【无标题】
2023-12-17 20:16:09
文章目录

针对大学名称 大学排名, 综合指数,学校情况等数据进行爬取
首先进行鼠标右键,进行数据抓包
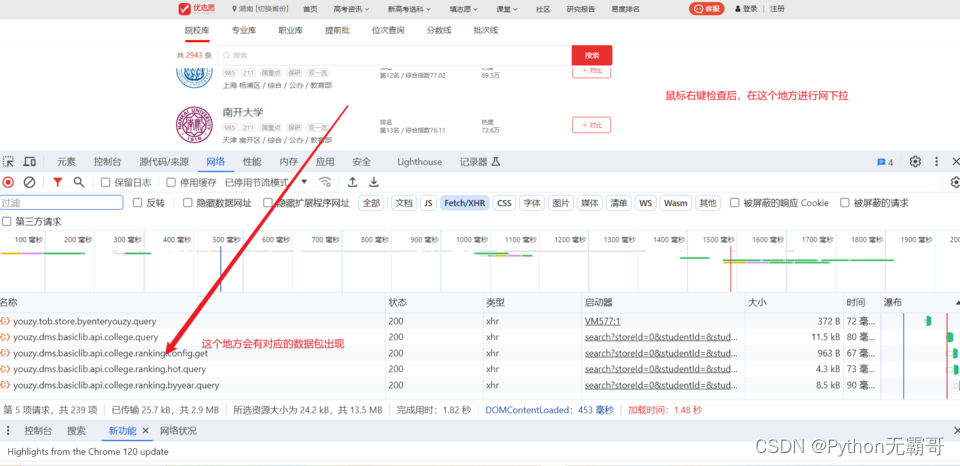
找对应得数据包
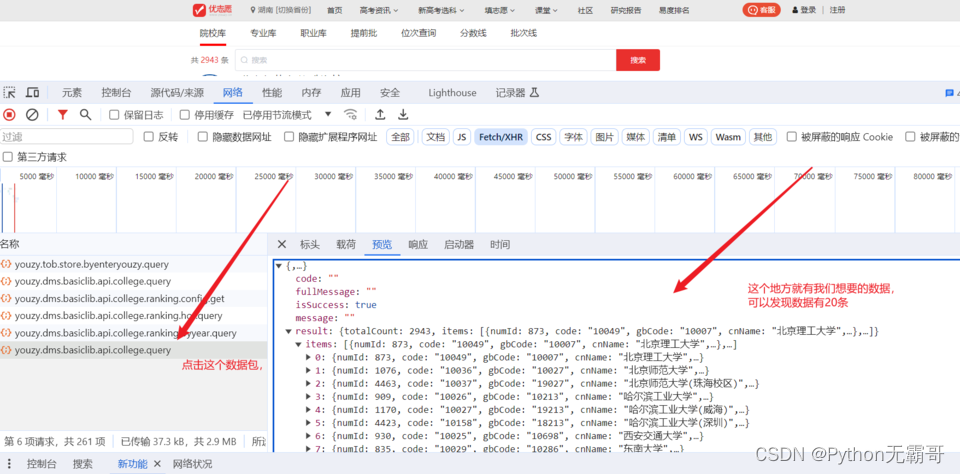
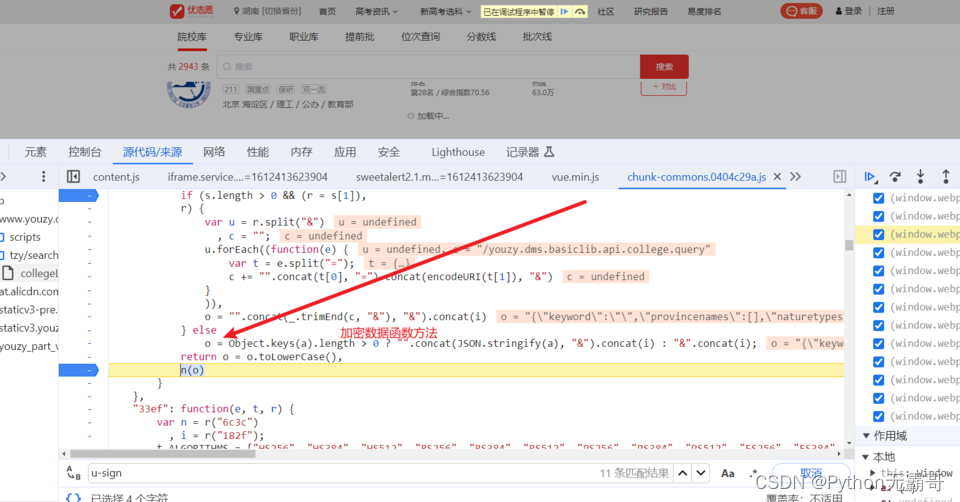
请求发现数据有加密
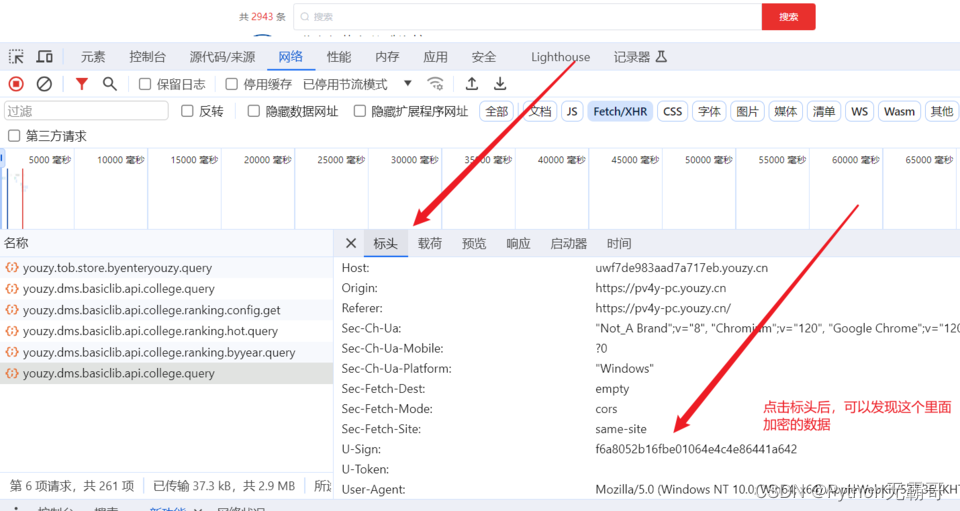
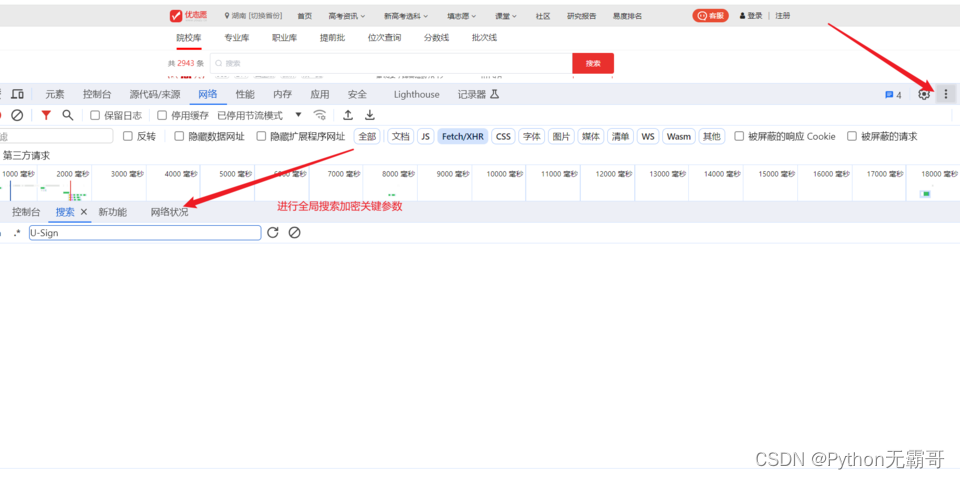
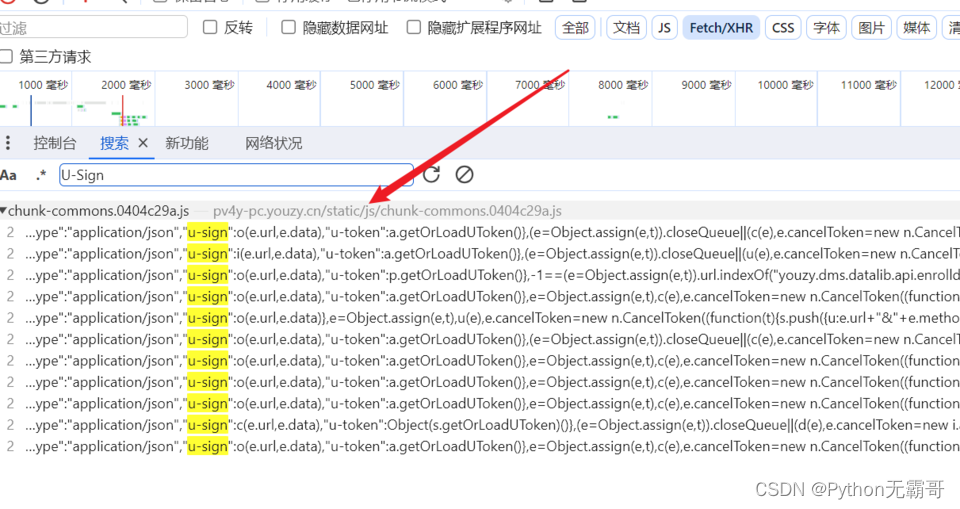
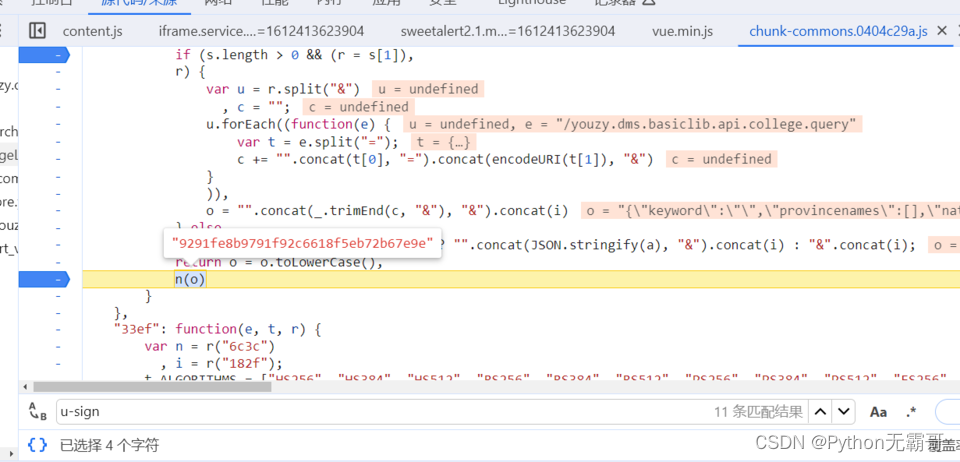
发现加密参数
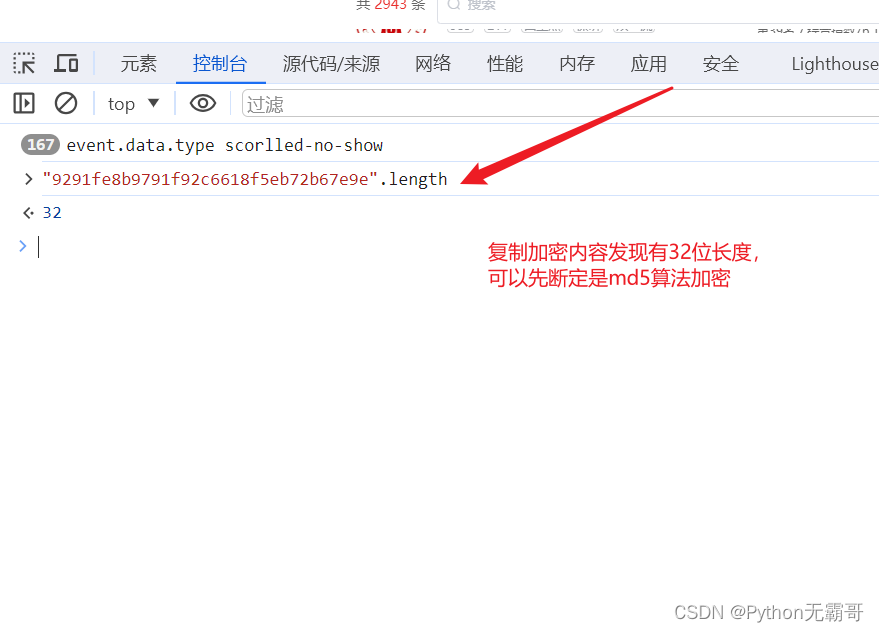
搜索加密参数,好进行分析
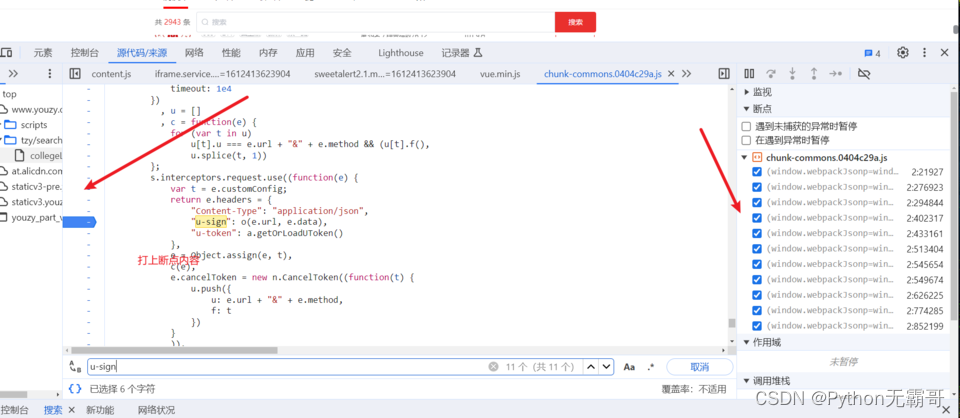
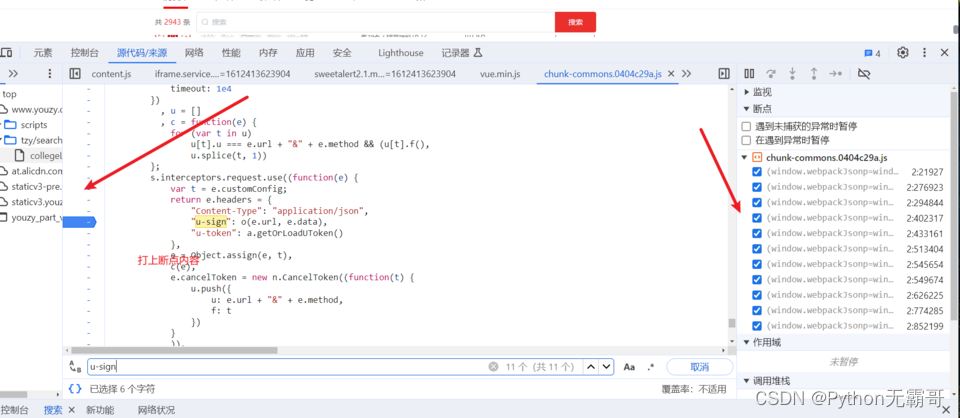
分析过程
In [2]:
!pip install jsonpath
Collecting jsonpath
Downloading jsonpath-0.82.2.tar.gz (10 kB)
Preparing metadata (setup.py) ... done
Building wheels for collected packages: jsonpath
Building wheel for jsonpath (setup.py) ... done
Created wheel for jsonpath: filename=jsonpath-0.82.2-py3-none-any.whl size=6724 sha256=3db960d7ff6f0bb132346f0e72e00349a7f6156100fc98c35ffda5cee786b2bf
Stored in directory: /home/mw/.cache/pip/wheels/2c/2a/fa/87e26ec807b9a21dd0464eb1319cc3ad51b0c9e505fe6b7396
Successfully built jsonpath
Installing collected packages: jsonpath
Successfully installed jsonpath-0.82.2
import requests
import json
import hashlib
import jsonpath
import pandas as pd
for i in range(1, 2):
data = '{"keyword":"","provincenames":[],"naturetypes":[],"edulevel":"","categories":[],"features":[],"pageindex":%s,"pagesize":20,"sort":11}&9sasji5owng41irkisvtjhlxhmrysrp1' % i
md5 = hashlib.md5(data.encode())
# md5.update(content.encode('utf-8'))
sign = md5.hexdigest()
print(sign)
headers = {
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Content-Type": "application/json",
"Origin": "https://pv4y-pc.youzy.cn",
"Referer": "https://pv4y-pc.youzy.cn/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-site",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Not_A Brand\";v=\"8\", \"Chromium\";v=\"120\", \"Google Chrome\";v=\"120\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"u-sign": sign,
"u-token": ""
}
url = "https://uwf7de983aad7a717eb.youzy.cn/youzy.dms.basiclib.api.college.query"
data = {"keyword":"","provinceNames":[],"natureTypes":[],"eduLevel":"","categories":[],"features":[],"pageIndex":i,"pageSize":20,"sort":11}
