解析为什么Go语言要使用[]rune而不是string来表示中文字符
众所周知,Go语言中有以下这些数据类型。但rune32这个go语言特有的数据类型,比较有意思却经常遭到忽视。所以今天探索学习一下这个数据类型的功能、用法。
Go基本数据类型
布尔:bool
字符串:string
整数:
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64
字节:byte ,uint8 的别名
Unicode:rune ,int32 的别名
浮点:float32 float64
复数:complex64 complex128
Go语言中的中文字符
一个趣味的测试
先做一个趣味的小测试
package main
import "fmt"
func main() {
str := "你好我是climber"
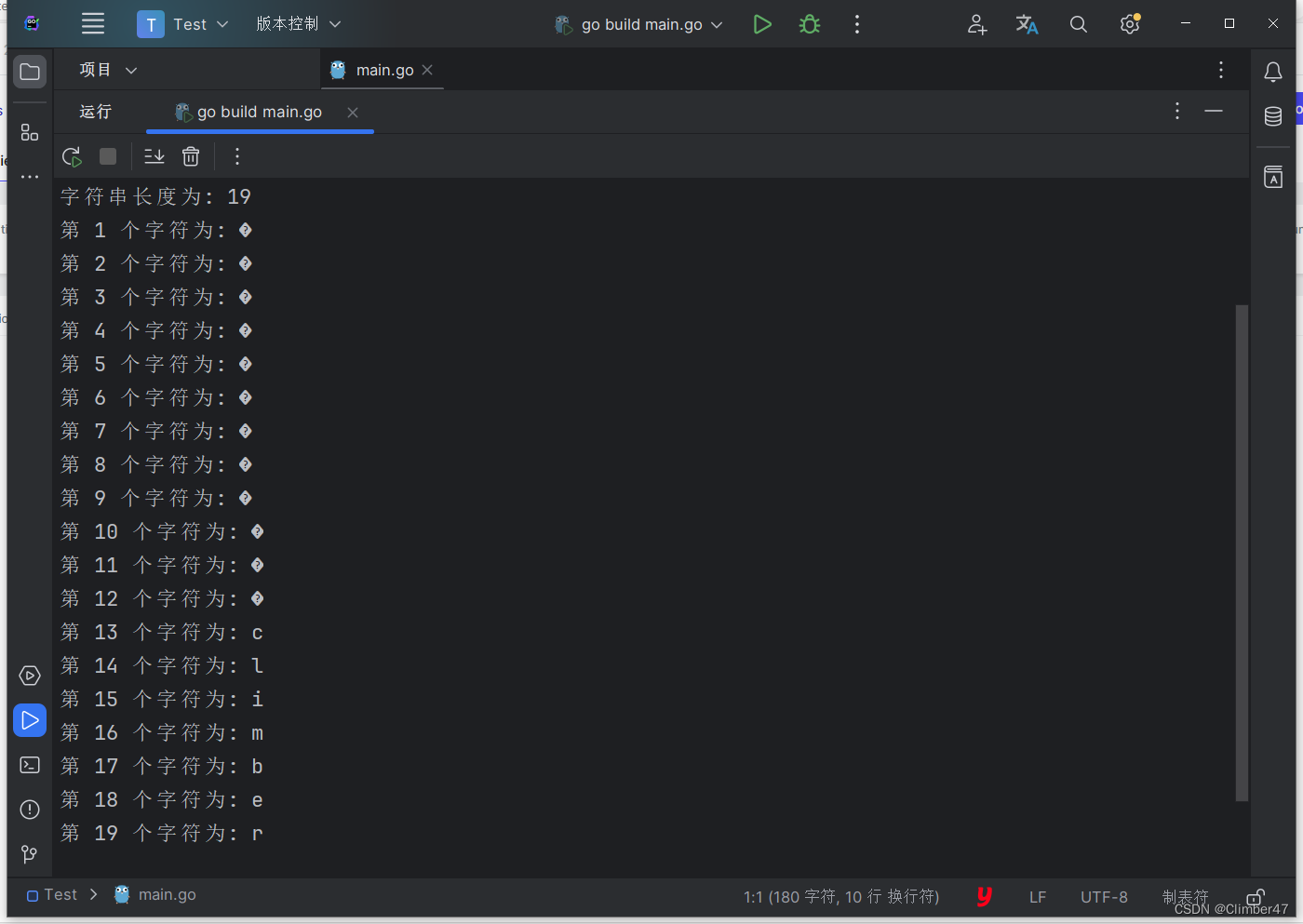
fmt.Println("字符串长度为:", len(str))
for i := 0; i < len(str); i++ {
fmt.Println("第", i+1, "个字符为:", str[i:i+1])
}
}
结果如下:
如果修改输出内容为
fmt.Println("第", i+1, "个字符为:", str[i])
则结果为

如果我们分别给他们加上强制转换为string类型
for i := 0; i < len(str); i++ {
fmt.Println("第", i+1, "个字符为:", string(str[i:i+1]))
}
fmt.Println("字符串长度为:", len(str))
for i := 0; i < len(str); i++ {
fmt.Println("第", i+1, "个字符为:", string(str[i]))
}
那么结果又是这样:

我们发现,所输出的分别是乱码和奇怪的字符
结果及其原因分析
通过对比我们发现,对string进行切片输出,每次输出一位,中文字符会显示为乱码。而单独输出的每一位都对应的是数字。
归纳原因,string的底层是byte数组形式存储数据的。而byte的底层实质上是type byte = uint8。字符的底层是UTF-8编码,因此对于一个汉字,需要使用3个byte进行存储,而英文字符只需要一个。
对于str[i:i+1],所输出的是一个长度为1的[]byte。因为使用切片访问时,获得的是一个新的字符串。因此相当于是“三分之一个汉字”,所以自然就会导致乱码。
对于str[i],所输出的是这一位byte的内容。因为利用索引访问时,输出的是此处原始字节值。所以输出的是数字。但对其进行强制转换,那么所获得的就是对应位置的字符了。
所以如果想通过此方法输出字符串中的一位汉字,应该是输出str[i,i+3]。具体位置需要自己算。
使用[]rune操作中文字符
rune的底层是type rune = int32。相当于4个byte,所占位置是4字节。
我们也可以打印内存地址看到。
func main() {
str := []rune("你好我是climber")
fmt.Println(str)
fmt.Println(&str[0])
for i := 0; i < 11; i++ {
fmt.Println(&str[i])
}
}

而通过内存对齐,可以实现一个位置只存储一个中文或英文字符。这样情况下,输出len(),或切片输出,也就都可以获取预期值了。
func main() {
str := []rune("你好我是climber")
fmt.Println(len(str))
for i := 0; i < 10; i++ {
fmt.Println(string(str[i : i+1]))
}
}

参考资源
http://www.17bigdata.com/study/programming/it-go/it-go-240840.html
https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-string/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!