3-高可用-隔离术
隔离是指将系统或资源分割开,系统隔离是为了在系统发生故障时,能限定传播范围和影响范围,即发生故障后不会出现滚雪球效应,从而保证只有出问题的服务不可用,其他服务还是可用的。
比较多的隔离手段有线程隔离、进程隔离、集群隔离、机房隔离、读写隔离、快慢隔离、动静隔离、爬虫隔离等。出现系统问题时,可以考虑负载均衡路由、自动/手动切换分组或者降级等手段来保障可用性。
线程隔离
线程隔离主要是指线程池隔离,在实际使用时,我们会把请求分类,然后交给不同的线程池处理。当一种业务的请求处理发生问题时,不会将故障扩散到其他线程池,从而保证其他服务可用。

进程隔离
公司发展初期,一般是先进行从零到一,不会一上来就进行系统拆分,这样就会开发出一些大而全的系统,系统中的一个模块/功能出现问题,整个系统就不可用了。
首先,想到的解决方案是通过部署多个实例,通过负载均衡进行路由转发。但是,这种情况无法避免某个模块因BUG而出现如OOM导致整个系统不可用的风险。因此,此种方案只是一个过渡,较好的解决方案是通过将系统拆分为多个子系统来实现物理隔离。
通过进程隔离使得某一个子系统出现问题时不会影响到其他子系统。

集群隔离
随着系统的发展,单实例服务无法满足需求,此时需要服务化技术,通过部署多个服务形成服务集群,来提升系统容量,如下图所示。
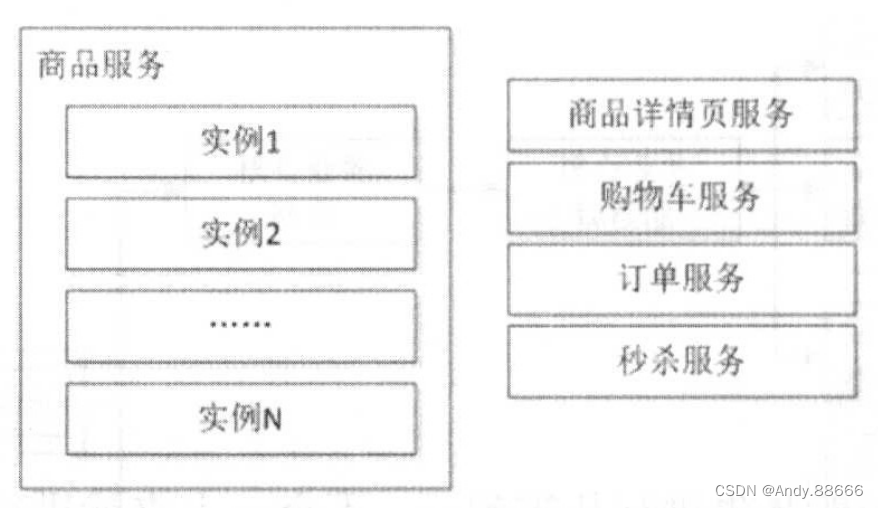
随着调用方的增多,当秒杀服务被刷会影响到其他服务的稳定性时,应该考虑为秒杀提供单独的服务集群,即为服务分组,这样当某一个分组出现问题时,不会影响到其他分组,从而实现了故障隔离。
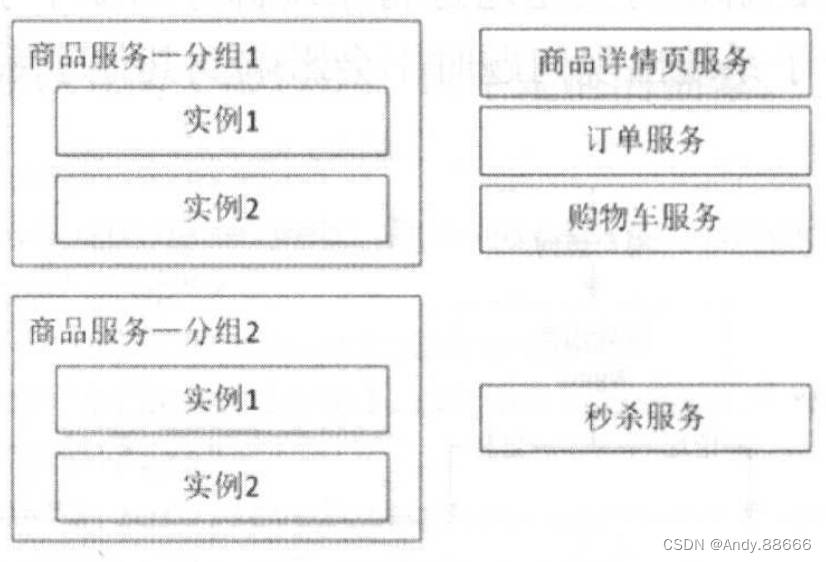
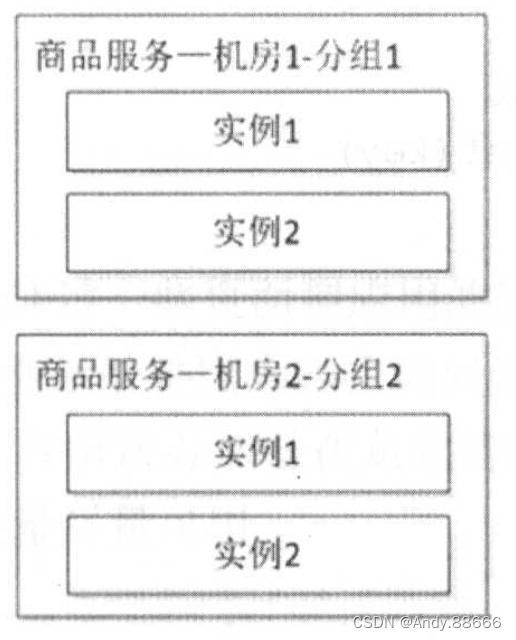
机房隔离