data = json.dumps(data, separators=(',', ':'))
response = requests.post(url, headers=headers, data=data).json()
# print(resps)
# 学校名称
data_name = jsonpath.jsonpath(response, '$..cnName')
print(data_name)
# 学校类型
data_shape = jsonpath.jsonpath(response, '$..categories')
# 综合指数
data_comScore = jsonpath.jsonpath(response, '$..comScore')
# 是不是本科
data_eduLevel = jsonpath.jsonpath(response, '$..eduLevel')
# 学校情况
data_features = jsonpath.jsonpath(response, '$..features')
# 排名
data_ranking = jsonpath.jsonpath(response, '$..ranking')
# 热度
data_hits = jsonpath.jsonpath(response, '$..hits')
# 部门
data_belong = jsonpath.jsonpath(response, '$..belong')
data = {'学校名称': data_name, '学校类型': data_shape, '综合指数': data_comScore, '学历': data_eduLevel,
'学校情况': data_features, '排名': data_ranking, '热度': data_hits,
'部门': data_belong}
df = pd.DataFrame(pd.DataFrame.from_dict(data, orient='index').values.T, columns=list(data.keys()))
print(df)
# df.to_csv("中国院校统计.csv",index=False)
643ff9499febb3ee34c95ffe0bb29cb0
['清华大学', '北京大学', '北京大学医学部', '中国科学院大学', '复旦大学', '复旦大学上海医学院', '上海交通大学', '上海交通大学医学院', '中国科学技术大学', '中国人民大学', '中国人民大学(苏州校区)', '浙江大学', '浙江大学医学院', '南京大学', '北京航空航天大学', '北京航空航天大学中法航空学院', '武汉大学', '同济大学', '南开大学', '中国人民解放军国防科技大学']
学校名称 学校类型 综合指数 学历 学校情况 排名 热度 \
0 清华大学 [综合] 93.59 ben [985, 211, 国重点, 保研, 双一流] 1 1378946
1 北京大学 [综合] 92.13 ben [985, 211, 国重点, 保研, 双一流] 2 2155577
2 北京大学医学部 [医药] 92.13 ben [985, 211, 国重点, 保研, 双一流] 2 439830
3 中国科学院大学 [综合] 79.95 ben [国重点, 保研, 双一流] 3 474549
4 复旦大学 [综合] 83.73 ben [985, 211, 国重点, 保研, 双一流] 4 1091717
5 复旦大学上海医学院 [医药] 83.73 ben [985, 211, 国重点, 保研, 双一流] 4 321950
6 上海交通大学 [综合] 84.72 ben [985, 211, 国重点, 保研, 双一流] 5 934308
7 上海交通大学医学院 [医药] 84.72 ben [985, 211, 国重点, 保研, 双一流] 5 306197
8 中国科学技术大学 [综合] 79.59 ben [985, 211, 国重点, 保研, 双一流] 6 540224
9 中国人民大学 [综合] 79.92 ben [985, 211, 保研, 国重点, 双一流] 7 895950
10 中国人民大学(苏州校区) [综合] 79.92 ben [985, 211, 保研, 双一流] 7 448989
11 浙江大学 [综合] 86.16 ben [985, 211, 国重点, 保研, 双一流] 8 1102871
12 浙江大学医学院 [医药] 86.16 ben [985, 211, 国重点, 双一流] 8 298237
13 南京大学 [综合] 80.51 ben [985, 211, 国重点, 保研, 双一流] 9 1068208
