?Linux Ubuntu环境下使用docker构建spark运行环境(超级详细)
?Linux Ubuntu环境下使用docker构建spark运行环境(超级详细)
这篇文章深入研究了在Linux Ubuntu环境下使用Docker构建Spark运行环境的详细步骤。首先,文章介绍了Spark的基本概念以及在大数据处理中的关键作用,为读者提供了对Spark的背景和价值的全面了解。随后,文章逐一解释了在Ubuntu系统中安装和配置Docker的具体步骤,为搭建Spark环境做好准备。
在Docker环境准备就绪后,文章详细说明了如何通过Docker容器配置Spark的运行环境,包括依赖项的安装、环境变量的设置以及Spark的核心组件的配置。通过这些步骤,读者将能够轻松地建立一个高效运行的Spark环境,以满足大数据处理的需求。
文章以超级详细的方式呈现了每个关键步骤,确保读者能够清晰理解并成功实施。最终,本文为在Linux Ubuntu环境下构建和配置Spark运行环境提供了实用的指南,为大数据处理提供了一个强大的工具和平台。
使用docker hub查找我们需要的镜像
参考 Docker Hub
curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
提示:curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused

原因应该是国外的ip,撞墙了 直接看解决方案吧
解决方案:
1、打开网站,https://www.ipaddress.com/,在此网站中查询一下 raw.githubusercontent.com对应的IP 地址
到这个网站查找这个域名绑定的ip

Vi etc/hosts
末尾加上:
185.199.108.133 raw.githubusercontent.com
curl运行成功

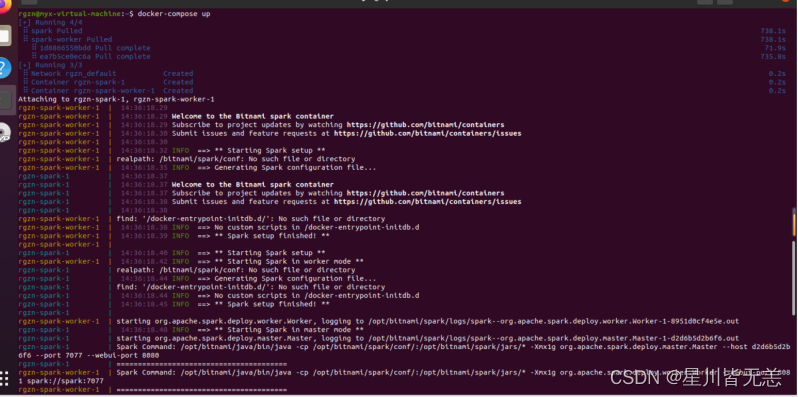
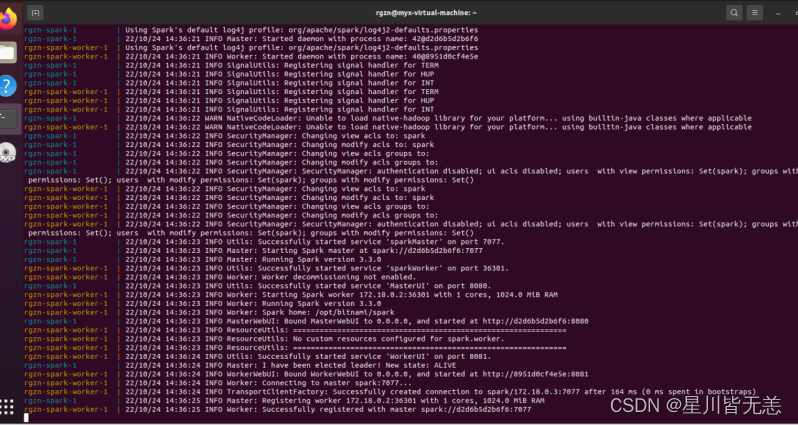
curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
?docker-compose up
?
?
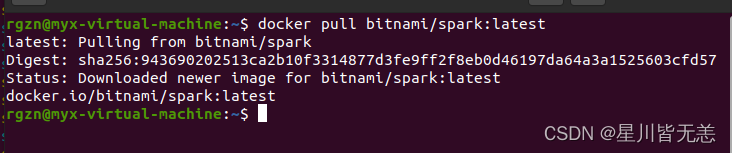
安装?Spark?的 docker 镜像
docker pull bitnami/spark:latest
docker pull bitnami/spark:[TAG]
 git clone出现 fatal: unable to access ‘https://github.com/...‘的解决方法
git clone出现 fatal: unable to access ‘https://github.com/...‘的解决方法
![]()
查阅了一些资料,发现需要在hosts文件中添加映射。
vi /etc/hosts在hosts文件中加入两行
140.82.113.4 github.com
140.82.113.4 www.github.com
git clone

 cd bitnami/APP/VERSION/OPERATING-SYSTEM
cd bitnami/APP/VERSION/OPERATING-SYSTEM
找到对应目录:
cd /home/rgzn/containers/bitnami//spark/3.2/debian-11
?
?# . 表示当前目录
docker build -t bitnami/spark:latest .参数说明:
-t?:指定要创建的目标镜像名
.?:Dockerfile?文件所在目录,可以指定Dockerfile?的绝对路径
找到包含 Dockerfile 的目录并执行命令来自己构建映像