着对系统可用性的要求,会进行多机房部署,每个机房的服务都有自己的服务分组,本机房的服务应该只调用本机房服务,不进行跨机房调用。其中,一个机房服务发生问题时,可以通过DNS/负载均衡将请求全部切到另一个机房,或者考虑服务能自动重试其他机房的服务,从而提升系统可用性。
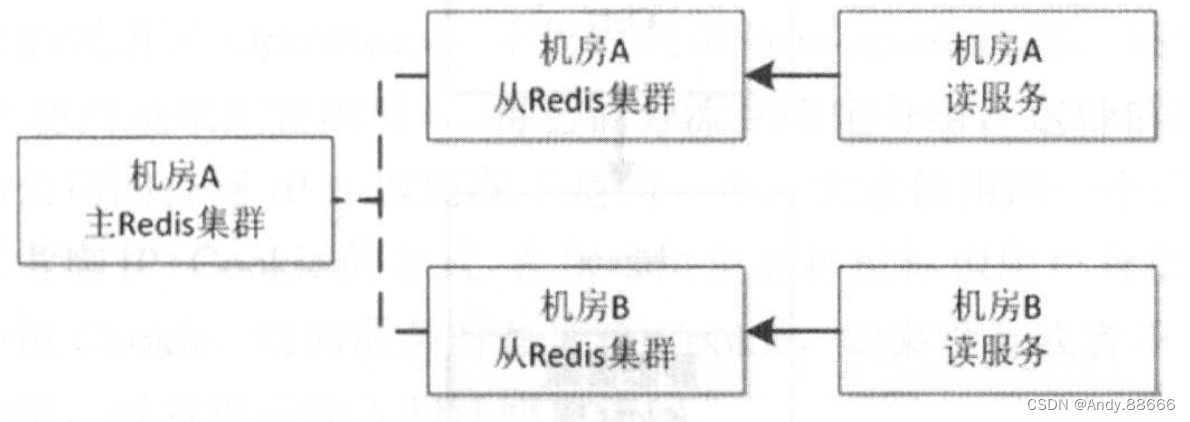
读写隔离
通过主从模式将读和写集群分离,读服务只从Redis集群获取数据,当主Redis集群出现问题时,从Redis集群还是可用的,从而不影响用户访问。而当从Redis集群出现问题时,可以进行其他集群的重试。
动静隔离
当用户访问如结算页时,如果JS/CSS等静态资源也在结算页系统中时,很可能因为访问量太大导致带宽被打满,从而出现不可用。

应该将动态内容和静态资源分离,一般应该将静态资源放在CDN上,如下图所示。

爬虫隔离
一些系统是因为爬虫访问量太大而导致服务不可用。
一种解决办法是通过限流解决。
另一种解决办法是在负载均衡层面将爬虫路由到单独集群,从而保证正常流量可用,爬虫流量尽量可用。

热点隔离
秒杀、抢购属于非常合适的热点例子,对于这种热点,是能提前知道的,所以可以将秒杀和抢购做成独立系统或服务进行隔离,从而保证秒杀/抢购流程出现问题时不影响主流程。
还存在一些热点,可能是因为价格或突发事件引起的。对于读热点,笔者使用多级缓存来搞定,而写热点我们一般通过缓存+队列模式削峰。
资源隔离
最常见的资源,如磁盘、CPU、网络,这些宝贵的资源,都会存在竞争问题。
在“构建需求响应式亿级商品详情页”中,我们使用JIMDB数据同步时要dump数据,SSD盘容量用了50%以上,dump到同一块磁盘时遇到了容量不足的问题,我们通过单独挂一块SAS盘来专门同步数据。
还有,使用Docker容器时,有的容器写磁盘非常频繁,因此,要考虑为不同的容器挂载不同的磁盘。