14 北京航空航天大学 [理工] 77.19 ben [985, 211, 保研, 双一流] 10 668746
15 北京航空航天大学中法航空学院 [] 77.19 ben [] 10 11630
16 武汉大学 [综合] 79.82 ben [985, 211, 国重点, 保研, 双一流] 11 1167221
17 同济大学 [综合] 77.02 ben [985, 211, 国重点, 保研, 双一流] 12 694969
18 南开大学 [综合] 76.11 ben [985, 211, 国重点, 保研, 双一流] 13 725994
19 中国人民解放军国防科技大学 [军事] 73.59 ben [985, 211, 国重点, 双一流] 14 717849
部门
0 教育部
1 教育部
2 教育部
3 中科院
4 教育部
5 教育部
6 教育部
7 教育部
8 中科院
9 教育部
10 教育部
11 教育部
12 浙江大学
13 教育部
14 工信部
15
16 教育部
17 教育部
18 教育部
19 中国共产党中央军事委员会
数据可视化
In [29]:
import pandas as pd
data=pd.read_csv("/home/mw/input/yuanxiao7383/中国院校统计.csv")
data
Out[29]:
| 学校名称 | 学校类型 | 综合指数 | 学历 | 学校情况 | 排名 | 热度 | 部门 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 清华大学 | ['综合'] | 93.59 | ben | ['985', '211', '国重点', '保研', '双一流'] | 1 | 1377703 | 教育部 |
| 1 | 北京大学 | ['综合'] | 92.13 | ben | ['985', '211', '国重点', '保研', '双一流'] | 2 | 2155049 | 教育部 |
| 2 | 北京大学医学部 | ['医药'] | 92.13 | ben | ['985', '211', '国重点', '保研', '双一流'] | 2 | 439644 | 教育部 |
| 3 | 中国科学院大学 | ['综合'] | 79.95 | ben | ['国重点', '保研', '双一流'] | 3 | 474239 | 中科院 |
| 4 | 复旦大学 | ['综合'] | 83.73 | ben | ['985', '211', '国重点', '保研', '双一流'] | 4 | 1091254 | 教育部 |
| 5 | 复旦大学上海医学院 | ['医药'] | 83.73 | ben | ['985', '211', '国重点', '保研', '双一流'] | 4 | 321828 | 教育部 |
| 6 | 上海交通大学 | ['综合'] | 84.72 | ben | ['985', '211', '国重点', '保研', '双一流'] | 5 | 933901 | 教育部 |
| 7 | 上海交通大学医学院 | ['医药'] | 84.72 | ben | ['985', '211', '国重点', '保研', '双一流'] | 5 | 306102 | 教育部 |
| 8 | 中国科学技术大学 | ['综合'] | 79.59 | ben | ['985', '211', '国重点', '保研', '双一流'] | 6 | 539918 | 中科院 |
| 9 | 中国人民大学 | ['综合'] | 79.92 | ben | ['985', '211', '保研', '国重点', '双一流'] | 7 | 895604 | 教育部 |
| 10 | 中国人民大学(苏州校区) | ['综合'] | 79.92 | ben | ['985', '211', '保研', '双一流'] | 7 | 448698 | 教育部 |
| 11 | 浙江大学 | ['综合'] | 86.16 | ben | ['985', '211', '国重点', '保研', '双一流'] | 8 | 1102369 | 教育部 |
| 12 | 浙江大学医学院 | ['医药'] | 86.16 | ben | ['985', '211', '国重点', '双一流'] | 8 | 298159 | 浙江大学 |
| 13 | 南京大学 | ['综合'] | 80.51 | ben | ['985', '211', '国重点', '保研', '双一流'] | 9 | 1067571 | 教育部 |
| 14 | 北京航空航天大学 | ['理工'] | 77.19 | ben | ['985', '211', '保研', '双一流'] | 10 | 668359 | 工信部 |
| 15 | 北京航空航天大学中法航空学院 | [] | 77.19 | ben | [] | 10 | 11509 | NaN |
