1-GAN
一、GAN简介
人脸检测、图像识别、语音识别,机器总是在现有事物的基础上做出描述或判断[参考]
能不能创造这个世界不存在的东西?GAN
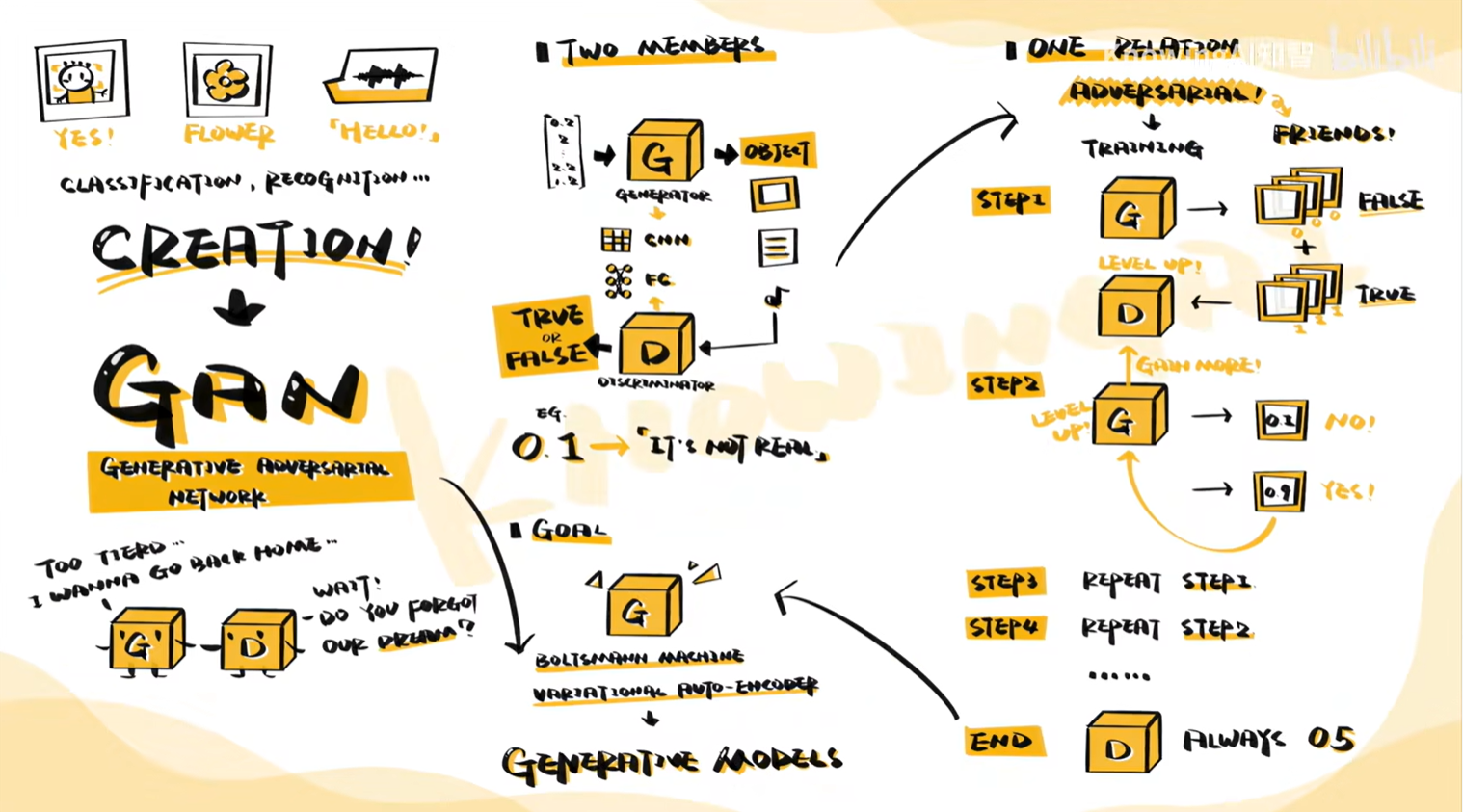
GAN,全称Generative Adversarial Networks,中文叫生成式对抗网络。GAN它包含三个部分(生成、判别和对抗),训练GAN的最终目标是获得一个足够好用的生成器(也就是生成能够以假乱真的内容), 能够完成类似功能的还有玻尔兹曼机,变分自编码器等等,它们被称为生成模型。
GAN分为两个模块,生成网络以及判别网络。
生成网络?负责依据先验分布P(Z)中提取的随机向量z(通常选择正态或均匀分布为先验分布)产生图片、语音等内容,产生的内容是数据集中没有见过的,也可以称为虚假内容;
判别网络 负责对生成网络产生的虚假内容和另一端输入的真实内容进行判断,判断其内容是否是真实的,通常它会给出一个概率来代表内容的真实度,真实内容打高分,虚假内容打低分。
两者使用何种网络(擅长处理图片的 CNN,全连接)并没有规定,只要能完成相应的功能就可以。
对抗,就是指GAN两个网络交替训练的过程,其中生成网络为了欺骗判别网络,会不断提升自己的生成效果,做到以假乱真,令判别网络一直认为生成网络产生的内容是真实的:而判别网络为了不被生成网络欺骗也会不断提升自己的判别效果,做到拥有一双“火眼金睛”一直能识别出生成网络产生的虚假内容。即生成网络为了在判别网络中得到高分,会不断提升自己的性能,而判别网络为了能准确地给生成网络打低分,也会不断提升自己的性能,双方就是在一种对抗的过程中互相提升自己,这就是GAN[参考]。
?以图片生成为例:
①先让生成器产生一些[假]图片和收集到的[真]图片一起交给判别器,让它学习区分两者,给真的高分,给假的低分。
②当判别器能够熟练判断现有数据后,再让生成器以从判别器处获得高分为目标,不断生成更好的[假]图片, 直到能骗过判别器
重复进行这一过程, 直到判别器对任何图片的预测概率都接近0.5,也就是无法分辨图片的真假,就停止训练。

