PiflowX大数据流水线系统
2023-12-27 09:03:50
PiflowX大数据流水线系统。支持分布式计算引擎flink和spark。以所见即所得的方式,实现大数据采集、处理、存储与分析流程化配置、运行与智能监控。
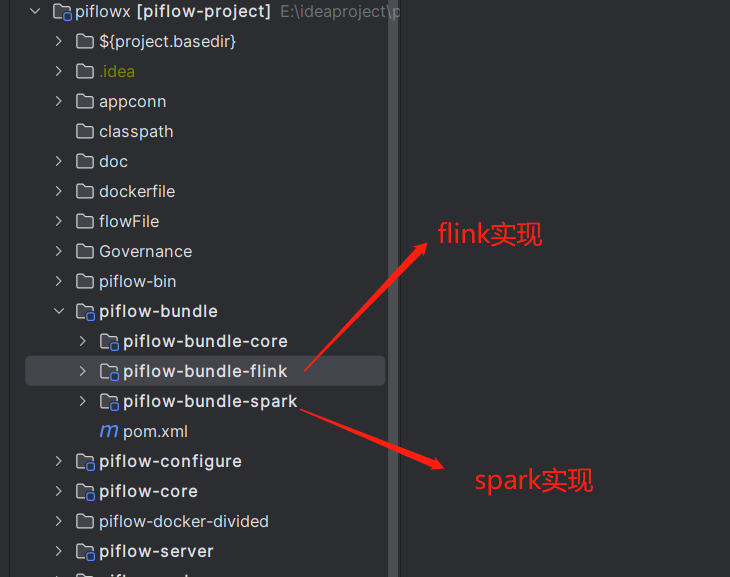
PiflowX基于Piflow(PiFlow: 混合型科学大数据流水线系统,包含丰富的处理器组件,提供Shell、DSL、Web配置界面、任务调度、任务监控等功能 (gitee.com))开发,在此,向Piflow作者和开发者致敬!Piflow原生基于spark引擎,提供了100+的