| 16 | 武汉大学 | ['综合'] | 79.82 | ben | ['985', '211', '国重点', '保研', '双一流'] | 11 | 1166705 | 教育部 |
| 17 | 同济大学 | ['综合'] | 77.02 | ben | ['985', '211', '国重点', '保研', '双一流'] | 12 | 694605 | 教育部 |
| 18 | 南开大学 | ['综合'] | 76.11 | ben | ['985', '211', '国重点', '保研', '双一流'] | 13 | 725646 | 教育部 |
| 19 | 中国人民解放军国防科技大学 | ['军事'] | 73.59 | ben | ['985', '211', '国重点', '双一流'] | 14 | 717346 | 中国共产党中央军事委员会 |
| 20 | 北京理工大学 | ['理工'] | 74.96 | ben | ['985', '211', '保研', '双一流'] | 15 | 669865 | 工信部 |
| 21 | 北京师范大学 | ['师范'] | 76.59 | ben | ['985', '211', '保研', '国重点', '双一流'] | 16 | 698563 | 教育部 |
| 22 | 北京师范大学(珠海校区) | ['综合'] | 76.59 | ben | ['985', '211', '国重点', '保研', '双一流'] | 16 | 282745 | 教育部 |
| 23 | 哈尔滨工业大学 | ['理工'] | 76.45 | ben | ['985', '211', '国重点', '保研', '双一流'] | 17 | 724788 | 工信部 |
| 24 | 哈尔滨工业大学(威海) | ['理工'] | 76.45 | ben | ['985', '211', '国重点', '保研', '双一流'] | 17 | 506924 | 工信部 |
| 25 | 哈尔滨工业大学(深圳) | ['理工'] | 76.45 | ben | ['985', '211', '国重点', '保研', '双一流'] | 17 | 253199 | 工信部 |
| 26 | 西安交通大学 | ['综合'] | 77.40 | ben | ['985', '211', '国重点', '保研', '双一流'] | 18 | 879613 | 教育部 |
| 27 | 东南大学 | ['综合'] | 76.03 | ben | ['985', '211', '国重点', '保研', '双一流'] | 19 | 776147 | 教育部 |
| 28 | 东南大学医学院 | ['医药'] | 76.03 | ben | ['985', '211', '国重点', '保研', '双一流'] | 19 | 161457 | 教育部 |
| 29 | 华中科技大学 | ['综合'] | 77.98 | ben | ['985', '211', '国重点', '保研', '双一流'] | 20 | 1055994 | 教育部 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1570 | 阜阳职业技术学院 | ['理工'] | 0.00 | zhuan | [] | 0 | 27130 | 省政府 |
| 1571 | 湖南信息职业技术学院 | ['理工'] | 0.00 | zhuan | ['省重点'] | 0 | 32456 | 省政府 |
| 1572 | 秦皇岛职业技术学院 | ['理工'] | 0.00 | zhuan | [] | 0 | 90203 | 省政府 |
| 1573 | 浙江纺织服装职业技术学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 24877 | 省政府 |
| 1574 | 广东农工商职业技术学院 | ['综合'] | 0.00 | zhuan | ['省属'] | 0 | 30821 | 省政府 |
| 1575 | 江西旅游商贸职业学院 | ['财经'] | 0.00 | zhuan | ['省重点'] | 0 | 26661 | 省政府 |
| 1576 | 唐山职业技术学院 | ['综合'] | 0.00 | zhuan | ['省属'] | 0 | 41608 | 省政府 |
| 1577 | 沈阳航空职业技术学院 | ['理工'] | 0.00 | zhuan | ['省重点'] | 0 | 27589 | 省政府 |
| 1578 | 七台河职业学院 | ['综合'] | 0.00 | zhuan | ['省属'] | 0 | 19431 | 省政府 |
