[]byte和string互转太慢?标准库都在劝你这么用了
经常和网络协议打交道势必会经常用到[]byte和string类型的互相转换,那么这个小小优化可能对你性能的提升非常大。
案例
我们看下面这段代码:
// 长字符
const lcap = 1024 * 1024 //1M
var lstr string
var lbs []byte
?
// 短字符
const scap = 1 //1B
var sstr string
var sbs = []byte(sstr)
?
const char = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()_+=-"
?
func init() {
//生成长string及长byte数组
lstr = generateIntStringWithCap1(lcap)
lbs = []byte(lstr)
fmt.Println("long: ", len(lstr))
//生成短string及短byte数组
sstr = generateIntStringWithCap1(scap)
sbs = []byte(sstr)
fmt.Println("short: ", len(sstr))
}
?
func generateIntStringWithCap1(n int) string {
rand.Seed(time.Now().UnixNano())
?
result := make([]byte, n)
?
for i := 0; i < n; i++ {
result[i] = char[rand.Intn(len(char))]
}
return string(result)
}
?
//优化版
func BenchmarkLongBytesToString(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = BytesToString(lbs)
}
}
func BenchmarkLongStringToBytes(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = StringToBytes(lstr)
}
}
?
//简单版
func BenchmarkLongBytesToStringSimple(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = BytesToStringSimple(lbs)
}
}
?
func BenchmarkLongStringToBytesSimple(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = StringToBytesSimple(lstr)
}
}
?
?
//优化版
func BenchmarkShortBytesToString(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = BytesToString(sbs)
}
}
?
func BenchmarkShortStringToBytes(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = StringToBytes(sstr)
}
}
?
//简单版
func BenchmarkShortBytesToStringSimple(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = BytesToStringSimple(sbs)
}
}
?
func BenchmarkShortStringToBytesSimple(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = StringToBytesSimple(sstr)
}
}
可以看到非常明显的性能差异,1B的字符串优化版比简单版快了10倍左右,1M的字符串,优化版比简单版快了近10万倍。
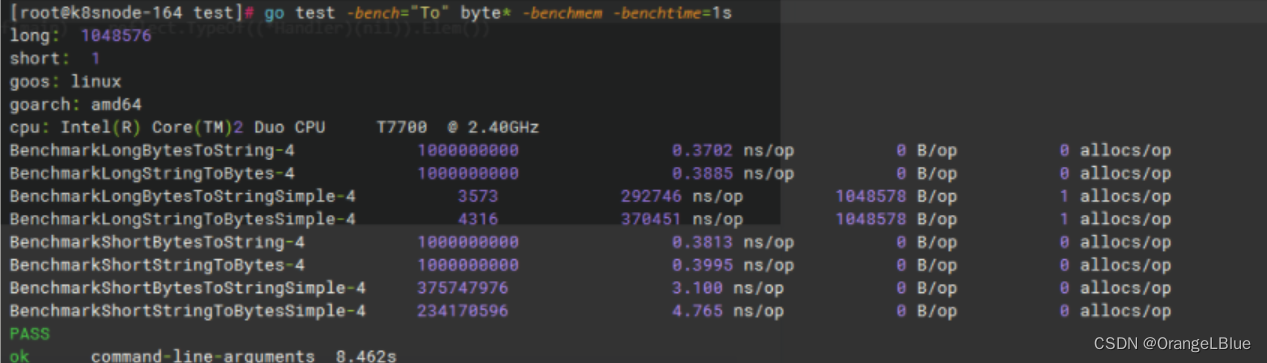
现在我们揭露优化版和简单版的转化分别是怎么实现的
//优化版
func StringToBytes(s string) []byte {
return *(*[]byte)(unsafe.Pointer(
&struct {
string
Cap int
}{s, len(s)},
))
}
?
func BytesToString(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
?
?
//简单版
func StringToBytesSimple(s string) []byte {
return []byte(s)
}
?
func BytesToStringSimple(b []byte) string {
return string(b)
}
可以看到简单版可能是我们现在代码中用的最多的转化方式。对于优化版,为什么这么快,官方的解释是

//(1)将T1转换为指向T2的指针。
//假设T2不大于T1,并且两者共享相同的内存布局,这种转换允许将一种类型的数据重新解释为另一种类型的数据。
而[]byte(本质是Slice)和String的底层结构是这样的
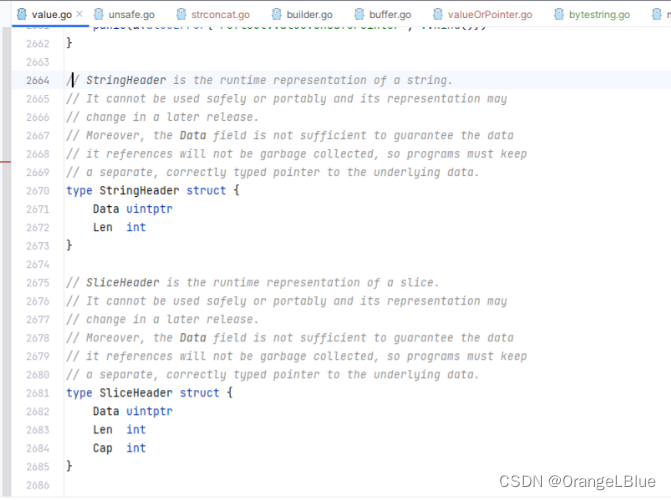
可以看到,Slice比String就多了个Cap,因此在包含了string后再构造一个cao就可以和[]byte底层数据大小相等了,满足条件可以直接用指针做转化。
优化后的转换方式:
1.避免了数据拷贝:通过 unsafe 包的方式,直接将 string 类型的指针转换成了 []byte 类型的指针,避免了在转换过程中的数据拷贝操作。
2.直接操作底层数据:直接进行内存地址的转换,绕过了 Go 语言中一些安全检查和内存复制的开销,不再是传统意义上的转换,而是直接将该地址中数据的类型进行了重新解释
如果看过前面谈的字符串拼接的相关性能,细心可能个会发现bytes.Buffer转为字符串时,官方提了这么一句话

跳到strings.Builder会看到,它就是这么转换的

这也是之前测字符串拼接时,为什么bytes.Buffer总是比strings.Builder allocs次数多1,分配内存更多的原因,很多的第三方库也有类似用法。
总结
利用Slice与String底层数据结构相似特点,可以使用unsafe包避免数据拷贝,直接操作底层数据,直接对数据类型进行重新解释,从而减少了开销,大幅提高转换性能
关于unsafe包还有很多其他用法可以自行探索,但也需要注意unsafe,包如其名它并不是安全的,使用时需要使用者清楚自己在做什么。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!