Linux 网络协议
1 网络基础
1.1 网络概念
网络是一组计算机或者网络设备通过有形的线缆或者无形的媒介如无线,连接起来,按照一定的规则,进行通讯的集合( 缺一不可 )。
5G的来临以及IPv6的不断普及,能够进行联网的设备将会是越来越多(物联网时代)。

网络功能和优点:
作用范围分类:
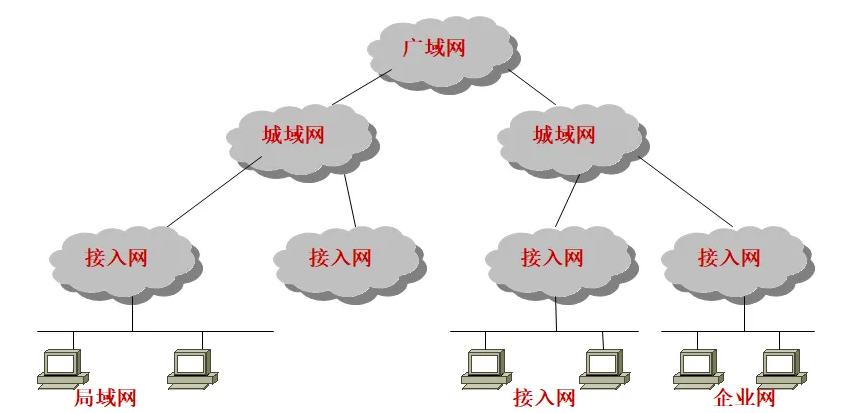
OpenVPN 为了解决出差移动的用户连接。底层技术:VPN 虚拟私有网络。
1.2 常见的网络物理组件
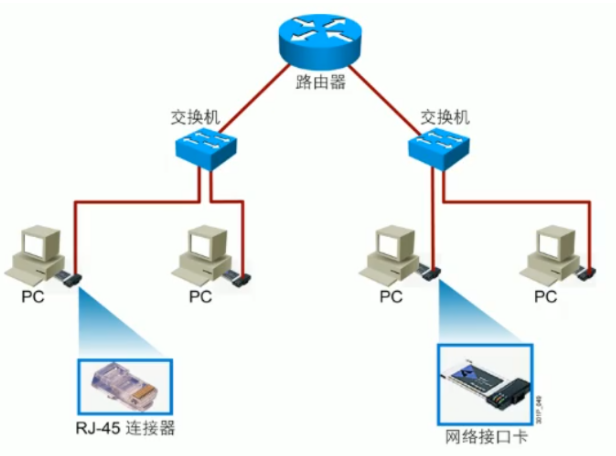
交换机 Switch :企业内部使用交换机最多,企业内部的网络设备普遍使用交换机进行连接。
路由器 Router :互联网连接的时候需要使用路由器
1.3 网络应用程序
1.3.1 各种网络应用
各种网络应用对网络的延迟是不尽相同的。
1.3.2 应用程序对网络的要求
1.4 网络的特征
网络特性
可靠性很难保证的情况下(很难保证硬件不出故障),就需要高可用性(又称冗余技术)来确保某个硬件出现故障后,还能使其功能可靠。
Raid 就是典型实现高可用的技术,还有 Keepalived,HAProxy等。
1.4.1 速度(带宽)
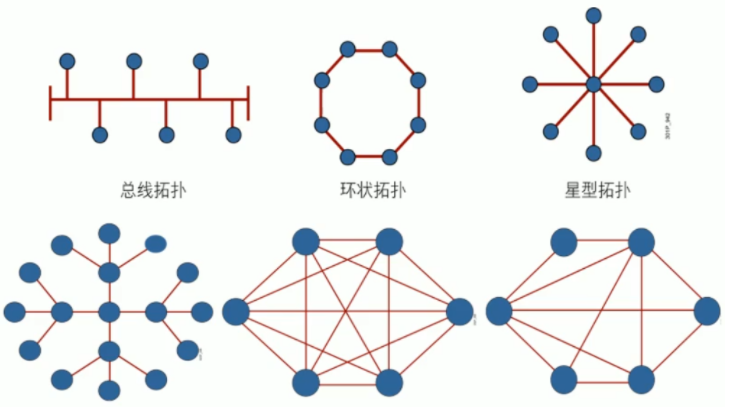
1.4.2 网络拓扑
拓扑结构一般是指由点和线排列成的几何图形
计算机网络的拓扑结构是指一个网络的通信链路和计算机结点相互连接构成的几何图形
拓扑分类
拓扑结构分类
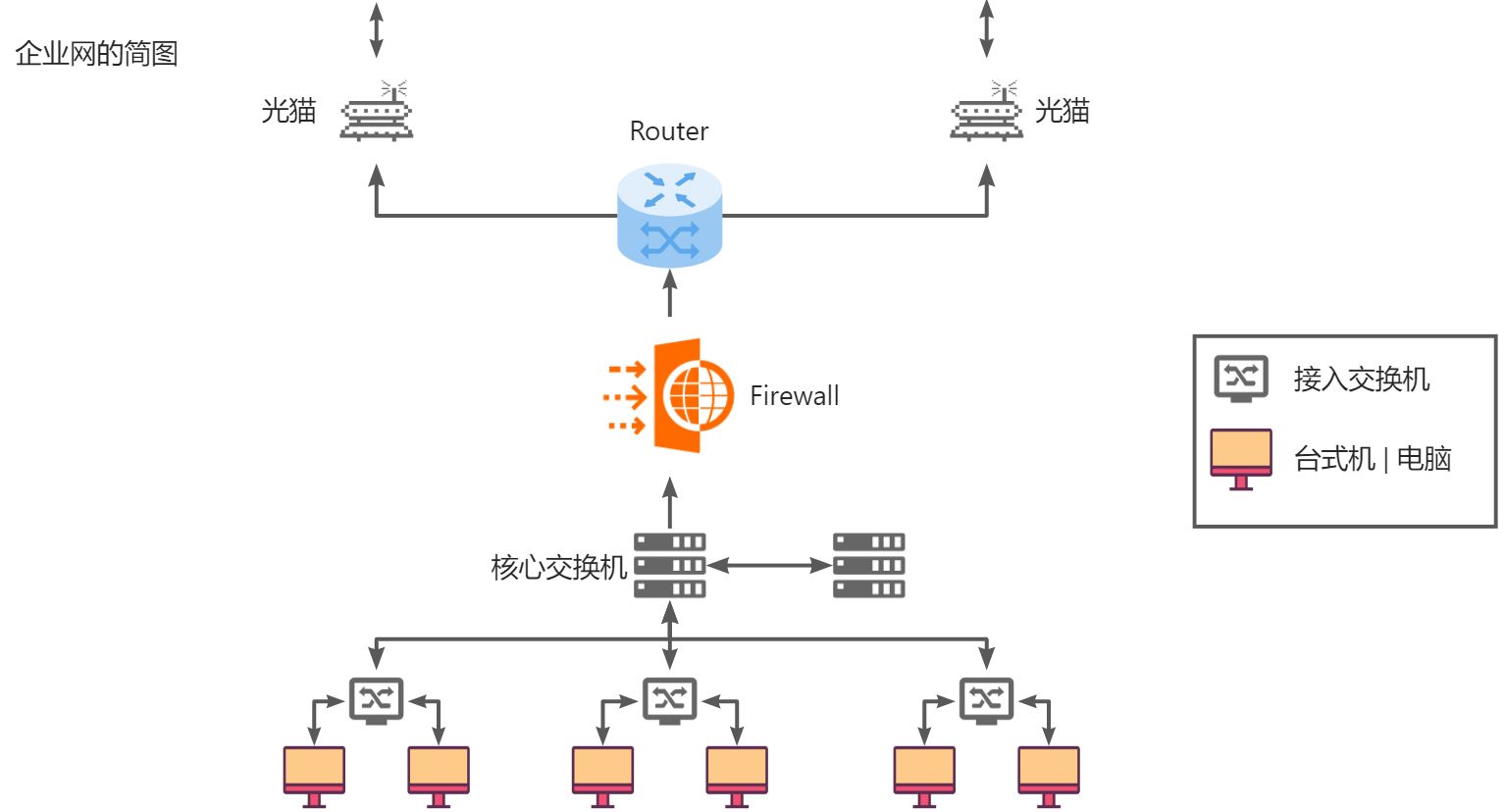
1.5 网络标准
1.5.1 网络标准和分层
旧模型:专有产品,由一个厂家控制应用程序和嵌入的软件,即各个厂家拥有自己的一套网络标准,造成厂家之间不兼容的情况。
基于标准的模型:多个厂家软件,分层方法
层次划分的必要性
计算机网络是由许多硬件,软件和协议交织起来的复杂系统。由于网络设计十分复杂,如何设计、组织和实现计算机网络是一个挑战,必须要采用科学有效的方法。
网络中拆分成多个层级,每一层都会有自己的标准和规范,层与层之间只要遵循标准,就可以实现互联互通。
层次划分的方法
层次划分的优点
1.5.2 开放系统互联OSI

在指定计算机网络标准方面,起着重大作用的两大国际组织是:国际电信联盟标准化部门,与国际标准组织(ISO),虽然它们工作领域不同,但是随着科学技术的发展,通信与信息处理之间的界限可以变得比较模糊,这也成了国际电信联盟标准化部门和ISO共同关心的领域。1984年,ISO发布了著名的OSI(Open System Interconnection,开放系统互联)标准,它定义了网络互连的7层框架,物理层、数据链路层、网络层、传输层、会话层、表示层和应用层,即OSI 开放系统互连参考模型。
OSI 模型的七层结构:
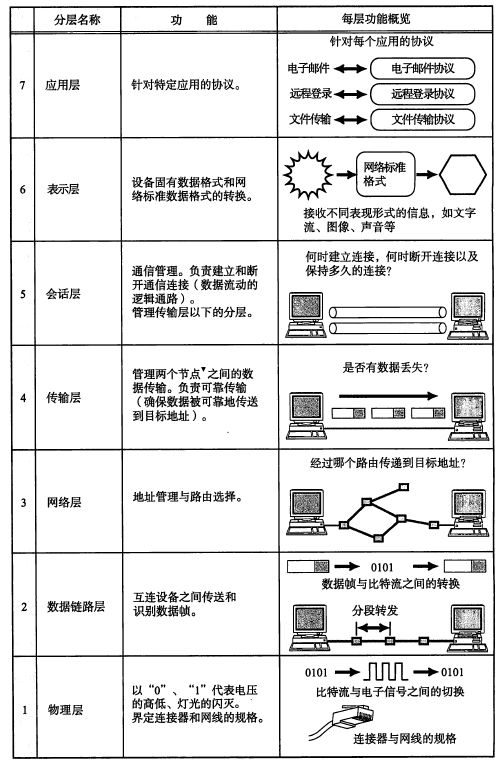
物理层,数据链路层,网络层通常是使用硬件来完成(但是并不绝对)。
传输层,会话层,表示层,应用层通常是使用软件来完成。
第 7 层 应用层
应用层(Application Layer)提供为应用软件而设的接口,以设置与另一个应用软件之间的通信。例如:HTTP、HTTPS、FTP、FTP、TELNET、SSH、SMTP、POP3、HTML、MySQL等等。(应用层实现不同应用的通信)
第 6 层 表示层
主条目:表示层或者表达层(Presentation Layer)把数据转换为能与接收者的系统格式兼容并且适合传输的格式。编码格式的兼容转换。(表示层负责进行编码,格式的转换以及传输,包括压缩加密解密)
第 5 层 会话层
会话层(Session Layer)负责在数据传输中设置和维护电脑网络中两台电脑之间的通信连接,例如:Xshell,浏览器等等。实现格式的互相兼容。(会话层实现两个主机之间的会话通信,用于维护通信连接的窗口)功能:建立会话,删除会话,管理会话等。
第 4 层 传输层
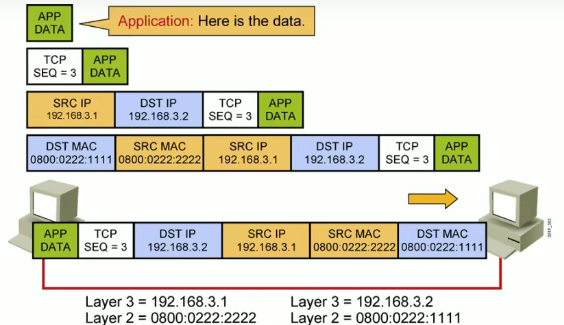
传输层(Transport Layer)把传输表头(TH)加至数据以形成数据包。传输表头包含了所使用的协议等发送信息。例如:传输控制协议(TCP)等等。在局部局域网上传送单位:数据段(Data Segment)端到端的数据传输。(传输层实现了两个节点之间传输数据的确认,分为可靠和不可靠。传输层要标识出机器中的每一个应用程序的地址,以及传输数据是否有丢失的情况)
第 3 层 网络层
网络层(Network Layer)在局部局域网上传送单位:数据包(Data Package)决定数据的路径选择和转寄,将网络表头(NH)加至数据包,以形成报文。网络表头包含了网络数据。例如:互联网协议(IP)等等。;例如:路由器。属于逻辑概念。(网络层用来选择最佳路径,网络层实现了多个网络(实现跨物理,跨链路的通信)之间的远程通信,链路层只解决了一个网络内部的通信)
第 2 层 数据链路层
数据链路层(Data Link Layer)在局部局域网上传送单位:数据帧(Data Frame)负责网络寻址、错误侦测和改错。当表头和表尾被加至数据包时,会形成信息框(Data Frame)。数据链表头(DLH)是包含了物理地址和错误侦测及改错的方法。数据链表尾(DLT)是一串指示数据包末端的字符串。例如以太网,无线局域网(Wi-Fi)和通用分组无线服务(GPRS)等等。分为两个子层:逻辑链路控制(Logical Link Control,LLC)子层和介质访问控制(Media Access Control,MAC)子层。例如:网卡、交换机等等。(数据链路层用来实现一个链路内部的通信,可以标识机器的源和目标(即链路层中的源MAC和 目的MAC,MAC地址就是用来链路区分不同的网络设备,每一个网络设备都要有一个与众不同的地址。))
LLC的主要功能是:处理两个站点之间的帧的交换,实现端到端(源到目的)的无差别的帧传输和应答功能以及流量控制功能。由于 LAN的介质共享特点,因而也可以实现广播式通信。
LLC可以为网络用户提供两种服务:无确认无连接服务和面向连接的服务。
(1)无确认无连接服务:它提供无需建立数据链路级连接而网络层实体能交换链路服务数据单元的手段。数据传送方式可以是点到点、点到多点式,也可以是广播式。这是一种数据报服务。
(2)面向连接的服务:在这种服务方式下,必须先建立链路连接,才能进行帧的传送。它提供了建立、维持、复位和终止数据链路层连接的手段。还提供了数据链路层的定序、流控和错误恢复,这是一种虚电路服务。
第 1 层 物理层
物理层(Physical Layer)在局部局域网上传送单位:比特(Bit),它负责管理电脑通信设备和网络媒体之间的互通。包括了针脚、电压、线缆规范、集线器、中继器、主机接口卡、网线、光纤等等。(物理层就是定义物理电器的电气特性,确保解决物理连通的功能)
现实局域网中使用的TCP/IP四层标准。OSI 七层模型作为研究参考以及学习的对象。
1.5.3 网络的通信过程
1.5.3.1 数据封装和数据解封装
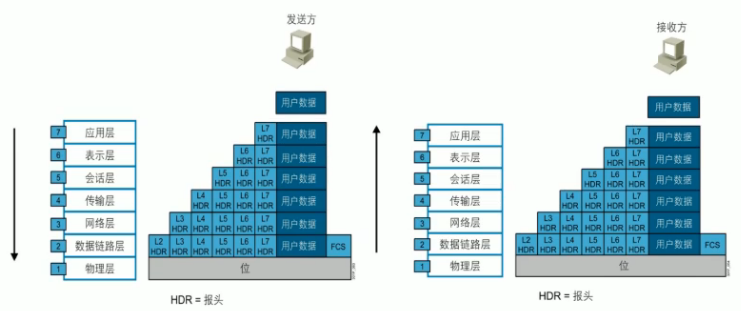
FCS:属于数据链路层,又称为CRC,校验位;防止网络传输过程中,因为某些原因组成数据的破坏,会将前面的数据利用算法计算出一个值放在FCS。对方也利用这个算法进行计算比较发送端的FCS。FCS相同则表示数据没有改变,FCS不同则表示数据被破坏,数据就会不可达。
1.5.3.2 协议数据单元 PDU

PDU:Protocol Data Unit,协议数据单元是指对等层次之间传递的数据单元。
每一层会将不同的部分数据整合在一起,形成一个单位。
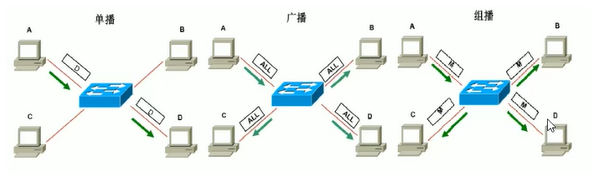
1.5.3.3 三种通讯模式
unicast:单播,目标设备是一个
broadcast:广播,目标设备是所有
multicast:多播,组播,目标设备是多个
1.5.3.4 冲突域和广播域
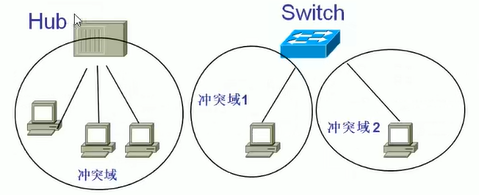
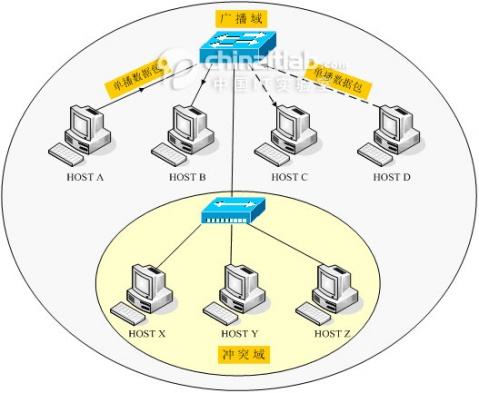
1.5.3.5 三种通讯机制
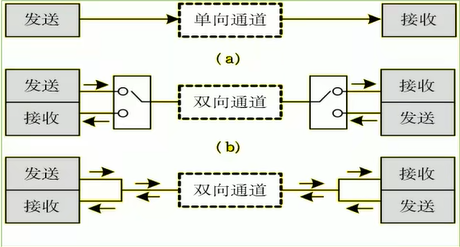
以上三种通信机制都是作用在物理层中。
范例:查看双工和速度
## mii-tool 和 ethtool 可以用来判断网线是否正常
#显示网卡的工作模式
~ mii-tool eth0
eth0: negotiated 1000baseT-FD flow-control, link ok
~ mii-tool -v eth0
eth0: negotiated 1000baseT-FD flow-control, link ok
product info: Yukon 88E1011 rev 3
basic mode: autonegotiation enabled
basic status: autonegotiation complete, link ok
#FD:全双工 HD:半双工
capabilities: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
advertising: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
link partner: 1000baseT-HD 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
~ ethtool -i eth0
~ ethtool eth0
ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
#自动协商
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
MDI-X: off (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
# 网络断开的状态
~ ip link show eth1
3: eth1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether 00:0c:29:16:73:3f brd ff:ff:ff:ff:ff:ff
~ ethtool eth1
Settings for eth1:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: Unknown!
Duplex: Unknown! (255)
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
MDI-X: Unknown (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: no
~ mii-tool -v eth1
eth1: no link
product info: Yukon 88E1011 rev 3
basic mode: autonegotiation enabled
basic status: no link
capabilities: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
advertising: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
面试题:如何判断系统的网线是断开的
~ ethtool ens160
~ mii-tool ens160 && mii-tool -v ens160
~ ip addr && ip link #查看对应的网卡状态信息
2 局域网 Local Area Network(LAN)
2.1 概述
2.1.1 特点
2.1.2 主要功能
2.1.3 优点
2.1.4 标准
IEEE(国际电子电气工程师协会) 于 1980年 2 月成立于局域网标准委员会(简称IEEE 802委员会),专门从事局域网标准化工作,并制定了IEEE 802标准。802标准所描述的局域网参考模型只对应 OSI 参考模型的数据链路层 与 物理层,它将数据链路层划分为逻辑链路层 LLC 子层 和介质访问控制 MAC 子层。以太网只约定了数据链路层和物理层,上层不关心。
LLC 子层负责向上提供访问:LLC 逻辑链路层用于 数据链路层的与上层(网络层)进行交互(主要任务是解决共享型网络中多用户对信道竞争的问题,完成网络介质的访问控制;)
MAC子层的主要功能包括数据帧的封装 / 卸装,帧的寻址和识别,帧的接收与发送,链路的管理,帧的差错控制等等。MAC子层的存在屏蔽了不同物理链路种类的差异性。(主要任务是建立和维护网络连接,执行差错校验、流量控制和链路控制。)
局域网标准
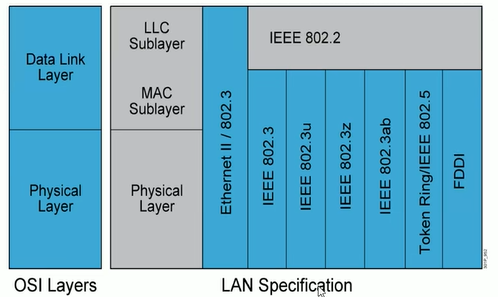
(1)IEEE 802.1 标准
局域网体系结构、网络互联、以及网络管理和性能测试
(2)IEEE 802.2 标准
逻辑链路控制 LLC 子层功能与服务
(3)IEEE 802.3 标准
(带冲突检测的载波侦听多路访问)CSMA/CD 总线介质访问控制子层 与 物理层规范
(4)IEEE 802.4 标准
令牌总线(Token Bus)介质访问控制子层 与 物理层规范
(5)IEEE 802.5 标准
令牌环(Token Ring)介质访问控制子层 与 物理层规范
(6)IEEE 802.6 标准
城域网 MAN 介质访问控制子层 与 物理层规范
(7)IEEE 802.7 标准
带宽网络技术
(8)IEEE 802.8 标准
光纤传输技术
(9)IEEE 802.9 标准
综合语音与数据局域网(IVD LAN)技术
(10)IEEE 802.10 标准
可互操作的局域网安全性规范(SILS)
(11)IEEE 802.11 标准
无线局域网技术(Wi-Fi)
(12)IEEE 802.12 标准
优先度要求的访问控制方法
(13)IEEE 802.13 标准
未使用
(14)IEEE 802.14 标准
交互式电视网
(15)IEEE 802.15 标准
无线个人局域网(WPAN)的MAC子层和物理层规范,代表技术为 蓝牙(Bluetooth)
(16)IEEE 802.16 标准
带宽无线局域网网络
(17)IEEE 802.20 标准
移动带宽无线接入系统(MBWA,Mobile Boradband Wireless Access)
(18)IEEE 802.22 标准
无线地域网络(Wireless Regional Area Networks,WRAN)
无线网络标准
中国国家无线网络标准:WAPI
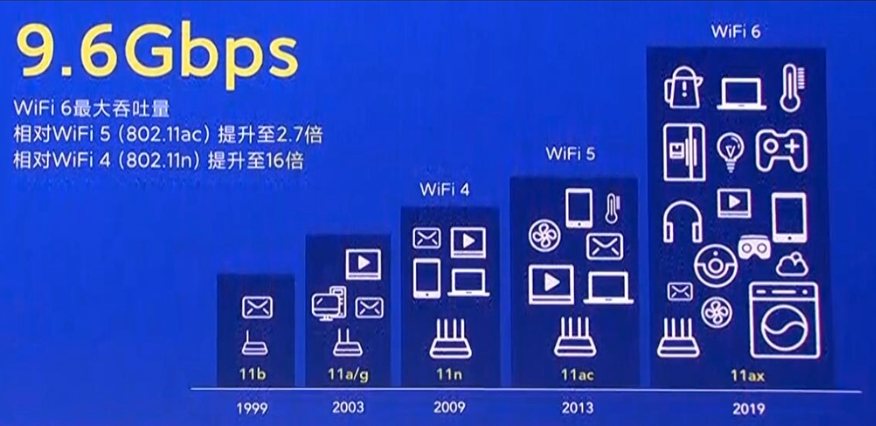
Mi4:无线保真(Wireless Fidelity),是WHFi联盟制造商的商标做为产品的品牌认证,是一个创建于IEE 802.11标准的无线局域网技术,M-E联盟成立于1999年,当时的名称叫做Wireless Ethernet Compatibility Alliance (WECA)。在2002年10月,正式改名为Wi-EiAlliance。

WiFi 6是当前最新的WiEi技术标准,专业称呼为:802.11ax,WiFi6简单来讲就是第六代ME标准的意思,就和第五代移动通信标准——5G、丐帮第六代长老的意思差不多。在WiFi6之前,WiFi的名字并不是什么WiFi5、WiFi 4 这种简单的叫法,而是用一串非常拗口的技术型号来区分,比如WiFi 5 之前就叫802.11ac,WiFi 就叫802.11 a/b/g/n,对于懂行的人来说辨别起来没问题,但对于普通用户来说就是两眼—抓瞎看谁都一样(这就好比俄罗斯大兄弟的人名:尼古拉·阿列克谢耶维奇·奥斯特洛夫斯基,—样难记)
2018年 WiFi 联盟自己也感觉这样叫下去不行,我们得学学别人移动通信协会3G\4G\5G那样整个简单容易记的代号,让消费者们容易区分前代与新代,刺激厂商升级更新换代。所以WiFi 6的名称就诞生了!并且一改还顺便把WIFI4、WIFI5一起名字简化了,现在大家在最新的手机系统中的WiFi 角标就能看到WiFi 4、WiFi 5、WiFi6的标识来区分你连接的是第几代WiFI技术,整的和手机信号是一样一样的。

802.11b - WIFI 1 (1999)
802.11a - WIFI 2 (1999)
802.11g - WIFI 3 (2003)
802.11n - WIFI 4 (2009)
802.11ac - WIFI 5(2014)
802.11ax - WIFI 6(2018)
2.2 组网设备