使用yml部署文件部署spark环境
spark.yml文件可以从本机编辑好再上传的虚拟机或服务器。spark.yml文件内容如下:
version: '3.8'
services:
spark-master:
image: bde2020/spark-master
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- ~/spark:/data
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:latest
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
volumes:
- ~/spark:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
spark-worker-2:
image: bde2020/spark-worker:latest
container_name: spark-worker-2
depends_on:
- spark-master
ports:
- "8082:8081"
volumes:
- ~/spark:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
使用yml部署文件部署spark环境
cd /usr/local/bin创建文件sudo vim spark.yml
sudo chmod 777 spark.yml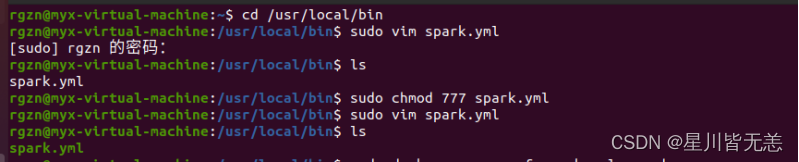
在spark.yml文件所在的目录下,执行命令:
sudo docker-compose -f spark.yml up -d![]()
查看容器创建与运行状态
sudo docker ps
对输出进行格式化
sudo docker ps --format '{{.ID}} {{.Names}}'
使用浏览器查看master的web ui界面
127.0.0.1:8080

http://192.168.95.171:50070

进入spark-master容器
sudo docker exec -it <master容器的id,仅需输入一部分即刻> /bin/bash
sudo docker exec -it 98600cfa9ba7 /bin/bash
查询spark环境,安装在/spark下面。
ls /spark/bin
进入spark-shell
/spark/bin/spark-shell --master spark://spark-master:7077 --total-executor-cores 8 --executor-memory 2560m或者
/spark/bin/spark-shell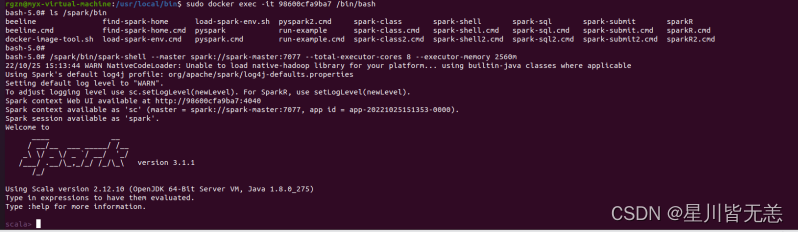
进入浏览器查看spark-shell的状态

测试:创建RDD与filter处理
创建一个RDD
val rdd=sc.parallelize(Array(1,2,3,4,5,6,7,8))
打印rdd内容
rdd.collect() ?查询分区数
?查询分区数
rdd.partitions.size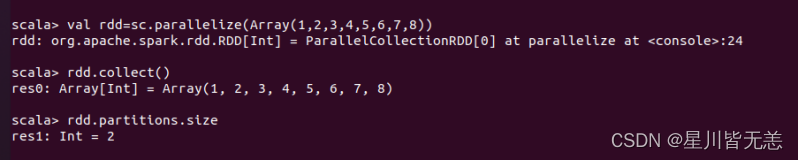
选出大于5的数值
val rddFilter=rdd.filter(_ > 5)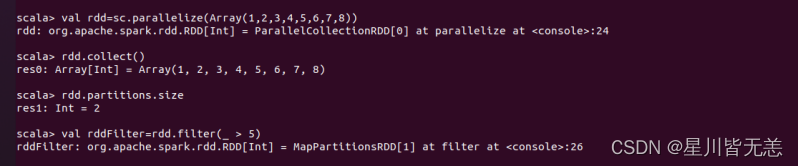
打印rddFilter内容
rddFilter.collect()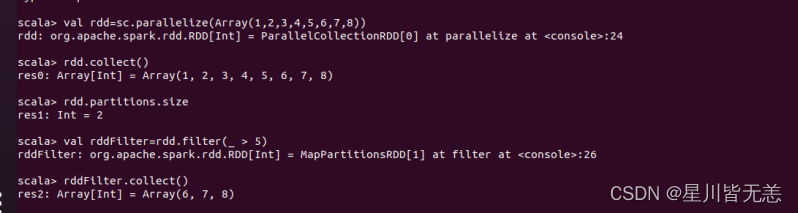
退出spark-shell
:quit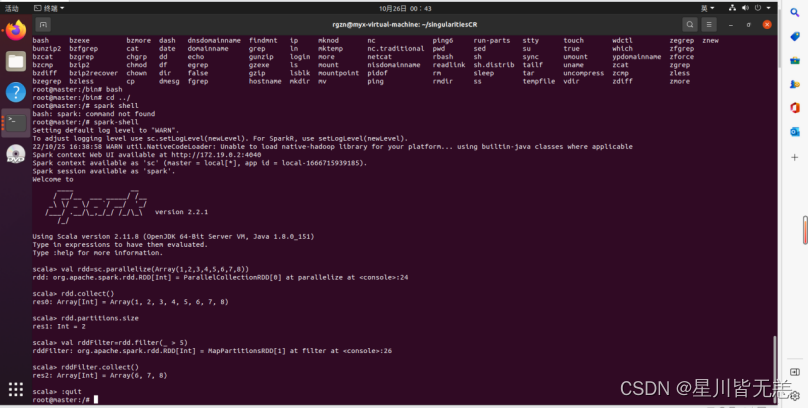
?运行案列成功!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!