【LMM 013】ImageBind: One Embedding Space To Bind Them All
论文标题:ImageBind: One Embedding Space To Bind Them All
论文作者:Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh Kalyan, Vasudev Alwala, Armand Joulin, Ishan Misra?
作者单位:FAIR, Meta AI
论文原文:https://arxiv.org/abs/2305.05665
论文出处:–
论文被引:57(01/05/2023)
论文代码https://github.com/facebookresearch/ImageBind,7.5k star
项目主页:https://facebookresearch.github.io/ImageBind/
Abstract
我们介绍了 IMAGEBIND,这是一种学习 6 种不同模态(images, text, audio, depth, thermal, and IMU data)联合嵌入(joint embedding)的方法。我们的研究表明,训练这种联合嵌入并不需要所有配对数据(paired data)组合,只有图像配对数据才足以将各种模态结合在一起。IMAGEBIND 可以利用最新的大规模视觉语言模型,并通过使用这些模型与图像的自然配对,将其零样本(zero-shot)能力扩展到新的模态。它能实现开箱即用的新兴应用,包括跨模态检索,用算术合成模态,跨模态检测和生成。随着图像编码器强度的提高,新兴能力也在不断增强,我们在跨模态的新兴零样本识别任务方面达到了新的水平,表现优于专业的监督模型。最后,我们展示了优于之前工作的强大的零样本识别结果,IMAGEBIND 是评估视觉和非视觉任务的视觉模型的一种新方法。
1. Introduction
一幅图像可以将多种体验结合在一起–海滩的图像可以让我们想起海浪的声音,沙子的质地,微风的吹拂,甚至可以激发一首诗的灵感。图像的这种 结合(binding)特性为学习视觉特征提供了许多监督来源,通过将视觉特征与任何与图像相关的感官体验对齐,就可以学习视觉特征。理想情况下,对于单个联合嵌入空间(joint embedding space),应通过与所有这些传感器对齐来学习视觉特征。然而,这需要获取与同一组图像配对的所有类型和组合数据,而这是不可行的。
最近,许多方法都在学习与文本[1, 31, 46, 60, 64, 65, 82, 83],音频[3, 4, 50, 55, 56, 70]等相对齐的(aligned)图像特征。这些方法只使用一对模态,或最多使用小样本的视觉模态。然而,最终的嵌入结果仅限于用于训练的模态对(pairs of modalities)。因此,视频-音频嵌入不能直接用于图像-文本任务,反之亦然。学习真正的联合嵌入的一个主要障碍是缺乏大量的多模态数据,而在这些数据中,所有模态都同时存在。
在本文中,我们介绍了 IMAGEBIND,它通过利用多种类型的图像对数据来学习单一的共享表示空间。它不需要所有模态同时出现的数据集。取而代之的是,我们利用图像的结合(binding)特性,并证明了只需将每种模态的嵌入与图像嵌入对齐,就能在所有模态之间产生新的对齐。在实践中,IMAGEBIND 利用网络规模的 (image, text) 配对数据,并将其与自然出现的配对数据 (video, audio), (image, depth) 等结合起来,学习单一的联合嵌入空间。这样,IMAGEBIND 就能将文本嵌入隐式地与音频,深度等其他模态对齐,从而在没有明确的语义或文本配对的情况下,在该模态上实现零样本识别能力。此外,我们还展示了它可以通过大规模视觉语言模型(如 CLIP [60])进行初始化,从而利用这些模型丰富的图像和文本表示。因此,IMAGEBIND 只需小样本训练就可以应用于各种不同的模态和任务。

我们使用了大规模图像-文本配对数据以及自然配对的自监督数据,这些数据跨越了 audio, depth, thermal, Inertial Measurement Unit (IMU) 数据等四种新模态,并在每种模态的任务中都显示出强大的新兴零样本分类和检索性能。随着底层图像表征的增强,这些新兴特性也得到了改善。在音频分类和检索基准上,IMAGEBIND 的新兴零样本分类与在 ESC,Clotho,AudioCaps 等基准上使用直接音频文本监督训练的专业模型不相上下,甚至更胜一筹。此外,IMAGEBIND 表示法在小样本评估基准上的表现也优于专业监督模型。最后,我们展示了 IMAGEBIND 的联合嵌入可用于图 1 所示的各种组合任务,包括跨模态检索(cross-modal retrieval),通过算术组合嵌入(combining embeddings via arithmetic),检测图像中的音频源(detecting audio sources in images)以及根据音频输入生成图像(generating images given audio input)。
2. Related Work
IMAGEBIND 建立在视觉语言,多模态和自监督研究的若干进展基础之上。
Language Image Pre-training.