Hub:集线器;Switch:交换机;Router:路由器
2.2.1 网络线缆和接口

双绞线:有8根线,两两缠在一起,那么就有4组(4对)。
原因:主要为了抵消彼此的电磁干扰。
2.2.1.1 网线标准
上世纪 80 年代初,诞生了最早的网线标准(CAT),这个标准一直沿用至今,主要根据带宽和传输速率来区分,从一类网线CAT1 —— 八类网线CAT8。
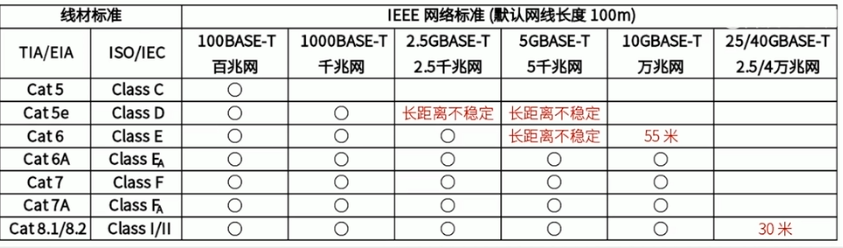
1、一类网线:主要用于传输语音,不同于数据传输主要用于八十年代初之前的电话线缆,已淘汰。
2、二类网线:传输带宽为 1MHz,用于语音传输,最高数据传输速率 4Mbps,常见于使用4Mbps规范令牌传递协议的旧的令牌网(Token Ring),已被淘汰。
3、三类网线:该电缆的传输带宽 16MHz,用于语音传输及最高传输速率为10Mbps的数据传输,主要用于10BASE-T,被 ANSI/TIA-568.C.2 作为最低使用等级。
4、四类网线:该类电缆的传输频率为 20MHz,用于语音传输和最高传输速率16Mbps(指的是16Mbit/s 令牌环)的数据传输,主要用于基于令牌的局域网和 10BASE-T/100BASE-T 。最大网段长为 100m,采用 RI 形式的连接器,未被广泛采用。
5、五类线:可追溯到 1995年,传输带宽为100MHz,可支持10Mbps和100Mbps 传输速率(虽然现实中与理论值有一定的差距),主要用于双绞线以太网(10BASE-T/100BASE-T),目前仍可使用,不过在新网络建设中以及很难看到了。
6、超五类线(目前生产环境中使用最多):标准于 2001 年提出,传输带宽为100MHz,近距离情况下传输速率可以到达1000Mbps,它具有衰减小,串扰少,比五类线增加了近端串音功能和测试要求,所以它也成为当前应用最为广泛的网线,比如山泽基本入门级别的网线就是超五类线。
7、六类线:继CATSe 之后,CAT6标准被提出,传输带宽为 250MHz,最适用于传输速率为1Gbps的应用。改善了在串扰以及回波损耗方面的性能,这一点对于新一代全双工的高速网络应用而言是极为重要的,还有一个特点是在 4个双绞线中间加了十字形的骨架,使得网线十分的结实,不会容易断裂。。
8、超六类线:超六类线是六类线的改进版,发布于2008年,同样是ANSI/TIA-S58C.2 和 ISO/IEC 11801超六类/EA 标准中规定的一种双绞线电缆,主要应用于万兆位网络中,传输频率为 500MHz,最大传输速率可达到 10Gbps,在外部串扰等方面有较大的改善。
9、七类线:该线是ISO/IEC 11801 7类/F级标准中于2002年认可的一种双绞线,它主要为了适应万兆以太网技术的应用和发展,但是它不再是一种非屏蔽双绞线了,而是一种屏蔽双绞线(可以防止电磁干扰),所以它的传输频率至少可达 600MHz,传输速率可达 10Gbps。
10、超七类线:相对于 CAT 7 最大的区别在于,支持的频率带宽提升了1000MHz,在国内而言,七类网线已经有很少地方使用了,超七类就更加没有广泛进入人们的生活,目前使用范围最广的是超五类,六类等网线。
11、八类线CAT8:相关标准由美国通信工业协会(TIA)TR-43委员会在2016年正式发布,支持 2000MHz 带宽,支持40Gbps以太网络,主要应用在数据中心IDC。
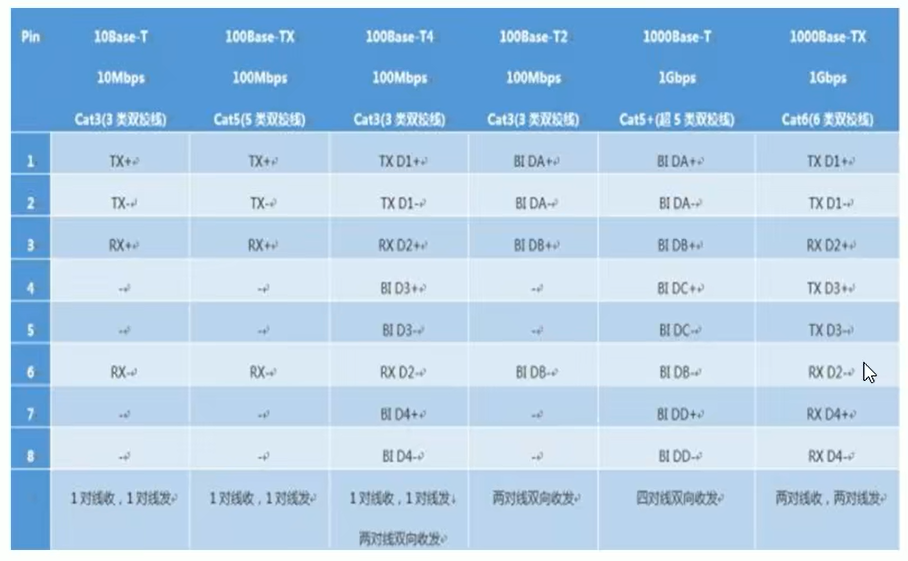
2.2.1.2 网线线序和规范
非屏蔽式双绞线Unshielded Twisted-Pair Cable UTP
T568B 和 T568A

T568-A:白绿,绿,白橙,蓝,白蓝,橙,白棕,棕。
T568-B:白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。(橙蓝绿棕,前面都加白,白一三对调)
RJ-45(水晶头) Connector 和 Jack

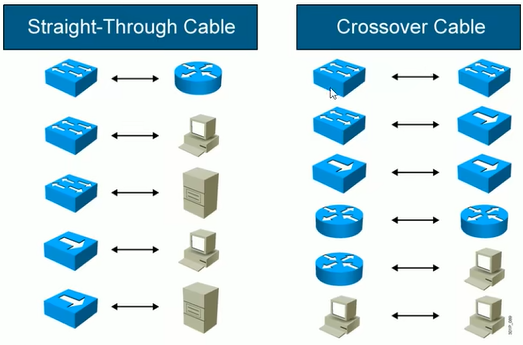
UTP直通线(Straight-Through)
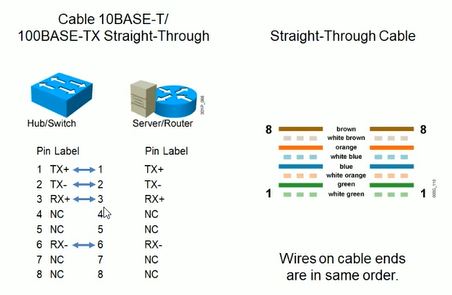
1-2 TX 发生数据
3,6 RX 接收数据
不过目前网卡是智能的,可以判断线序是直连线还是交叉线。以及自动协商速率。
UTP 交叉线(Crossover)
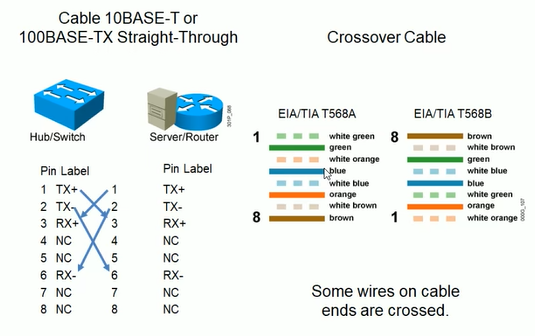
交叉线就是一边按照T568-A的标准,一边按照T568-B的标准。
UTP 直通线和交叉线
双绞线针脚定义
注意:BI=双向数据,RX=接收数据 Receive Data TX=传送数据 Transmit Data
2.2.1.3 光纤和接口Fiber-Optic
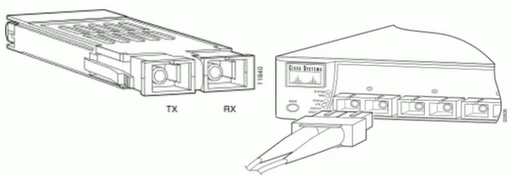
光纤一般是成对出现的,一端是收数据,一段是发数据。
2.2.2 网络适配器


作用
类型
(1)按总线接口类型进行分类
分为 ISA 网卡、PCI 网卡、PCI-X 网卡、PCMCIA 网卡和 USB 网卡等等几种类型
(2)按传输介质接口分类
细同轴电缆的BNC接口网卡、粗同轴电缆的AUI接口网卡、以太网双绞线RJ-45接口网卡、光纤F/O接口网卡、无线卡等等。
(3)按传输速率(带宽)分类
10Mbps网卡、100Mbps以太网卡、10Mbps/100Mbps自适应网卡、1000Mbps千兆以太网卡、10Mbps/100Mbps/1000Mbps自适应网卡,40Gbps自适应网卡(可以自动适应远端网络设备,以确定当前可以使用的速率)等等。多网卡绑定的技术,就可以将传输的速度提升。
2.2.3 中继器和集线器
2.2.3.1 中继器 repeater
它实际上是一种信号再生放大器,可将变弱的信号和有失真的信号进行整形与放大,输出信号比原信号的强度将大大提高。
中继器不解释,不改变收到的数字信息,而只是将其整形放大后再转发出去。工作在物理层。
优点:
缺点:
2.2.3.2 集线器 hub
集线器(Hub)工作在物理层,是中继器的一种形式,是一种几种连接缆线的网络组件,可以认为集线器是一个多端口的中继器,集线器能够提供多端口服务,主要功能是对接收到的信号进行再生整形放大,以扩大网络的传输距离,同时把所有节点集中在以它为中心的节点上。
Hub并不记忆报文是由哪个MAC地址发出,哪个MAC地址在Hub的哪个端口。集线器是共享带宽的,连接改集线器的计算机都是共享该带宽。Hub (工作模式:基于广播机制)默认是广播发生数据。Hub 存在数据传输安全性问题。并且集线器相连的设备即在一个冲突域也在一个广播域中。
Hub 的特点:
2.2.4 网桥Bridge和交换机Switch
2.2.4.1 网桥Bridge

网桥(Bridge)也叫桥接器,是连接两个局域网的一种存储/转发设备,根据MAC地址表对数据帧进行转发,可隔离碰撞域(冲突域)。
网桥将网络的多个网段在数据链路层连接起来,并对网络数据帧进行管理。
网桥的内部结构

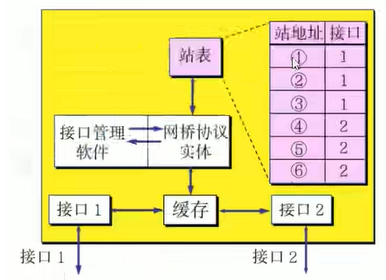
优点:
缺点:
2.2.4.2 交换机Switch

交换机(Switch)是工作在OSI参考模型数据链路层的设备,外表和集线器相似
它通过判断数据帧的目的MAC地址,从而将数据帧从合适端口发送出去
交换机是通过MAC地址的学习和维护更新机制来实现数据帧的转发
以太网交换机是根据接收到的数据帧的(源MAC地址)来学习mac地址表的
交换机可以隔离冲突域,不能隔离广播域。
内部结构:
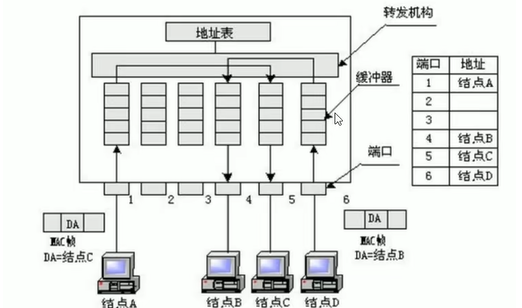
工作原理:
生产环境中可能会出现三层交换机,即交换机具有了路由器的功能。
面试题的时候问:交换机工作在哪一层?答:二层,数据链路层
交换机学习的源MAC地址,所以在MAC地址表中不会出现多播地址和广播地址,也正是因为该原因所以交换机无法隔离广播域。
2.2.4.3 集线器和交换机的比较

2.2.5 路由器 Router
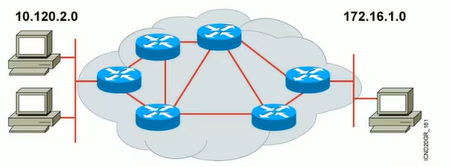
路由:把一个数据包从一个设备发送到不同网络里的另一个设备上去。这些工作依靠路由器来完成,路由器只关心网络的状态和决定网络中最佳路径。路由的实现依靠路由器中的路由表来完成。
为了实现路由,路由器需要做下列事情:

路由器可以起到连接广域网的功能。
家用路由器是集成产品:集成了交换机,路由器,无线AP。
2.3 以太网技术
2.3.1 概述
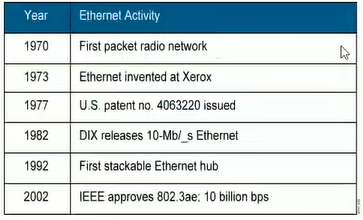
以太网(Ethernet)是一种产生较早并且使用相当广泛的局域网,由美国Xerox(施乐)公司的Palo Alto研究中心(简称PARC)于20世纪70年代初期开始研究并于1975年研制成功。1982 年DIX(第一代以太网技术) 由美国Dec公司,Xerox(施乐)公司,Intel(英特尔)公司研制。
无线局域网技术WLAN:中国标准:WAPI;国际标准:WIFI
2.3.2 以太网MAC帧格式
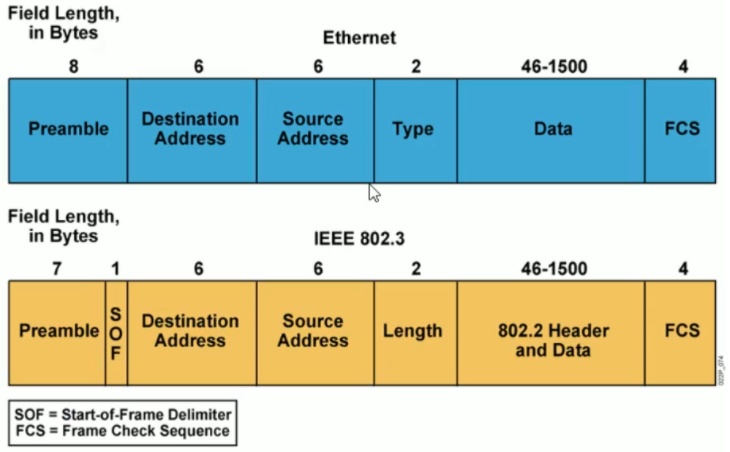
Ethernet II:现如今以太网的标准;
Preamble :前导码,用作数据校验;8个字节;不参加数据处理。用来探测网络是否有故障。
Destination Address:目的MAC地址;6个字节;
Source Address:源MAC地址;6个字节;
Length:长度,2个字节;
Type:指定接收数据的高层协议(网络层使用协议)类型,2个字节;
Data:数据,46字节-1500字节;
FCS(CRC):校验位,4个字节。不参加数据处理。
2.3.3 MAC地址

在局域网中,硬件地址又称为物理地址或者MAC地址(因为这种地址用在MAC帧中)
b0:0=>unicast:单播。1=>multicast:组播
b1:0=>OUI全局唯一标识,由国际组织IEEE分配。1=>本地管理标识
IEEE 802标准为局域网规定了一种 48位的全球地址(一般都简称为“地址”),是局域网中每一台计算机固化在网卡ROM中的地址。
IEEE 的注册管理机构 RA 负责向厂家分配地址字段的前三个字节(即高位 24位)
地址字段中的后三个字节(即低位 24 位)由厂家自行指派,称为扩展标识符,必须保证生产出的适配器没有重复的地址。
物理网卡的MAC是全球唯一。
查看各大厂商MAC地址识别码的网址:http://standards-oui.ieee.org/oui/oui.txt
2.3.4 冲突检测的载波侦听多路访问 CSMA/CD
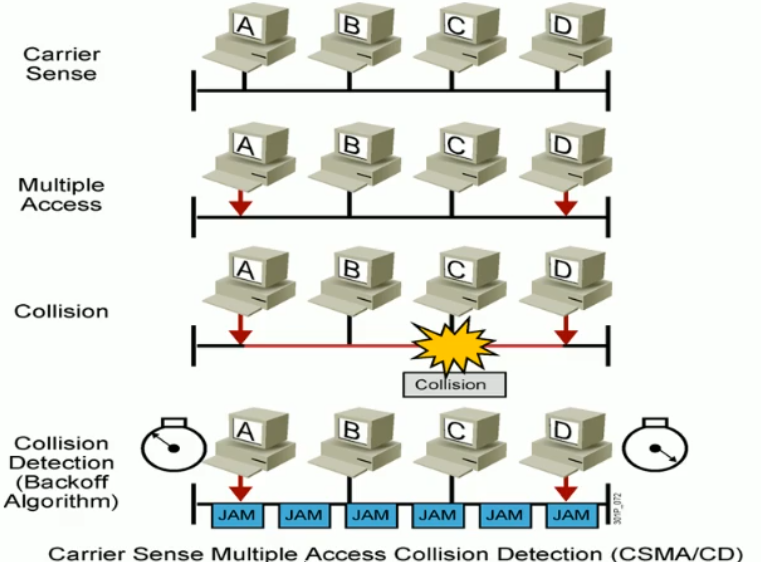
CSMA/CD 工作原理
2.4 虚拟数据网 VLAN
2.4.1 VLAN 原理
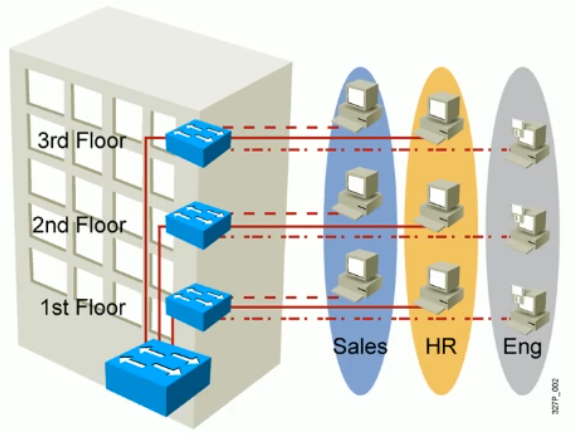
虚拟局域网 VLAN 是由一些局域网网段构成的与物理位置无关的逻辑组;
这些网段具有某些共同的需求。每一个 VLAN 的帧都有一个明确的标识符,指明发送这个帧的工作站是属于哪一个 VLAN 。虚拟局域网其实只是局域网给用户提供的一种服务,而并不是一种新型局域网。所以一个 VLAN 就是一个广播域。
VLAN 技术可以让交换机切割成多个虚拟的广播域。借用的路由器的隔离广播域功能。
优点:
(1)更有效的共享网络资源。如果用交换机构成较大的局域网,大量的广播报文就会使网络性能下降。VLAN 能将广播报文限制在本VLAN 范围内,从而提升了网络的效能。
(2)简化网络管理。当结点物理位置发送变化时,如跨越多个局域网,通过逻辑上配置VLAN即可形成网络设备的逻辑组,无需重新布线和改变IP地址等等。这些逻辑组可以跨越一个或者多个二层交换机
(3)提高网络的数据安全性。一个VLAN中的结点接收不到另一个VLAN中其他结点的帧。
虚拟局域网的实现技术
(1)基于端口的VLAN
(2)基于MAC地址的VLAN
(3)基于协议的VLAN
(4)基于网络地址的VLAN
云计算时代的来临,使得传统的VLAN技术已经不够实用了,VLAN只能划分4096个虚拟网络;VXLAN技术来解决云计算时代的网络隔离问题,VXLAN可以划分1600万个虚拟网络。
参考文献:[ https://baike.baidu.com/item/vxlan/20385445?fr=aladdin ]
2.4.2 IEEE 802.1Q帧结构
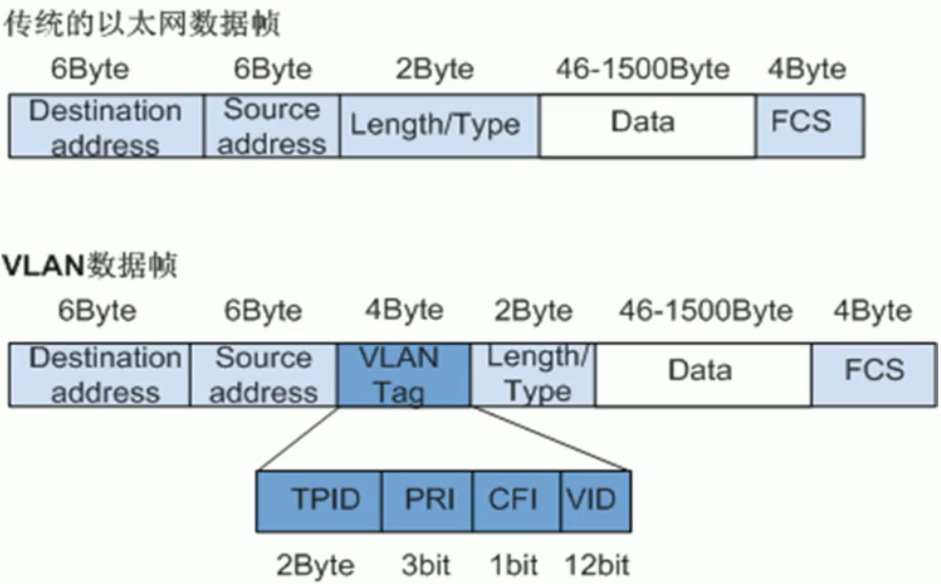
| 字段 | 长度 | 含义 |
|---|---|---|
| Destination address | 6字节 | 目的MAC地址。 |
| Source address | 6字节 | 源MAC地址。 |
| Type | 2字节 | 长度为2字节,表示帧类型。取值为0x8100时表示802.1Q Tag帧。如果不支持802.1Q的设备收到这样的帧,会将其丢弃。 |
| PRI | 3比特 | Priority,长度为3比特,表示帧的优先级,取值范围为0~7,值越大优先级越高。用于当阻塞时,优先发送优先级高的数据包。 |
| 如果设置用户优先级,但是没有VLANID,则VLANID必须设置为0x000。 | ||
| CFI | 1比特 | CFI (Canonical Format Indicator),长度为1比特,表示MAC地址是否是经典格式。CFI为0说明是标准格式,CFI为1表示为非标准格式。用于区分以太网帧、FDDI(Fiber Distributed Digital Interface)帧和令牌环网帧。在以太网中,CFI的值为0。 |
| VID | 12比特 | LAN ID,长度为12比特,表示该帧所属的VLAN。在VRP中,可配置的VLAN ID取值范围为1~4094。0和4095协议中规定为保留的VLAN ID。 |
| 三种类型: |
- Untagged帧:VID 不计
- Priority-tagged帧:VID为 0x000
- VLAN-tagged帧:VID范围0~4095
三个特殊的VID:
- 0x000:设置优先级但无VID
- 0x001:缺省VID
- 0xFFF:预留VID
|
| Length/Type | 2字节 | 指后续数据的字节长度,但不包括CRC检验码。 |
| Data | 42~1500字节 | 负载(可能包含填充位)。 |
| CRC | 4字节 | 用于帧内后续字节差错的循环冗余检验(也称为FCS或帧检验序列)。 |
IEEE 802.1Q 帧结构
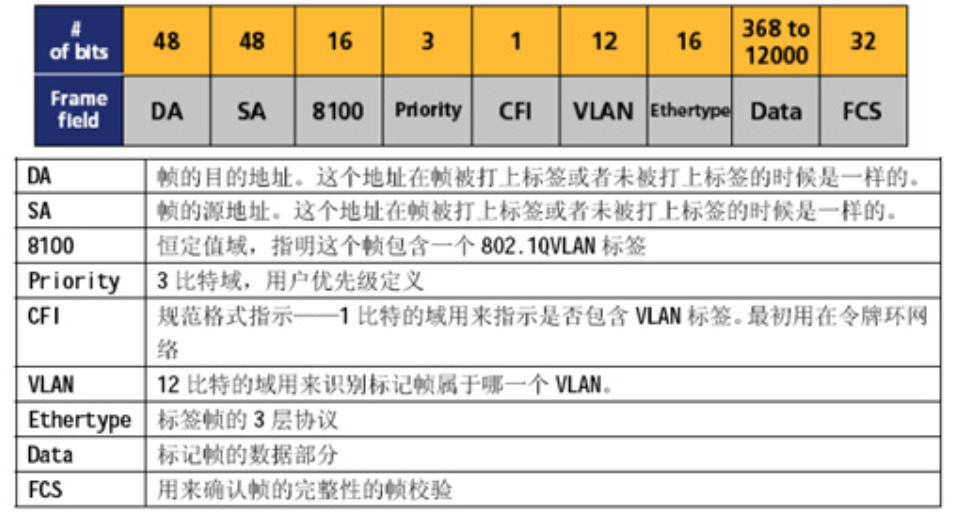
VLAN 标签各字段含义:
TPID:Tag Protocol Identifier(标签协议标识符),2Byte,表示帧类型,取值为 0x8100时表示 IEEE 802.1Q的 VLAN 数据帧。如果不支持802.1Q 的设备收到这样的帧,会将其丢弃,各设备厂商可以自定义该字段的值。当邻居设备将TPID值配置为非0x8100时,为了能够识别这样的报文,实现互通,必须在本设备上修改TPID值,确保和邻居设备的TPID值配置一致。
PRI:Priority,3bit,表示数据帧的802.1P(是IEEE 802.1Q的扩展协议)优先级。取值范围为 0-7,值越大优先级越高。当网络阻塞时,交换机优先发送优先级高的数据帧。
CFI:Canonical Format Indicator(标准格式指示位),1bit 表示MAC地址在不同的传输介质中是否以标准格式进行封装,用于兼容以太网和令牌环网。CFI 取值为 0 表示MAC地址以标准格式进行封装,为1表示以非标准格式封装。在以太网中,CFI 的值为0。
VID:VLAN ID,12bit,表示该数据帧所属的VLAN的编号。VLAN ID取值范围是 0-4095。由于0 和 4095为协议保留取值,所以 VLAN ID 的有效取值范围是 1 - 4094。
2.5 分层的网络架构
网络划分的分层:
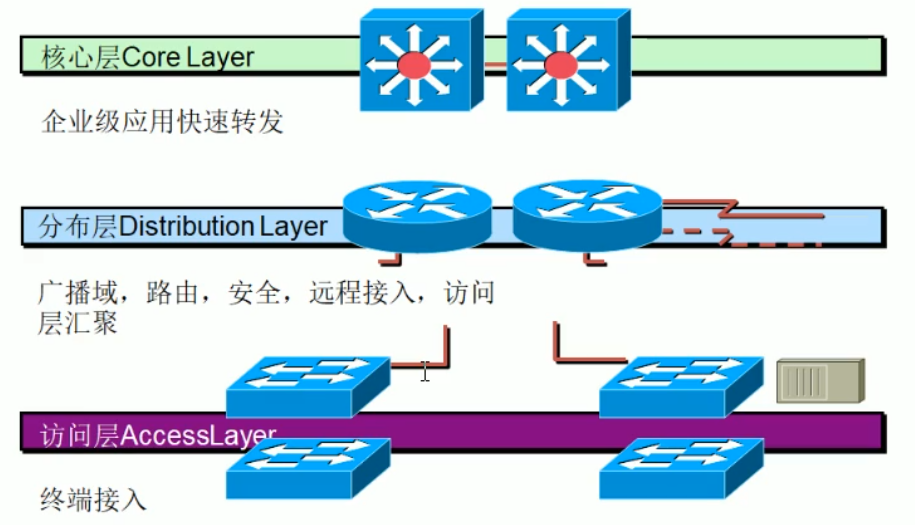
架构一:

架构二:
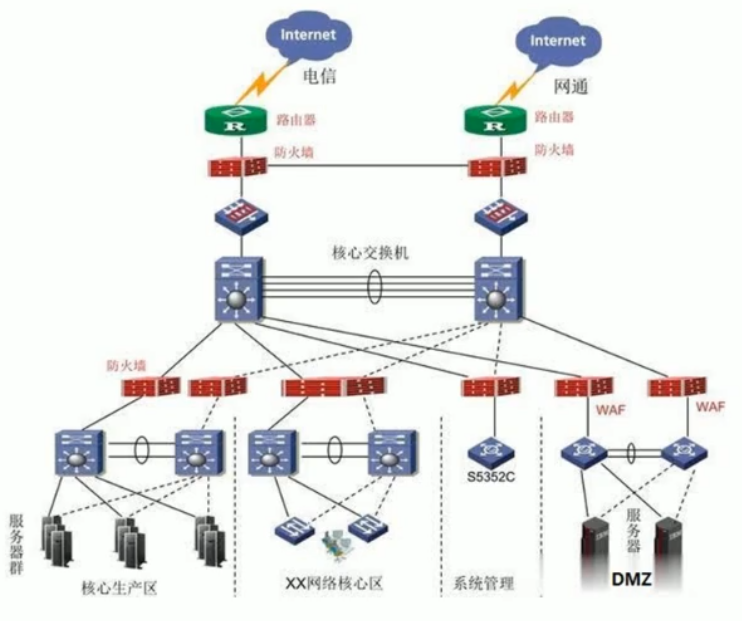
DMZ:非军事化区;主要是存放能够被互联网访问的服务器。
架构三:
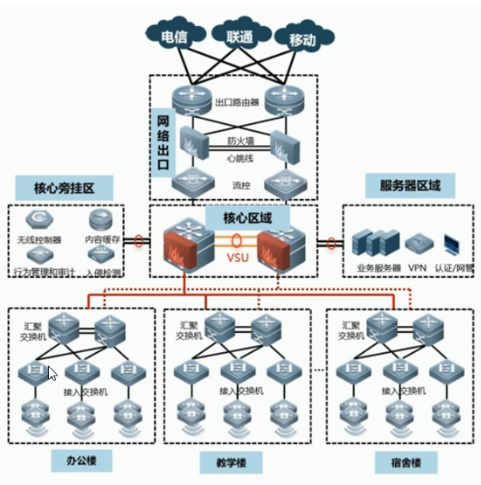
3 TCP/IP 协议栈
3.1 TCP/IP标准
3.1.1 TCP/IP介绍
Transmission Control Protocol / Internet Protocol,传输控制协议/因特网互联协议
TCP/IP 是一个 Protocol Stack 协议栈,包括 TCP、UDP、IP、ICMP、RIP、TELNET、FTP、SMTP、ARP等等许多协议
最早发源于 1969 年美国国防部(缩写 DoD)的因特网的前身 ARPA 网项目,1983年1月1日,TCP/IP取代了旧的的网络控制协议 NCP,成为今天互联网和局域网的基石和标准,由互联网工程任务组负责维护。1969年Unix出生。
国防高级研究计划局DARPA与BBN技术公司、斯坦福大学和伦敦大学学皖签约,在多个硬件平台上开发协议的操作版本。在协议开发过程中,数据包路由层的版本号从版本1进展到版本4,后者于1983年安装在 ARPANET 中。它被称为互联网协议版本4(IPv4)作为协议,仍在互联网使用,连同其目前的继承,互联网协议版本6(IPv6)。
互联网最先普及TCP/IP协议,局域网在 20世纪90年代初使用的普遍的技术是 IPX/SPX。是 Novell 公司的通信协议集。与NetBEUI形成鲜明区别的是IPX/SPX比较庞大,在复杂环境下具有很强的适应性。当微软推出了NT4.0系统适合企业级的服务器产品,采用TCP/IP协议,很快就打败了IPX/SPX(因为在IPX/SPX ←→ TCP/IP 之间需要进行协议的转换网关,实施复杂)。
RFC请求注解 文档:https://www.ietf.org/rfc/rfc1180.html
小知识:Novell 现在拥有全欧洲流行的操作系统SUSE。一直与 微软/红帽 竞争。
3.1.2 TCP/IP分层
共定义了四层,和OSI参考模型的分层有着对应关系
RFC文档:https://www.ietf.org/rfc/rfc1122#section-1.3.3
RFC 官方分为四层:

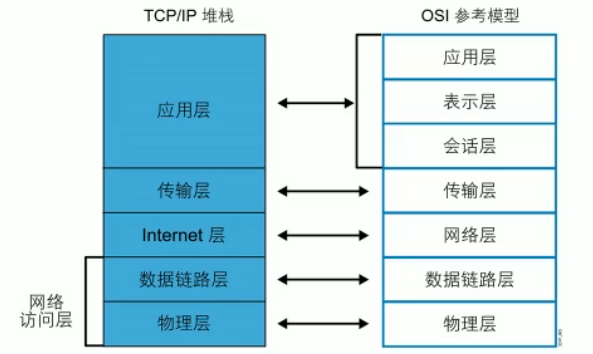
TCP/IP 应用层:

应用层协议:HTTP/HTTPS,FTP/TFTP,Telnet,Redis,MySQL,网络通信协议,NFS,DNS。
3.1.3 TCP/IP通讯过程
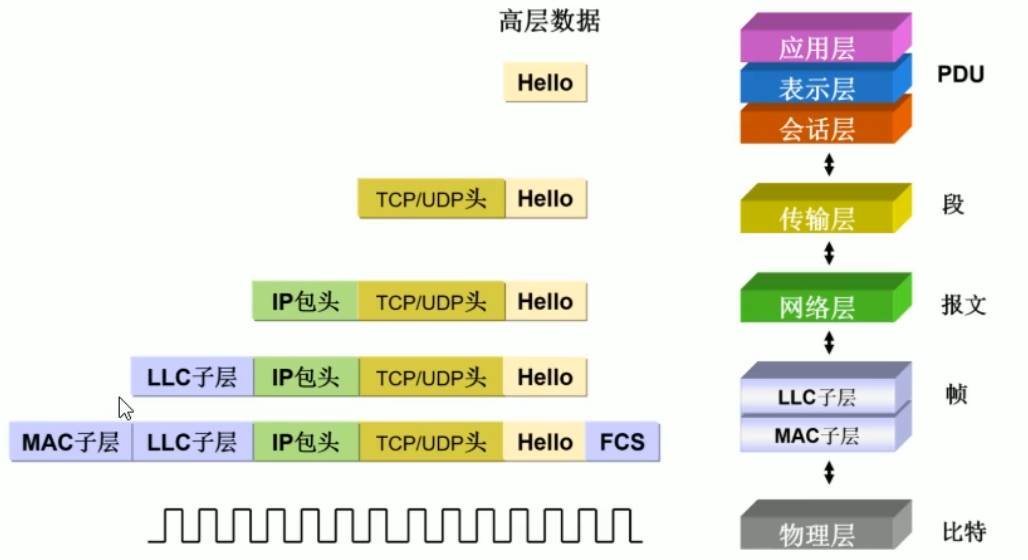
逻辑链路控制(Logical Link Control,LLC)子层和介质访问控制(Media Access Control,MAC)子层。
MAC子层就是目的MAC地址和源MAC地址;LLC子层就是上层协议的类型,只负责对上层的交互,比如上层协议为IP协议,会有一个Type类型。
数据链路层的MAC和LLC子层的区别为:实现不同、依赖体不同、主要功能不同。
一、实现不同
1、MAC子层:MAC子层是由网络接口卡(NIC:网卡)来实现。
2、LLC子层:LLC子层是由传输驱动程序实现的。
二、依赖体不同
1、MAC子层:MAC子层依赖于各自的物理层。
2、LLC子层:LLC子层在IEEE802.2标准中定义,为802标准系列共用。

三、主要功能不同
1、MAC子层:MAC子层的的主要功能为数据帧的封装/卸装,帧的寻址和识别,帧的接收与发送,链路的管理,帧的差错控制。
2、LLC子层:LLC子层的主要功能为传输可靠性保障和控制,数据包的分段与重组,数据包的顺序传输。
3.1.4 TCP/IP 和 OSI模型的比较
3.2 transport 层
传输层功能:实现数据终端到终端的连接,可靠或者非可靠的传输连接。
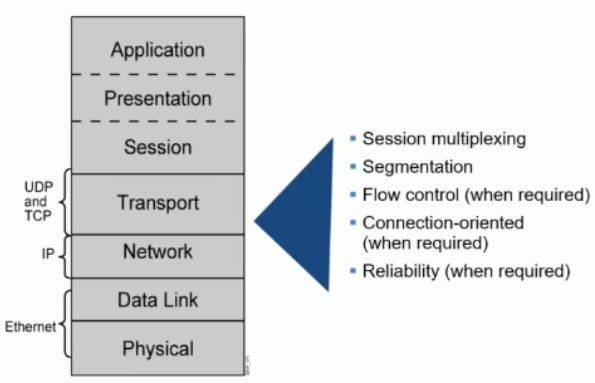
TCP 和 UDP



TCP 提供可靠,UDP 提供高性能。
3.2.1 TCP Transmission Control Protocol 传输控制协议
3.2.1.1 TCP特性
更多关于 TCP 的内核参数,可以参考 man 7 tcp
3.2.1.2 TCP包头

32位 = 4 个字节(1Byte = 8bit),TCP固定20个字节。
TCP 包头字段介绍:
端口号就相当于是应用程序(应用层协议)在计算机中的唯一标识。服务器应用程序的端口号是固定的。端口一旦被分配,就不能冲突,不能再有其他应用服务使用该端口,除非该端口被释放。例如:HTTP的80端口,HTTPS的443端口。
Windows 查看端口
#查看进程信息~ tasklist | finstr “software”
#查看端口~ netstat -no | findstr “process”
TCP 的6个状态标记位:
TCP 包头常见选项:
3.2.1.3 TCP协议PORT
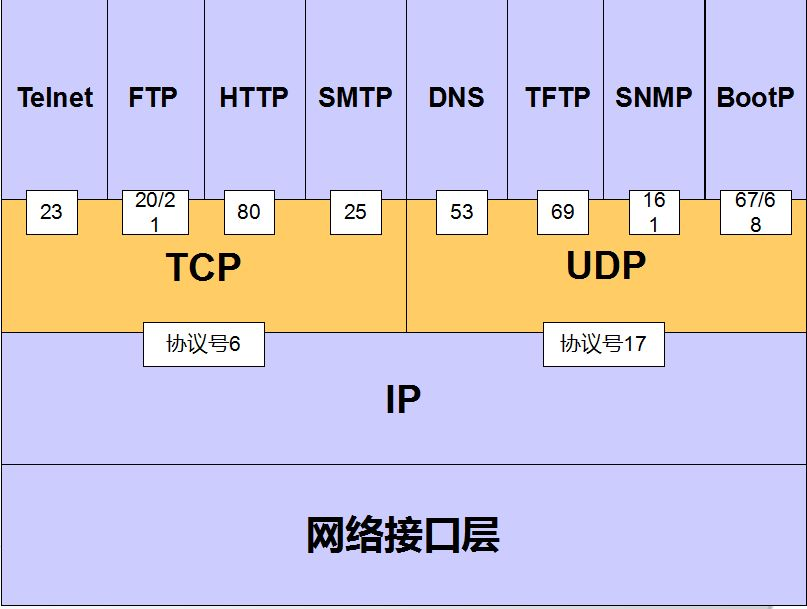
传输层通过port号,确定应用层协议,范围:0-65535
维基百科: [https://en.wikipedia.org/wiki/List of TCP and UDP port numbers](https://en.wikipedia.org/wiki/List of TCP and UDP port numbers)
IANA互联网数字分配机构负责域名,数字资源,协议分配
注意:DNS端口号分为TCP 53 和UDP 53,TCP是用来做区域传送,UDP是用来做DNS解析的。DNS协议主要运行在UDP协议之上。
范例:调整客户端的动态端口范围
#调整客户端的动态端口范围
~# cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
~# echo 20000 62000 > /proc/sys/net/ipv4/ip_local_port_range
~# cat /proc/sys/net/ipv4/ip_local_port_range
20000 62000
# echo "20000 65535" > /proc/sys/net/ipv4/ip_local_port_range
范例:
? ~ yum install -y man-pages
? ~ man 2 socket
#nc可以用来做网络实验
#?nc是netcat的简写,是一个功能强大的网络工具,有着网络界的瑞士军刀美誉。nc命令在linux系统中实际命令是ncat,nc是软连接到ncat。
? ~ yum install -y nc
#服务器端
? ~ ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 128 [::]:22 [::]:*
? ~ nc -l 22
Ncat: bind to :::22: Address already in use. QUITTING.
? ~ nc -l 9527
I am kubsphere-docker
I am kubsphere-docker
#客户端
~# nc 139.198.105.99 9527
I am kubsphere-docker
I am kubsphere-docker
#再开一个连接失败
~# nc 139.198.105.99 9527
Ncat: Connection refused.
? ~ ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 10.150.22.47:9527 120.229.46.204:21728
#服务器开启UDP的端口
? ~ nc -l 7000 -u
#客户端连接
~# nc 139.198.105.99 7000 -u
? ~ ss -ntu
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 10.150.22.47:7000 120.229.46.204:22207
? ~ nc -l 1023
Ncat: bind to :::1023: Permission denied. QUITTING.
范例:找到端口冲突的应用程序
? ~ nc -l 22
Ncat: bind to :::22: Address already in use. QUITTING.
? ~ ss -ntlp | grep 22
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:* users:(("sshd",pid=727,fd=3))
LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=727,fd=4))
? ~ lsof -i :22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 727 root 3u IPv4 17393 0t0 TCP *:ssh (LISTEN)
sshd 727 root 4u IPv6 17395 0t0 TCP *:ssh (LISTEN)
sshd 4940 zhongzhiwei 3u IPv4 29803268 0t0 TCP kubesphere-docker.io:ssh->120.229.46.204:22405 (ESTABLISHED)
范例:判断端口是否正在打开
# 代表端口已经被占用
~ < /dev/tcp/127.0.0.1/80
~ echo $?
0
# 代表端口访问不到,没有被占用
~ < /dev/tcp/127.0.0.1/8080
bash: connect: Connection refused
bash: /dev/tcp/127.0.0.1/8080: Connection refused
~ echo $?
1
范例:利用重定向实现上网
~ exec 8<>/dev/tcp/www.baidu.com/80
~ ls -l /proc/$$/fd
total 0
lrwx------ 1 root root 64 Jun 7 22:48 0 -> /dev/pts/4
lrwx------ 1 root root 64 Jun 7 22:48 1 -> /dev/pts/4
lrwx------ 1 root root 64 Jun 7 22:48 2 -> /dev/pts/4
lrwx------ 1 root root 64 Jun 7 22:48 255 -> /dev/pts/4
lrwx------ 1 root root 64 Jun 7 22:55 8 -> socket:[29844110]
~ echo -e 'GET / HTTP/1.1\n' >& 8
~ cat <& 8
HTTP/1.1 200 OK
范例:反弹shell实现远程控制
面试题:怎么查看某个端口给哪个应用程序使用
~ ss -ntlp
~ netstat -antp
#格式 lsof -i :[端口]
~ lsof -i :2222
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nc 119407 root 3u IPv6 350112 0t0 TCP *:EtherNet/IP-1 (LISTEN)
nc 119407 root 4u IPv4 350113 0t0 TCP *:EtherNet/IP-1 (LISTEN)
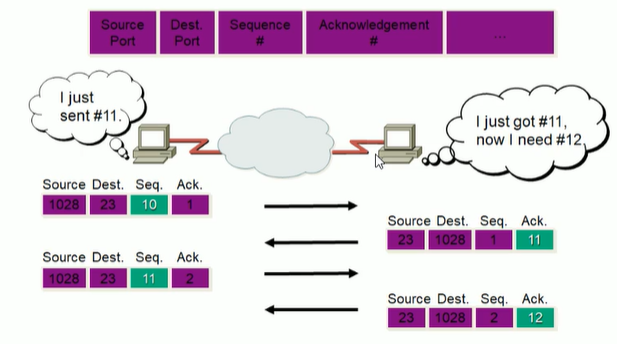
TCP端口号通信过程

TCP序列和确认号
TCP确认和固定窗口
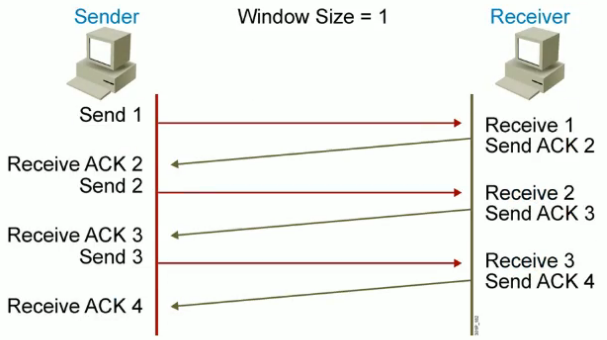
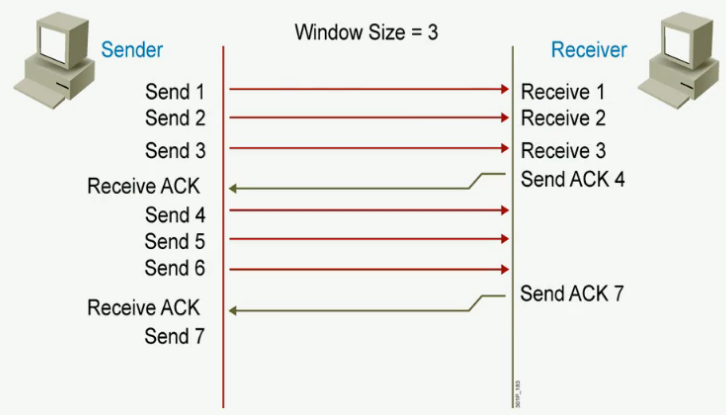
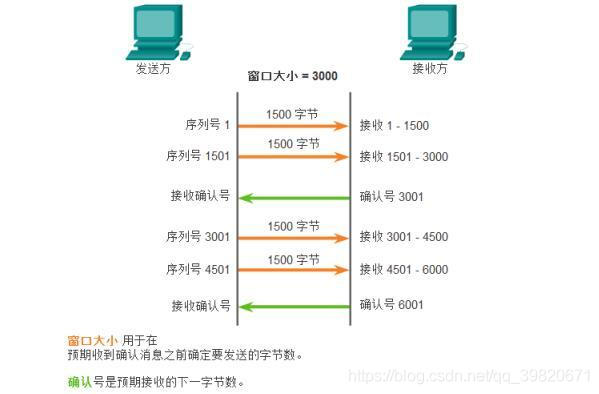
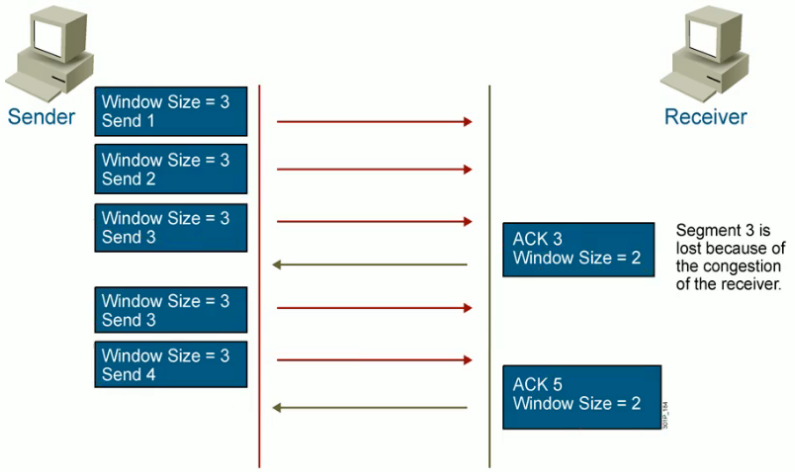
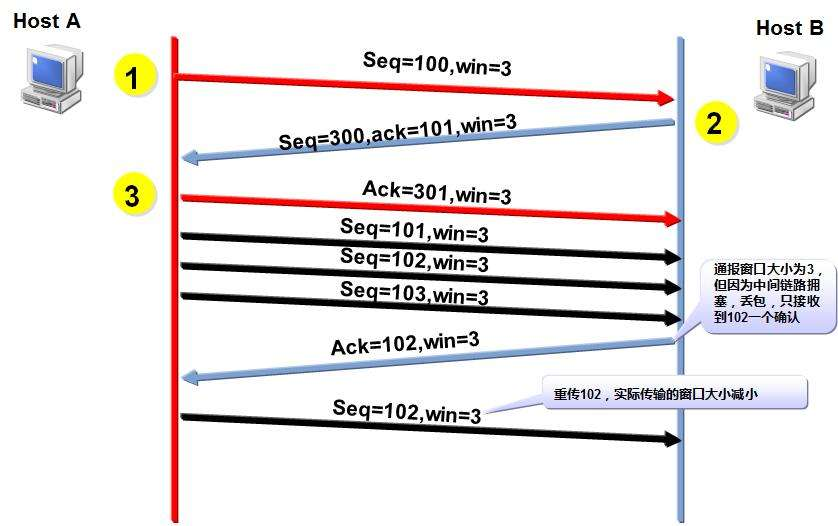
TCP滑动窗口
3.2.1.4 三次握手和四次挥手
TCP 协议是个可靠的协议,可靠不仅是体现在发送数据报文有序号和确认号,还有建立连接的过程,TCP在双方传输数据之前要先确保链路安全可靠,通过标记位来实现。
TCP三次握手详解
TCP四次挥手详解
建立连接
TCP三次握手
TCP 三次握手是由TCP协议栈自动完成实现的,不需要应用程序参与。
面试题:为什么需要三次握手?
计算机的通信是需要有去有回才是完整的通信。防火墙是会防外网访问内网。

第一次握手:客户端给服务器发送一个同步报文段SYN,并指定客户端的初始序列号ISN,此时客户端处于SYN_SENT状态。
首部的同步位SYN = 1(SYN只是一个比特位,0表示不是SYN,1表示是SYN),初始序列号 seq = m。
SYN = 1的报文段不能携带任何的数据,但要指定序号。
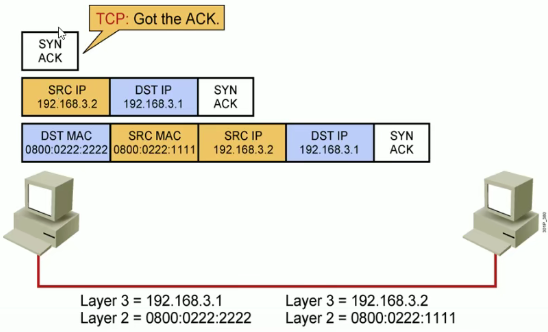
第二次握手:服务器接收到来自客户端的同步报文段SYN后,会以自己的SYN报文作为应答,并且也指定了自己的初始序列号ISN。同时会把客户端的 seq + 1 确认序列号ack的值,表示自己已经收到了客户端的同步报文段SYN,此时服务器处于SYN_RCVD的状态。
确认报文段中SYN = 1,ACK = 1(ACK也只是一个比特位,0表示不是ACK,1表示是ACK),确认序列号ack = m+1,初始序列号seq = n。
第三次握手:客户端收到来自服务器的同步报文段SYN之后,会发送一个确认报文段ACK,以服务器的 seq+1作为ack的值 ,表明自己已经收到来自服务器的同步报文段SYN。客户端进入ESTABLISHED状态,服务器确认报文段ACK之后,也会进入ESTABLISHED状态。
确认报文段中,ACK = 1,确认序列号 ack = n+1,序列号 seq = m+1。
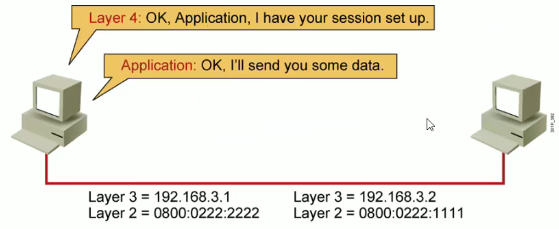
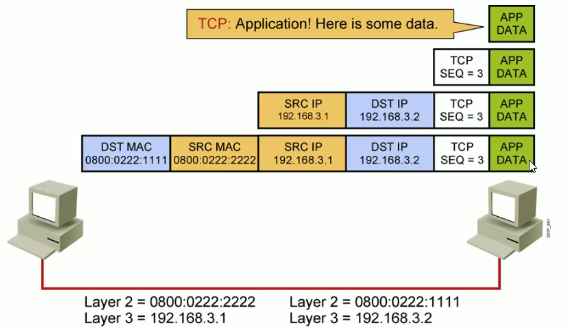
双方已经建立起连接,可以正常的发送数据。
范例:三次握手抓包
# 使用ssh连接即可
ssh root@10.0.0.101
#wireshark抓包分析
(ip.src == 10.0.0.101 and ip.dst == 10.0.0.102) || (ip.dst == 10.0.0.101 and ip.src == 10.0.0.102)
tcpdump -i eth0 -nn -e

# 查看TCP的状态机
netstat -auntlp
ss -tunalp
TCP四次挥手
MSL:Maximum Segment Lifetime
TCP挥手需要视情况而定,有可能是三次或者四次,甚至异常情况下可能就没有挥手的阶段,例如断网,服务器关闭等。

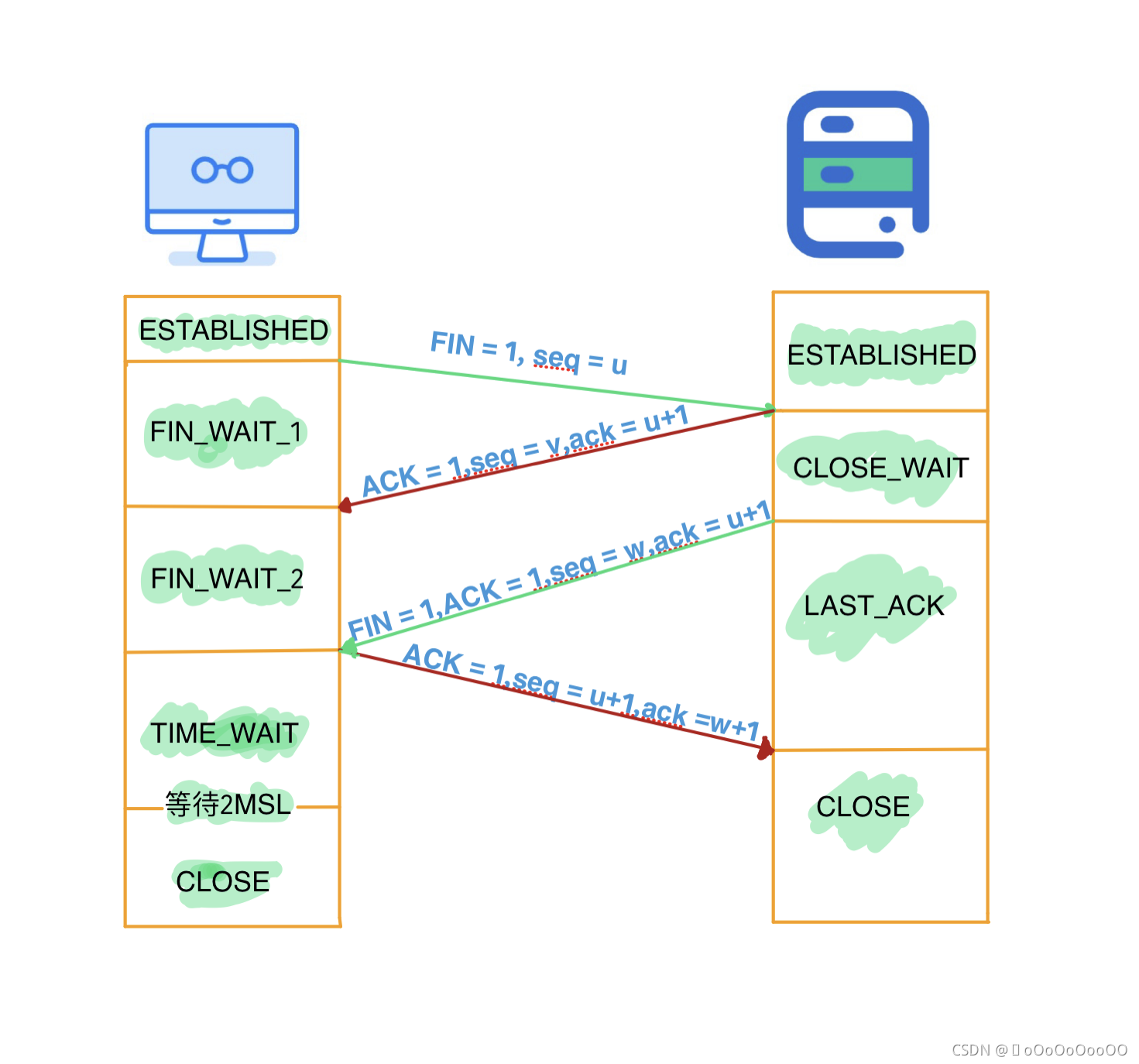
在断开连接之前客户端和服务器都处于ESTABLISHED状态,双方都可以主动断开连接,以客户端主动断开连接为优。
第一次挥手:客户端打算断开连接,向服务器发送FIN报文(FIN标记位被设置为1,1表示为FIN,0表示不是),FIN报文中会指定一个序列号,之后客户端进入FIN_WAIT_1状态。
也就是客户端发出连接释放报文段(FIN报文),指定序列号seq = u,主动关闭TCP连接,等待服务器的确认。
第二次挥手:服务器收到连接释放报文段(FIN报文)后,就向客户端发送ACK应答报文,以客户端的FIN报文的序列号 seq+1 作为ACK应答报文段的确认序列号ack = seq+1 = u + 1。
接着服务器进入CLOSE_WAIT(等待关闭)状态,此时的TCP处于半关闭状态(下面会说什么是半关闭状态),客户端到服务器的连接释放。客户端收到来自服务器的ACK应答报文段后,进入FIN_WAIT_2状态。
第三次握手:服务器也打算断开连接,向客户端发送连接释放(FIN)报文段,之后服务器进入LASK_ACK(最后确认)状态,等待客户端的确认。
服务器的连接释放(FIN)报文段的FIN=1,ACK=1,序列号seq=m,确认序列号ack=u+1。
第四次握手:客户端收到来自服务器的连接释放(FIN)报文段后,会向服务器发送一个ACK应答报文段,以连接释放(FIN)报文段的确认序号 ack 作为ACK应答报文段的序列号 seq,以连接释放(FIN)报文段的序列号 seq+1作为确认序号ack。
之后客户端进入TIME_WAIT(时间等待)状态,服务器收到ACK应答报文段后,服务器就进入CLOSE(关闭)状态,到此服务器的连接已经完成关闭。
客户端处于TIME_WAIT状态时,此时的TCP还未释放掉,需要等待2MSL(MSL:最大分段生存期 或 报文最大生存时间)后,客户端才进入CLOSE状态。
为什么挥手需要四次?
这是由于TCP的半关闭(half-close)造成的。半关闭是指:TCP提供了连接的一方在结束它的发送后还能接受来自另一端数据的能力。通俗来说,就是不能发送数据,但是还可以接受数据。
TCP不允许连接处于半打开状态时,就单向传输数据,因此完成三次握手后才可以传输数据(第三握手可以携带数据)。
当连接处于半关闭状态时,TCP是允许单向传输数据的,也就是说服务器此时仍然可以向客户端发送数据,等服务器不再发送数据时,才会发送FIN报文段,同意现在关闭连接。
这一特性是由于TCP双向通道互相独立所导致的,也使得关闭连接必须经过四次握手。
可能有些人会有疑惑:为什么中间的ACK和FIN不可以像三次握手那样合为一个报文段呢?
在socket网络编程中,执行close()方法会触发内核发送FIN报文。什么时候调用close()方法,这是由用户态决定的,假如服务器仍有大量数据等待处理,那么服务器会等数据处理完后,才调用close()方法,这个时间可能会很久,而ACK报文则是由系统内核来完成的,这个过程会很快。所以中间的ACK和FIN不能合为一个包。
为什么TIME_WAIT等待的时间是2MSL?
MSL(Maximum Segment LifeTime)是报文最大生成时间,它是任何报文在网络上存在的最长时间,超过这个时间的报文将被丢弃。
因为TCP协议是基于IP协议(位于IP协议的上一层),IP数据报中有限制其生存时间的TTL字段,是IP数据报可以经过的最大路由器的个数,每经过处理它的路由,TTL就会减一。TTL为 0 时还没有到达目的地的数据报将会被丢弃,同时发送 ICMP 报文通知源主机。
MSL的单位为时间,TTL的单位为跳转数。所以MSL应该大于等于TTL变为0的时间,以确保报文已被丢弃。
TIME_WAIT等待的2MSL时间,可以理解为数据报一来一回所需要的最大时间。
2MSL时间是从客户端接收到FIN后发送ACK开始计时的。如果在这个时间段内,服务器没有收到ACK应答报文段,会重发FIN报文段,如果客户端收到了FIN报文段,那么2MSL的时间将会被重置。如果在2MSL时间段内,没有收到任何数据报,客户端则会进入CLOSE状态。
等待2MSL的意义
- 保证客户端最后发送的ACK能够到达服务器,帮助其正常关闭。
由于这个ACK报文段可能会丢失,使得处于LAST_ACK状态的服务器得不到对已发送FIN报文段的确认,从而会触发超时重传。服务器会重发FIN报文段,客户端能保证在2MSL时间内收到来自服务器的重传FIN报文段,从而客户端重新发送ACK应答报文段,并重置2MSL计数。
假如客户端不等待2MSL就之间进入CLOSE状态,那么服务器会一直处于LAST_ACK状态。
当客户端发起建立SYN报文段请求建立新的连接时,服务端会发送RST报文段给客户端,连接建立的过程就会被终止。
- 防止已失效的连接请求报文段出现在本连接中。
TIME_WAIT等待的2MSL时间,确保本连接内所产生的所有报文段都从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段。
- 由于网络复杂,有可能在服务器数据传输过程中有一些数据包还在传输过程中,并没有到客户端。这样就不至于丢失数据。
TIME_WAIT状态过多有什么危害?
只有主动发起断开请求的一方才会进入TIME_WAIT状态!
- 占用系统资源
- socket的TIME_WAIT状态结束之前,该socket占用的端口号将一直无法释放。如果服务器TIME_WAIT状态过多,占满了所有端口资源,则会导致无法创建新的连接。
如何解决TIME_WAIT状态过多?
最好的办法是尽量让客户端主动断开连接,除非遇到一些异常情况,如客户端协议错误、客户端超时等。
(1)打开系统的TIME_WAIT重用和快速回收。
在Linux系统可以修改以下参数:
1.打开TCP对时间戳的支持,保持服务器与客户端时间同步
net.ipv4.tcp_timestamps=1(默认即为 1)
2.修改net.ipv4.tcp_tw_reuse = 1,允许对处于TIME_WAIT的socket用于建立新的连接
net.ipv4.tcp_tw_reuse = 1 (默认为0)
(2)修改TIME_WAIT连接状态的上限值,超过上限值,处于TIME_WAIT状态的socket将立刻被清除并打印警告信息。
net.ipv4.tcp_max_tw_buckets = 18000,表示系统同时保持处于TIME_WAIT状态的socket的最大数量,默认为18000。
可修改为更小值。
net.ipv4.tcp_max_tw_buckets = 6666
范例:四次挥手抓包
#wireshark抓包分析
(ip.src == 10.0.0.101 and ip.dst == 10.0.0.102) || (ip.dst == 10.0.0.101 and ip.src == 10.0.0.102)
tcpdump -i eth0 -nn -e