| 1579 | 甘肃有色冶金职业技术学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 19093 | 省政府 |
| 1580 | 宁夏职业技术学院 | ['综合'] | 0.00 | zhuan | ['省属'] | 0 | 27452 | 自治区政府 |
| 1581 | 内蒙古警察职业学院 | ['政法'] | 0.00 | zhuan | ['省属'] | 0 | 26005 | 自治区政府 |
| 1582 | 天津海运职业学院 | ['综合'] | 0.00 | zhuan | ['省重点'] | 0 | 47443 | 市政府 |
| 1583 | 广东工贸职业技术学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 33165 | 省政府 |
| 1584 | 湘潭医卫职业技术学院 | ['医药'] | 0.00 | zhuan | ['省属'] | 0 | 33889 | 省政府 |
| 1585 | 黑龙江建筑职业技术学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 32713 | 省政府 |
| 1586 | 温州职业技术学院 | ['综合'] | 0.00 | zhuan | [] | 0 | 37202 | 省政府 |
| 1587 | 浙江东方职业技术学院 | ['综合'] | 0.00 | zhuan | [] | 0 | 25348 | 省教育厅 |
| 1588 | 辽宁建筑职业学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 34613 | 省政府 |
| 1589 | 邢台医学高等专科学校 | ['医药'] | 0.00 | zhuan | [] | 0 | 56330 | 省政府 |
| 1590 | 铁岭师范高等专科学校 | ['师范'] | 0.00 | zhuan | ['省属'] | 0 | 32921 | 省政府 |
| 1591 | 广西水利电力职业技术学院 | ['理工'] | 0.00 | zhuan | [] | 0 | 25498 | 自治区政府 |
| 1592 | 武汉外语外事职业学院 | ['综合'] | 0.00 | zhuan | [] | 0 | 24622 | 省教育厅 |
| 1593 | 福建信息职业技术学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 24146 | 省政府 |
| 1594 | 平顶山工业职业技术学院 | ['理工'] | 0.00 | zhuan | ['省属'] | 0 | 27876 | 省政府 |
| 1595 | 广东省外语艺术职业学院 | ['艺术'] | 0.00 | zhuan | ['省属'] | 0 | 39208 | 省政府 |
| 1596 | 长沙航空职业技术学院 | ['理工'] | 0.00 | zhuan | ['省重点'] | 0 | 112407 | 空军装备部 |
| 1597 | 桂林师范高等专科学校 | ['师范'] | 0.00 | zhuan | [] | 0 | 26748 | 自治区政府 |
| 1598 | 山东商务职业学院 | ['综合'] | 0.00 | zhuan | ['省属'] | 0 | 43707 | 省政府 |
| 1599 | 延边职业技术学院 | ['理工'] | 0.00 | zhuan | [] | 0 | 23005 | 省政府 |
In?[30]:
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1600 entries, 0 to 1599
Data columns (total 8 columns):
学校名称 1600 non-null object
学校类型 1600 non-null object
综合指数 1600 non-null float64
学历 1600 non-null object
学校情况 1600 non-null object
排名 1600 non-null int64
热度 1600 non-null int64
部门 1588 non-null object
dtypes: float64(1), int64(2), object(5)
memory usage: 100.1+ KBIn?[31]:
import jieba
# jieba.load_userdict('addwords.txt')
title_cut = []
for i in data.学校情况:
j = jieba.lcut(i)
title_cut.append(j)Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.971 seconds.