事实证明,将图像与单词或句子等语言信号结合起来进行训练,是零样本,开放词汇识别和文本到图像检索的有效方法[14, 18, 38, 68]。语言作为监督可进一步用于学习强大的视频表征[2, 47, 48]。
- Joulin et al. [34]的研究表明,使用带有噪声描述(noisy captions)的大规模图像数据集可以获得强大的视觉特征。
- 最近,CLIP[60],ALIGN[31]和 Florence[83]收集了大量图像和文本对,并利用对比学习训练模型,将图像和语言输入嵌入联合空间,表现出令人印象深刻的零样本性能。
- CoCa [82] 在对比损失的基础上增加了图像描述目标,从而提高了性能。
- Flamingo [1] 可处理任意交错的图像和文本,并在许多零样本学习基准测试中取得了 SOTA。
- LiT [84] 采用对比训练进行微调,并观察到冻结图像编码器效果最佳。
之前的工作主要考虑图像和文本,而我们的工作则实现了多种模态的零样本识别。
Multi-Modal Learning.
我们的工作是在联合嵌入空间中结合(bind)多种模态表征。
- 之前的工作探索了在监督[21, 42]或自监督的情况下对多种模态进行联合训练[3, 20, 50, 70, 74]。
- 图像和语言预训练方法(如 CLIP)的成功启发了通过匹配其他模态和语言输入来重新学习深层语义表征的方法。
- 各种方法对 CLIP 进行了调整,以提取语义更强的视频表征 [15, 43, 45, 79]。
- 与我们的方法最相关的是,Nagrani et al. [51] 为配对的视频音频和描述创建了一个弱标签数据集,用于训练多模态视频音频编码器,以匹配文本特征,从而实现强大的音频和视频检索及描述性能。
- AudioCLIP [27] 将音频作为附加模态添加到 CLIP 框架中,实现了零样本音频分类。
相比之下,IMAGEBIND 不需要所有模态之间明确的配对数据,而是利用图像作为统一模态的天然弱监督。
Feature Alignment.
由于 CLIP 模型具有强大的视觉表征能力,预先训练的 CLIP 模型已被用作监督其他模型的教师[44, 58, 75]。此外,CLIP 联合图像和文本嵌入空间还被用于检测 [24,88],分割 [41],网格动画 [81] 等各种零样本任务,显示了联合嵌入空间的威力。
- PointCLIP [85] 发现,通过将点云投影到多个二维深度图视图上,再使用 CLIP 视觉编码器对这些视图进行编码,可以将预先训练好的 CLIP 编码器用于三维识别。
- 在多语言神经机器翻译中,通常可以观察到并利用与 IMAGEBIND 出现行为类似的现象:如果通过学习的隐式桥接在同一潜在空间中训练语言,则可以在未提供配对数据的语言对之间进行翻译 [33, 40]。
3. Method
我们的目标是利用图像将所有模态结合(bind)在一起,从而为所有模态学习单一的联合嵌入空间。我们将每种模态的嵌入空间与图像嵌入空间相匹配,例如利用网络数据实现文本到图像的嵌入空间,以及利用带有 IMU 的第一视角的摄像头捕获的视频数据实现 IMU 到视频的嵌入空间。我们的研究表明,由此产生的嵌入空间具有强大的新兴零样本行为,它能在不查看任何训练数据的情况下自动关联模态对。图 2 展示了我们的方法。

3.1. Preliminaries
Aligning specific pairs of modalities.
