线程使用越多程序越快?别瞎整。。。

当运行 CPU 密集型的并行程序时,通常希望将线程或进程池的大小设置为计算机上的 CPU 核数量,但有没有考虑过是否真的是核数用的越多并行程序越快?
理论上线程过少,无法充分利用所有核心,线程过多,程序会因为多个线程争夺同一核心而变得运行缓慢
事实上,确定要运行多少个线程没那么容易
- Python 标准库提供了多个获取此信息的 API,但没有一个是恰当的(稍后会举例)
- 由于 CPU 具有指令级并行性和同时多线程等功能(在英特尔 CPU 上称为超线程),可以有效使用的核心数量取决于编写的代码
从 Python 获取 CPU 内核数
前述提到在Python中获取内核数的API是不准确的,为啥这么说,我们看个例子
Python提供 os.cpu_count() 函数,可以返回 “系统中逻辑 CPU 的数量”
文档说明 “len(os.sched_getaffinity(0))可以获取当前进程调用线程受限的逻辑 CPU 数量”,调度器亲和性是一种限制进程使用特定内核的方法
遗憾的是,这个 API 也不够恰当,例如使用Docker在创建容器时人为限制CPU数量,比如将 CPU 限制为2.25 个内核
$ docker run -i -t --cpus=2.25 python:3.12-slim
Python 3.12.1 (main, Dec 9 2023, 00:21:37) [GCC 12.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import os
>>> os.cpu_count()
20
>>> len(os.sched_getaffinity(0))
20
在Docker中只提供了2.25个内核资源,但显然调用Python API时返回的数量仍不对
说完这个问题,还需要先了解物理和逻辑 CPU 内核是什么再进入正题
物理与逻辑 CPU内核
以英特尔 i7-12700K 处理器为例,它具有
- 12 个物理内核(8 个高性能内核和 4 个性能较弱的内核)
- 20 个逻辑内核
现代 CPU 内核可以并行执行多条指令,但如果 CPU 在等待从 RAM 中加载某些数据时卡住了,会发生什么情况?在此之前,它可能无法执行任何工作
为了充分利用这些可能被浪费的资源,CPU 物理内核的计算资源可以作为多个内核向操作系统公开。在这台电脑上,8 个高性能内核中的每一个都可以作为两个内核公开,总共有 16 个逻辑内核。成对的逻辑内核将共享单个物理内核的计算资源,例如,如果一个逻辑内核没有充分利用所有内部算术逻辑单元,比如因为它在等待内存加载,那么通过配对逻辑内核运行的代码仍然可以使用这些闲置资源
这种技术被称为同步多线程技术,英特尔称之为超线程技术。如果你有一台电脑,通常可以在 BIOS 中禁用它
这种解释非常不准确,而且不同型号的 CPU,即使是同一制造商生产的 CPU,实际执行情况也不尽相同。不过,逻辑内核与物理内核并不完全相同的一般意义足以满足这篇文章要表达的目的
现在又有了一个新问题,抛开调度器亲和性等因素不谈,我们应该使用物理内核数还是逻辑内核数作为线程池大小?