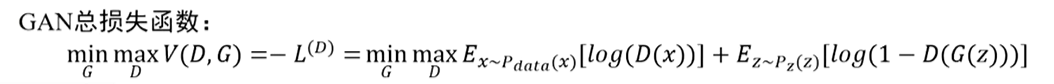
二、GAN反演
GAN的生成网络输入的是随机噪声z,而非真实图片,因此它产生的结果是具有随机性的。假设我们通过训练好的GAN网络得到一张非常逼真的虚假人物图片x',这就是我们想要的效果,但在日后的实验中我们又想对这张x' 图片的脸部进行修改,比如更改头发颜色、修改眉毛细节,那能否继续用GAN网络进行生成呢?
我们需要再找到一个精确的随机噪声z',通过z'来生成我们想要的修改结果。

反演(inversion):对目标图像x,推断出Z空间中的一个z,把z输入给生成器时产生一个与x非常相似的图像。从x推断z的过程称为反演。每个z值映射到单个图像x,单个x值可能存在多个可能的z来表示。

常规的GAN 模型如 PGGAN 和 BigGAN 是从预定义的分布空间Z(如正态分布)中采样噪声向量z,再把采样的值送入生成器,从而映射到图像空间,这个预定义的分布空间Z即为 GAN 的隐空间atent space),而这个采样的噪声向量z,也会被称之为隐码(latent code)。

隐空间是压缩数据的一个表示。隐空间的作用是为了找到模式(pattern)而学习数据特征并且简化数据表示。数据压缩指用比原来表示更少的比特对信息进行编码。比如将一个3维的数据降到2维。

1)为什么要数据压缩?
数据压缩的目的是学习数据中较重要的信息。比如在卷积神经网络中,我们通过CNN提取图片特征再将提取的特征送入解码器进行数据重建,所以模型最关注的问题就是如何储存所有相关信息并且舍弃一些例如噪音等的无关信息。而压缩(降维)的好处在于可以去掉多余的信息从而关注于最关键的特征。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!