对比学习[28]是一种通过使用成对的相关示例(正样本对)和不相关示例(负样本对)来学习嵌入空间的通用技术。使用成对的观察结果,对比学习可以对齐成对的模态,如(图像,文本)[60],(音频,文本)[27],(图像,深度)[70],(视频,音频)[50]等。不过,在每种情况下,联合嵌入都是使用相同的模态对进行训练和评估的。因此,(视频,音频)嵌入并不能直接用于基于文本的任务,而(图像,文本)嵌入也不能用于音频任务。
Zero-shot image classification using text prompts.
CLIP [60] 推广了一种基于对齐(图像,文本)嵌入空间的零样本分类任务。这需要构建一个文本描述列表来描述数据集中的类别。输入图像根据其与嵌入空间中文本描述的相似度进行分类。为其他模态解锁这种零样本分类需要使用成对文本数据进行专门训练,例如(音频,文本)[27] 或(点云,文本)[85]。相比之下,IMAGEBIND 可以在没有成对文本数据的情况下,为各种模态解锁零样本分类。
3.2. Binding modalities with images
IMAGEBIND 使用成对的模态(I, M)(其中 I 代表图像,M 代表另一种模态)来学习单一的联合嵌入。我们使用的是大规模网络数据集,其中的(图像,文本)配对涵盖了广泛的语义概念。此外,我们还利用其他模态(audio,depth,thermal 和 IMU)与图像的自然,自监督配对。
考虑具有对齐观测数据的一对模态(I,M)。给定图像 Ii 及其在另一模态 Mi 中的对应观测值,我们将它们编码为归一化嵌入:qi = f (Ii) 和 ki = g(Mi),其中f,g 是深度网络。我们使用 InfoNCE [54] 损失对嵌入和编码器进行了优化:
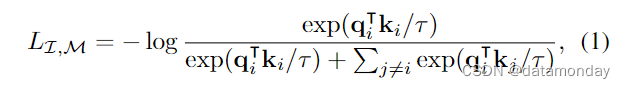
其中,τ 是一个标量温度,用于控制 softmax 分布的平滑度,j 表示不相关的观测值,也称为负样本(negatives)。我们遵循文献 [76],将 mini batch 中每个 j ≠ i j \neq i j=i 的实例都视为负样本。在实践中,我们使用对称损失 LI,M + LM,I 。
Emergent alignment of unseen pairs of modalities.
IMAGEBIND 使用与图像配对的模态,即形式为(I, M)的配对,来对齐每个模态 M 的嵌入和图像的嵌入。我们在嵌入空间中观察到一种新出现的行为,它能对齐两对模态(M1, M2),即使我们只使用(I, M1)和(I, M2)这两对模态进行训练。这种行为使我们能够在不进行训练的情况下执行各种零样本和跨模态检索任务。我们无需观察配对(音频,文本)的单个样本,就能获得最先进的零样本文本-音频分类结果。
3.3. Implementation Details
IMAGEBIND 概念简单,可以通过多种不同方式实现。我们特意选择了一种普通的实现方式,这种方式灵活多变,可以进行有效的研究并易于采用。在第 5 节中,我们将介绍对良好的新兴 binding 至关重要的设计决策。
Encoding modalities.
我们对所有模态编码器都采用了 Transformer 架构[73]。
- 我们使用 ViT [13] 来处理图像。根据 OmniMAE [20],我们对图像和视频使用相同的编码器。我们对 ViT 的 patch 投影层进行 temporally inflate [7],并使用从 2 秒钟开始采样的 2 帧视频片段。
- 我们按照 AST [22]对音频进行编码,将采样频率为 16kHz 的 2 秒音频转换为使用 128 个梅尔频谱图分区的频谱图。由于频谱图与图像一样也是二维信号,因此我们使用了patch大小为 16,步长为 10 的 ViT。
- 我们将热图像和深度图像视为单通道图像,并使用 ViT 对其进行编码。
- 我们按照 Omnivore [21]的方法将深度图转换成不等度图,以获得尺度不变性。
- 我们提取的 IMU 信号包括加速度计和陀螺仪在 X,Y 和 Z 轴上的测量值。我们使用 5 秒钟的片段生成 2K 时间步长的 IMU 读数,并使用核大小为 8 的一维卷积进行投影。
- 最后,我们采用 CLIP [60] 的文本编码器设计。
我们对图像,文本,音频,热图像,深度图像和 IMU 使用单独的编码器。我们在每个编码器上都添加了一个特定于模态的线性投影头,以获得固定大小的 d 维嵌入,并将其归一化,用于公式 1 中的 InfoNCE 损失。除了便于学习外,这种设置还允许我们使用预训练模型初始化编码器子集,例如使用 CLIP [60] 或 OpenCLIP [30]初始化图像和文本编码器。
4. Experiments
我们首先介绍了主要的实验装置,并在补充材料中提供了全部细节。
Naturally paired modalities and datasets.