范例:三次挥手抓包
#wireshark抓包分析
(ip.src == 10.0.0.101 and ip.dst == 10.0.0.102) || (ip.dst == 10.0.0.101 and ip.src == 10.0.0.102)
tcpdump -i eth0 -nn -e
# 在TCP三次挥手的范例有只访问一次http服务
# 需要关闭机器的防火墙功能或者开启相应的端口
10.0.0.101$ yum install -y httpd && echo "Hello Apache Server" > /var/www/html/index.html && systemctl enable --now httpd
10.0.0.102$ curl 10.0.0.101


范例:MSL最大分段生存期
? ~ sysctl net.ipv4.tcp_fin_timeout
net.ipv4.tcp_fin_timeout = 60
3.2.1.5 有限状态机FSM:Finite State Machine
范例:查看状态机状态
~ ss -ant
~ netstat -antlp
#实验:查看客户端SYN-SENT状态
10.0.0.210~ iptables -A OUTPUT -d 10.0.0.211 -j DROP
#将10.0.0.211数据进行丢弃
10.0.0.210~ iptables -A INPUT -s 10.0.0.211 -j DROP
10.0.0.211~ ssh 10.0.0.210
10.0.0.211~ ss -ant | grep SYN-SENT
SYN-SENT 0 1 10.0.0.211:38966 10.0.0.210:22
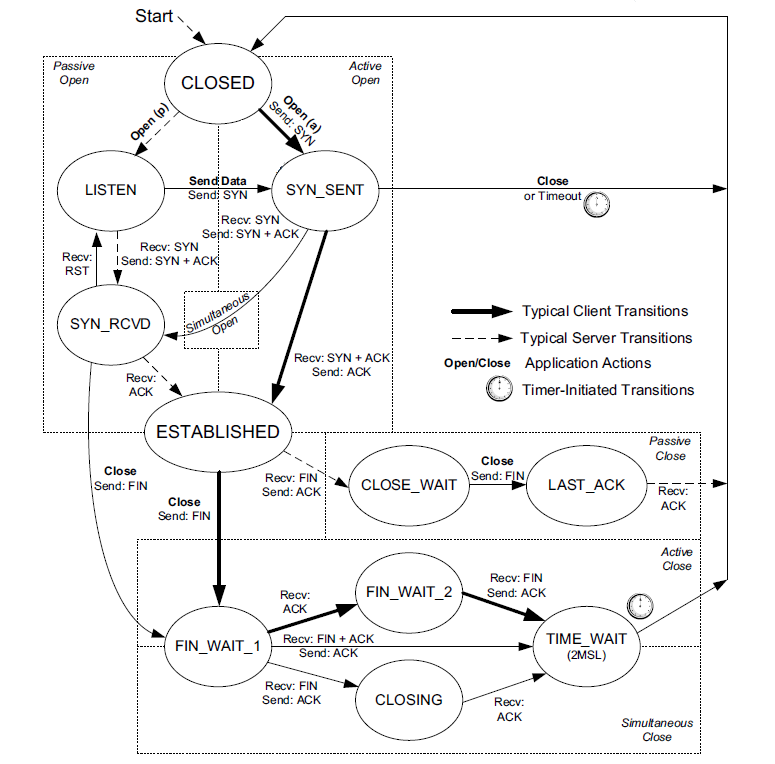
虚线:服务器,实线:客户端

客户端先发送一个FIN给服务端,自己进入FIN_WAIT_1状态,这时等待接收服务端报文,该报文会有三种可能:
1、只收到服务器的ACK,客户端会进入FIN_WAIT_2状态,后续当收到服务端的FIN时,回应发送一个ACK,会进入到TIME_WAIT状态,这个状态会持续2MSL(TCP报文段在网络中的最大生存时间,RFC 1122 标准的建议值时 2min)。客户端等待2MSL,是为了当最后一个ACK丢失时,可以再发送一次。因为服务端再等待超时后会再发送一个FIN给客户端,进而客户端知道ACK已丢失
2、只有服务端的FIN时,回应一个ACK给服务端,进入CLOSING状态,然后接收到服务端的ACK时,进入TIME_WAIT状态
3、同时收到服务端的ACK和FIN,直接进入TIME_WAIT状态
客户端的典型状态转移
客户端通过connect相同调用主动与服务器建立连接connect系统调用首先给服务器发送一个同步报文段,使连接转移到SYN_SENT状态
此后 connect 系统调用可能因为如下两个原因失败返回:
1、如果connect连接的目标端口不存在(未被任何进程监听),或者该端口仍被处于TIME_WAIT状态的连接所占用,则服务器将给客户端发送一个复位报文段,connect 调用失败
2、如果目标端口存在,但是connect在超时时间内未收到服务器的确认报文段,则connect调用失败。
connect调用失败将便连接立刻返回到初始的CLSOED状态。如果客户端成功收到服务器的同步报文段的确认,则connect调用成功返回,连接转移至ESTAB LISHED状态。
当客户端执行主动关闭时,它将向服务器发送一个结束报文段,同时连接进入FIN_WAIT_1状态。若此时客户端收到服务器专门用于确认目的确认报文段,则连接转移至FIN_WAIT_2状态。当客户端处于FIN_WAIT_2状态时,服务器处于CLOSE_WAIT状态,这一对状态是可能发送半关闭的状态。此时如果服务器也关闭连接(发送结束报文段),则客户端将给予确认并TIME_WAIT状态。
客户端从FIN_WAIT_1状态可能直接进入TIME_WAIT状态(不经过FIN_WAIT_2状态),前提是处于FIN_WAIT_1状态的服务器直接收到带确认信息的结束报文段(而不是先收到确认报文段,再收到结束报文段)。
处于FIN_WAIT_2状态的客户端需要等待服务器发送结束报文段,才能转移至TIME_WAIT状态,否则它将一直停留在这个状态。如果不是为了在半关闭状态下继续接收数据,连接长时间的停留在FIN_WAIT_2状态并无益处。连接停留在FIN_WAIT_2状态的情况可能发生在:客户端执行半关闭后,未等服务器关闭连接就强行退出了。此时客户端连接由内核来接管,可称之为孤儿连接(和孤儿进程类似)。
Linux为了孤儿连接长时间存留在内核中,定义了两个内核参数:
~ cat /proc/sys/net/ipv4/tcp_max_orphans
8192
~cat /proc/sys/net/ipv4/tcp_fin_timeout
60
客户机端的三次握手和四次挥手状态转换

服务器端的三次握手和四次挥手状态转换
3.2.1.6 sync半连接和accpet全连接

半连接队列:三次握手的第一次握手发过来以后,对方还没有回来第二次握手和第三次握手,还没有完成整个TCP三次握手的状态,Server 会有一个队列(syns queue),把目前还没有完全建立连接的连接请求放在队列中,队列会有最大值,也就是说同一时间建立半连接的数量是有限的,默认是128。只要超过这个数值,那么就无法进行连接,默认这个数值是有些不够用的。
全连接队列:将三次握手完成以后,会调用 accept queue 队列,用来存放已经建立连接之后的队列,服务器会开启一个进程来处理该队列的请求,这个队列的数值就会下降,若程序比较忙,没有来得及处理该队列的请求,请求又在不断的进来,那么队列就会越来越多,默认是128。accept queue 队列最长累积128个,超过这个数值,那么就无法进行处理,默认这个数值是有些不够用的。(用于高并发)
链接:https://www.jianshu.com/p/6a0fcb1008d6
有两个队列:sync queue(半连接队列);accept queue(全连接队列)
三次握手,两个队列的工作如下:
1.第一步,server收到client的syn后,把相关的信息放到半连接队列中;
2.第二步,回复syn+ack给client;
3.第三步,server 收到 client 的ack,如果这时全连接没满,那么从半连接队列拿出相关信息放入到全连接队列中,否则按 tcp_abort_on_overflow 指示的执行。全连接队列满了并且 tcp_abort_on_overflow=0 的话,server 会过一段时间发送 syn+ack 给 client(重新握手过程的第二步)。
# 未完成连接队列大小(半连接队列),默认值为128,建议调整大小为1024以上
# 需要根据机器的实际性能资源量力而行
~ cat /proc/sys/net/ipv4/tcp_max_syn_backlog
128
echo "1024" > /proc/sys/net/ipv4/tcp_max_syn_backlog
# 完成连接队列大小(全连接队列),默认值为128,建议调整大小为1024以上
# 需要根据机器的实际性能资源量力而行
~ cat /proc/sys/net/core/somaxconn
128
echo "1024" > /proc/sys/net/core/somaxconn
3.2.1.7 TCP超时重传
异常网络状况下(开始出现超时或者丢包),TCP控制数据传输以保证其承认的可靠服务
TCP服务必须能够重传超时时间内未收到确认的TCP报文段。为此,TCP模块为每个TCP报文段都维护一个重传定时器,该定时器在TCP报文段第一次被发送时启动。如果超时时间内未收到接收方的应答,TCP模块将重传TCP报文段并重置定时器。至于下次重传的超时时间如何选择,以及最多执行多少次重传,就是TCP的重传策略
与TCP超时重传相关的两个内核参数:
# 指定在底层IP接管之前TCP最少执行的重传次数,默认值是3
~ cat /proc/sys/net/ipv4/tcp_retries1
3
# 指定连接放弃前TCP最多可以执行的重传次数,默认值15(一般对应13min ~ 30min)
~ cat /proc/sys/net/ipv4/tcp_retries2
15
范例:重传次数显示
ssh root@10.0.0.102
# 登录之后,将10.0.0.102机器的网线拔掉,wireshark抓包显示

3.2.1.8 TCP拥塞控制
网络中的带宽、交换结点中的缓存和处理机等,都是网络的资源。在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可承受的能力,网络的性能就会变坏。此情况称为拥塞。
TCP为提高网络利用率,降低丢包率,并保证网络资源对每条数据流的公平性。即所谓的拥塞控制
TCP拥塞控制的标准文档RFC 5681,其中详细介绍了拥塞控制的四个部分:慢启动(slow start),拥塞避免(congestion avoidance),快速重传(fast retransmit)和快速恢复(fast recovery)。拥塞控制算法在Linux下有多种实现,比如 reno 算法、vegas 算法和 cubic 算法等等。它们或者部分全部实现了上述四个部分。
当前所使用的拥塞控制算法:
~ cat /proc/sys/net/ipv4/tcp_congestion_control
cubic
3.2.1.9 内核TCP参数优化
参考帮助:man tcp
编辑文件 /etc/sysctl.conf ,加入以下内容:然后执行 sysctl -p 让参数生效
tee >> /etc/sysctl.conf <<-'EOF'
# Kernel TCP Optimize BEGIN
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_keepalive_time = 1000
net.ipv4.ip_local_port_range = 2000 65000
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_max_tw_buckets = 36000
# net.ipv4.route_gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
# net.ipv4.tcp_max_reordering = 16384
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
# Kernel TCP Optimize END
EOF
作用说明:
3.2.2 UDP User Datagram Protocol 用户数据报协议
3.2.2.1 UDP特性
3.2.2.2 UDP包头


3.3 Internet 层

3.3.1 Internet Control Message Protocol
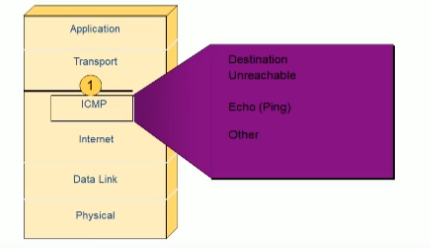
范例:利用 ICMP 协议判断网络状态
# TTL:代表最多允许经过多少个路由器
# 当TTL=128,代表最多可以经过128个路由器,中间隔了一个路由器,就会自动的减一
~ ping -c 2 192.168.237.3
PING 192.168.237.3 (192.168.237.3) 56(84) bytes of data.
64 bytes from 192.168.237.3: icmp_seq=1 ttl=64 time=0.272 ms
64 bytes from 192.168.237.3: icmp_seq=2 ttl=64 time=0.954 ms
#远程主机不可达,可能原因有:
# 1.局域网使用DHCP动态分配IP地址时,DHCP出现故障或者失败
# 2.子网掩码设置错误
# 3.路由表返回错误信息
~ ping -c 2 192.168.237.32
PING 192.168.237.32 (192.168.237.32) 56(84) bytes of data.
From 192.168.237.5 icmp_seq=1 Destination Host Unreachable
From 192.168.237.5 icmp_seq=2 Destination Host Unreachable
#远程主机目标端口不可达,可能原因有:防火墙禁ping等
10.0.0.101~ iptables -t filter -A INPUT -s 10.0.0.102 -p icmp -j REJECT
10.0.0.101~ iptables -vnL
Chain INPUT (policy ACCEPT 53 packets, 2936 bytes)
pkts bytes target prot opt in out source destination
0 0 REJECT icmp -- * * 10.0.0.102 0.0.0.0/0 reject-with icmp-port-unreachable
10.0.0.102~ ping -c 2 10.0.0.101
PING 10.0.0.101 (10.0.0.101) 56(84) bytes of data.
From 10.0.0.101 icmp_seq=1 Destination Port Unreachable
From 10.0.0.101 icmp_seq=2 Destination Port Unreachable
#域名解析有问题
~ ping www.kubesphere.org
ping: www.kubesphere.org: Name or service not known
#指定数据包的大小,数据帧中数据部分大小在46-1500字节
~ ping -s 65508 192.168.237.5
Error: packet size 65508 is too large. Maximum is 65507
#-f (flood)实现网络攻击:尽CPU所能去发送请求。
#这种攻击方式被称为DOS攻击,将服务端的流量打满,使其无法对外提供服务。
~ ping -s 65507 -f 192.168.237.5
PING 192.168.237.5 (192.168.237.5) 65507(65535) bytes of data.
.^C
--- 192.168.237.5 ping statistics ---
117 packets transmitted, 116 received, 0.854701% packet loss, time 809ms
rtt min/avg/max/mdev = 1.333/6.720/13.396/1.843 ms, ipg/ewma 6.970/6.696 ms
# 查看网卡的带宽
~ ifconfig -s eth0
~ watch -n 1 ifconfig s eth0
ping 中 TTL 的介绍:
1,TTL是指定数据报被路由器丢弃之前允许通过的网段数量,如果同一服务器不同的IP,你ping这些 IP得到的TTL越高(经过转发的路由器少),延时越小,说明直连该 IP 会更快。
2,TTL 是由发送主机设置的,以防止数据包不断在 IP 互联网络上永不终止地循环。转发 IP 数据包时,要求路由器至少将 TTL 减小 1。
3, 使用PING时涉及到的 ICMP 报文类型,一个为ICMP请求回显(ICMP Echo Request),一个为ICMP回显应答(ICMP Echo Reply),TTL 字段值可以帮助我们识别操作系统类型。
4,TTL 会有个初始值(管理员可以进行修改),根据操作系统的不同会有所不同,Linux 系统一般是 64,Windows 系统则是 128。
3.3.2 Address Resolution Protocol
3.3.2.1 ARP
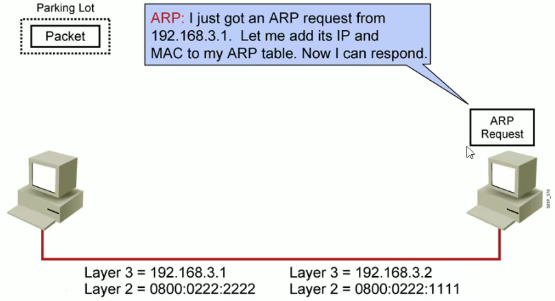
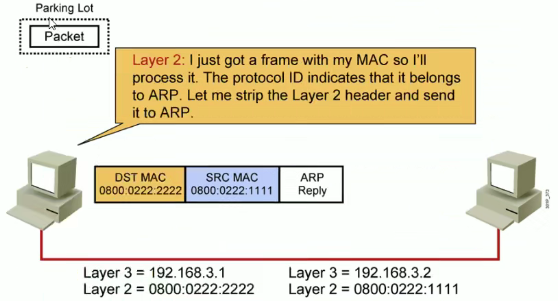
ARP 地址解析协议由互联网工程任务(IETF)在1982年11月发布的RFC 826中描述指定的,是根据IP地址获取物理地址的一个TCP/IP协议。通过IP地址解析成MAC地址。使用的机制就是广播实现。
主机发送信息时包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本地ARP缓存中保留一定时间,下次请求时直接查询ARP缓存以节约资源。地址解析协议是建立在网络中各个主机互相信任的基础之上,局域网上的主机可以自主发送ARP应答消息,其他主机收到应答消息时不会检测该报文的真实性就会将其记入主机ARP缓存中。
同网段的ARP

跨网段的ARP

在 ping 之后会有 arp 的过程。ARP 协议没有确认的机制,会有恶意冒充其他的主机的可能性。
范例:ARP表
~ ip neigh
192.168.237.2 dev eth0 lladdr 00:50:56:ff:1c:e1 STALE
192.168.237.254 dev eth1 lladdr 00:50:56:fa:63:f0 STALE
192.168.237.1 dev eth0 lladdr 00:50:56:c0:00:08 REACHABLE
192.168.237.254 dev eth0 lladdr 00:50:56:fa:63:f0 STALE
192.168.237.3 dev eth0 lladdr 00:0c:29:39:b1:32 STALE
192.168.237.32 dev eth0 FAILED
~ arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.237.5 ether 00:0c:29:fb:26:f9 C ens33
192.168.237.1 ether 00:50:56:c0:00:08 C ens33
192.168.237.2 ether 00:50:56:ff:1c:e1 C ens33
~ ping -c1 -W1 192.168.237.10
PING 192.168.237.10 (192.168.237.10) 56(84) bytes of data.
64 bytes from 192.168.237.10: icmp_seq=1 ttl=64 time=0.502 ms
--- 192.168.237.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.502/0.502/0.502/0.000 ms
#可以使用tcpdump抓包ARP协议
~ tcpdump -i ens33 arp -nn
~ arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.237.5 ether 00:0c:29:fb:26:f9 C ens33
192.168.237.1 ether 00:50:56:c0:00:08 C ens33
192.168.237.10 ether 00:0c:29:49:e4:84 C ens33
192.168.237.2 ether 00:50:56:ff:1c:e1 C ens33
#默认网关
范例:ARP静态绑定可以防止ARP欺骗
? ~ arp -s 10.0.0.160 00:50:56:2d:4b:ce
? ~ arp -n
Address HWtype HWaddress Flags Mask Iface
10.0.0.160 ether 00:50:56:2d:4b:ce CM eth0
......
# 删除ARP条目
? ~ arp -d 10.0.0.160
范例:kali 系统实现ARP欺骗上网流量劫持
Kali 系统就是带有大量的黑客工具的Linux系统。Debian 系列的系统。
阿里云 Kali 镜像下载:https://developer.aliyun.com/mirror/kali
Kali 安装源(Kali-images):https://developer.aliyun.com/mirror/kali-images
#启动路由转发功能
echo 1 > /proc/sys/net/ipv4/ip_forward
#安装包
apt-get install dsniff
#欺骗目标主机,本机是网关
arpspoof -i eth0 -t <被劫持的目标主机IP> <网关IP>
#欺骗网关,本机是目标主机
arpspoof -i eth0 -t <网关IP> <被劫持的目标主机IP>
ARP 跨网段通信:
A - (1)Router(2) - B
前提条件:A 已经知道 B的IP地址
(1)首先A 会判断和 B 是否是同一个网段,发现不再同一个网段
(2)A 会发送ARP广播,获取 Router(1) 接口的MAC地址【Router 其实为A和B的网关】,ARP广播会交由Router进行转发。
(3)Router(2) 将ARP请求发送到 B,获取B的MAC地址。
有几个网段就做几次ARP广播,从而实现ARP跨网段通信。
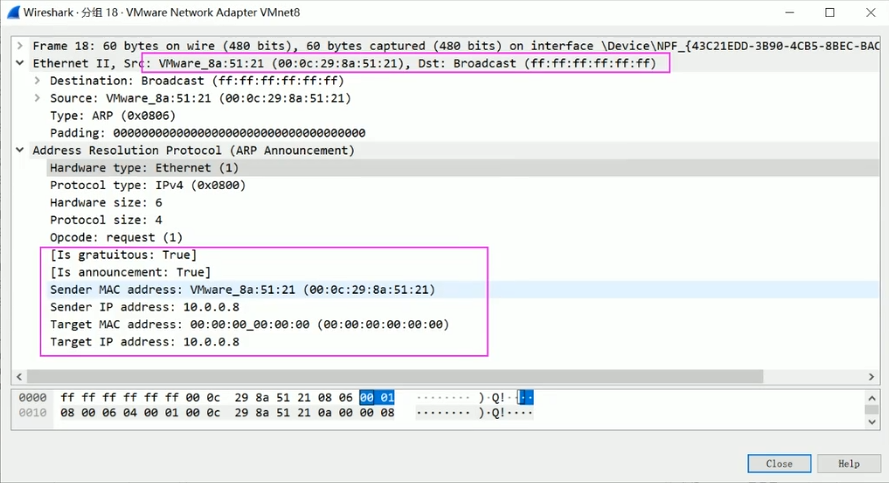
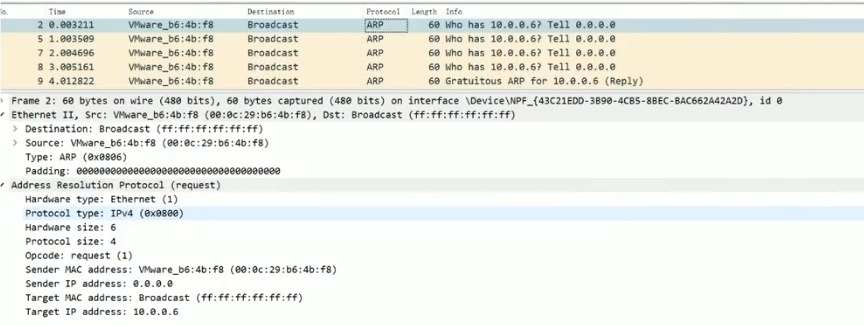
3.3.2.2 Gratuitous ARP
Gratuitous ARP也称为免费 ARP,无敌ARP,Gratuitous ARP不同于一般的ARP需求,它并非期待得到 ip 对应的 mac 地址,而是当主机启动的时候,将发送一个Gratuitous ARP请求(默认发送三次Gratuitous ARP),即请求自己的ip地址的mac地址。
免费ARP可以由两个方面的作用:
范例:抓取CentOS 8重启过程的ARP信息