示例
在该例中,用 Numba 将两个函数编译成机器代码,确保释放 GIL 以实现并行
这两个函数做的事情一毛一样,但slow_threshold特意写成比较慢的方式而fast_threshold则更快(感兴趣的可以对比学习下为何另一个更快,很简单)。现在可以在多个线程上并行运行这些函数,在大多数人眼里,只需并行处理更多图像,就能线性提高吞吐量,直到内核耗尽,先从单核上进行测试
from numba import njit
import numpy as np
@njit(nogil=True)
def slow_threshold(img, noise_threshold):
noise_threshold = img.dtype.type(noise_threshold)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
result[i, j] = img[i, j] // 256
for i in range(result.shape[0]):
for j in range(result.shape[1]):
if result[i, j] < noise_threshold // 256:
result[i, j] = 0
return result
@njit(nogil=True)
def fast_threshold(img, noise_threshold):
noise_threshold = np.uint8(noise_threshold // 256)
result = np.empty(img.shape, dtype=np.uint8)
for i in range(result.shape[0]):
for j in range(result.shape[1]):
value = img[i, j] >> 8
value = (
0 if value < noise_threshold else value
)
result[i, j] = value
return result
rng = np.random.default_rng(12345)
def make_image(size=256):
noise = rng.integers(0, high=1000, size=(size, size), dtype=np.uint16)
signal = rng.integers(0, high=5000, size=(size, size), dtype=np.uint16)
# A noisy, hard to predict image:
return noise | signal
NOISY_IMAGE = make_image()
assert np.array_equal(
slow_threshold(NOISY_IMAGE, 1000),
fast_threshold(NOISY_IMAGE, 1000)
)
借助timeit测试单核上运行每个功能的性能,结果如下
%timeit slow_threshold(NOISY_IMAGE, 1000)
# 90.6 μs ± 77.7 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
%timeit fast_threshold(NOISY_IMAGE, 1000)
# 24.6 μs ± 10.8 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
结果如前所述,确实fast_threshold表现更好
并行化示例
现在我们使用线程池处理上述函数
from multiprocessing.dummy import Pool as ThreadPool
def apply_in_thread_pool(
num_threads, function, images
):
with ThreadPool(num_threads) as pool:
result = pool.map(
lambda img: function(img, 1000),
images,
chunksize=10
)
assert len(result) == len(images)
借助benchit绘制不同线程数运行不同函数所需的时间图
import benchit
benchit.setparams(rep=1)
# 4000 images to run through the pool:
IMAGES = [make_image() for _ in range(4000)]
def slow_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, slow_threshold, IMAGES)
def fast_threshold_in_pool(num_threads):
apply_in_thread_pool(num_threads, fast_threshold, IMAGES)
# Measure the two functions with 1 to 24 threads:
timings = benchit.timings(
[slow_threshold_in_pool, fast_threshold_in_pool],
range(1, 25),
input_name="Number of threads"
)
timings.plot(logy=True, logx=False)
绘制的图片如下
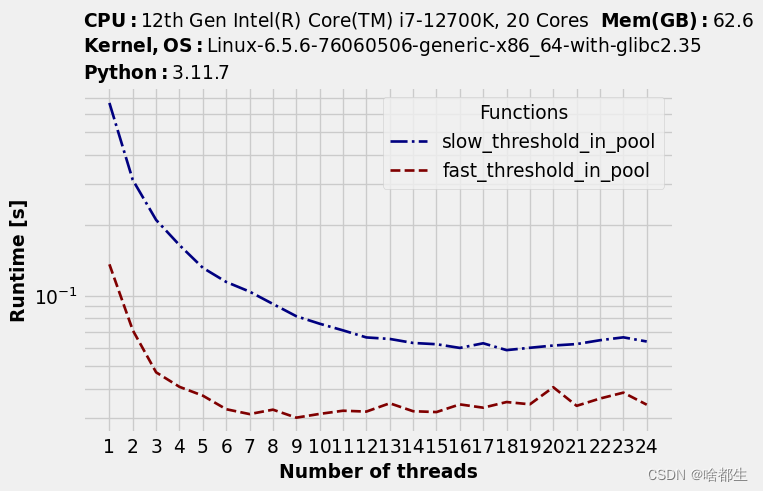
可以注意到随着线程数变多,运行时间先是有明显下降,但到一定程度后无明显改进,且另一个发现是每个函数的最佳线程数不同
timings.to_dataframe().idxmin(axis="rows")
| Functions | Optimal number of threads |
|---|---|
| slow_threshold | 19 |
| fast_threshold | 9 |
slow_threshold函数基本上可以利用所有逻辑内核,单线程可能无法充分利用特定物理内核的所有可用处理能力,因此逻辑内核允许更多并行性
相比之下,fast_threshold函数使用超过 9 个内核后,速度就开始减慢。可能遇到计算以外的瓶颈,比如内存带宽
总结
- 考虑到操作系统限制 CPU 使用的所有不同方式,很难获得准确的内核数量
- 最佳并行程度(如线程数)取决于工作量
- 内核数量并不是唯一的瓶颈
如果有一个长期运行的数据处理任务,需要在多个线程中运行相同的代码一段时间,通常也值得这样做,花一点时间根据经验测算出最佳线程数
https://pythonspeed.com/articles/cpu-thread-pool-size
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!