我们将 IMAGEBIND 用于六种模态:图像/视频,文本,音频,深度,热图像和 IMU。如第 3.3 节所述,我们将视频视为两帧图像,处理方法与图像相同。对于自然可用的配对数据,我们使用 Audioset 数据集[19]中的(视频,音频)配对,SUN RGB-D 数据集[69]中的(图像,深度)配对,LLVIP 数据集[32]中的(图像,热图像)配对和 Ego4D 数据集[23]中的(视频,IMU)配对。对于这些模态对,我们不使用任何额外的监督,如类标签,文本等。由于 SUN RGB-D 和 LLVIP 的规模相对较小,我们按照 [21] 的方法,将它们复制 50 倍进行训练。我们利用大规模网络数据 [60] 中的图像-文本监督。为了便于实验,我们使用在数十亿(图像,文本)对上训练过的预训练模型。具体来说,我们使用 OpenCLIP [11, 30] 的预训练视觉编码器(ViT-H 6.3 亿参数)和文本编码器(3.02 亿参数)。
Encoders for each modality.
我们将音频转换为 2D Mel 光谱图[22],将热和深度模态转换为单通道图像,并分别使用 ViT-B 和 ViT-S 编码器。在 IMAGEBIND 训练期间,图像和文本编码器保持冻结,而音频,深度,热和 IMU 编码器则不断更新。
Emergent zero-shot vs. zero-shot.
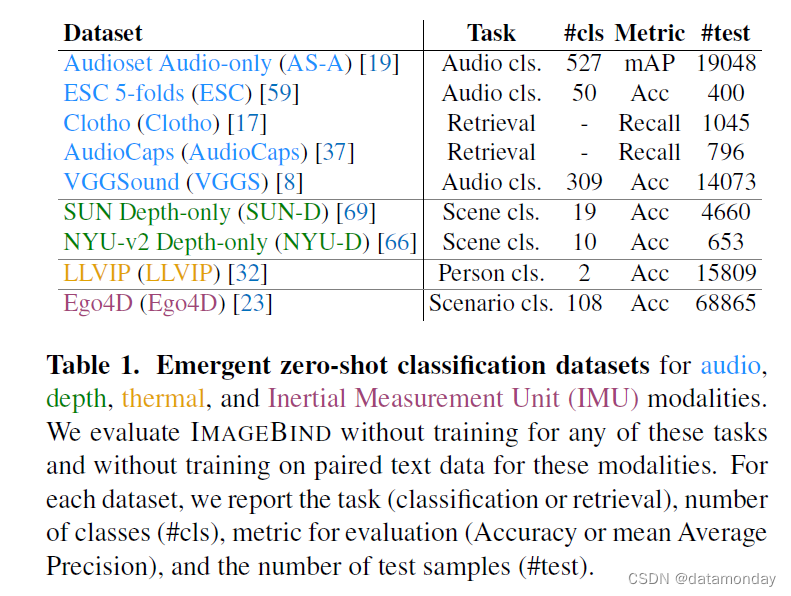
CLIP[60],AudioCLIP[27]等方法使用模态对(图像,文本)和(音频,文本)进行训练,使用同一模态的文本摘要展示零样本分类。相比之下,IMAGEBIND 只使用图像配对数据将各种模态 binding 在一起。因此,只需对(图像,文本)和(图像,音频)进行训练,IMAGEBIND 就能使用文本提示对音频进行零样本分类。由于我们并没有直接训练这种能力,因此我们将其称为新兴的零样本分类,以区别于专门针对所有模态使用成对文本监督进行训练的方法。我们使用不同的协议,在许多不同的下游任务中对 IMAGEBIND 进行了全面评估。我们在表 1 中总结了用于评估的主要数据集。
4.1. Emergent zero-shot classification
我们使用 [60] 中的文本提示模板对 IMAGEBIND 进行了评估(详情见附录 B)。我们在表 2 中报告了结果。每个任务衡量的是 IMAGEBIND 将文本嵌入与其他模态相关联的能力,而无需在训练过程中同时观察它们。鉴于我们问题设置的新颖性,没有公平的基线可与 IMAGEBIND 进行比较。尽管如此,我们还是将 IMAGEBIND 与之前使用文本与某些模态(如音频 [27, 51])配对的工作进行了比较,对于某些类视觉模态,如深度图和thermal图,我们直接使用 CLIP 模型。我们还报告了每个基准的最佳监督上限。