Prefix dict has been built succesfully.In?[32]:
cut_words = jieba.lcut(str(data['学校情况'].values), cut_all = False)
In?[33]:
file_path = open(r'/home/mw/input/data8378/stopwords.txt',encoding='utf-8')
stop_words = file_path.read()In?[34]:
# 新建一个空列表,用于存储删除停用词后的数据
new_data = []
for word in cut_words:
if word not in stop_words:
new_data.append(word)
print(new_data)['[', '"', '[', "'", '985', "'", "'", '211', "'", "'", '国', '重点', "'", "'", '保研', "'", "'", '双', '一流', "'", ']', '"', '"', '[', "'", '985', "'", "'", '211', "'", "'", '国', '重点', "'", "'", '保研', "'", "'", '双', '一流', "'", ']', '"', '"', '[', "'", '985', "'", "'", '211', "'", "'", '国', '重点', "'", "'", '保研', "'", "'", '双', '一流', "'", ']', '"', '...', "'", '[', ']', "'", '"', '[', "'", '省属', "'", ']', '"', "'", '[', ']', "'", ']']
In?[35]:
from nltk import FreqDist
freq_list = FreqDist(new_data)
# 返回词语列表
most_common_words = freq_list.most_common()
print(most_common_words)[("'", 36), ('"', 8), ('[', 7), (']', 7), ('985', 3), ('211', 3), ('国', 3), ('重点', 3), ('保研', 3), ('双', 3), ('一流', 3), ('...', 1), ('省属', 1)]
In?[36]:
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
from pyecharts.globals import SymbolType
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", most_common_words, word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="美团标题标签可视化"))
)
return c
wd = wordcloud_base()
wd.render_notebook()Out[36]:

In?[25]:
import numpy as np
data["综合指数"] = data["综合指数"].astype(np.int64)
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1600 entries, 0 to 1599
Data columns (total 8 columns):
学校名称 1600 non-null object
学校类型 1600 non-null object
综合指数 1600 non-null int64
学历 1600 non-null object
学校情况 1600 non-null object
排名 1600 non-null int64
热度 1600 non-null int64
部门 1588 non-null object
dtypes: int64(3), object(5)
memory usage: 100.1+ KBIn?[26]:
data['学校类型']=data['学校类型'].apply(lambda x: x.replace('[', '').replace(']', ''))
data['学校类型']Out[26]:
0 '综合'
1 '综合'
2 '医药'
3 '综合'
4 '综合'
5 '医药'
6 '综合'
7 '医药'
8 '综合'
9 '综合'
10 '综合'
11 '综合'
12 '医药'
13 '综合'
14 '理工'
15
16 '综合'
17 '综合'
18 '综合'
19 '军事'
20 '理工'
21 '师范'
22 '综合'
23 '理工'
24 '理工'
25 '理工'
26 '综合'
27 '综合'
28 '医药'
29 '综合'
...
1570 '理工'
1571 '理工'
1572 '理工'
1573 '理工'
1574 '综合'
1575 '财经'
1576 '综合'
1577 '理工'
1578 '综合'
1579 '理工'
1580 '综合'
1581 '政法'
1582 '综合'
1583 '理工'
1584 '医药'
1585 '理工'
1586 '综合'
1587 '综合'
1588 '理工'
1589 '医药'
1590 '师范'
1591 '理工'
1592 '综合'
1593 '理工'
1594 '理工'
1595 '艺术'
1596 '理工'
1597 '师范'
1598 '综合'
1599 '理工'
Name: 学校类型, Length: 1600, dtype: objectIn?[27]:
# 查看缺失值
data.isnull().any()Out[27]:
学校名称 False
学校类型 False
综合指数 False
学历 False
学校情况 False
排名 False
热度 False
部门 True
dtype: boolIn?[28]:
# 查看数据结构
data.describe()Out[28]:
| 综合指数 | 排名 | 热度 | |
|---|---|---|---|
| count | 1600.000000 | 1600.000000 | 1.600000e+03 |
| mean | 47.107500 | 477.676875 | 1.650321e+05 |
| std | 25.032106 | 406.079676 | 1.851948e+05 |
| min | 0.000000 | 0.000000 | 2.730000e+03 |
| 25% | 55.000000 | 43.750000 | 5.205350e+04 |
| 50% | 57.000000 | 435.500000 | 9.286500e+04 |
| 75% | 60.000000 | 835.250000 | 2.108105e+05 |
| max | 93.000000 | 1235.000000 | 2.155049e+06 |
In?[10]:
data2 = data.groupby('学校名称')['综合指数'].agg(['mean', 'median'])
data2Out[10]:
| mean | median | |
|---|---|---|
| 学校名称 | ||
| 七台河职业学院 | 0 | 0 |
| 三亚中瑞酒店管理职业学院 | 0 | 0 |
| 三亚学院 | 55 | 55 |
| 三峡大学 | 62 | 62 |
| 三峡大学科技学院 | 57 | 57 |
| 三明学院 | 58 | 58 |
| 三江学院 | 56 | 56 |
| 三门峡社会管理职业学院 | 0 | 0 |
| 三门峡职业技术学院 | 0 | 0 |