默认CPU的调度策略在一些追求极致性能的场景下可能并不太适合,我们希望通过绑定CPU到特定进程来提升性能。当一台机器启动很多Redis实例时,将CPU通过taskset绑定到Redis实例上可以提升一些性能。还有,Nginx提供了worker_processes和worker_cpu affinity来绑定CPU。如系统网络应用比较繁忙,可以考虑将网卡IRQ绑定到指定的CPU来提升系统处理中断的能力,从而提升整体性能。
可以通过cat/proc/interrupts查看中断情况,然后通过/proc/irq/N/smp_affinity手动设置中断要绑定的CPU。或者开启irqbalance优化中断分配,将中断均匀地分发给CPU。
还有如大数据计算集群、数据库集群应该和应用集群隔离到不同的机架或机房,实现网络的隔离。
因为大数据计算或数据库同步时会占用比较大的网络带宽,可能会拥塞网络导致应用响应变慢。
还有一些其他类似的隔离术,如环境隔离(测试环境、预发布环境/灰度环境、正式环境)、压测隔离(真实数据、压测数据隔离)、AB测试(为不同的用户提供不同版本的服务)、缓存隔离(有些系统混用缓存,而有些系统会扔大字节值到Redis,造成Redis慢查询)、查询隔离(简单、批量、复杂条件查询分别路由到不同的集群)等。通过隔离,可以将风险降到最低,将性能提升至最优。
使用Hystrix实现隔离
Hystrix是Netflix开源的一款针对分布式系统的延迟和容错库,目的是用来隔离分布式服务故障。它提供线程和信号量隔离,以减少不同服务之间资源竞争带来的相互影响。
提供优雅降级机制,提供熔断机制使得服务可以快速失败,而不是一直阻塞等待服务响应,并能从中快速恢复。
Hystrix通过这些机制来阻止级联失败并保证系统弹性、可用。下图是一个典型的分布式服务实现。
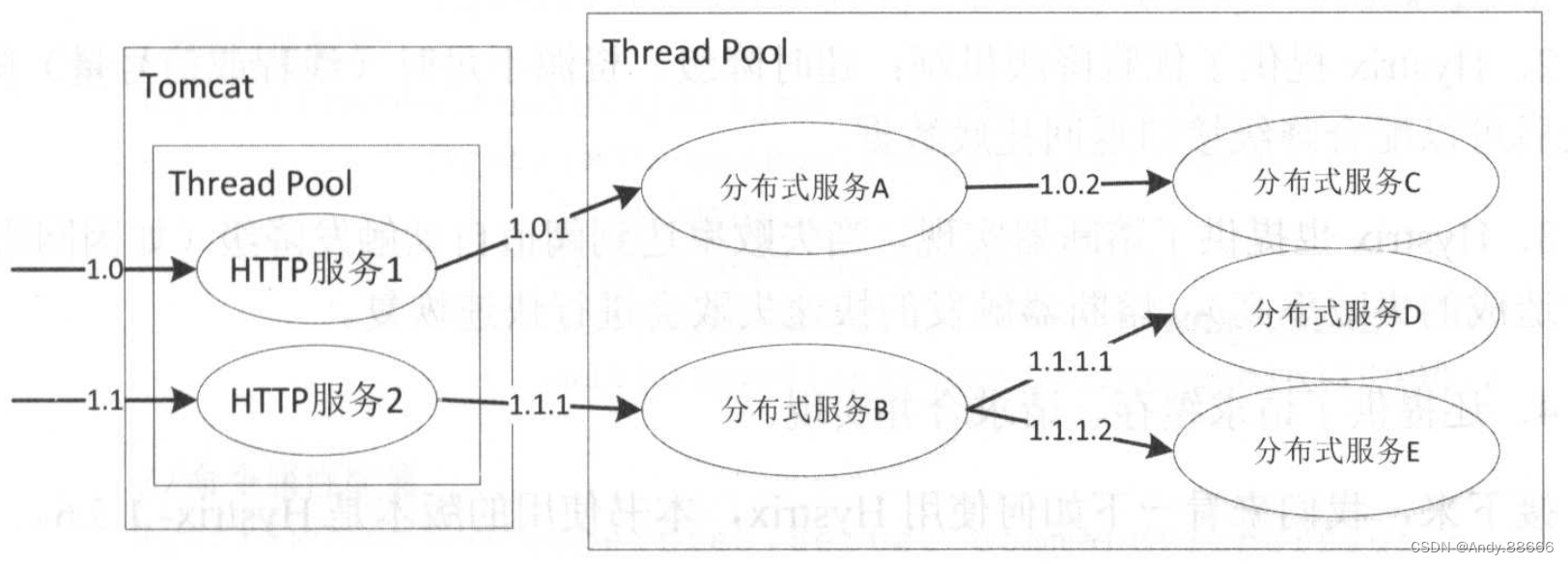
