangeShardingValue.getLogicTableName() + "_2");
}
}
//表策略-精确,支持等值查找和in查找
public class MyPreciseAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//course_$->{cid%2+1}
BigInteger value = BigInteger.valueOf(preciseShardingValue.getValue());
BigInteger sharding = value.mod(BigInteger.valueOf(2L)).add(BigInteger.valueOf(1L));
String key = preciseShardingValue.getLogicTableName() + "_" + sharding;
if (collection.contains(key)) {
return key;
}
throw new UnsupportedOperationException("not support key " + key + " please check");
}
}
//库策略-范围,返回可用的表
public class MyRangeDBAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Long lowerEndpoint = rangeShardingValue.getValueRange().lowerEndpoint();
Long upperEndpoint = rangeShardingValue.getValueRange().upperEndpoint();
System.out.println(lowerEndpoint + " : " + upperEndpoint);
return collection;
}
}
//库策略-精确
public class MyPreciseDBAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
// m$->{cid%2}
BigInteger value = BigInteger.valueOf(preciseShardingValue.getValue());
BigInteger sharding = value.mod(BigInteger.valueOf(2L));
String key = "m" + sharding;
if (collection.contains(key)) {
return key;
}
throw new UnsupportedOperationException("not support key " + key + " please check");
}
}多条件查询(复杂查询)
思考:在使用范围查询的基础上,还需要查询其他等值字段,这种情况standard是否支持?
使用ShardingSphere提供的complex方式实现,修改配置文件:
# 打印SQL
spring.shardingsphere.props.sql.show=true
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123666
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123666
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#新增
spring.shardingsphere.sharding.tables.course.database-strategy.complex.sharding-columns=cid,user_id
spring.shardingsphere.sharding.tables.course.database-strategy.complex.algorithm-class-name=com.sharding.demo.algorithm.MyComplexDBAlgorithm
#新增
spring.shardingsphere.sharding.tables.course.table-strategy.complex.sharding-columns=cid,user_id
spring.shardingsphere.sharding.tables.course.table-strategy.complex.algorithm-class-name=com.sharding.demo.algorithm.MyComplexAlgorithm添加Complex的算法实现:、
//表策略
public class MyComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
//select * from cid where cid in (xxx,xxx,xxx) and user_id between {lowerEndpoint} and {upperEndpoint};
Collection<Long> cidCol = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("cid");
Range<Long> userIdRange = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get("user_id");
Long lowerEndpoint = userIdRange.lowerEndpoint();
Long upperEndpoint = userIdRange.upperEndpoint();
List<String> list = new ArrayList<>();
for (Long cid : cidCol) {
String targetTable = complexKeysShardingValue.getLogicTableName() + "_" + (cid%2+1);
if(availableTargetNames.contains(targetTable)){
list.add(targetTable);
}
}
return list;
}
}
//库策略
public class MyComplexDBAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
return availableTargetNames;
}
}注意:需要关注的重点是,如何获取到分区键、查询条件字段及范围、逻辑表名,真实表列表等,具体的算法实现可以发挥你的聪明才智,怎样编排都可以
不需要分片键的hint算法
同样修改配置文件:
# 打印SQL
spring.shardingsphere.props.sql.show=true
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123666
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123666
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.database-strategy.hint.algorithm-class-name=com.sharding.demo.algorithm.MyHintDBAlgorithm
spring.shardingsphere.sharding.tables.course.table-strategy.hint.algorithm-class-name=com.sharding.demo.algorithm.MyHintAlgorithm新增策略算法类:
//表策略
public class MyHintAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
//hintShardingValue的值通过HintManager设置
String key = "course_" + hintShardingValue.getValues().toArray()[0];
if (collection.contains(key))
{
return Collections.singletonList(key);
}
throw new UnsupportedOperationException("not support key " + key + " please check");
}
}
//库策略
public class MyHintDBAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
return collection;
}
}测试代码:
@Test
public void list()
{
QueryWrapper<Course> queryWrapper = new QueryWrapper<>();
// queryWrapper.eq("cid", 7L);
// queryWrapper.between("cid", 949780868333834240L, 949780869441130496L);
// queryWrapper.in("cid", 949780868333834240L, 949780869441130496L);
// queryWrapper.between("user_id", 99L, 101L);
HintManager instance = HintManager.getInstance();
instance.addTableShardingValue("course", "1");
List<Course> courses = courseMapper.selectList(queryWrapper);
courses.forEach(course -> System.out.println(course));
}思考:hint这种方式是不是和之前总结的多数据源动态切换很像,dynamic-datasource其实也是一种hint策略
ShardingSphere的hint策略能不能用作切换数据源呢?
答案肯定是能的,但是这样做显然有些大材小用了
总结
企业中ShardingSphere使用的也很谨慎,需要团队对其中的策略有很好的把控,把控不好就不要用了
一个应用中肯定会有精确查询、范围查询、或者多条件查询
使用分库分表之后,对查询条件必然是有限制的,数据库逻辑必然会影响到上层的应用
所以一旦用了ShardingSphere-JDBC,必须要了解你的数据有哪些操作,然后针对最影响性能的操作做优化
好处:可以不用切换产品,单表存不下数据可以用这种方案解决
思考:扩容可以使用哪些策略?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!