范例:抓取CentOS 6重启过程的ARP信息

0.0.0.0 就是系统刚启动还没有获取到地址,只有当10.0.0.6的地址没有机器使用,系统才会继承该IP地址。
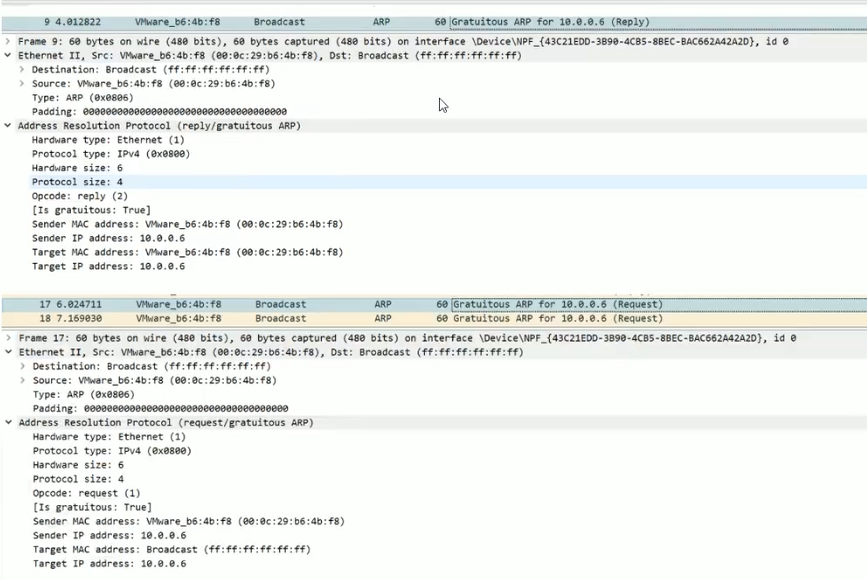
3.3.3 Reverse Address Resolution Protocol
RARP 即将MAC地址转换为IP地址
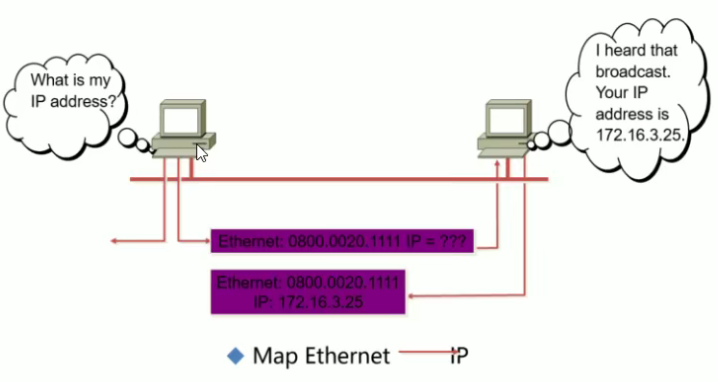
反向地址转换协议(RARP:Reverse Address Resolution Protocol) 允许局域网的物理机器从网关服务器的 ARP 表或者缓存上请求其 IP 地址。网络管理员在局域网网关路由器里创建一个表以映射物理地址(MAC)和与其对应的 IP 地址。当设置一台新的机器时,其 RARP 客户机程序需要向路由器上的 RARP 服务器请求相应的 IP 地址。
应用场景:网吧的无盘工作站。网络中会有MAC地址与IP地址的对应表,当主机的MAC地址发送请求IP地址,就会根据该对应表获取IP地址
3.3.4 Internet 协议
3.3.4.1 Internet 协议特征
3.3.4.2 IP PDU包头
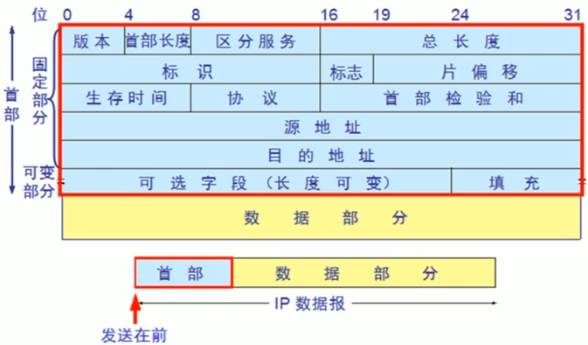
IP 头部固定是 20 个字节。IP地址其实就是一个二进制数。
IP PDU抱头格式
# linux 查看TTL值
~ cat /proc/sys/net/ipv4/ip_default_ttl
64
范例:发现IP冲突的主机
#sudo arping IPAddr
#sudo arping -c [count] IPAddr
~ arping 10.0.0.100
ARPING 10.0.0.100 from 10.0.0.8 eth0
Unicast reply from 10.0.0.100[00:0C:29:63:8B:AC] 0.908ms
Unicast reply from 10.0.0.100[00:0C:29:63:8B:AC] 0.833ms
范例:禁用IPv6
#默认启动ipv6
? ~ ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.160 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::ef92:bc30:7ce0:bef2 prefixlen 64 scopeid 0x20<link>
ether 00:50:56:2d:4b:ce txqueuelen 1000 (Ethernet)
RX packets 237844 bytes 155371234 (148.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 291679 bytes 143477220 (136.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#修改内核配置
? ~ vim /etc/sysctl.conf
#加下面两行
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
? ~ sysctl -p
#查看IP验证
? ~ ifconfig ens33
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.160 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:50:56:2d:4b:ce txqueuelen 1000 (Ethernet)
RX packets 238566 bytes 155429296 (148.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 292678 bytes 143590240 (136.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#注意:禁用ipv6可能会影响一些服务的启动,如:ssh,postfix,mysql等
? ~ vim /etc/ssh/sshd_config
#AddressFamily any #此行修改为以下的内容
AddressFamily inet
? ~ vim /etc/postfix/main.cf
#inet_interfaces = localhost #此行修改为以下的内容
inet_interfaces = 127.0.0.1
? ~ ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
协议域
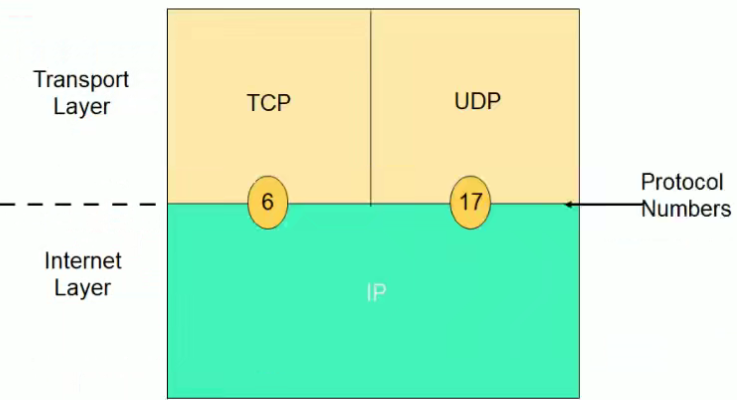
3.4 主机到主机的包传递完整过程
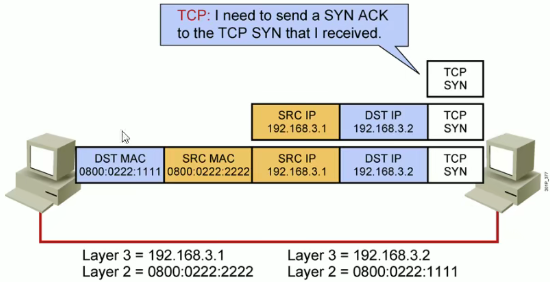
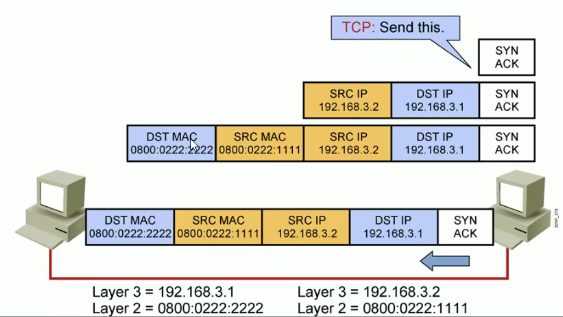
主机到主机的包传递完整大致过程:
(1)路由选择
(2)ARP 地址解析协议
(3)TCP 三次握手
(4)正常数据通信
应用程序使用TCP还是UDP,是由开发程序员决定的。
网络的故障排查:路由,ARP,TCP建立连接,数据传输等。




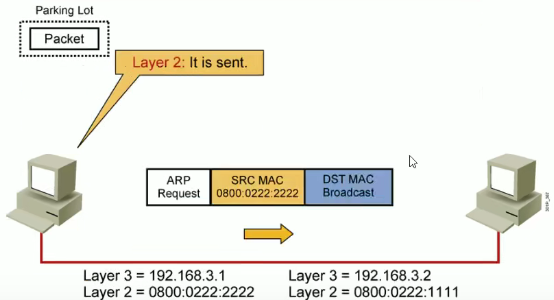









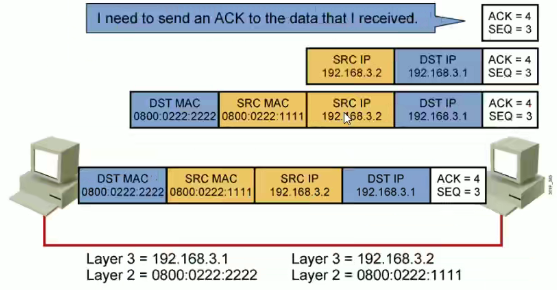
3.5 IP地址
MAC 地址是世界唯一的,IP 地址在局域网每一个设备也是唯一的;IP地址就是逻辑地址,MAC则是真实地址。
IP 地址特点:
- IP地址具有唯一性,表达性;
- IP地址是可以修改的地址。
- IP地址具有可管理的特性。
3.5.1 IP地址组成
它们可以唯一标识 IP 网络中的每台设备,每台主机(计算机、网络设备、外围设备)必须具有唯一的地址。IPv6 已经在互联网中开始大规模的采用,但在企业局域网内部使用的依旧是以 IPv4 为主。IPv6 使用的十六进制进行表示,而IPv4则是使用大众所认知的十进制进行表示。
拓展:VLAN = subnet子网 = 网段 = 广播域
不同网段来讲,网络ID肯定不一样;同一个网段来讲,主机ID肯定不一样。
IP地址由两部分组成
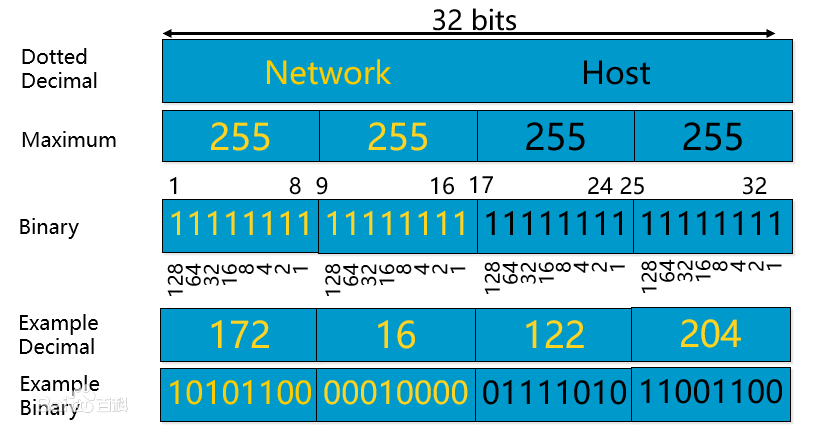
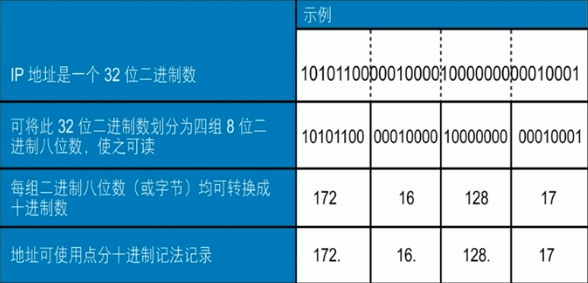
IPv4地址格式:点分十进制记法
3.5.2 IP地址分类
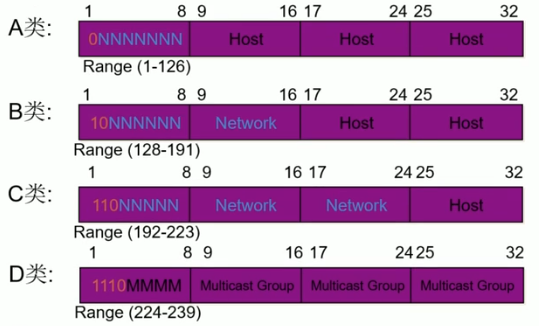
IP=netID + hostID
可用主机数 = 2^hostID(主机ID位数) - 2 = 2 ^(32-网络ID位数) - 2
网络数 = 2^ 可变的网络ID位数
A类:一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”, 地址范围从1.0.0.0 到126.0.0.0。可用的A类网络有126个,每个网络能容纳1亿多个主机。
B类:一个B类IP地址由2个字节的网络地址和2个字节的主机地址组成,网络地址的最高位必须是“10”,地址范围从128.0.0.0到191.255.255.255。可用的B类网络有16382个,每个网络能容纳6万多个主机。
C类:一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”。范围从192.0.0.0到223.255.255.255。C类网络可达209万余个,每个网络能容纳254个主机。
D类:D类IP地址第一个字节以"1110"开始,它是一个专 门 保留的地址。它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中。多点广播地址用来一次寻址一组计算机,它标识共享同一协议的一组计算机。
E类:以"1111 0"开始,为将来使用保留。
全“0”的IP地址0.0.0.0 对应于当前主机网络地址。全“1”的IP地址 "255.255.255.255"是当前所有子网的广播地址。
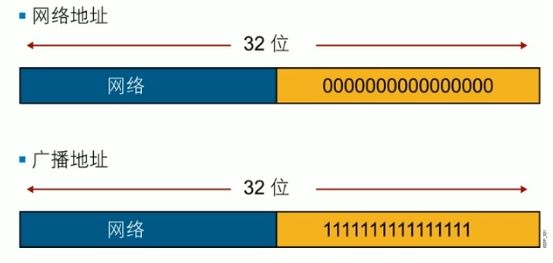
网络地址,主机地址,广播地址
| 名称 | 定义 |
|---|---|
| 网络地址 | 主机位全为0 |
| 代表一个网段(头) | |
| 主机地址 | 主机位不全为0也不全为1 |
| 代表一个网段的一个节点(身体) | |
| 广播地址 | 主机位全为1 |
| 代表一个网段内的所有节点(尾) |
各类IP地址可分配的网络地址与IP地址
| 类别 | 可分配网络数量 | 可分配IP地址数量A类 |
|---|---|---|
| A类 | 2^(8-1) - 2 = 126 | |
| (减2的原因是除去最小网络号0与最大网络号127) | 2^24 - 2 | |
| (除去网络地址与广播地址) | ||
| B类 | 2^(16-2) = 16384 | 2^16 - 2 = 65534 |
| C类 | 2^(24-3) = 2097152 | 2^8 - 2 = 254 |
3.5.3 公共和私有IP地址
私有IP地址:不直接用于互联网,通常在局域网中使用
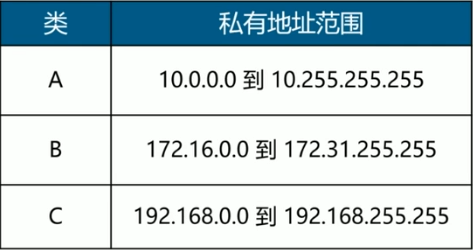
公共IP地址:互联网上设备拥有的唯一地址

3.5.4 特殊地址
0.0.0.0不是一个真正意义上的IP地址。它表示所有不清楚的主机和目的网络
限制广播地址。对本机来说,这个地址指本网段内(同一广播域)的所有主机
本机回环地址,主要用于测试。在传输介质上永远不应该出现目的地址为"127.0.0.1"的数据包
组播地址,224.0.0.1特指所有主机,224.0.0.2特指所有路由器。224.0.0.5指OSPF路由器,地址多用于一些特定的程序以及多媒体程序
如果Windows主机使用了DHCP自动分配IP地址,而又无法从DHCP服务器获取地址,系统会为主机分配这样地址
3.5.5 保留地址
范例:
172.16.0.0网络中的两个地址:172.16.0.0(网络地址) - 172.16.255.255(广播地址)
小总结:
|
| A类 | B类 | C类 | D类 | E类 |
| — | — | — | — | — | — |
| 二进制表示 | 0 0000000 -
0 1111111.X.Y.Z | 10 000000 -
10 111111.X.Y.Z | 110 00000 -
110 11111.X.Y.Z | 1110 0000 -
1110 1111.X.Y.Z | 保留未使用 |
| 十进制表示法 | 0-127.X.Y.Z | 128-191.X.Y.Z | 192-223.X.Y.Z | 224-239.X.Y.Z | 240-255 |
| 网络ID | 网络ID位是最高8位 | 网络ID位是最高16位 | 网络ID位是最高24位 | 组(多)播 |
|
| 主机ID | 主机ID是24位低位 | 主机ID是16位低位 | 主机ID是8位低位 |
|
|
| 网络数 | 126=2^7(可变是的网络ID位数)-2 | 2^14=16384 | 2^21=2097152 |
|
|
| 每个网络中的主机数 | 2^24-2=16777214 | 2^16-2=65534 | 2^8-2=254 |
|
|
| 默认子网掩码 | 255.0.0.0 | 255.255.0.0 | 255.255.255.0 |
|
|
| 私网地址 | 10.0.0.0 | 172.16.0.0-172.31.0.0 | 192.168.0.0-192.168.255.0 |
|
|
| 范例 | 114.114.114.114
1.1.1.1
58.87.87.99
119.29.29.29 | 180.76.76.76
172.16.0.1 | 223.6.6.6 |
|
|
3.5.6 子网掩码
主机数=2^主机ID位数 - 2
网络数=2^可变的网络ID位数
网络ID=IP 与 Netmask
CIDR:无类域间路由,目前的网络已不再按A,B,C类划分网段,可以任意指定网段的范围
CIDR无类域间路由表示法:IP/网络ID位数,如:172.16.0.100/16
CIDR表示法:IP/网络ID位数
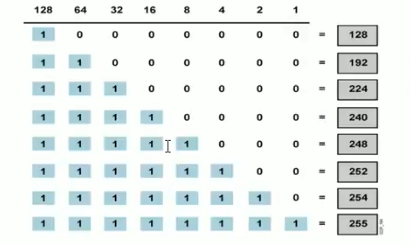
NetMask:子网掩码,32bit二进制,和IP地址成对使用,对应于IP中的网络ID为1,对应于IP中的主机ID为0。
netmask 子网掩码: 32位或128位(IPv6)的数字,和IP成对使用,用来确认IP地址中的网络ID和主机D,对应网络D的位为1,对应主机D的位为0,范例:255.255.255.0,表现为连续的高位为1,连续的低位为0。

子网掩码的八位
相关公式:
判断对方主机是否在同一个网段:
用自已的子网掩码分别和自已的IP及对方的IP相与,比较结果,相同则同一网络,不同则不同网段
范例:
netmask: 255.255.224.0,网络ID位:19 主机ID位:13 主机数=2^13-2=8190
范例:判断A和B是否在网一个网段?
A: 192.168.1.100 netmask:255.255.255.0
B: 192.168.2.100 netmask:255.255.0.0
范例:一个主机:172.16.1.100/28
1、此主机所在的网段最多有多少主机?主机数=2N(32-28)-2=14
2、网络ID?IP和子网掩码相与,172.16.1.96
3、此网段的主机中最小的IP:172.16.1.97。最大的IP:172.16.1.110
范例:CIDR计算题
### 问题1:
203.101.123.163/28
#求子网掩码,主机数,IP范围(最小IP,最大IP),网络ID
子网掩码:255.255.255.240
主机数:2^4 - 2 = 14
IP范围(最小IP,最大IP):203.101.123.161 - 203.101.123.174
网络ID:203.101.123.160/28
广播地址:203.101.123.175
### 问题2:判断两个网段是否可以通信
A:10.0.0.100/24
B:10.0.0.200/25
1)IPA与netmaskA=netmaskIDA
2)IPB与netmaskA=netmaskIDB
3)netmaskIDA =? netmaskIDB
#通信结果
A-->B
A)10.0.0.100 与 255.255.255.0 = 10.0.0.0
B)10.0.0.200 与 255.255.255.0 = 10.0.0.0
) A = B,是在同一个网段
1)IPA与netmaskB=netmaskIDA
2)IPB与netmaskB=netmaskIDB
3)netmaskIDA =? netmaskIDB
#通信结果
B-->A
A)10.0.0.100 与 255.255.255.128 = 10.0.0.0
B)10.0.0.200 与 255.255.255.128 = 10.0.0.128
) A != B,不在同一个网段
### 问题3:
210.123.222.100/22
210.123.198.200/22
#问:是否在同一个网段
210.123.110111 | 10.0/22
210.123.110001 | 10.0/22
#不再同一个网段
### 问题4:
10.123.200.100/22
#求子网掩码Netmask,主机数,网络ID
子网掩码:255.255.252.0
主机数:2^10-2=1022
网络ID:10.123.200.0/22
子网掩码不一样,在某些场合也是可以通信的。
3.5.7 划分子网
划分子网:将一个大网(主机数量多,主机ID位多)分割成多个小网(主机数量少,主机ID位少),网络ID向主机ID借 N 位,将划分成个 2^N 子网。
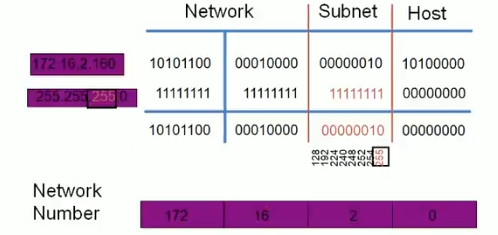
可变长度子网掩码
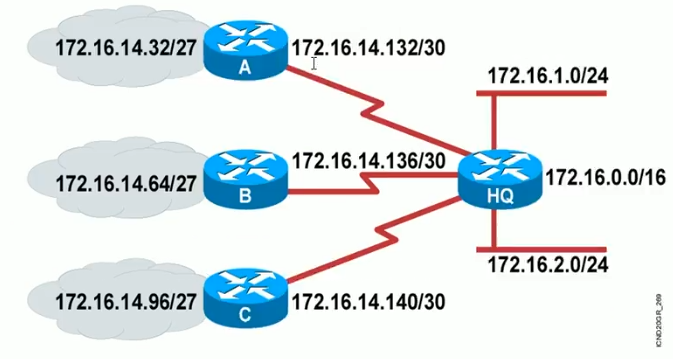
Subnet 地址

范例:划分子网
### 问题1:
中国移动10.0.0.0/8,为32个省分配各自的子网
#1 新的子网的子网掩码?
2^N = 32 --> N=5
新的子网的子网掩码是:255.248.0.0
10.0.0.0/13
#2 每个子网的主机数?
32-13=19
每个子网的主机数是:2^19-2=524,286
#3 第一个子网和最后一个子网的网络ID(CIDR表示法)?
第一个子网:10.0.0.0/13
最后一个子网:10.248.0.0/13
#4 河南省获得了第10个子网网络ID?最小的IP和最大的IP是?
10.00000 000.0.0 #第1个子网
10.00001 000.0.0
10.00010 000.0.0
...
10.01001 000.0.0 #第10个子网
最小IP:10.72.0.1/13
最大IP:10.79.255.254/13
#5 最后一个子网的CIDR表示法
最后一个子网:10.248.0.0/13
### 问题2:
172.16.0.0/16 划分成多个子网,每个子网最多存放60台主机,如何实现?
2^N-2 >= 60
N=6
网络ID=32-6=26
172.16.0.0/26
### 问题3:
中国移动10.0.0.0/8给32个各省公司划分对应的子网,河南省得到第10个子网,再给省内的16个地市划分子网
2^N=32 --> N=5
省公司的子网:10.0.0.0/13
河南省得到第10个子网:10.72.0.0/13
# 10.0.0.0/13
# 10.00000 000.0.0/13 是第一个子网(在 00000 进行划分)
# 10.01001 000.0.0/13 是第十个子网
1)每个市公司的子网的netmask?
10.72.0.0/13
2^N >= 16 --> N=4
每个市公司的子网的netmask:10.72.0.0/17
2)每个市公司的子网的主机数有多少?
32-17=15
每个市公司的子网的主机数有:2^15-2=32766
3)各地市的最小netid和最大的netid?
最小的netid:10.72.0.0/17
最大的netid:10.75.128.0/17
4)洛阳市第2个子网,最小IP和最大IP?
10.73.0.0/17
最小的IP:10.73.0.1/17
最大的IP:10.73.127.254/17
5)最后一个子网的CIDR表示法?
10.79.128.0/17
3.5.8 优化IP地址分配

合并超网:将多个小网络合并成一个大网,主机ID位向网络ID位借位
超网(Supernetting)是与子网类似的概念,IP地址根据子网掩码被分为独立的网络地址和主机地址。超网,也称无类别域间路由选择(CIDR),它是集合多个同类互联网地址的一种方法。
与子网划分(把大网络分成若干小网络)相反,它是把一些小网络组合成一个大网络,就是超网。
范例:
8个C类网段
220.78.168.0/24
220.78.169.0/24
220.78.170.0/24
220.78.171.0/24
220.78.172.0/24
220.78.173.0/24
220.78.174.0/24
220.78.175.0/24
# 使用二进制转换
220.78.10101 000.0 220.78.168.0/24
220.78.10101 001.0 220.78.169.0/24
220.78.10101 010.0 220.78.170.0/24
...
220.78.10101 110.0 220.78.174.0/24
220.78.10101 111.0 220.78.175.0/24
# 合并后的网段
220.78.168.0/21
3.5.9 跨网络通信
跨网络通信:路由,选择路径
路由分类:
优先级:精度越高,优先级越高
# Windows 查看路由表
route print
# Linux 查看路由表
route -n
ip route
3.5.10 动态主机配置协议DHCP