当大多数人在使用Tomcat时,多个HTTP服务会共享一个线程池,假设其中一个HTTP服务访问的数据库响应非常慢,这将造成服务响应时间延迟增加,大多数线程阻塞等待数据响应返回,导致整个Tomcat线程池都被该服务占用,甚至拖垮整个Tomcat。因此,如果我们能把不同HTTP服务隔离到不同的线程池,则某个HTTP服务的线程池满了也不会对其他服务造成灾难性故障。这就需要线程隔离或者信号量隔离来实现了。
使用线程隔离或信号隔离的目的是为不同的服务分配一定的资源,当自己的资源用完,直接返回失败而不是占用别人的资源。
同理,如“HTTP服务1”和“HTTP服务2”要分别访问远程的“分布式服务A”和“分布式服务B”,假设它们共享线程池,那么其中一个服务在出现问题时也会影响到另一个服务,因此,我们需要进行访问隔离,可以通过Hystrix的线程池隔离或信号量隔离来实现。
其次,“分布式服务B”依赖了“分布式服务D”和“分布式服务E”,其中“分布式服务D”是一个可降级的服务,意思是出现故障时(如超时、网络故障)可以暂时屏蔽掉或者返回缓存脏数据,如访问商品详情页时,可以暂时屏蔽掉上边的商家信息,不会影响用户下单流程。
当我们依赖的服务访问超时时,要提供降级策略。比如,返回托底数据阻止级联故障。当因为一些故障(如网络故障)使得服务可用率下降时,要能及时熔断,一是快速失败,二是可以保护远程分布式服务。
到此我们大体了解了Hystrix是用来解决什么问题的。
- 限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用,通过线程池隔离和信号量隔离实现。
- Hystrix提供了优雅降级机制:超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。
- Hystrix也提供了熔断器实现,当失败率达到阈值自动触发降级(如因网络故障/超时造成的失败率高),熔断器触发的快速失败会进行快速恢复。
- 还提供了请求缓存、请求合并实现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!