| 上海中侨职业技术大学 | 55 | 55 |
| 上海中医药大学 | 65 | 65 |
| 上海交通大学 | 84 | 84 |
| 上海交通大学医学院 | 84 | 84 |
| 上海体育大学 | 64 | 64 |
| 上海健康医学院 | 59 | 59 |
| 上海公安学院 | 0 | 0 |
| 上海兴伟学院 | 56 | 56 |
| 上海商学院 | 60 | 60 |
| 上海外国语大学 | 68 | 68 |
| 上海外国语大学贤达经济人文学院 | 55 | 55 |
| 上海大学 | 71 | 71 |
| 上海对外经贸大学 | 65 | 65 |
| 上海工程技术大学 | 61 | 61 |
| 上海师范大学 | 65 | 65 |
| 上海师范大学天华学院 | 56 | 56 |
| 上海应用技术大学 | 61 | 61 |
| 上海建桥学院 | 55 | 55 |
| 上海思博职业技术学院 | 0 | 0 |
| 上海戏剧学院 | 65 | 65 |
| 上海政法学院 | 64 | 64 |
| ... | ... | ... |
| 黄冈师范学院 | 59 | 59 |
| 黄冈职业技术学院 | 0 | 0 |
| 黄山学院 | 59 | 59 |
| 黄河交通学院 | 57 | 57 |
| 黄河科技学院 | 56 | 56 |
| 黄淮学院 | 57 | 57 |
| 黎明职业大学 | 0 | 0 |
| 黑河学院 | 56 | 56 |
| 黑龙江东方学院 | 55 | 55 |
| 黑龙江中医药大学 | 60 | 60 |
| 黑龙江八一农垦大学 | 58 | 58 |
| 黑龙江外国语学院 | 55 | 55 |
| 黑龙江大学 | 62 | 62 |
| 黑龙江工业学院 | 57 | 57 |
| 黑龙江工商学院 | 55 | 55 |
| 黑龙江工程学院 | 58 | 58 |
| 黑龙江工程学院昆仑旅游学院 | 55 | 55 |
| 黑龙江建筑职业技术学院 | 0 | 0 |
| 黑龙江科技大学 | 59 | 59 |
| 黑龙江财经学院 | 55 | 55 |
| 黔南民族师范学院 | 57 | 57 |
| 齐鲁医药学院 | 57 | 57 |
| 齐鲁工业大学 | 60 | 60 |
| 齐鲁师范学院 | 59 | 59 |
| 齐鲁理工学院 | 55 | 55 |
| 齐齐哈尔医学院 | 58 | 58 |
| 齐齐哈尔大学 | 58 | 58 |
| 齐齐哈尔工程学院 | 54 | 54 |
| 齐齐哈尔高等师范专科学校 | 0 | 0 |
| 龙岩学院 | 58 | 58 |
1600 rows × 2 columns
In?[11]:
data_brand=data2.sort_values(by='median', ascending=True).tail(10)
data_brandOut[11]:
| mean | median | |
|---|---|---|
| 学校名称 | ||
| 南京大学 | 80 | 80 |
| 复旦大学上海医学院 | 83 | 83 |
| 复旦大学 | 83 | 83 |
| 上海交通大学 | 84 | 84 |
| 上海交通大学医学院 | 84 | 84 |
| 浙江大学 | 86 | 86 |
| 浙江大学医学院 | 86 | 86 |
| 北京大学医学部 | 92 | 92 |
| 北京大学 | 92 | 92 |
| 清华大学 | 93 | 93 |
In?[12]:
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (Bar()
.add_xaxis(list(data_brand.index))
.add_yaxis('',[int(i) for i in(round(data_brand['median']))])
.set_global_opts(title_opts=opts.TitleOpts(title="中国大学综合指数概况", subtitle="中位数"),xaxis_opts=opts.AxisOpts(name_rotate=0,name="综合指数",axislabel_opts={"rotate":60}))
)
bar.render_notebook()Out[12]:

In?[13]:
data3 = data.groupby('学校名称')['热度'].agg(['mean', 'median'])
data3
Out[13]:
| mean | median | |
|---|---|---|
| 学校名称 | ||
| 七台河职业学院 | 19431 | 19431 |
| 三亚中瑞酒店管理职业学院 | 21755 | 21755 |
| 三亚学院 | 104658 | 104658 |
| 三峡大学 | 501787 | 501787 |
| 三峡大学科技学院 | 89985 | 89985 |
| 三明学院 | 98712 | 98712 |
| 三江学院 | 101231 | 101231 |
| 三门峡社会管理职业学院 | 20692 | 20692 |
| 三门峡职业技术学院 | 37561 | 37561 |
| 上海中侨职业技术大学 | 57802 | 57802 |
| 上海中医药大学 | 214334 | 214334 |
| 上海交通大学 | 933901 | 933901 |
| 上海交通大学医学院 | 306102 | 306102 |
| 上海体育大学 | 76233 | 76233 |
| 上海健康医学院 | 115812 | 115812 |
| 上海公安学院 | 106291 | 106291 |
| 上海兴伟学院 | 33532 | 33532 |
| 上海商学院 | 155186 | 155186 |
| 上海外国语大学 | 302454 | 302454 |
| 上海外国语大学贤达经济人文学院 | 92331 | 92331 |
| 上海大学 | 607608 | 607608 |
| 上海对外经贸大学 | 243112 | 243112 |
| 上海工程技术大学 | 224267 | 224267 |
| 上海师范大学 | 407476 | 407476 |
| 上海师范大学天华学院 | 76674 | 76674 |
| 上海应用技术大学 | 291811 | 291811 |
| 上海建桥学院 | 188996 | 188996 |
| 上海思博职业技术学院 | 33447 | 33447 |
| 上海戏剧学院 | 116150 | 116150 |
| 上海政法学院 | 219194 | 219194 |
| ... | ... | ... |
| 黄冈师范学院 | 104892 | 104892 |
| 黄冈职业技术学院 | 42997 | 42997 |
| 黄山学院 | 60550 | 60550 |
| 黄河交通学院 | 60367 | 60367 |
| 黄河科技学院 | 96146 | 96146 |
| 黄淮学院 | 152150 | 152150 |
| 黎明职业大学 | 32186 | 32186 |
| 黑河学院 | 69555 | 69555 |
| 黑龙江东方学院 | 50417 | 50417 |
| 黑龙江中医药大学 | 169616 | 169616 |
| 黑龙江八一农垦大学 | 125798 | 125798 |
| 黑龙江外国语学院 | 49229 | 49229 |
| 黑龙江大学 | 344645 | 344645 |
| 黑龙江工业学院 | 121327 | 121327 |
| 黑龙江工商学院 | 42071 | 42071 |
| 黑龙江工程学院 | 117734 | 117734 |
| 黑龙江工程学院昆仑旅游学院 | 34104 | 34104 |
| 黑龙江建筑职业技术学院 | 32713 | 32713 |
| 黑龙江科技大学 | 238421 | 238421 |