动态主机配置协议 DHCP(Dynamic Host Configuration Protocol,动态主机配置协议) 是 RFC 1541(已被 RFC 2131 取代)定义的标准协议,该协议允许服务器向客户端动态分配 IP 地址和配置信息。VMware 的内置DHCP租约默认是30min,最多2h。
DHCP协议支持C/S(客户端/服务器)结构,主要分为两部分:
1、DHCP客户端:通常为网络中的PC、打印机等终端设备,使用从DHCP服务器分配下来的IP信息,包括IP地址、DNS等。
2、DHCP服务器:所有的IP网络设定信息都由DHCP服务器集中管理,并处理客户端的DHCP请求。
DHCP采用UDP作为传输协议,客户端发送消息到DHCP服务器的的67号端口,服务器返回消息给客户端的68号端口。
在生产环境中物理服务器的IP地址是静态地址,当在容器环境中,则容器都是采用DHCP动态地址。
DHCP 八种报文
| 报文类型 | 用途 |
|---|---|
| DHCP Discover | 客户端广播查找可用服务器 |
| DHCP Offer | 响应DHCP discover报文,分配相应配置参数 |
| DHCP Request | 客户端请求配置参数、请求配置确认、续租约 |
| DHCP Ack | 服务器确认DHCP request报文 |
| DHCP Decline | 客户端发现地址被使用,通知服务器 |
| DHCP Release | 客户端释放地址时通知服务器的报文 |
| DHCP Inform | 客户端已有IP地址,请求更详情配置参数 |
| DHCP Nak | 服务器告诉客户端地址请求不正确或租期已过期 |
DHCP 动态主机配置协议工作原理:
拓展:Windows里管理网络命令
C:\Users\Administrator>netsh
netsh>?
3.5.11 IPv4 到 IPv6 的过渡
考虑到因特网上的系统和设备非常之多,想要一次性从IPv4升级到IPv6是无法做到的。而要实现IP版本的升级,需要花费相当多的时间,且升级过程必须是相当平滑的,防止升级过程中出现任何问题。IETF(Internet Engineering Task Force,国际互联网工程任务组)设计了三种策略来实现平滑的IP版本升级。
(1)双协议栈策略,就是一个站同时运行IPv4和IPv6,直到整个因特网使用IPv6。当一个分组被发送到目的端时,主机向DNS进行查询。如果DNS返回一个IPv4地址,那么源主机就发送一个IPv4分组,如果返回一个IPv6地址,就发送一个IPv6分组。
(2)隧道技术策略,当两台使用IPv6的计算机要进行相互通信,但其分组数据要通过使用IPv4的网络时,该分组要封装成IPv4分组,而当分组离开时该网络时再去掉这个封装。
(3)头部转换策略,当因特网中绝大多数系统设备已经过渡到IPv6,但一些系统仍然使用IPv4时,发送方想使用IPv6,但接收方不能识别IPv6,这时将IPv6头部格式转换成IPv4头部格式,IPv6地址按照一定规则映射转换为IPv4地址。
4 网络配置
4.1 基本网络配置
将Linux主机接入到网络,需要配置网络相关设置—般包括如下内容:
4.2 CentOS6 之前的版本的网卡名称
接口命名方式:CentOS 6
以太网:eth[0,1,2,......]
# CentOS6使用eth命名可能会造成网络设备编号混乱
#ppp拨号网络
ppp:ppp[0,1,2,......]
网络接口识别并命名相关的 udev 配置文件:
/etc/udev/rules.d/70-persistent-net.rules
#修改对应的名称即可。重启系统,或者将网卡卸载重新安装
~ vim /etc/udev/rules.d/70-persistent-net.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:4b:20:62", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
查看网卡:
dmesg | grep -i eth
ethtool -i eth0
卸载网卡驱动:
modprobe -r e1000
rmmod e1000
装载网卡驱动:
modprobe e1000
范例:临时修改网卡名称
~ ip link set eth0 down
~ ip link set eth0 name abc
~ ip link set abc up
范例:主机名设置
# 查看主机名
# 主机名不支持下划线,支持使用横线。
~ hostname
~ vim /etc/sysconfig/network
HOSTNAME=GD-VM-CentOS6-10-0-0-40.kubernetes.com
4.3 网络配置命令
4.3.1 网络配置方式
4.3.2 ifconfig 命令
来自于 net-tools 包,建议使用 ip 代替换
~ rpm -qi net-tools
Name : net-tools
Version : 2.0
Release : 0.52.20160912git.el8
Architecture: x86_64
Install Date: Sun 11 Jul 2021 08:42:19 PM CST
Group : System Environment/Base
Size : 964782
License : GPLv2+
Signature : RSA/SHA256, Tue 28 Apr 2020 11:49:03 PM CST, Key ID 05b555b38483c65d
Source RPM : net-tools-2.0-0.52.20160912git.el8.src.rpm
Build Date : Mon 27 Apr 2020 09:59:47 AM CST
Build Host : x86-01.mbox.centos.org
Relocations : (not relocatable)
Packager : CentOS Buildsys <bugs@centos.org>
Vendor : CentOS
URL : http://sourceforge.net/projects/net-tools/
Summary : Basic networking tools
Description :
The net-tools package contains basic networking tools,
including ifconfig, netstat, route, and others.
Most of them are obsolete. For replacement check iproute package.
# 网络工具包包含基本的网络工具,包括ifconfig、netstat、route等。大多数都过时了。更换检查iproute包。
范例:
ifconfig [interface]
# -a 可以查看所有网卡信息,不管是启用还是禁用
ifconfig -a
# 启用和禁用网卡
ifconfig IFACE [up|down]
ifup IFACE # 启动网卡
ifdown IFACE # 禁用网卡,将IP逻辑地址禁用,链路层没有禁用
# ifconfig 的禁用是数据链路层,当然链路层禁用后,网络层也不能使用
ifconfig interface [aftype] options | address ...
ifconfig IFACE IP/netmask [up]
ifconfig IFACE IP netmask NETMASK
注意:立刻生效
启用混杂模式:[-] promisc
范例:
#添加/修改网卡IP地址(临时性的)
~ ifconfig eth0 10.0.0.68 netmask 255.255.0.0
或者
~ ifconfig eth0 10.0.0.68/16
#清除eth0上面的IP地址
~ ifconfig eth0 0.0.0.0 | ifconfig eth0 0.0.0.0/0
或者
~ ifconfig eth0 0
#启用和禁用网卡
~ ifconfig eth0 down
~ ifconfig eth0 up
#对一个网卡设置多个IP地址
~ ifconfig eth1:1 10.0.0.200/24
~ ifconfig
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:bf:63:5c txqueuelen 1000 (Ethernet)
RX packets 590 bytes 47797 (46.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 818 bytes 112874 (110.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth1:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.200 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:bf:63:5c txqueuelen 1000 (Ethernet)
#禁用eth1:1网卡
~ ifconfig eth1:1 down
~ ifconfig
范例:
#-s 可以查看网卡的通信情况
~ ifconfig -s
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 330960 0 0 0 411959 0 0 0 BMRU
eth1 1500 1013 0 0 0 1562 0 0 0 BMRU
lo 65536 599 0 0 0 599 0 0 0 LRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU
#查看指定网卡的通信情况
~ ifconfig -s eth1
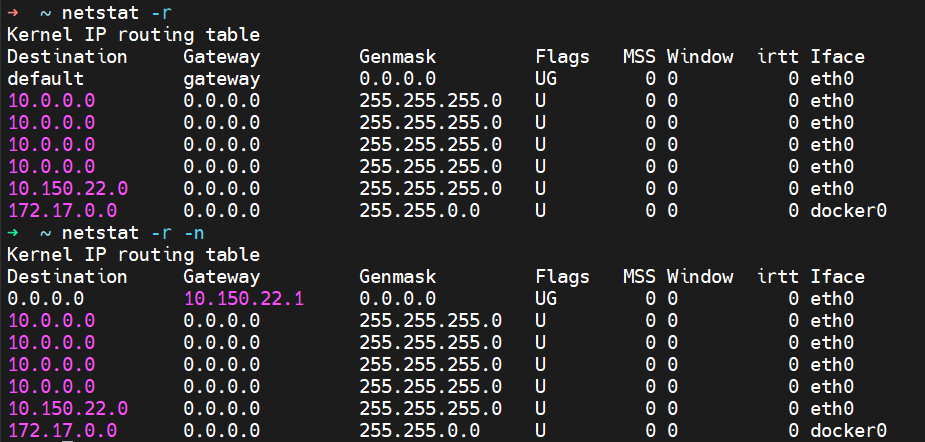
4.3.3 route 命令
任何一个网络通信的主机都有路由表,包括Linux,Windows以及路由器等网络设备都有路由表
Route Record:
- 网络路由:表示一个网段的路由
- 主机路由:表示一个主机的路由
- 默认路由:所有未知网段的路由 0.0.0.0/0
路由表组成:四个组成部分
- 目标网络Destination:目标主机所在的网络ID
- 子网掩码Netmask:目标网络的子网掩码
- 接口lface:当前网络设备的出口
- 网关Gateway:下一个路由器的邻近当前路由器的接口IP,下一跳Next Hop
- 开销Metric:费用,值越小,优先级越高
路由表管理命令
路由表主要构成:
查看路由表:
route
route -n
范例:
? ~ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default gateway 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
10.150.22.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
# 直连路由,则网关不需要配置;直连路由在配置接口IP地址就会自动生成
? ~ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.150.22.1 0.0.0.0 UG 100 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
10.150.22.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
添加:route add
route add [-net|-host|default] target [netmask Nm] [gw GW] [[dev] If]
范例:route del
route del [-net|-host] target [netmask Nm] [gw GW] [[dev] If]
范例:
###添加路由
#目标:192.168.1.3 网关:172.16.0.1
? ~ route add -host 192.168.1.3 gw 172.16.0.1 dev eth0
#目标:192.168.0.0 网关:172.16.0.1
? ~ route add -net 192.168.0.0 netmask 255.255.255.0 gw 172.16.0.1 dev eth0
? ~ route add -net 192.168.0.0/24 gw 172.16.0.1 dev eth0
#设置路由优先级
? ~ route add -net 192.168.8.0/24 dev eth0 metric 200
#默认路由,网关:172.16.0.1
? ~ route add -net 0.0.0.0 netmask 0.0.0.0 gw 172.16.0.1
? ~ route add -net 0.0.0.0/0 gw 172.16.0.1
? ~ route add default gw 172.16.0.1
###删除路由
#目标:192.168.1.3 网关:172.16.0.1
? ~ route del -host 192.168.1.3 gw 172.16.0.1
? ~ route del -host 192.168.1.3
#目标:192.168.0.0 网关:172.16.0.1
? ~ route del -net 192.168.0.0 netmask 255.255.255.0 gw 172.16.0.1
? ~ route del -net 192.168.0.0/24
范例:实现静态路由
静态路由(英语:Static routing)是一种路由的方式,路由项(routing entry)由手动配置,而非动态决定。与动态路由不同,静态路由是固定的,不会改变,即使网络状况已经改变或是重新被组态。一般来说,静态路由是由网络管理员逐项加入路由表。
环境:
四台主机:
A主机:etho NAT模式
R1主机: etho NAT模式,eth1仅主机模式
R2主机: etho桥接摸式,eth1仅主机模式
B主机:eth0桥接模式

#A主机
ifconfig eth0 10.0.0.123/8
route add -net 10.0.0.0/8 dev eth0
route add default gw 10.0.0.200 dev eth0
#R1主机
ifconfig eth0 10.0.0.200/8
ifconfig eth1 192.168.0.200/24
route add -net 10.0.0.0/8 dev eth0
route add -net 192.168.0.0/24 dev eth1
route add -net 172.16.0.0/16 gw 192.168.0.201 dev eth1
#临时生效(路由转发功能)
echo 1 > /proc/sys/net/ipv4/ip_forward
#永久生效(路由转发功能)
~ vim /etc/sysctl.conf
net.ipv4.ip_forward=1
~ sysctl -p
#R2主机
ifconfig etho 172.16.0.200/16
ifconfig eth1 192.168.0.201/24
route add -net 192.168.0.0/24 dev eth1
route add -net 172.16.0.0/16 dev etho
route add -net 10.0.0.0/8 gw 10.0.0.200 dev eth1
#临时生效(路由转发功能)
echo 1 > /proc/sys/net/ipv4/ip_forward
#永久生效(路由转发功能)
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
#B主机
ifconfig eth0 172.16.0.123/16
route add -net 172.16.0.0/16 dev eth0
route add default gw 172.16.0.200 dev eth0
范例:将两台不同网段的主机直连通信
# A <---> Switch <---> B
# A主机IP地址:11.0.0.101
~ ifconfig eth0 11.0.0.101/24
~ route add -host 10.0.0.102 dev eth0
~ ping -c 1 -W 1 10.0.0.102
# B主机IP地址:10.0.0.102
~ ifconfig eth0 10.0.0.102/24
~ route add -host 11.0.0.101 dev eth0
~ ping -c 1 -W 1 11.0.0.101
PING 11.0.0.101 (11.0.0.101) 56(84) bytes of data.
64 bytes from 11.0.0.101: icmp_seq=1 ttl=64 time=0.473 ms
--- 11.0.0.101 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.473/0.473/0.473/0.000 ms
# 在两主机之间添加路由器,可以实现需求
# 环境中只要确保物理上是连通的,有路(路由)就可以通
# 若物理上是连通的,但是没有路(路由)那么还是不通的

#使其Linux系统具有路由转发功能
echo 1 > /proc/sys/net/ipv4/ip_forward
范例:Linux系统实验

###网络规划(Linux主机中添加相应的网卡配置并添加对应的网络)
# A--net8(10.0.0.0/24)--R1--net1(192.168.10.0/24)--R2--net2(172.16.20.0/24)--B
#A:10.0.0.123/24
修改网卡配置即可
#R1:开启路由转发功能(重要)并添加相应的路由策略
##eth0:10.0.0.200/24
##eth1:192.168.10.200/24
修改网卡配置即可
#临时生效
route add -net 172.16.20.0/24 gw 192.168.10.100 dev eth1
#永久生效
vim /etc/sysconfig/static-routes
any net 172.16.20.0/24 gw 192.168.10.100
#R2:开启路由转发功能(重要)并添加相应的路由策略
##eth0:192.168.10.100/24
##eth1:172.16.20.100/24
修改网卡配置即可
#临时生效
route add -net 10.0.0.0/24 gw 192.168.10.200 dev eth0
#永久生效
vim /etc/sysconfig/static-routes
any net 10.0.0.0/24 gw 192.168.10.200
#B:172.16.20.123/24
修改网卡配置即可
#查看系统的路由转发功能是否开启
sysctl -a | grep -i "ip_forward"
#抓包
tcpdump -i eth0 -nn icmp
#查看路由的追踪过程(查看跳数)
mtr <IP地址>
tracepath
traceroute


范例:查看路由
#查看路由
route -n
#查看网关
cat /etc/sysconfig/network-scripts/ifcfg-eth1 | grep -i "gateway"
#查看DNS服务
cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 114.114.114.114
nameserver 8.8.8.8
4.3.4 配置动态路由
通过守护进程获取动态路由,安装quagga包,通过命令 vtysh 配置
支持多种路由协议:RIP、OSPF 和 BGP
路由信息协议RIP(Routing Information Protocol)是基于距离矢量算法的路由协议,利用跳数来作为计量标准。
OSPF(Open Shortest Path First开放式最短路径优先)是一个内部网关协议(Interior Gateway Protocol,简称IGP),用于在单一自治系统(autonomous system,AS)内决策路由。是对链路状态路由协议的一种实现,隶属内部网关协议(IGP),故运作于自治系统内部。著名的迪克斯彻(Dijkstra)算法被用来计算最短路径树。OSPF支持负载均衡和基于服务类型的选路,也支持多种路由形式,如特定主机路由和子网路由等。
边界网关协议(BGP)是运行于 TCP 上的一种自治系统的路由协议。 BGP 是唯一一个用来处理像因特网大小的网络的协议,也是唯一能够妥善处理好不相关路由域间的多路连接的协议。 BGP 构建在 EGP 的经验之上。 BGP 系统的主要功能是和其他的 BGP 系统交换网络可达信息。网络可达信息包括列出的自治系统(AS)的信息。这些信息有效地构造了 AS 互联的拓扑图并由此清除了路由环路,同时在 AS 级别上可实施策略决策。
4.3.5 netstat 命令
来自于net-tools包,建议便用 ss 代替
ss代替显示网络连接:
netstat [--tcp|-t] [--udp|-u] [--raw|-w] [--listening|-l] [--all|-a] [--numeric|-n] [--extend|-e[--extend|-e]] [--program|-p]
常用选项:
-t: tcp协议相关
-u: udp协议相关
-w: raw socket相关
-l: 处于监听状态
-a: 所有状态
-n: 以数字显示IP和端口
-e: 扩展格式
-p: 显示相关进程及PID
常用组合:
netstat:
-tan
-uan
-tnl
-unl
显示路由表:
netstat {--route|-r} [--numeric|-n]
-r:显示内核路由表
-n:数据格式
4.3.6 显示接口统计数据
netstat {--interfaces|-I|-i} [iface] [--all|-a] [--extend|-e] [--program|-p] [--numeric|-n]
netstat -i
netstat -I=IFACE
ifconfig -s IFACE
范例:
? ~ netstat -Ieth0
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 15672755 0 0 0 19992263 0 0 0 BMRU
? ~ ifconfig -s eth0
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 15672842 0 0 0 19992354 0 0 0 BMRU
? ~ netstat -nt
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 10.150.22.47:22 120.229.46.206:6176 ESTABLISHED
tcp 0 0 10.150.22.47:22 120.229.46.206:6170 ESTABLISHED
4.3.7 ip 命令
来自于iproute包,可用于代替ifconfig,route
Linux ip 命令与 ifconfig 命令类似,但比 ifconfig 命令更加强大,主要功能是用于显示或设置网络设备。
ip 命令是 Linux 加强版的的网络配置工具,用于代替 ifconfig 命令。
菜鸟教程 Linux ip 命令
4.3.7.1 配置 Linux 网络属性
ip [ OPTIONS ] OBJECT { COMMAND | help }
ip 命令说明:
OBJECT={ link | addr | addrlabel | route | rule | neigh | ntable | tunnel | maddr | mroute | mrule | monitor | xfrm | token }
OBJECT := { link | addr | route }
ip link - network device configuration
set dev IFACE,可设置属性: up and down:激活或禁用指定接口,相当于 ifup / ifdown
show [dev IFACE] [up]: :指定接口,up仅显示处于激活状态的接口
man帮助:ip(8), ip-address(8),ip-link(8),ip-route(8)
范例:查看帮助
~ ip help
Usage: ip [ OPTIONS ] OBJECT { COMMAND | help }
ip [ -force ] -batch filename
where OBJECT := { link | address | addrlabel | route | rule | neigh | ntable |
tunnel | tuntap | maddress | mroute | mrule | monitor | xfrm |
netns | l2tp | fou | macsec | tcp_metrics | token | netconf | ila |
vrf | sr | nexthop | mptcp }
OPTIONS := { -V[ersion] | -s[tatistics] | -d[etails] | -r[esolve] |
-h[uman-readable] | -iec | -j[son] | -p[retty] |
-f[amily] { inet | inet6 | mpls | bridge | link } |
-4 | -6 | -I | -D | -M | -B | -0 |
-l[oops] { maximum-addr-flush-attempts } | -br[ief] |
-o[neline] | -t[imestamp] | -ts[hort] | -b[atch] [filename] |
-rc[vbuf] [size] | -n[etns] name | -N[umeric] | -a[ll] |
-c[olor]}
~ ip link help
~ ip addr help
~ ip route help
IP地址管理
ip addr { add | del } IFADDR dev STRING [label LABEL] [scope {global | link | host}] [broadcast ADDRESS]
[label LABEL]:添加地址时之名网卡别名
[scope {global | link | host}]:指明作用域,global:全局可用,link:仅链接可用,host:本机可用
# global:表示网卡中的IP地址是保存在内核中的,全局性的
# link:表示网卡只能针对所连接的链路有效
# host:表示IP地址只能本机有效,地址即不会广播出去,别的机器也不能访问该机器地址
[broadcast ADDRESS]:指明广播地址
ip address show
ip address flush
范例:
ip link show # 显示网络接口信息
ip link set eth0 up # 开启网卡
ip link set eth0 down # 关闭网卡
ip link set eth0 promisc on # 开启网卡的混合模式
ip link set eth0 promisc offi # 关闭网卡的混个模式
ip link set eth0 txqueuelen 1200 # 设置网卡队列长度
ip link set eth0 mtu 1400 # 设置网卡最大传输单元
ip addr show # 显示网卡IP信息
ip addr add 192.168.0.1/24 dev eth0 # 设置eth0网卡IP地址192.168.0.1
ip addr del 192.168.0.1/24 dev eth0 # 删除eth0网卡IP地址
ip addr add 192.168.0.1/24 dev eth0 label eth0:0 # 设置网卡别名
ip addr del 192.168.0.1/24 dev eth0 label eth0:0 # 删除网卡别名
ip addr flush dev eth0 # 清空网络地址
范例:增加网卡别名实现一个网卡多个IP地址
~ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:37:9e:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.110/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::698a:144a:4ba2:572e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 添加子网卡
~ ip addr add 192.168.1.110/24 dev eth0 label eth0:0
~ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:37:9e:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.110/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.1.110/24 scope global eth0:0
valid_lft forever preferred_lft forever
inet6 fe80::698a:144a:4ba2:572e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 删除子网卡
~ ip addr del 192.168.1.110/24 dev eth0 label eth0:0
~ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:37:9e:a1 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.110/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::698a:144a:4ba2:572e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
范例:修改IP地址
~ ip addr show eth1
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:37:9e:ab brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 scope global eth1
valid_lft forever preferred_lft forever
# 先添加新的IP地址,再删除旧的IP地址
~ ip addr add 10.10.10.10/24 dev eth1
~ ip addr del 192.168.1.1/24 dev eth1
~ ip addr show eth1
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:37:9e:ab brd ff:ff:ff:ff:ff:ff
inet 10.10.10.10/24 scope global eth1
valid_lft forever preferred_lft forever
范例:
~ ip addr change 10.0.0.18/24 dev eth1 preferred_lft 30 valid_lft 6
preferred_lft is greater than valid_lft
~ ip addr change 10.0.0.18/24 dev eth1 preferred_lft 5 valid_lft 30
~ 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:37:9e:ab brd ff:ff:ff:ff:ff:ff
inet 10.0.0.18/24 scope global deprecated dynamic eth1
valid_lft 20sec preferred_lft 0sec
4.3.7.2 管理路由
ip route 的用法:
# 添加路由
ip route add TARGET via GW dev IFACE src SOURCE_IP
TARGET:
主机路由: IP
网络路由: NETWORK/MASK
# 添加网关
ip route add default via GW dev IFACE
# 网关是和当前网卡是在同一个网段中
# 删除路由
route del TARGET
# 查看路由
ip route show | ip route list
# 清空路由表
ip route flush [dev IFACE] [via PREFIX]
范例:
# 设置系统默认路由
ip route add default via 192.168.1.254
# 设置192.168.4.0网段的网关为192.168.0.254,数据走eth0接口
ip route add 192.168.4.0/24 via 192.168.0.254 dev eth0
# 设置默认网关为192.168.0.254
ip route add default via 192.168.0.254 dev eth0
# 删除192.168.4.0网段的网关
ip route del 192.168.4.0/24
# 删除默认路由
ip route del default
# 删除路由
ip route delete 192.168.1.0/24 dev eth0
范例:查看路由过程
~ ip route get 10.0.0.111
10.0.0.111 dev eth0 src 10.0.0.110
cache
4.3.8 ss 命令
来自于iproute包,代替netstat,netstat通过遍历/proc来获取 socket信息,ss 使用netlink与内核tcp_diag 模块通信获取socket信息
格式:
ss [OPTIONS]... [FILTER]
选项:
-t: tcp协议相关
-u: udp协议相关
-w: 裸套接字相关
-X: unix sock相关
-l: listen状态的连接
-a: 所有
-n: 数字格式
-p: 相关的程序及PID
-e: 扩展的信息
-m: 内存用里
-o: 计时器信息
格式说明:
FILTER :[ state TCP-STATE ][ EXPRESSION ]
TCP的常见状态:
tcp finite state machine:
LISTEN:监听
ESTABLISHED:已建立的连接
FIN_WAIT_1
FIN_WAIT_2
SYN_SENT
SYN_RECVCLOSED
EXPRESSION:
dport =
sport =
常用组合:
ss -ant
ss -antl
ss -antlp
ss -aun
范例:常见用法
#显示本地打开的所有端口
ss -l
#显示每个进程具体打开的socket
ss -pl
#显示所有的TCP socket
ss -t -a
#显示所有的UDP socket
ss -u -a
#显示所有已经建立的ssh链接
ss -o state established '( dport = :ssh or sport = :ssh )'
ss -o state established '( dport = :22 or sport = :22 )'
#显示所有已经建立的HTTP链接
ss -o state established '( dport = :http or sport = :http )'
#列出当前的socket详细信息显示
ss -s