标准化组件,考虑到当前flink在流计算领域的广泛应用,所以开始基于Piflow扩展,使其同时支持spark和flink引擎。
目前PiflowX已完成底层接口改造,顶层算子节点实现spark和flink共用一套接口,引擎实现侧则各自基于不同的引擎API实现。
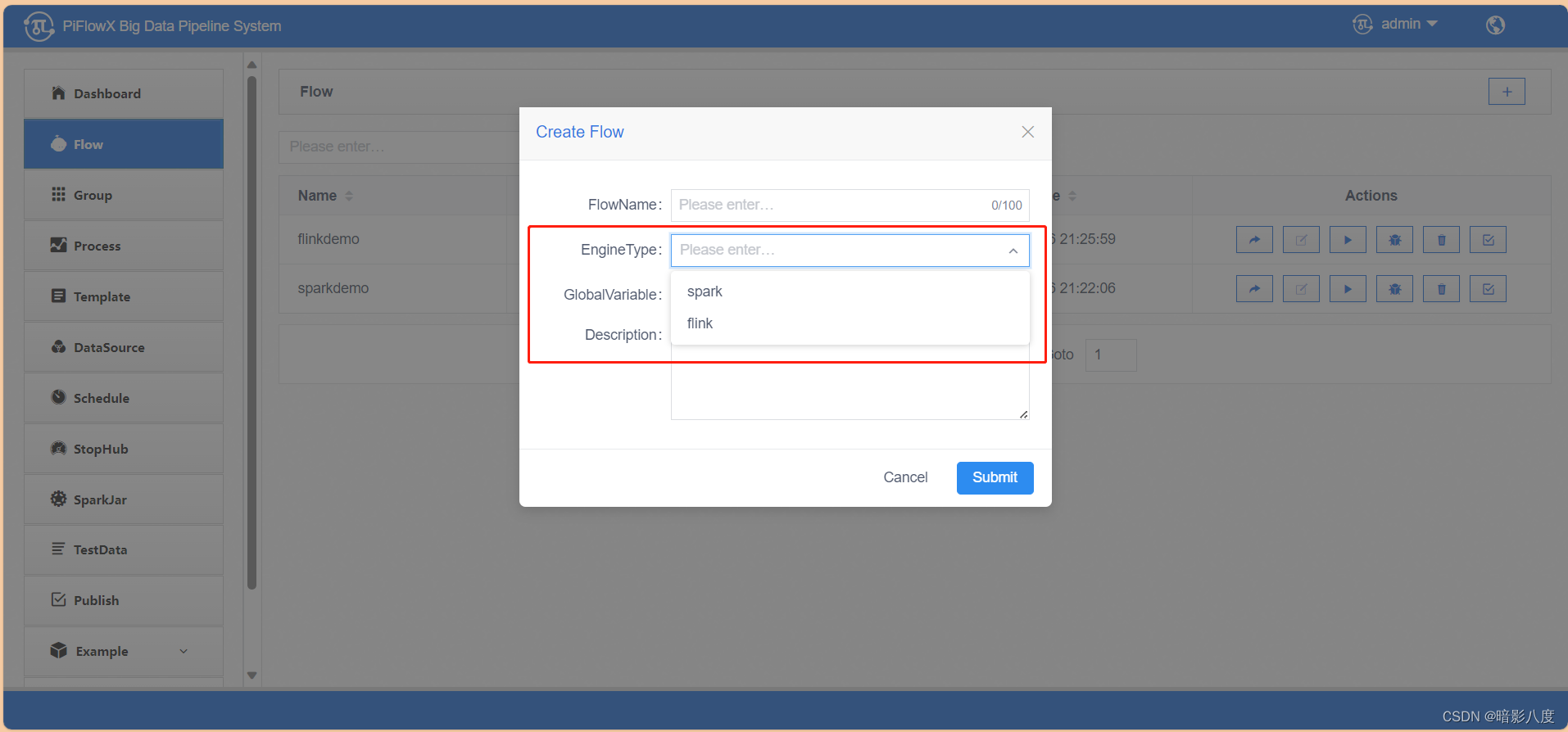
创建任务时,可选择计算引擎是spark还是flink,从而创建不同类型的计算任务。
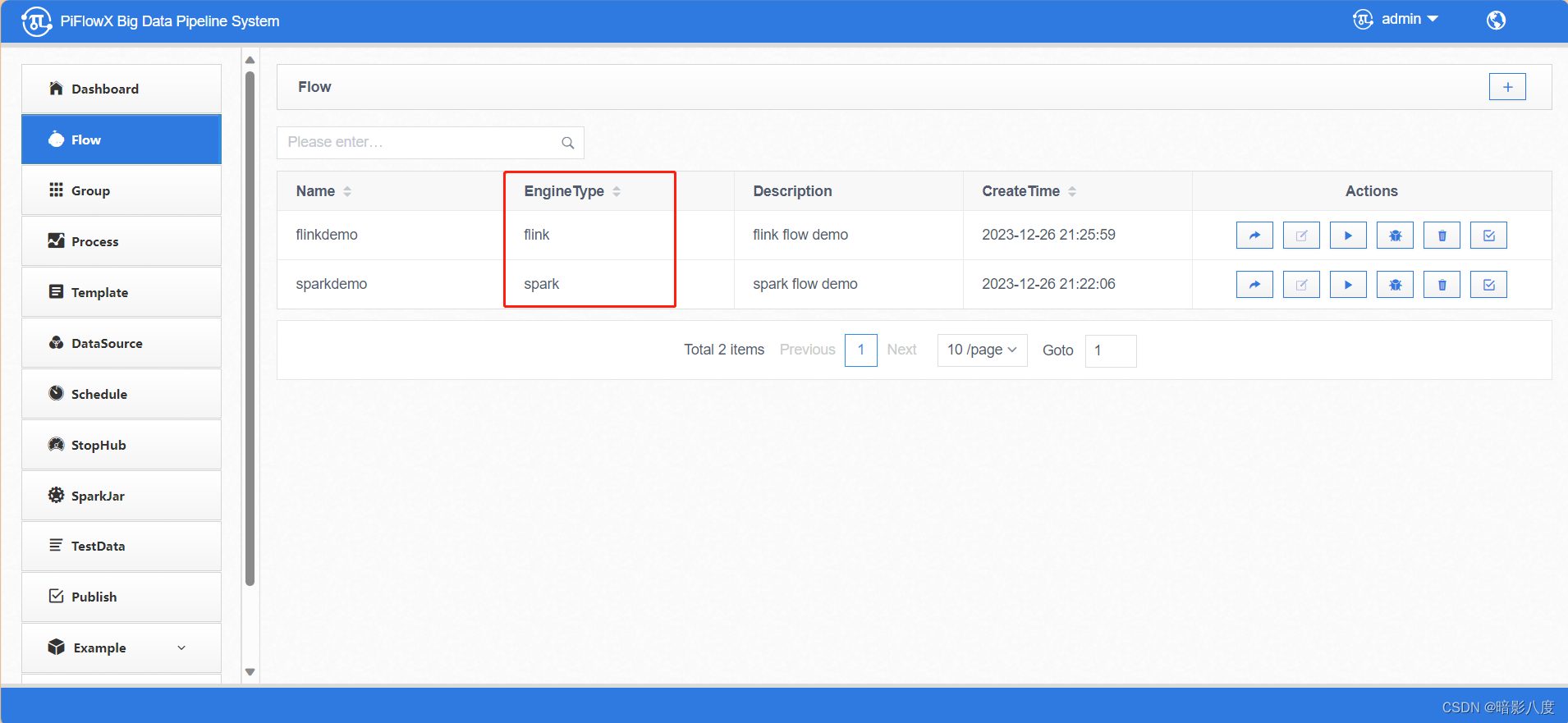
任务编辑,组件节点会通过任务类型加载不同引擎实现的算子节点,目前flink引擎实现了大概30个组件,还在不断扩展中。
