data_loader返回的每个batch的数据大小是怎么计算得到的?
data_loader是一个通用的术语,用于表示数据加载器或数据批次生成器。它是在机器学习和深度学习中常用的一个概念。
一、data loader
数据加载器(data loader)是一个用于加载和处理数据集的工具,它可以将数据集划分为小批次(batches)并提供给模型进行训练或推断。数据加载器的主要目的是帮助有效地处理大规模数据集,并提供可迭代的接口,以便在每个批次中获取数据。
在训练模型时,通常需要将数据集分成多个批次进行训练。这样做的好处包括:
- 内存效率:将整个数据集一次性加载到内存中可能导致内存不足的问题,而使用数据加载器可以逐批次地加载数据,减少内存消耗。
- 训练效率:使用批次训练可以利用并行计算的优势,加快模型训练的速度。
- 模型收敛性:批次训练可以提供更多的样本多样性,帮助模型更好地收敛。
数据加载器通常会接收以下参数:
- 数据集:要加载和处理的数据集。
- 批次大小(batch size):每个批次中包含的样本数量。
- 随机化(shuffle):是否在每个时期(epoch)开始时对数据进行随机化,以提高模型的泛化能力。
数据加载器可以是自定义的实现,也可以是使用机器学习框架(如TensorFlow、PyTorch等)提供的内置函数或类来实现。它们通常会提供一个迭代器或生成器接口,使用户可以通过迭代获取每个批次的数据。
需要根据具体的机器学习框架和任务来选择和使用适当的数据加载器。常见的数据加载器包括torch.utils.data.DataLoader(PyTorch)、tf.data.Dataset(TensorFlow)等。这些加载器提供了更多功能,如数据预处理、并行加载、数据增强等,以满足不同的数据处理需求。
二、data_loader返回的每个batch的数据大小是怎么计算得到的?
data_loader返回的每个批次(batch)的数据大小是根据数据集的总样本数量和批次大小来计算得到的。
通常情况下,数据集的总样本数量可以通过查看数据集的长度或大小来获取。例如,对于一个包含1000个样本的数据集,总样本数量为1000。
批次大小是指在每个批次中包含的样本数量。它可以由用户指定,通常是根据内存限制、模型训练的效果和计算资源等因素来确定。常见的批次大小可以是32、64、128等。
计算每个批次的数据大小时,可以使用以下公式:
数据大小 = min(批次大小, 总样本数量 - 当前批次索引 * 批次大小)其中,当前批次索引从0开始。这个公式的作用是确保在最后一个批次中,即使样本数量不足一个完整的批次大小,也可以返回剩余的样本。
以下是一个简单的示例代码,演示如何计算每个批次的数据大小:
import math
def data_loader(dataset, batch_size):
total_samples = len(dataset)
num_batches = math.ceil(total_samples / batch_size)
for i in range(num_batches):
start_index = i * batch_size
end_index = min((i + 1) * batch_size, total_samples)
data_batch = dataset[start_index:end_index]
yield data_batch
# 示例数据集
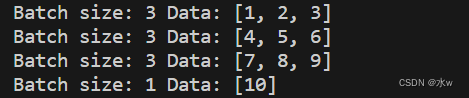
dataset = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
batch_size = 3
# 使用data_loader函数加载数据集
loader = data_loader(dataset, batch_size)
# 遍历每个批次的数据
for batch in loader:
print("Batch size:", len(batch), "Data:", batch)在上面的示例中,我们定义了一个data_loader函数,它接收数据集和批次大小作为输入,并使用生成器(generator)来逐个返回每个批次的数据。然后,我们使用示例数据集和批次大小调用data_loader函数,并遍历每个批次的数据。在输出中,我们可以看到每个批次的数据大小和对应的数据。
请注意,以上示例中的数据集是一个简单的列表,实际应用中的数据集可能是一个文件、数据库或其他数据源,需要根据具体情况进行适当的处理和加载。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!