范例:ss命令的使用实例介绍
#不带任何选项,处理证明已建立连接的所有结果的列表:
ss
#如果要取消命令输出中的标题行,可以使用 -H 选项:
ss -H
#如果需要在命令的输出中显示 tcp 连接,可以使用 -t 选项:
ss -t
#如果需要在命令的输出中显示 udp 连接,可以使用 -u 选项:
ss -u
#如果必须在命令的输出中显示 unix 效率连接,可以使用 -x 选项:
ss -x
#如果你只求是侦听的结果,可以使用 -l 选项:
ss -l
#使用 -s 选项可以显示摘要信息:
ss -s
#如果显示ipv4侦听的,可以使用 -4 和 -l 选项。
ss -4l
#如果显示ipv6侦听的,可以使用 -6 和 -l 选项。
ss -6l
#如果不想将ip解析为主机名称,可以使用 -n 选项,以防止将ip地址解析为主机名。但可能会阻止端口号的解析:
ss -n -4l
4.4 网络配置文件
CentOS 6 之前的版本网卡名为 eth开头
CentOS 7 以后的版本网卡名为 ens开头
原因是:传统的 eth 开头的命名简单,但是有个缺点,在生产环境中添加或者删除网卡,会带来 网卡名的变化。eth 命名方式不是特别的稳定。CentOS 7 以后的版本网卡名是通过硬件和网卡的类型进行确认,也就是说通过增加或者删除网卡不会动态的自动将网卡名修改,可以保证网卡名的稳定性,从而避免增加或者删除网卡带来网卡名的变化,进而导致配置文件出错的问题错误。
但是生产环境中还是会将 eth 开头,因为生产环境中要兼容低版本的操作系统,进而比较好的实现自动化,标准化。
CentOS 8 则取消了 network 服务,所以在 /etc/sysconfig/network-scripts/ 下就少了很多的脚本文件。使用的是 NetworkManager 管理网络服务。
4.4.1 网络基本配置文件
IP、MASK、GW、DNS相关的配置文件:
/etc/sysconfig/network-scripts/ifcfg-IFACE
说明参考:
/usr/share/doc/initcripts-*/sysconfig.txt
常用配置:
| 设置 | 说明 |
|---|---|
| TYPE | 接口类型;常见有的Ethernet, Bridge |
| NAME | 此配置文件应用到的设备 |
| DEVICE | 设备名 |
| HWADDR | 对应的设备的MAC地址 |
| UUID | 设备的惟一标识 |
| BOOTPROTO | 激活此设备时使用的地址配置协议,常用的dhcp, static, none, bootp |
| IPADDR | 指明IP地址 |
| NETMASK | 子网掩码,如:255.255.255.0 |
| PREFIX | 网络ID的位数,如:24 |
| GATEWAY | 默认网关 |
| DNS1 | 第一个DNS服务器地址 |
| DNS2 | 第二个DNS服务器地址 |
| DOMAIN | 主机不完整时,自动搜索的域名后缀 |
| ONBOOT | 在系统引导时是否激活此设备 |
| USERCTL | 普通用户是否可控制此设备 |
| PEERDNS | 如果BOOTPROTO的值为"dhcp",YES将允许dhcp server分配的dns服务器信息直接覆盖至/etc/resolv.conf文件,NO不允许修改resolv.conf |
| NM_CONTROLLED | NM是NetworkManager的简写,此网卡是否接受NM控制 |
范例:常见配置网卡
#静态配置
~ vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
NAME=eth0
#BOOTPROTO=none
BOOTPROTO=static
IPADDR=10.0.0.8
#NETMASK=255.255.255.0
PREFIX=24
GATEWAY=10.0.0.2
DNS1=223.5.5.5
DNS2=223.6.6.6
ONBOOT=yes
DOMAIN=kubesphere.org
#DHCP
~ vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
NAME=eth0
BOOTPROTO=dhcp
ONBOOT=yes
范例:重启网络服务
#CentOS6和CentOS7
service network restart
systemctl restart network
#CentOS8
nmcli connection reload
nmcli connection up <网卡设备>
#重启网卡设备
nmcli device reapply <网卡设备>
4.4.2 配置当前主机的主机名
#CentOS6之前的版本
/etc/sysconfig/network
HOSTNAME=
#CentOS7以后的版本
/etc/hostname
[HOSTNAME]
4.4.3 本地主机名数据库和IP地址的映射
优先于使用 DNS 前检查
getent hosts 查看 /etc/hosts 内容
/etc/hosts
4.4.4 DNS 域名解析
~ cat /etc/resolv.conf
# Generated by NetworkManager
nameserver DNS_SERVER_IP1
nameserver DNS_SERVER_IP2
nameserver DNS_SERVER_IP3
search DOMAIN
#常用的DNS服务器
DNS_SERVER_IP:
114.114.114.114 , 8.8.8.8
#阿里
223.5.5.5 , 223.6.6.6
#百度
180.76.76.76
#腾讯
119.29.29.29 , 119.28.28.28
182.254.118.118 , 182.254.116.116
4.4.5 修改/etc/hosts和DNS的优先级
/etc/nsswitch.conf
hosts: files dns
4.4.6 路由相关的配置文件
/etc/sysconfig/network-scripts/route-IFACE
两种风格:
(1)TARGET (via = Gw)
如:10.0.0.0/8 via 172.16.0.1
(2)每三行一定一条路由
ADDRESS #=TARGET
NETMASK #=mask
GATEWAY #=GW
范例:CentOS7创建/etc/sysconfig/network-scripts/static-routes文件添加持久静态路由
注意:CentOS7支持,CentOS8已经不支持了(因为CentOS8默认取消了 network.service 服务)
#查看network脚本调用路由文件
? ~ grep -A 3 "/etc/sysconfig/static-routes" /etc/init.d/network
if [ -f /etc/sysconfig/static-routes ]; then
if [ -x /sbin/route ]; then
grep "^any" /etc/sysconfig/static-routes | while read ignore args ; do
/sbin/route add -$args
done
else
#查看当前路由
? ~ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.2 0.0.0.0 UG 100 0 0 ens33
10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
#创建文件
? ~ vim /etc/sysconfig/static-routes
? ~ cat /etc/sysconfig/static-routes
any net 192.168.1.0/24 gw 10.0.0.2
any net 192.168.2.0/24 gw 10.0.0.2
? ~ systemctl restart network
#确认路由生效
? ~ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.2 0.0.0.0 UG 100 0 0 ens33
10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.1.0 10.0.0.2 255.255.255.0 UG 0 0 0 ens33
192.168.2.0 10.0.0.2 255.255.255.0 UG 0 0 0 ens33
4.5 网卡别名
将多个IP地址绑定到一个NIC上
每个IP绑定到独立逻辑网卡,即网络别名,命名格式: ethX:Y,如: eth0:1 , eth0:2、eth0:3
范例:ifconfig命令
ifconfig eth0:0 192.168.1.100/24 up
ifconfig eth0:0 down
范例:网卡别名
#创建网卡别名
? ~ ifconfig eth0:1 10.0.0.20/24
? ~ ifconfig eth0:1 10.0.0.20 netmask 255.255.255.0
#启用网卡别名(默认创建即启用)
? ~ ifconfig eth0:1 up
#查看网卡别名
? ~ ifconfig
? ~ ip addr
#清除网卡别名上面的IP地址
? ~ ifconfig eth0:1 0.0.0.0 && ifconfig eth0:1 0
#禁用网卡别名
? ~ ifconfig eth0:1 down
#清除网卡别名上面的IP地址并禁用网卡别名
? ~ ifconfig eth0:1 0 down
范例:ip 命令
#在eth0网卡新增IP地址
ip addr add 172.16.1.1/16 dev eth0
#创建网卡别名
ip addr add 172.16.1.1/16 dev eth0 label eth0:0
#删除网卡别名
ip addr del 172.16.1.1/14 dev eth0 label eth0:0
#清楚网卡别名上面的IP地址
ip addr flush dev eth0 label eth0:0
为每个设备别名生成独立的接口配置文件,格式为:ifcfg-ethX:xxx
范例:
~ cat /etc/sysconfig/network-scripts/ifcfg-eth0:1
NAME=eth0:1
DEVICE=eth0:1
IPADDR=10.0.0.100
NETMASK=255.255.255.0
#PREFIX=24
#CentOS8
~ nmcli connection reload
~ nmcli device reapply eth0
#CentOS7以前版本重启网络服务即可
~ service network restart
#查看网卡别名配置
~ ifconfig
~ ip addr show
注意:
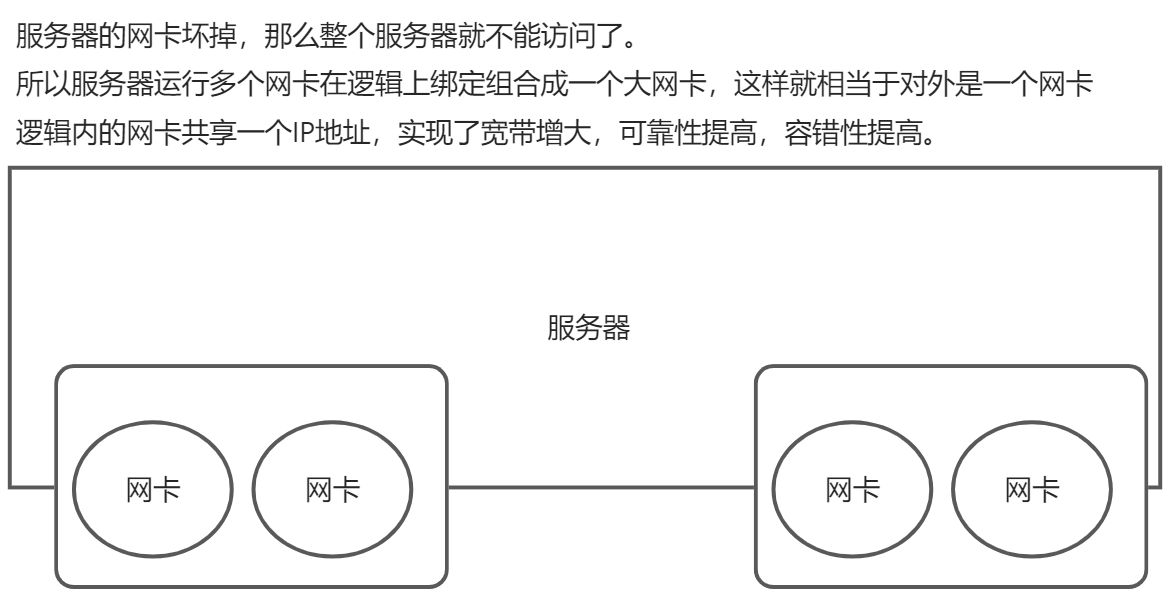
4.6 多网卡Bonding
将多块网卡绑定同一IP地址对外提供服务,可以实现高可用或者负载均衡。直接给两块网卡设置同一IP地址是不可以的。通过bonding,虚拟一块网卡对外提供连接,物理网卡的被修改为相同的MAC地址。
4.6.1 Bonding 聚合链路工作模式
bond聚合链路模式共7种模式:0-6 Mode
负载均衡─所有链路处于负载均衡状态,轮询方式往每条链路发送报文这模式的特点增加了带宽,同时支持容错能力,当有链路出问题,会把流量切换到正常的链路上。
性能问题——个连接或者会话的数据包如果从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降。Bond0在大压力的网烙传输下,性能增长的并不是很理想。
需要交换机进行端口绑定
容错能力一只有一个slave是激活的(active)。也就是说同一时刻只有一个网卡处于工作状态,其他的slave都处于备份状态,只有在当前激活的slave故障后才有可能会变为激活的(active)。
无负载均衡一此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有N个网络接口的情况下,资源利用率为1/N。
负载均衡一基于指定的传输HASH策略传输数据包。
容错能力一这模式的特点增加了带宽,同时支持容错能力,当有链路出问题,会把流量切换到正常的链路上。
性能问题―该模式将限定流量,以保证到达特定对端的流量总是从同一个接口上发出。既然目的地是通过MAC地址来决定的,因此该模式在’本地"网络配置下可以工作得很好。如果所有流最是通过单个路由器,由于只有一个网关,源和目标mac都固定了,那么这个算法算出的线路就一直是同一条,那么这种模式就没有多少意义了。
需要交换机配置为port channel
当有对端交换机失效,感觉不到任何downtime,但此法过于浪费资源;不过这种模式有很好的容错机制。此模式适用于金融行业,因为他们需要高可靠性的网络。不先评出现任何问题。
在动态聚合模式下,聚合组内的成员端口上均启用LACP(链路汇聚控制协议)协议,其端口状态通过该协议自动进行维护。负载均衡一基于指定的传输HASH策略传输数据包。默认算法与blance-xor一样。
容错能力一这模式的特点增加了带宽,同时支持容错能力,当有链路出问题,会把流量切换到正常的链路上,对比blance-xor,这种模式定期发送LACPD报文维护镞路聚合状态,保证链路质量。
需要交换机支持LACP协议
在每个物理接口上根据当前的负载(根据速度计算)分配外出流量。如果正在接收数据的物理接口口出故障了,另一个物理接口接管该故障物理口的MAC地址。
需要ethtool支持获取每个slave的速率
该模式包含了balance-tb模式,同时加上针对IPV4流量的接收负载均衡,而且不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的。bonding驱动截获本机发送的ARP应答,并把源硬件地址改写为bond中某个物理接口的难一硬件地址,从而便得不同的对端使用不同的硬件地址进行通信。
mod=6 与 mod=0的区别: mod=6,先把eth0流量占满,再占eth1 …ethX;而mod=0的话,会发现2个口的流虽都很稳定,基本一样的带宽。而mod=6,会发现第一个口流是很高,第2个口只占了小部分流量。
说明:
常用的模式为 0,1,3,6
mode 1,5,6 不需要交换机的设置
mode 0,2,3,4 需要交换机配置
active-backup、balance-tlb 和 balance-alb 模式不需要交换机的任何特殊配置。
其他绑定模式需要配置交换机以便整合链接。
如:Cisco交换机需要在模式0、2和3中使用EtherChannel,但是模式4中需要LACP和EtherChannel
4.6.2 Bonding 配置
详细信息帮助:
/usr/share/doc/kernel-doc-version/Documentation/networking/bonding.txt
https://www.kernel.org/doc/Documentation/networking/bonding.txt
创建bonding设备的配置文件
~ vim /etc/sysconfig/network-scripts/ifcfg-bond0
NAME=bond0
TYPE=bond
DEVICE=bond0
BOOTPROTO=none
IPADDR=10.0.0.100
PREFIX=8
#miimon指定链路监测时间间隔。如果miimon=100,那么系统每100ms监测一次链路连接状态,如果有一条线路不通就转入另一条线路
#fail_over_mac=1用于虚拟环境,生产环境中不需要添加
BONDING_OPTS="mode=1 miimon=100 fail_over_mac=1"
~ vim /etc/sysconfig/network-scripts/ifcfg-eth0
NAME=eth0
DEVICE=eth0
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
ONBOOT=yes
~ vim /etc/sysconfig/network-scripts/ifcfg-eth1
NAME=eth1
DEVICE=eth1
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
ONBOOT=yes
#重启网络服务(CentOS 7|CentOS 8)
~ systemctl restart network
~ nmcli connection reload
~ nmcli connection up bond0
~ nmcli connection up eth0
~ nmcli connection up eth1
# CentOS 6重启网卡
~ service network restart
查看bond0状态:
/proc/net/bonding/bond0
删除bond0:
ifconfig bond0 down
rmmod bonding
4.7 CentOS7 以上版本网络配置
CentOS 6之前,网络接口使用连续号码命名:eth0、eth1等,当增加或删除网卡时,名称可能会发生变化,CentOS7以上版使用基于硬件,设备拓扑和设置类型命名。
CentOS 8中已弃用network.service,采用NetworkManager (NM)为网卡启用命令。CentOS 8仍可以安装network.service作为网卡服务,只是默认没有安装,具体方法为: dnf install network-scripts,不过官方已明确在下一个大版本中,将彻底放弃network.sevice,不建议继续使用network.service管理网络。
4.7.1 网卡命名机制
systemd对网络设备的命名方式
基于BIOS支持启用biosdevname软件
内置网卡:em1,em2
pci卡:pYpX Y: s1ot ,x: port
网卡组成格式
en : Ethernet有线局域网
wl : wlan无线局域网
ww : wwan无线广域网
o : 集成设备的设备素引号
s : 护展槽的素引号
x : 基于MAC地址的命名
ps : enp2s1
使用传统命名方式:
(1)编辑/etc/default/grub配置文件
#需要提前准备好 ifcfg-eth0 的配置文件,否则网络找不到网卡配置文件
#biosdevname=0 用于戴尔服务器的网卡设置
GRUB_CMDLINE_LINUX=“net.ifnames=0 biosdevname=0”
sed -i.bak -r ‘/GRUB_CMDLINE_LINUX=/s#(.*)“#\1 net.ifnames=0 biosdevname=0”#ig’ grub
(2)为grub2生成其配置文件
grub2-mkconfig -o /etc/grub2.cfg
grub2-mkconfig -o /boot/grub2/grub.cfg
(3)重启系统
reboot
4.7.2 主机名
配置文件:
#CentOS6版本
/etc/sysconfig/network
#CentOS7以后版本
/etc/hostname
默认没有此文件,通过DNS反向解析获取主机名,主机名默认为: localhost.localdomain。
设置主机名:
hostnamectl set-hostname centos7.kubernetes . com
删除文件/etc/hostname,恢复主机名localhost.localdomain
显示主机名信息:
hostname
hostnamectl status
4.7.3 网络配置工具 nmcli
图形工具:nm-connection-editor
字符配置tui工具:
命令行工具:nmcli
以上工具都依赖 NetworkManager 服务,此服务是管理和监控网络设置的守护进程
nmcli 命令
nmcli 命令相关术语
格式:
nmcli [ OPTIONS ] OBJECT { COMMAND \ help }
device - show and manage network interfaces
nmcli device help
connection - start, stop,and manage network connections
nmcli connection help
修改IP地址等属性:
nmcli connection modify IFACE [+|-]setting-property value
setting-property: ipv4.addresses ipv4.gateway ipv4.dns1 ipv4.method manual | auto
修改配置文件执行生效:
nmcli connection reload
nmc1i connection up con-name
| nmcli con mod | ifcfg_*文件 |
|---|---|
| ipv4.method manual | BOOTPROTO=none |
| ipv4.method auto | BOOTPROTO=dhcp |
| ipv4.addresses 192.168.2.1/24 | IPADDR=192.168.2.1 PREFIX=24 |
| ipv4.gateway 172.16.0.200 | GATEWAY=172.16.0.200 |
| ipv4.dns 8.8.8.8 | DNS0=8.8.8.8 |
| ipv4.dns-search example.com | DOMAlN=example.com |
| ipv4.ignore-auto-dns true | PEERDNS=no |
| connection.autoconnect yes | ONBOOT=yes |
| connection.id eth0 | NAME=eth0 |
| connection.interface-name eth0 | DEVICE=eth0 |
| 802-3-ethernet.mac-address … | HWADDR= … |
范例:nmcli 的基本使用
#查看帮助
? ~ nmcli connection add help
#使用nmcli配置网络
? ~ nmcli connection show
#显示所有活动连接
? ~ nmcli connection show active
#显示网络连接配置
? ~ nmcli connection show "System eth0"
#修改网卡名称(作用在网卡配置文件中的NAME字段)
? ~ nmcli connection modify eth1 con-name "System eth1"
#显示设备状态
? ~ nmcli dev status
#显示网络接口属性
? ~ nmcli connection show eth0
#创建新连接default,IP自动通过DHCP获取
? ~ nmcli connection add con-name default type Ethernet ifname eth0
#删除连接
? ~ nmcli connection del default
#创建新连接static,指定静态IP,不自动连接
? ~ nmcli connection add con-name static ifname eth0 autoconnect no type Ethernet ipv4.addresses 172.16.X.10/24 ipv4.gateway 172.16.X.254
#启用static连接配置
? ~ nmcli connection up static
#启用default连接配置
? ~ nmcli connection up default
#修改连接设置
? ~ nmcli connection mod "static" connection.autoconnect no
? ~ nmcli connection mod "static" ipv4.dns 223.5.5.5
? ~ nmcli connection mod "static" +ipv4.dns 8.8.8.8
? ~ nmcli connection mod "static" -ipv4.dns 8.8.8.8
? ~ nmcli connection mod "static" ipv4.addresses "172.16.X.10/24 172.16.X.254"
#在网卡IP地址的基础上再来添加IP地址
? ~ nmcli connection mod "static" +ipv4.addresses 10.10.10.10/16
#DNS设置存放在/etc/resolve.conf,PEERDNS=no 表示当IP通过DHCP自动获取时,DNS仍是手动设置,不自动获取等价于下面命令
? ~ nmcli coconnectionn mod "System eth0" ipv4.ignore-auto-dns yes
范例:nmcli 生成新的网卡配置文件
~ nmcli connection add con-name eth1-office ipv4.addresses 192.168.1.1/24 \
ipv4.gateway 192.168.1.254 ipv4.method manual type ethernet \
ifname eth1 ipv4.dns 223.5.5.5 +ipv4.dns 223.6.6.6
# 查看配置文件
~ cat /etc/sysconfig/network-scripts/ifcfg-eth-office
# 启动该网卡
~ nmcli connection reload
~ nmcli connection up eth1-office
# 查看网卡信息
~ ip addr show eth1
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:16:73:3f brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global noprefixroute eth1
valid_lft forever preferred_lft forever
inet6 fe80::19a9:320d:30ea:67c0/64 scope link noprefixroute
valid_lft forever preferred_lft forever
4.7.4 nmcli 实现 bonding
#CentOS 7以后的版本使用,CentOS 6以前的版本没有该功能。
#添加bonding接口
# con-name 连接名
# ifname 接口名
nmcli connection add type bond con-name mybond0 ifname bond0 \
mode active-backup ipv4.method manual ipv4.addresses 10.0.0.100/24
#添加从属接口
nmcli connection add type bond-slave ifname eth0 master bond0
nmcli connection add type bond-slave ifname eth1 master bond0
#注意:如无为从属接口提供连接名,则该名称时接口名称加类型构成
#查看连接名
nmcli connection
#要启动绑定,则必须首先启动从属接口
nmcli connection up bond-salve-eth0
nmcli connection up bond-salve-eth1
#启动绑定
nmcli connection up mybond0
4.7.5 网络组 Network Teaming
网络组:是将多个网卡聚合在一起方法,从而实现冗错和提高吞吐量
网络组不同于旧版中bonding技术,提供更好的性能和扩展性。Team 号称是内核里的新技术,在CentOS 7 之后的新的Linux发行版可以考虑使用 Team 网络组技术。
网络组由内核驱动和teamd守护进程实现
多种方式 runner
网络组特点
范例:
#创建网络组接口
nmcli con add type team con-name CNAME ifname INAME [config JSON]
CNAME 连接名
INAME 接口名
JSON 指定runner方式,格式:'{"runner": {"name": "METHOD"}}'
# METHOD 选择需要的模式
#创建port接口
nmcli connection add type team-slave con-rlame CNAME ifname INAME master TEAM
CNAME 连接名,连接名若不指定,默认为team-slave-IFACE
INAME 网络接口名
TEAM 网络组接口名
#断开和启动
nmcli device disconnect INAME
nmc1i connection up CNAME
INAME 设备名 CNAME 网络组接口名或port接口
范例:网络组示例
# 配置的作用域是全局性的
nmcli con add type team con-name myteam0 ifname team0 config '{"runner": {"name" :"loadbalance" }}' \
ipv4.addresses 192.168.1.100/24 ipv4.method manual
# 添加之后就会有192.168.1.100/24地址,是属于虚拟网卡,没有意义。
nmcli connection add con-name team0-eth1 type team-slave ifname eth1 master team0
nmcli connection add con-name team0-eth2 type team-slave ifname eth2 master team0
nmcli connection up team0-eth1
nmcli connection up team0-eth2
nmc1i connection up myteam0
teamdct1 team0 state
ping -I team0 192.168.0.254
nmcli device disconnect eth1
teamdct1 team0 state
nmcli connection up team0-port1
nmcli device disconnect eth2
teamdct1 team0 state
nmcli connection up team0-port2
teamdct1 team0 state
管理网络组配置文件
/etc/sysconfig/network-scripts/ifcfg-team0
DEVICE=team0
DEVICETYPE=Team
TEAM__CONFIG="{\"runner\": { \"name\": \"broadcast\"}}"
BOOTPROTO=none
IPADDR0=172.16.0.100
PREFIX0=24
NAME=team0
ONBOOT=yes
管理网络组配置文件
/etc/sysconfig/network-scripts/ifcfg-team0-eth1
NAME=team0-eth1
DEVICE=eth1
ONBOOT=yes
TEAM_MASTER=team0
DEVICETYPE=TeamPort
删除网络组
nmcli connection delete team0-eth0
nmcli connection delete team0-eth1
nmcli connection delete team0
teamdctl team0 state
nmcli connection show
4.8 网桥
4.8.1 桥接原理
桥接:把一台机器上的若干个网络接口"连接"起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。网桥就是这样一个设备,它有若干个网口,并且这些网口是桥接起来的。与网桥相连的主机就能通过交换机的报文转发而互相通信。实现网络的划分。KVM 就使用该技术。

主机A发送的报文被送到交换机S1的eth0口,由于eth0与eth1、eth2桥接在一起,故而报文被复制到eth1和eth2,并且发送出去,然后被主机B和交换机S2接收到。而S2又会将报文转发给主机C、D。
范例:CentOS 8取消brctl工具,可以用下面方法查看网桥
#查看桥接情况
~ ip link show master virbr0
~ bridge link show
4.8.2 配置实现网桥
工具包: bridge-utils,目前CentOS 8无此包。
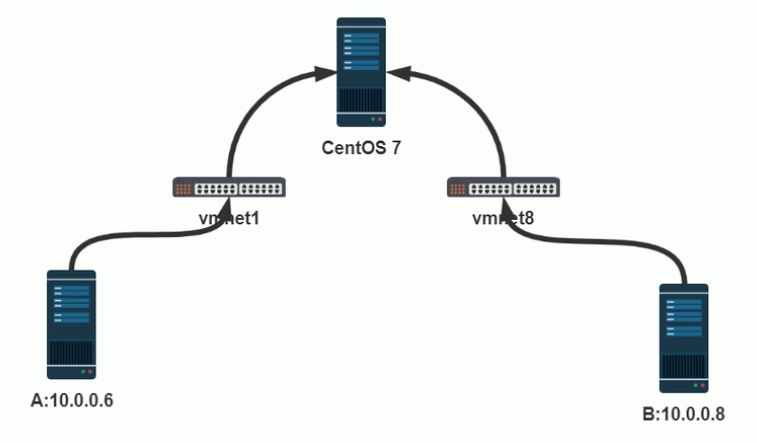
CentOS 7是主机,默认情况下是无法起到Hub,或者交换机的功能;所以默认情况下,收到目的地址不是主机IP地址的数据包,就会丢弃。
桥接设备的IP地址并没有关系。
yum install bridge-utils -y
#查看网桥
brctl show
#查看CAM(content addressable memory内容可寻址存储器)表
brctl showmacs br0
#添加和删除网桥
brctl addbr br0 | brctl delbr br0
#添加和删除网桥中的网卡
brctl addif br0 eth0 | brctl delbr br0 eth0
ip link | ip addr
#默认br0,是down,必须启用
ifconfig br0 up
ip link set br0 up
#启用STP
brctl show
brctl stp br0 on
brctl show
#以上操作都是临时生效,重启系统将丢失配置
范例:brctl 命令创建软件网桥
# 创建网桥(类似于交换机)
brctl addbr br0
# 将接口加入到网桥中
brctl addif br0 eth0
brctl addif br0 eth1
# 查看网桥的MAC表
brctl showmacs br0
# 启用br0
ip link set br0 up
# 为br0配置管理接口
ip address add 10.0.0.111/24 dev br0
# 查看网桥所连接的信息
$ brctl show
bridge name bridge id STP enabled interfaces
br0 8000.000c291380be no eth0
eth1
注意:NetworkManager只支持以太网接口接口连接到网桥,不支持聚合接口
范例:nmcli 命令创建软件网桥
nmcli connection add con-name mybr0 type bridge ifname br0
nmcli connection modify mybr0 ipv4.addresses 10.0.0.100/24 ipv4.method manual
nmcli connection add con-name br0-port0 type bridge-slave ifname eth0 master br0
查看配置文件
cat /etc/sysconfig/network-scripts/ifcfg-br0
cat /etc/sysconfig/network-scripts/ifcfg-br0-port0
范例:nmcli 实现
#1创建网桥
#nmcli默认会开启stp生成树协议
nmcli con add type bridge con-name br0 ifname br0
#(可选)网桥可以不加地址,添加地址为了方便管理
nmcli connection modify br0 ipv4.addresses 10.0.0.100/24 ipv4.method manual
nmcli connection up br0
#2加入物理网卡
nmcli connection add type bridge-slave con-name br0-port0 ifname eth0 master br0
nmcli connection add type bridge-slave con-name br0-port1 ifname eth1 master br0
nmcli con up br0-port0
nmcli con up br0-port1
#3查看网桥配置文件
cat/etc/sysconfig/network-scripts/ifcfg-br0
DEVICE=br0
STP=yes
TYPE=Bridge
BOOTPROTO=static
IPADDR=10.0.0.100
PREFIX=24
cat /etc/sysconfig/network-scripts/ifcfg-br0-port0
TYPE=Ethernet
NAME=br0-port0
DEVICE=eth0
ONBOOT=yes
BRIDGE=br0
UUID=23f41d3b-b57c-4e26-9b17-d5f02dafd12d
#4安装管理软件包
yum install -y bridge-utils
brctl show
#5删除br0
nmcli con down br0
rm /etc/sysconfig/network-scripts/ifcfg-br0*
nmcli con reload
4.8.3 网络相关术语
4.8.3.1 广播风暴:
广播风暴(broadcast storm)简单的讲是指当广播数据充斥网络无法处理,并占用大量网络带宽,导致正常业务不能运行,甚至彻底瘫痪,这就发生了“广播风暴”。一个数据帧或包被传输到本地网段 (由广播域定义)上的每个节点就是广播;由于网络拓扑的设计和连接问题,或其他原因导致广播在网段内大量复制,传播数据帧,导致网络性能下降,甚至网络瘫痪,这就是广播风暴。
4.8.3.2 生成树STP:
STP(Spanning Tree Protocol)是生成树协议的英文缩写,可应用于计算机网络中树形拓扑结构建立,主要作用是防止网桥网络中的冗余链路形成环路工作。但某些特定因素会导致STP失败,要排除故障可能非常困难,这取决于网络设计 。生成树协议适合所有厂商的网络设备,在配置上和体现功能强度上有所差别,但是在原理和应用效果是一致的。
是一种工作在OSI网络模型中的第二层(数据链路层)的通信协议,基本应用是防止交换机冗余链路产生的环路.用于确保以太网中无环路的逻辑拓扑结构.从而避免了广播风暴,大量占用交换机的资源。
功能:
生成树协议的主要功能有两个:一是在利用生成树算法、在以太网络中,创建一个以某台交换机的某个端口为根的生成树,避免环路。二是在以太网络拓扑发生变化时,通过生成树协议达到收敛保护的目的。
特点:
(1)生成树协议提供一种控制环路的方法。采用这种方法,在连接发生问题的时候,你控制的以太网能够绕过出现故障的连接。
(2)生成树中的根桥是一个逻辑的中心,并且监视整个网络的通信。最好不要依靠设备的自动选择去挑选哪一个网桥会成为根桥。
(3)生成树协议重新计算是繁冗的。恰当地设置主机连接端口(这样就不会引起重新计算),推荐使用快速生成树协议。
(4)生成树协议可以有效的抑制广播风暴。开启生成树协议后抑制广播风暴,网络将会更加稳定,可靠性、安全性会大大增强。
4.9 网络测试诊断工具
4.9.1 fping
fping是一个程序,用于将ICMP探测发送到网络主机,类似于ping, fping的历史由来已久:Roland schemers在1992年确实发布了它的第一个版本,从那时起它就确立了自己的地位,成为网络诊断和统计的标准工具
相对于ping多个主机时性能要高得多。fping完全不同于ping,可以在命令行上定义任意数量的主机,或者指定包含要ping的IP地址或主机列表的文件,常在she脚本中使用
CentOS中由EPEL源提供
官网:http://www.fping.org/
~ yum install -y fping
~ fping 10.0.0.22
10.0.0.22 is alive
~ echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
~ fping 10.0.0.22
10.0.0.22 is unreachable
#fping可以多个地址
~ fping 10.0.0.22 139.198.105.99
139.198.105.99 is alive
10.0.0.22 is unreachable
#-g 选项可以指定网段或者地址范围
~ fping -g 10.0.0.0/24
~ fping -g 10.0.0.5 10.0.0.10
#对文件中的主机进行测试
~ tee hosts.txt <<-'EOF'
10.0.0.7
10.0.0.6
EOF
~ fping < hosts.txt
~ fping -s < hosts.txt
4.9.2 tcpudmp
tcpdump详细教程
tcpdump是一个用于截取网络分组,并输出分组内容的工具。凭借强大的功能和灵活的截取策略,使其成为类UNIX系统下用于网络分析和问题排查的首选工具
tcpdump 支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息
网络数据包截获分析工具。支持针对网络层、协议、主机、网络或端口的过滤。并提供and、or、not等逻辑语句帮助去除无用的信息。
tcpdump只能抓取流经本机的数据包