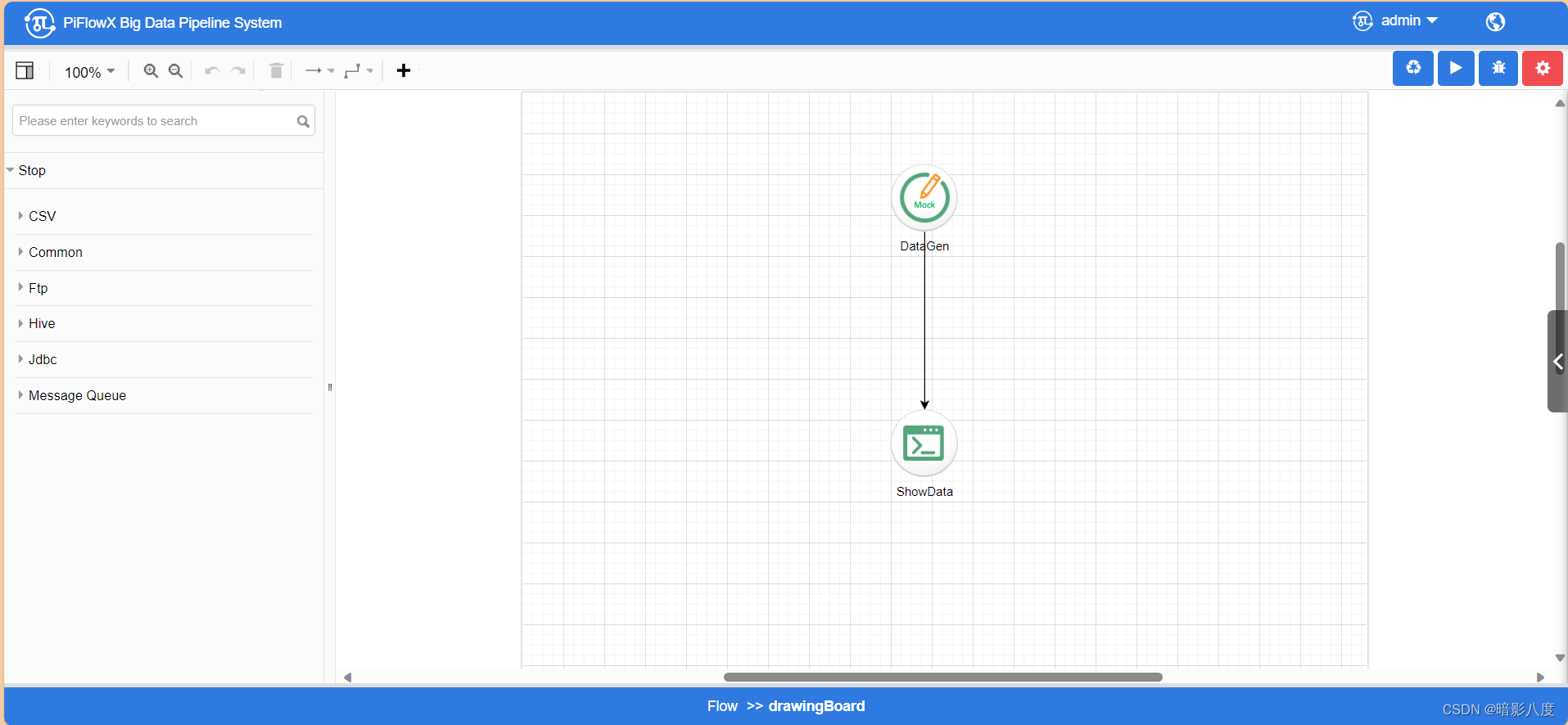
spark任务类型则是原官方项目实现,目前已有100+中组件类型。
PiflowX当前开发处于初期阶段,还有很多不完善的地方,期望以后会越来越完善。下面是简单的演示视频。
67bf2a930f51a536212ba5c442271bfb
文章来源:https://blog.csdn.net/qq_19635589/article/details/135233129
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!