IMAGEBIND 实现了较高的新兴零样本分类性能。在每个基准测试中,IMAGEBIND 都取得了很好的成绩,甚至可以与针对特定模态和任务训练的监督专家模型相媲美。这些结果表明,IMAGEBIND 协调了各种模态,并将与图像相关的文本监督隐式地转移到音频等其他模态。特别是,IMAGEBIND 对音频和 IMU 等非视觉模态显示出很强的一致性,这表明它们与图像的自然配对是监督的强大来源。为完整起见,我们还报告了标准的零样本图像(ImageNet [63] - IN1K,Places-365 [87] - P365)和视频(Kinetics400 [35] - K400,MSR-VTT 1kA [78] - MSR-VTT)任务。由于图像和文本编码器是使用 OpenCLIP 初始化(和冻结)的,因此这些结果与 OpenCLIP 的结果一致。
4.2. Comparison to prior work
现在,我们将 IMAGEBIND 与之前在零样本检索和分类任务方面的工作进行比较。
Zero-shot text to audio retrieval and classification.
与 IMAGEBIND 不同的是,先前的工作使用该模态的成对数据进行训练,例如,AudioCLIP [27] 使用(音频,文本)监督,AVFIC [52] 使用自动挖掘的(音频,文本)成对数据。在表 3 中,我们将它们的零样本文本到音频检索和分类性能与 IMAGEBIND 的新兴检索和分类性能进行了比较。
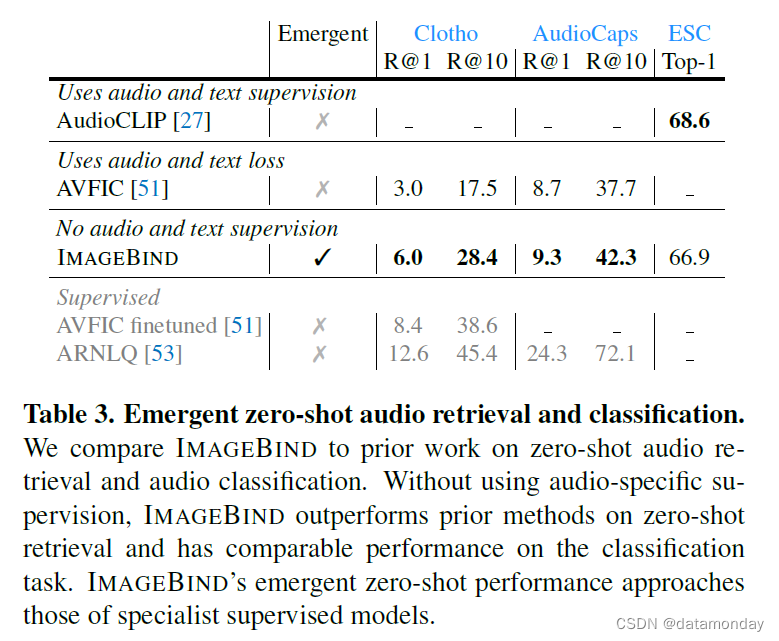
在音频文本检索基准方面,IMAGEBIND 的性能明显优于之前的研究成果。在 Clotho 数据集上,IM-AGBIND 的性能是 AVFIC 的两倍,尽管在训练过程中没有使用任何音频文本配对。与有监督的 AudioCLIP 模型相比,IMAGEBIND 在 ESC 上的音频分类性能相当。请注意,AudioCLIP 使用 AudioSet 中的类名作为音频-文本训练的文本目标,因此被称为有监督的。IMAGEBIND 在所有三个基准测试中的优异表现验证了其利用图像作为桥梁对音频和文本模态进行调整的能力。
Text to audio and video retrieval.