语法:
tcpdump [-adeflnNOpqStvx][-c<数据包数目>][-dd][-ddd][-F<表达文件>][-i<网络界面>][-r<数据包文件>][-s<数据包大小>][-tt][-T<数据包类型>][-vv][-w<数据包文件>][输出数据栏位]
参数说明:
-a 尝试将网络和广播地址转换成名称。
-c <数据包数目> 收到指定的数据包数目后,就停止进行倾倒操作。
-d 把编译过的数据包编码转换成可阅读的格式,并倾倒到标准输出。
-dd 把编译过的数据包编码转换成C语言的格式,并倾倒到标准输出。
-ddd 把编译过的数据包编码转换成十进制数字的格式,并倾倒到标准输出。
-e 在每列倾倒资料上显示连接层级的文件头。
-f 用数字显示网际网络地址。
-F <表达文件> 指定内含表达方式的文件。
-i <网络接口> 使用指定的网络截面送出数据包。
-l 使用标准输出列的缓冲区。
-n 不把主机的网络地址转换成名字。
-nn:除了-n的作用外,还把端口显示为数值,否则显示端口服务名。
-N 不列出域名。
-O 不将数据包编码最佳化。
-p 不让网络界面进入混杂模式。
-q 快速输出,仅列出少数的传输协议信息。
-r<数据包文件> 从指定的文件读取数据包数据。
-s<数据包大小> 设置每个数据包的大小。
-S 用绝对而非相对数值列出TCP关联数。
-t 在每列倾倒资料上不显示时间戳记。
-tt 在每列倾倒资料上显示未经格式化的时间戳记。
-T <数据包类型> 强制将表达方式所指定的数据包转译成设置的数据包类型。
-v :详细显示指令执行过程。
-vv : 更详细显示指令执行过程。
-vvv:产生比-vv更详细的输出。
-x :用十六进制字码列出数据包资料。
-XX:输出包的头部数据,会以16进制和ASCII两种方式同时输出,更详细。
-w <数据包文件>:把数据包数据写入指定的文件。
范例:
#查看网卡
~ tcpdump -D
1.virbr0
2.bluetooth0 (Bluetooth adapter number 0)
3.nflog (Linux netfilter log (NFLOG) interface)
4.nfqueue (Linux netfilter queue (NFQUEUE) interface)
5.usbmon1 (USB bus number 1)
6.usbmon2 (USB bus number 2)
7.ens33
8.any (Pseudo-device that captures on all interfaces)
9.lo [Loopback]
#不指定任何参数,监听第一块网卡上经过的数据包,主机可能有不止一块网卡,所以经常需要指定网卡
tcpdump
#监听特定网卡
tcpdump -i eth0
#监听10.0.0.100的通信包,注意:出、入的包都会被监听
tcpdump host 10.0.0.100
#特定来源、目标地址的通信
#特定来源
tcpdump src host hostname
#特定目标地址
tcpdump dst host hostname
#如果不指定src跟dst,那么来源或者目标是hostname的通信都会被监听
tcpdump host hostname
#面试题:
tcpdump -i eth0 -nn icmp and src host 10.0.0.6 and dst host 10.0.0.7
#特定端口
tcpdump port 3000
#监听TCP/UDP,服务器上不同服务分别用了TCP,UDP作为传输层,假如只想监听TCP的数据包
tcpdump tcp
#来源主机+端口+TCP,监听来自主机10.0.0.100在端口22上的TCP数据包
tcpdump tcp port 22 and src host 10.0.0.100
#监听特定主机之间的通信
tcpdump ip host 10.0.0.101 and 10.0.0.102
#10.0.0.101和除了10.0.0.1之外的主机之间的通信
tcpdump ip host 10.0.0.101 and ! 10.0.0.1
#详细示例:
tcpdump tcp -i eth1 t -g 0 -c 100 and dst port ! 22 and src net 192.168.1.0/24 -w ./target.cap
(1)tcp: ip icmp arp rarp和tcp、udp、icmp这些选项等都要放到第一个参数的位置,用来过滤数据报的类型
(2)-i eth1 :只抓经过接口eth1的包
(3)-t :不显示时间戳
(4)-s 0:抓取数据包时默认抓取长度为68字节。加上-s 0后可以抓到完整的数据包
(5)-c 100 :只抓取100个数据包
(6)dst port ! 22 :不抓取目标端口是22的数据包
(7)src net 192.168.1.0/24 :数据包的源网络地址为192.168.1.0/24
(8)-w ./target.cap :保存成cap文件,方便用wireshark分析
#限制抓包的数量,如下,抓到1000个包后,自动推出
tcpdump -c 1000
#保存到本地,tcpdump默认会将输出写到缓存区中,只有缓存区内容达到一定的大小,或者tcpdump推出时,才会将输出写到本地磁盘,可以加上-U强制
#立即写到本地磁盘(一般不建议,性能相对较差)
tcpdump -n -vvv -c 1000 -w /tmp/tcpdump_save.cap
范例:tcpdump示例
#默认情况下,直接启动tcpdump将监视第一个网络接口(非lo口)上所有流通的数据包。这样抓取的结果会非常多,滚动非常快。
tcpdump
#监视指定网络接口的数据包
tcpdump -i eth0
#监视指定主机的数据包,例如所有进入或离开node1的数据包
tcpdump -i eth0 host node1
#打印node1<-->node2或node1<-->node3之间通信的数据包
tcpdump -i eth0 host node1 and \( node2 or node3 \)
#打印node1与任何其他主机之间通信的IP数据包,但不包括与node4之间的数据包
tcpdump -i eth0 host node1 and not node4
#截获主机node1 发送的所有数据
tcpdump -i eth0 src host node1
#监视所有发送到主机node1 的数据包
tcpdump -i eth0 dst host node1
#监视指定主机和端口的数据包
tcpdump -i eth0 host node1 and port 8080
#监视指定网络的数据包,如本机与192.168网段通信的数据包,"-c 10"表示只抓取10个包
tcpdump -i eth0 -c 10 port 8080 net 192.168
#打印所有通过网关snup的ftp数据包
tcpdump 'gateway snup and (port ftp or ftp-data)'
##注意,表达式被单引号括起来了,这可以防止shell对其中的括号进行错误解析
#抓取ping包
tcpdump -i eth0 -nn icmp -c 5
#指定主机抓ping包
tcpdump -i eth0 -nn icmp -c 5 and src host 192.168.10.100
#抓取到本机22端口包
tcpdump -i eth0 dst port 22 -c 10 -nn
#解析包数据
tcpdump -i eth0 -c 2 -q -XX -vvv -nn tcp dst port 22
4.9.3 nmap
扫描远程主机工具,功能远超越用世人皆知的Ping工具发送简单的ICMP回声请求报文。探测主机是否存活的工具
官方帮助:https://nmap.org/book/man.html
格式:
nmap [scan Type(s)][options] {target specification}
命令选项
-sT TCP connect() 扫描,这是最基本的 TCP扫描方式。这种扫描很容易该检测到,在目标主机的日志中会记录大批的连接请求以及错误信息
-ss TCP 同步扫描(TCP SYR),因为不必全部打开一个TP连接,所以这项技术通常称为半开扫描(half-open)。这项技术最大的好处是,很少有系统能够把这记入系统日志
-sF,sX,-sN 秘密FIN数据包扫描、圣诞树(xmas Tree)、空(Nu11)扫描模式。这些扫描方式的理论依据是:关闭的嫌口需要对你的探测包回应RST包,而打开的端口必需忽略有问题的包
-sping 扫描,用ping方式检查网络上哪些主机正在运行。当主机阻塞工CP echo 请求包是ping 扫描是无效的。nmap在任何情况下都会进行 ping .扫描,只有目标主机处于运行状态,才会进行后续的扫描
-sU UDP的数据包进行扫描,想知道在某台主机上提供哪些UDP服务,可以使用此选项
-sA ACK扫描,这项高级的扫描方法通常可以用来穿过防火墙。
-sw 滑动窗口扫描,非常类似于ACK的扫描
-sR RPC扫描,和其它不同的端口扫描方法结合使用。
-b FTP反弹攻击(bounce attack),连接到防火墙后面的一台FTP服务器做代理,接着进行端口扫描。
-P0 在扫描之前,不 ping主机。
-PT 扫描之前,使用TCP ping 确定哪些主机正在运行
-pS 对于root 用户,这个选项让nmap使用SYN 包而不是ACK包来对目标主机进行扫描。
-I 设置这个选项,让nmap使用真正的 ping(IcMp echo 请求〉来扫描目标主机是否正在运行。
-PB 这是默认的ping 扫描选项。它使用 AK(-PT)和IONP(-PI)两种扫描类型并行扫描。如果防火墙能够过滤其中一种包,使用这种方法,你就能够穷过防M箭⑤:
-O 这个选项激活对TCP/IP指纹特征(fingerprinting)的扫描,获得远程主机的标志,也就是操作系统类型
-I 打开nmap的反向标志扫描功能。
-f 使用碎片IP数据包发送SYN、FIN、XMAS、NULL。包增加包过滤、入侵检测系统的难度,使其无法知道你的企图
-v 冗余模式。强烈推荐使用这个选项,它会给出扫描过程中的详细信息。
-5 <IP> 在一些情况下,nmap可能无法确定你的源地址。在这种情况使用这个选项给出指定IP地址
-g port 设置扫描的源端口
-oN 把扫描结果重定向到一个可读的文件logfilename中
-oS 扫描结果输出到标准输出。
--host_timeout 设置扫描一台主机的时间,以毫秒为单位。默认的情况下,没有超时限制
--max_rtt_timeout 设置对每次探测的等待时间,以毫秒为单位。如果超过这个时间限制就重传或者超时。默认值是大约9000毫秒
--min_rtt_timeout 设置nmap对每次探测至少等待你指定的时间,以毫秒为单位
-M count 只进行TCP connect()扫描时,最多使用多少个套接字进行并行的扫描
##设置时间模板
简单来说就是调整你的扫描时间等级,数字越大时间越快,但是相应就要牺牲一些别的东西。
-T0:paranoid,可以避免IDS报警,速度最慢,一个时间扫描一个端口,每个探测报文的发送间隔为5分钟。
-T1:sneaky,可以避免IDS报警,速度很慢,探测报文发送间隔为15s。
-T2:polite,降低了扫描速度从而可以使用更少的带宽和目标主机资源,速度较慢,探测报文发送间隔为0.4s。
-T3:normal,正常模式,未作任何改变和优化。
-T4:aggressive,假设用户具有合适及可靠的网络从而加速扫描,针对TCP端口禁止动态扫描延迟超过10ms,一般如果扫描可靠的网络使用这个较好。
-T5:insane,假设用户拥有特别快的网络或者为了速度可以牺牲准确性等其他因素,可能会使目标主机崩溃。
##扫描目标的选择相关选项
-iL :从一个文件中输入你的扫描目标信息(IP地址,主机名,CIDR,IPv6,或者八位字节范围),文件中的每一项必须以一个或多个空格,制表符或换行符分开。比如你创建了一个文件test.txt,里面输入了用换行符分开的一些IP地址,那么你就可以输入nmap命令nmap -iL test.txt来扫描文件中的目标。
-iR :随机生成个的目标进行扫描,如果hostnum是0,则代表永无止尽的随机扫描,慎用慎用!!。
--exclude <host1[,host2][,host3],...>:排除主机/网络,如果在你扫描过程中有一些网络/主机不是你想扫描的,那么就使用这个命令进行排除,举个例子,比如我的test.txt有3个IP地址,现在我不想对其中的192.168.1.121进行扫描,那么我就可以输入nmap命令nmap -iL test.txt --exclude 192.168.1.121。
--excludefile :排除文件中的主机/网络列表,原理和上面类似,如果我现在在test.txt中有一些IP地址不想扫描,那么我们可以把它们放在exclude.txt中并用适当的分隔符进行分割,举个例子就是nmap -iL test.txt --excludefile exclude.txt。
##主机/网络的发现和探测
可以理解为平时我们的ping命令,但是这里nmap有更多别的五花八门的方法来实现我们的“ping”。
-sL:列出指定网络上的每台主机,不发送任何报文到目标主机,例如nmap -sL 192.168.1.1,当然很多网络都对这个做了防护措施,或许你并扫不出来什么。
-sn:无端口扫描,也就是ping扫描,仅仅可以探测出目标是否可达,例如nmap -sn 192.168.1.112,早一些的版本这个命令叫-sP,在局域网内,该扫描可能并不会发送ICMP报文,而是会广播ARP报文。
--dns-servers:指定DNS服务器来进行端口扫描,指定一个或者多个dns服务器可以让你的扫描更快,例如nmap --dns-servers xxx.xxx.xxx.xxx -sn 192.168.1.112。
##扫描方式
-sT:TCP全连接扫描,主机会与目标端口进行三次握手,建立完整的TCP连接,这种方式扫描速度慢,网络流量大,容易被发现,例如nmap -sT 192.168.1.112。
-sS:TCP SYN扫描,主机向目标端口发送SYN报文,如果目标端口返回了[ACK,SYN],主机发送RST直接断开,这种扫描方式速度较快,被广泛使用,例如nmap -sS 192.168.1.112。
-sA:TCP ACK扫描,主机向目标端口发送ACK报文,如果目标端口返回了RST,则说明目标端口开放,该方式可以用来绕过防火墙,例如nmap -sA 192.168.1.112。
-sU:UDP扫描,通过向端口发送UDP数据包来判断开启了哪些UDP服务,UDP扫描通常比TCP扫描要慢,你可以将UDP扫描与TCP扫描同时进行,例如nmap -sS -sU 192.168.1.112。
-sN-sF-sX:这是三种秘密扫描方式,分别为NULL扫描,FIN扫描和Xmas扫描扫描,它们相对比较隐蔽,除了探测报文的标志位不同,这三种扫描在行为上完全一致。如果收到一个RST报文,该端口被认为是关闭的,而没有响应则意味着端口是开放或者被过滤的,这些扫描可以结合--scanflags进行使用,它的参数可以是URG,ACK,PSH,RST,SYN等。
##扫描端口设置
-p:设置扫描端口范围,设置扫描端口范围有多种方式,比如nmap -sS -p 1-65535 192.168.1.112代表扫描1到65535这些端口。当然你也可以根据不同的协议指定的更细一点,比如nmap -sS -p U:53,111,137,T:21-25,80,139,8080 192.168.1.112代表扫描UDP的53,111,137端口和TCP的21到25,80。。。等端口,其中T代表TCP, U代表UDP, S代表SCTP, P代表IP协议。\
--exclude-ports :设置扫描要排除的端口,用法和上面类似,例如nmap -sS -p 1-65535 --exclude-ports 3306 192.168.1.112。
-F:快速扫描,这里按照nmap内置的最常用端口表进行扫描,扫描数量比默认的更少,时间也会更短一些,例如nmap -sS -F 192.168.1.112。
-r:正常情况下,为了扫描效率,端口扫描的顺序是随机的,这个参数可以让扫描顺序按照由低到高的顺序进行扫描,例如nmap -sS -r 192.168.1.112。
--top-ports :扫描nmap的端口表里最常见的前n个端口,例如nmap -sS --top-ports 10 192.168.1.105。
##版本与操作系统探测
-sV:检测目标运行的服务版本,例如nmap -sV 192.168.1.105,它会检测出目标主机端口号所运行的服务或软件的版本
-O:检测目标操作系统,例如nmap -O 192.168.1.105
##扫描时间设置
--host-timeout :由于性能较差或不可靠的网络硬件或软件、带宽限制、严格的防火墙等原因,一些主机需要很长的时间扫描。这些极少数的主机扫描往往占据了大部分的扫描时间。因此,最好的办法是减少时间消耗并且忽略这些主机,使用--host-timeout选项来说明等待的时间(毫秒)。
--scan-delay :调整探测报文的时间间隔,将它设置小可以用来躲避防火墙。
##其他常用设置
-v:提高输出信息的详细程度
-A:启动强力扫描模式,该模式下会默认启动操作系统检测(-O) 和版本扫描(-sV)
-6:启用IPv6扫描
范例:
#TCP ack扫描,并发2000,速度快
~ nmap -n -pA --min-parallelism 2000 172.16.0.0/16
#仅列出指定网段的每台主机,不发送任何报文到目标主机
~ nmap -sL 10.0.0.0/24
#可以指定一个IP地址范围
~ nmap -sP 10.0.0.1-10
#批量扫描一个网段的主机存活数
~ nmap -sP -v 192.168.1.0/24
~ nmap -v -sn <IP地址>/24
#有些主机关闭了ping检测,所以可以使用-P0跳过ping的探测,可以加快扫描速度
~ nmap -P0 192.168.1.100
#扫描主机
~ nmap -v -A <IP地址>
#一次性扫描多台目标主机
~ nmap 10.0.0.6 10.0.0.7
#从一个文件中导入IP地址,并进行扫描
~ cat hosts.txt
10.0.0.6
10.0.0.7
58.87.87.99
~ nmap -iL hosts.txt
#探测目标主机开放的端口,可以指定一个以逗号分隔的端口列表(如-PS22,443,80)
~ nmap -PS22,443,80 10.0.0.1
#使用SYN半开放扫描
~ nmap -sS 10.0.0.1
#扫描开放了TCP端口的设备
~ nmap -sT 10.0.0.1
#扫描开放了UDP端口的设备
~ nmap -sU 10.0.0.1
#只扫描UDP端口
~ nmap -e eth1 -sU -O 10.0.0.1
#扫描了TCP和UDP的端口
~ nmap -e eth1 -sU -sT -O 10.0.0.1
~ nmap -sU -sT -p0-65535 10.0.0.1
#探测所有列出的目标主机端口
nmap -PS22,80,3306 10.0.0.1
#探测目标主机操作系统类型
nmap -O10.0.0.1
#探测目标主机操作系统类型
nmap -A 10.0.0.1
5 Ubuntu 网络配置
参考网址:路由协议基础 - 华为
网关Gateway:如果网络和当前设备同一网段,Gateway 为空;如果不在同一个网段,下一个路由器临近当前设备的接口IP地址
路由表组成:四个组成部分
- 目标网络Destination:目标主机所在的网络ID
- 子网掩码Netmask:目标网络的子网掩码
- 接口lface:当前网络设备的出口
- 网关Gateway:下一个路由器的邻近当前路由器的接口IP,下一跳Next Hop
- 开销Metric、Cost:费用,值越小,优先级越高
直连路由,网关不需要配置。直连路由自动生成。
0.0.0.0 默认路由,当路由表的所有路由都不匹配的时候就会走默认路由 default
路由协议缺省时的外部优先级
| 路由协议的类型 | 路由协议的外部优先级 |
|---|---|
| Direct | 0 |
| OSPF | 10 |
| IS-IS | 15 |
| Static | 60 |
| RIP | 100 |
| OSPF ASE | 150 |
| OSPF NSSA | 150 |
| IBGP | 255 |
| EBGP | 255 |
路由协议内部优先级
| 路由协议的类型 | 路由协议的内部优先级 |
|---|---|
| Direct | 0 |
| OSPF | 10 |
| IS-IS Level-1 | 15 |
| IS-IS Level-2 | 18 |
| Static | 60 |
| RIP | 100 |
| OSPF ASE | 150 |
| OSPF NSSA | 150 |
| IBGP | 200 |
| EBGP | 20 |
5.1 主机名
修改主机名
~ hostnamectl set-hostname ubuntu2004-clone.kubesphere.io
~ cat /etc/hostname
ubuntu2004-clone.kubesphere.io
~ hostname
ubuntu2004-clone.kubesphere.io
~ echo $HOSTNAME
ubuntu2004-server
~ exit
logout
$~ sudo -i
$ echo $HOSTNAME
ubuntu2004-clone.kubesphere.io
扩展:Ubuntu系统运行root远程登录系统
(1)vim /etc/ssh/sshd_config
PermitRootLogin yes
(2)systemctl restart sshd
(3)passwd root
生产环境中尽量不要使用root用户登录
5.2 网卡名称
默认ubuntu的网卡名和CentOS7类似,如:ens33,ens38等。
修改网卡名称为传统命名方式:
#修改配置文件为下面形式
[root@ubuntu2004-server ~]# vim /etc/default/grub
GRUB_CMDLINE_LINUX="net.ifnames=0"
#或者sed修改
~ sed -i.bak -r '/^GRUB_CMDLINE_LINUX=/s#"$#net.ifnames=0"#' /etc/default/grub
~ sed -i.bak -r '/^GRUB_CMDLINE_LINUX=/c\GRUB_CMDLINE_LINUX="net.ifnames=0"' /etc/default/grub
#生效新的grub.cfg文件
~ grub-mkconfig -o /boot/grub/grub.cfg
#或者
~ update-grub
~ grep net.ifnames /boot/grub/grub.cfg
linux /vmlinuz-5.4.0-117-generic root=UUID=fd454862-6eba-4ce2-a6bd-10532bdcaa46 ro net.ifnames=0 maybe-ubiquity
linux /vmlinuz-5.4.0-117-generic root=UUID=fd454862-6eba-4ce2-a6bd-10532bdcaa46 ro net.ifnames=0 maybe-ubiquity
linux /vmlinuz-5.4.0-117-generic root=UUID=fd454862-6eba-4ce2-a6bd-10532bdcaa46 ro recovery nomodeset dis_ucode_ldr net.ifnames=0
linux /vmlinuz-5.4.0-113-generic root=UUID=fd454862-6eba-4ce2-a6bd-10532bdcaa46 ro net.ifnames=0 maybe-ubiquity
linux /vmlinuz-5.4.0-113-generic root=UUID=fd454862-6eba-4ce2-a6bd-10532bdcaa46 ro recovery nomodeset dis_ucode_ldr net.ifnames=0
#重启生效
reboot
5.3 Ubuntu网络配置
官网文档:
https://help.ubuntu.com/
https://ubuntu.com/server/docs/network-configuration
5.3.1 配置自动获取IP
网卡配置文件采用YAML格式(缩进严格,缩进的空格数一致),必须以 /etc/netplan/xxx .yaml 文件命名方式存放
可以每个网卡对应一个单独的配置文件,也可以将所有网卡都放在一个配置文件里
范例:
~ cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
renderer: networkd
ethernets:
eth0:
dhcp4: yes
version: 2
修改网卡配置文件后需要执行命令生效:
~ netplan apply
5.3.2 配置静态IP
范例:配置静态IP
~ cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
eth0:
addresses:
- 10.0.0.30/24
gateway4: 10.0.0.2
nameservers:
addresses: [114.114.114.114,8.8.8.8]
search:
- Ubuntu2004-Server
version: 2
~ cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
eth0:
addresses: [192.168.10.10/24,10.0.0.10/8] #或者用下面两行,两种格式不能混用
- 192.168.10.10/24
- 10.0.0.10/8
gateway4: 10.0.0.2
nameservers:
addresses: [114.114.114.114,8.8.8.8]
search: [Ubuntu2004-Server,kubesphere.io] #或者用下面两行,两种格式不能混用
- Ubuntu2004-Server
- kubesphere.io
version: 2
查看IP和Gateway
~ ip addr
~ route -n
查看DNS(DNS最多可以添加三个)
~ ls -l /etc/resolv.conf
lrwxrwxrwx 1 root root 39 Feb 1 2021 /etc/resolv.conf -> ../run/systemd/resolve/stub-resolv.conf
~ grep -Ev "^(#|$)" /etc/resolv.conf
#使用以下命令进行替代
~ resolvectl status
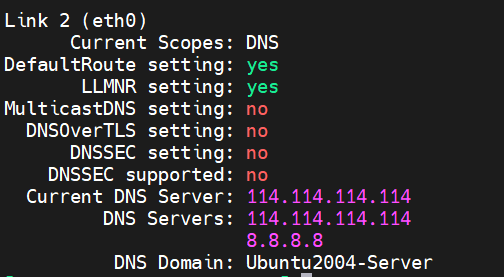
5.3.3 配置多网卡静态IP和静态路由
~ vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
dhcp6: no
addresses: [10.0.0.100/16]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5,223.6.6.6]
eth1:
dhcp4: no
dhcp6: no
addresses: [10.20.0.100/16]
routes:
- to: 10.30.0.0/16
via: 10.20.0.1
- to: 10.40.0.0/16
via: 10.20.0.1
- to: 10.50.0.0/16
via: 10.20.0.1
- to: 10.60.0.0/16
via: 10.20.0.1
~ netplan apply
~ route -n
#或者每个网卡各自一个配置文件
~ ls /etc/netplan/
01-netcfg.yaml 02-netcfg.yaml
~ cat /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: yes
~ cat /etc/netplan/02-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth1:
addresses:
- 10.20.0.100/16
- 192.168.0.100/24
gateway4: 10.20.0.2
nameservers:
search: [kubesphere.io, kubesphere.com]
addresses: [223.5.5.5,223.6.6.6]
routes:
- to: 10.30.0.0/16
via: 10.20.0.1
- to: 10.40.0.0/16
via: 10.20.0.1
- to: 10.50.0.0/16
via: 10.20.0.1
- to: 10.60.0.0/16
via: 10.20.0.1
5.3.4 单网卡桥接
~ apt install -y bridge-utils
~ dpkg -L bridge-utils
#三个网卡配置使用一个配置文件
~ cat /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: yes
eth1:
dhcp4: no
dhcp6: no
eth2:
dhcp4: no
bridges:
br0:
dhcp4: no
dhcp6: no
addresses: [10.0.0.18/16]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5,223.6.6.6]
interfaces:
- eth0
- eth1
#桥接配置单独一个文件
~ cat /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth1:
dhcp4: no
dhcp6: no
eth2:
dhcp4: no
bridges:
br0:
dhcp4: no
dhcp6: no
addresses: [10.0.0.18/16]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5,223.6.6.6]
interfaces:
- eth0
- eth1
~ netplan apply
~ ifconfig br0
~ brctl show
5.3.5 多网卡桥接
~ cat /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
dhcp6: no
eth1:
dhcp4: no
dhcp6: no
bridges:
br0:
dhcp4: no
dhcp6: no
addresses: [10.0.0.18/16]
gateway4: 10.0.0.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
interfaces:
- eth0
br1:
dhcp4: no
dhcp6: no
addresses: [10.10.0.18/16]
routes:
- to: 10.30.0.0/16
via: 10.20.0.1
- to: 10.40.0.0/16
via: 10.20.0.1
- to: 10.50.0.0/16
via: 10.20.0.1
- to: 10.60.0.0/16
via: 10.20.0.1
interfaces:
- eth1
~ netplan apply
~ brctl show
~ ifconfig br0 | ifconfig br1
~ routes
5.3.6 双网卡绑定
支持多网卡绑定方式
bond聚合链路模式共7种模式:0-6 Mode
- mod=0,即:(balance-rr)Round-robin policy(轮间)聚合口数据报文按包轮询从物理接口转发。
负载均衡─所有链路处于负载均衡状态,轮询方式往每条链路发送报文这模式的特点增加了带宽,同时支持容错能力,当有链路出问题,会把流量切换到正常的链路上。
性能问题——个连接或者会话的数据包如果从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降。Bond0在大压力的网烙传输下,性能增长的并不是很理想。
需要交换机进行端口绑定
- mod=1,即: (active-backup) Active-backup policy (主-备份策略)只有Active状态的物理接口才转发数据报文。
容错能力一只有一个slave是激活的(active)。也就是说同一时刻只有一个网卡处于工作状态,其他的slave都处于备份状态,只有在当前激活的slave故障后才有可能会变为激活的(active)。
无负载均衡一此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有N个网络接口的情况下,资源利用率为1/N。
- mod=2,即: (balance xoar) XOR policy (平衡策略)聚合口数据报文按源目MAC、源目IP、源目端口进行异或HASH运算得到一个值,根据该值查找接口转发数据报文
负载均衡一基于指定的传输HASH策略传输数据包。
容错能力一这模式的特点增加了带宽,同时支持容错能力,当有链路出问题,会把流量切换到正常的链路上。
性能问题―该模式将限定流量,以保证到达特定对端的流量总是从同一个接口上发出。既然目的地是通过MAC地址来决定的,因此该模式在’本地"网络配置下可以工作得很好。如果所有流最是通过单个路由器,由于只有一个网关,源和目标mac都固定了,那么这个算法算出的线路就一直是同一条,那么这种模式就没有多少意义了。
需要交换机配置为port channel
- mod=3,即: broadcast(广播策略)这种模式的特点是一个报文会复制两份往bond下的两个接口分别发送出去
当有对端交换机失效,感觉不到任何downtime,但此法过于浪费资源;不过这种模式有很好的容错机制。此模式适用于金融行业,因为他们需要高可靠性的网络。不先评出现任何问题。
- mod=4,即:(802.3ad) IEEE 802.3ad Dynamic link aggregation (IEEE 802.3ad 动态链接聚合)
在动态聚合模式下,聚合组内的成员端口上均启用LACP(链路汇聚控制协议)协议,其端口状态通过该协议自动进行维护。负载均衡一基于指定的传输HASH策略传输数据包。默认算法与blance-xor一样。
容错能力一这模式的特点增加了带宽,同时支持容错能力,当有链路出问题,会把流量切换到正常的链路上,对比blance-xor,这种模式定期发送LACPD报文维护镞路聚合状态,保证链路质量。
需要交换机支持LACP协议
- mod=5,即:(balance-tlb) Adaptive transmit load balancing(适配器传输负载均衡)
在每个物理接口上根据当前的负载(根据速度计算)分配外出流量。如果正在接收数据的物理接口口出故障了,另一个物理接口接管该故障物理口的MAC地址。
需要ethtool支持获取每个slave的速率
- mod=6,即:(balance-alb)Adaptive load balancing(适配器适应性负载均衡)
该模式包含了balance-tb模式,同时加上针对IPV4流量的接收负载均衡,而且不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的。bonding驱动截获本机发送的ARP应答,并把源硬件地址改写为bond中某个物理接口的难一硬件地址,从而便得不同的对端使用不同的硬件地址进行通信。
mod=6 与 mod=0的区别: mod=6,先把eth0流量占满,再占eth1 …ethX;而mod=0的话,会发现2个口的流虽都很稳定,基本一样的带宽。而mod=6,会发现第一个口流是很高,第2个口只占了小部分流量。
~ vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
dhcp6: no
eth1:
dhcp4: no
dhcp6: no
bonds:
bond0:
interfaces:
- eth0
- eth1
addresses: [10.0.0.18/16]
gateway4: 10.0.0.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
parameters:
mode: active-backup
mii-monitor-interval: 100
~ netplan apply
~ ifconfig bond0
~ ifconfig eth0
~ ifconfig eth1
~ cat /proc/net/bonding/bond0
5.3.7 双网卡绑定+桥接
网卡绑定用于提供网卡接口冗余以及高可用和端口聚合功能,桥接网卡再给需要桥接设备的服务使用
~ vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
dhcp6: no
eth1:
dhcp4: no
dhcp6: no
bonds:
bond0:
interfaces:
- eth0
- eth1
parameters:
mode: active-backup
mii-monitor-interval: 100
bridges:
br0:
dhcp4: no
dhcp6: no
addresses: [10.0.0.18/16]
gateway4: 10.0.0.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
interfaces:
- bond0
~ netplan apply
~ brctl show
~ ifconfig br0
~ route -n
~ ifconfig
5.3.8 网卡的多组绑定
可以实现网卡的多组绑定,比如: eth0,eth1绑定至bond0,eth2和eth3绑定bond1
~ vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
dhcp6: no
eth1:
dhcp4: no
dhcp6: no
eth2:
dhcp4: no
dhcp6: no
eth3:
dhcp4: no
dhcp6: no
bonds:
bond0:
interfaces:
- eth0
- eth1
addresses: [10.0.0.18/16]
gateway4: 10.0.0.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
parameters:
mode: active-backup
mii-monitor-interval: 100
bond1:
interfaces:
- eth2
- eth3
addresses: [10.0.0.18/16]
gateway4: 10.0.0.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
routes:
- to: 10.30.0.0/16
via: 10.20.0.1
- to: 10.40.0.0/16
via: 10.20.0.1
- to: 10.50.0.0/16
via: 10.20.0.1
- to: 10.60.0.0/16
via: 10.20.0.1
~ netplan apply
~ ifconfig
~ ip addr
~ cat /proc/net/bonding/bond{0,1}
~ route -n
5.3.9 网卡的多组绑定
~ cat /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
dhcp6: no
eth1:
dhcp4: no
dhcp6: no
eth2:
dhcp4: no
dhcp6: no
eth3:
dhcp4: no
dhcp6: no
bonds:
bond0:
interfaces:
- eth0
- eth1
parameters:
mode: active-backup
mii-monitor-interval: 100
bond0:
interfaces:
- eth2
- eth3
parameters:
mode: active-backup
mii-monitor-interval: 100
bridges:
br0:
dhcp4: no
dhcp6: no
addresses: [10.0.0.18/16]
gateway4: 10.0.0.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
interfaces:
- bond0
br1:
dhcp4: no
dhcp6: no
addresses: [10.0.0.18/16]
interfaces:
- bond1
routes:
- to: 10.30.0.0/16
via: 10.20.0.1
- to: 10.40.0.0/16
via: 10.20.0.1
- to: 10.50.0.0/16
via: 10.20.0.1
- to: 10.60.0.0/16
via: 10.20.0.1
~ netplan apply
~ brctl show
~ ifconfig br0
~ route -n
~ ifconfig
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!