| 黑龙江财经学院 | 55881 | 55881 |
| 黔南民族师范学院 | 55214 | 55214 |
| 齐鲁医药学院 | 121623 | 121623 |
| 齐鲁工业大学 | 329048 | 329048 |
| 齐鲁师范学院 | 134712 | 134712 |
| 齐鲁理工学院 | 99493 | 99493 |
| 齐齐哈尔医学院 | 120487 | 120487 |
| 齐齐哈尔大学 | 164782 | 164782 |
| 齐齐哈尔工程学院 | 47971 | 47971 |
| 齐齐哈尔高等师范专科学校 | 28897 | 28897 |
| 龙岩学院 | 80677 | 80677 |
In?[14]:
data_line=data3.sort_values(by='median', ascending=True).tail(10)
data_lineOut[14]:
| mean | median | |
|---|---|---|
| 学校名称 | ||
| 四川大学 | 1018881 | 1018881 |
| 苏州大学 | 1054040 | 1054040 |
| 华中科技大学 | 1055994 | 1055994 |
| 南京大学 | 1067571 | 1067571 |
| 复旦大学 | 1091254 | 1091254 |
| 浙江大学 | 1102369 | 1102369 |
| 吉林大学 | 1113904 | 1113904 |
| 武汉大学 | 1166705 | 1166705 |
| 清华大学 | 1377703 | 1377703 |
| 北京大学 | 2155049 | 2155049 |
In?[15]:
from pyecharts.charts import Line
line = (Line()
.add_xaxis(list(data_line.index))
.add_yaxis('',[int(i) for i in(round(data_line['mean']))])
.set_global_opts(title_opts=opts.TitleOpts(title="中国大学热度概况top10", subtitle="平均"),xaxis_opts=opts.AxisOpts(name_rotate=0,name="热度",axislabel_opts={"rotate":60}))
)
line.render_notebook()Out[15]:

In?[16]:
data["部门"].unique()
Out[16]:
array(['教育部', '中科院', '浙江大学', '工信部', nan, '中国共产党中央军事委员会', '公安部', '社科院',
'中国人民解放军海军', '市政府', '省政府', '国民委', '中国人民解放军陆军', '国卫委', '统战部',
'中国人民解放军空军', '交通运输部', '国体局', '省教育厅', '自治区政府', '海关总署',
'交通运输部(中国民用航空局)', '新疆生产建设兵团', '中华妇女联合会', '中华全国总工会', '市教委',
'河南省体育局', '应管部', '地震局', '自治区教育厅', '香港特别行政区教育局', '澳门特别行政区政府',
'中华人民共和国澳门特别行政区高等教育局', '中国人民解放军火箭军', '香港特别行政区政府教育局', '香港特别行政区政府',
'上海市 中国科学院', '中国人民武装警察部队总部', '国家军委', '外交部', '解放军战略支援部队航天系统部',
'中国人民解放军战略支援部队', '共青团', '中国澳门特区政府', '中央办公厅', '司法部', '中国人民武装警察部队',
'中国人民武装警察部队政治部', '解放军成都军区', '中央军委联合参谋部', '中国人民解放军空军总部',
'中国共产党中央军事委员会政治工作部', '解放军兰州军区', '香港特别行政区政府高等教育署', '中国人民解放军',
'解放军总参谋部', '澳门特别行政区社会文化司', '空军装备部'], dtype=object)
In?[17]:
from collections import Counter
# 使用 Counter 统计元素出现次数
counts = Counter(data["部门"])
# 使用 sorted() 函数对出现次数进行降序排序
sorted_counts = sorted(counts.items(), key=lambda x: x[1], reverse=True)
# 打印结果
for element, count in sorted_counts:
print(element, count)省政府 780 省教育厅 386 教育部 95 市政府 89 自治区政府 80 市教委 38 自治区教育厅 21 nan 12 工信部 9 中国人民解放军陆军 8 香港特别行政区教育局 7 国民委 6 公安部 5 中国人民解放军空军 5 中国人民解放军海军 4 新疆生产建设兵团 3 中国人民武装警察部队 3 解放军总参谋部 3 中科院 2 统战部 2 交通运输部(中国民用航空局) 2 应管部 2 香港特别行政区政府 2 中国人民武装警察部队总部 2 浙江大学 1 中国共产党中央军事委员会 1 社科院 1 国卫委 1 交通运输部 1 国体局 1 海关总署 1 中华妇女联合会 1 中华全国总工会 1 河南省体育局 1 地震局 1 澳门特别行政区政府 1 中华人民共和国澳门特别行政区高等教育局 1 中国人民解放军火箭军 1 香港特别行政区政府教育局 1 上海市 中国科学院 1 国家军委 1 外交部 1 解放军战略支援部队航天系统部 1 中国人民解放军战略支援部队 1 共青团 1 中国澳门特区政府 1 中央办公厅 1 司法部 1 中国人民武装警察部队政治部 1 解放军成都军区 1 中央军委联合参谋部 1 中国人民解放军空军总部 1 中国共产党中央军事委员会政治工作部 1 解放军兰州军区 1 香港特别行政区政府高等教育署 1 中国人民解放军 1 澳门特别行政区社会文化司 1 空军装备部 1
In?[19]:
from pyecharts import options as opts
from pyecharts.charts import Radar
# 数据
data = [
{"value": [780, 386, 95, 89, 80, 38], "name": "实际值"},
{"value": [1000, 1000, 1000, 1000, 1000, 1000], "name": "目标值"}
]
# 指示器名称
indicator = [
{"name": "省政府", "max": 1000},
{"name": "省教育厅", "max": 1000},
{"name": "教育部", "max": 1000},
{"name": "自治区政府", "max": 1000},
{"name": "市教委", "max": 1000},
{"name": "自治区教育厅", "max": 1000},
]
# 绘图
radar = (
Radar()
.set_global_opts(title_opts=opts.TitleOpts(title="中国院校部门雷达图"))
.add_schema(schema=indicator)
.add("数据", data, label_opts=opts.LabelOpts(is_show=False))
)
# 展示
radar.render_notebook()Out[19]:

文章来源:https://blog.csdn.net/weixin_45841831/article/details/135047202
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!