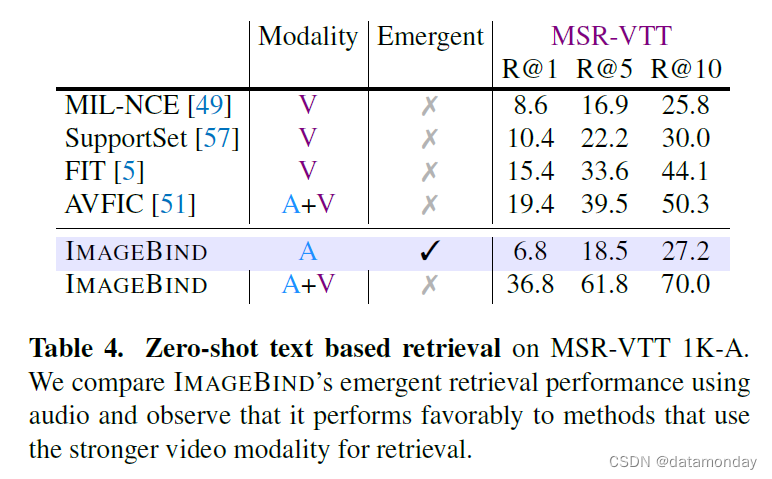
我们使用 MSR-VTT 1k-A 基准来评估文本到音频和视频的检索性能,见表 4。与 MIL-NCE 等先前工作的视频检索性能相比,IMAGEBIND 仅使用音频就实现了很强的新兴检索性能。由于使用了 OpenCLIP 的视觉和文本编码器,我们的模型在文本到视频方面的性能很强(表 2 中的 R@1 为 36.1%),超过了许多先前的方法。然而,将音频和视频模态结合在一起可进一步提高性能,这表明 IMAGEBIND 的功能在一个已经很强大的检索模型上的实用性。
4.3. Few-shot classification
现在,我们通过小样本分类来评估 IMAGEBIND 的标签效率。我们使用 IMAGEBIND 的音频和深度编码器,并在图 3 中分别对音频和深度分类进行评估。对于≥1 个样本的结果,我们遵循 [50, 60] 的方法,在固定特征上训练线性分类器(详情见附录 B)。

在小样本音频分类方面(图 3 左),我们与(1)根据 Audioset 音频训练的自监督 AudioMAE 模型和(2)根据音频分类微调的监督 AudioMAE 模型进行了比较。两种基线都使用与 IMAGEBIND 相同容量的 ViT-B 音频编码器。在所有设置下,IMAGEBIND 都明显优于 AudioMAE 模型,在 ≤4 个样本分类的 top-1 准确率上,IMAGEBIND 的准确率提高了 40%。IMAGEBIND 在 ≥1 个样本分类上的表现也与监督模型相当或更胜一筹。IMAGEBIND 的新兴零样本性能超过了监督模型的≤2 个样本性能。
在小样本深度分类方面,我们与根据图像,深度和语义分割数据训练的多模态 MultiMAE [4] ViT-B/16 模型进行了比较。在所有小样本设置中,IMAGEBIND 都明显优于 MultiMAE。总之,这些结果表明,通过图像对齐训练的 IMAGEBIND 音频和深度特征具有很强的通用性。
4.4. Analysis and Applications
Multimodal embedding space arithmetic.

我们研究了 IMAGEBIND 的嵌入是否可用于跨模态组合信息。在图 4 中,我们展示了通过将图像和音频嵌入信息相加而获得的图像检索结果。联合嵌入空间允许我们将两个嵌入信息组合在一起:例如,桌子上水果的图像+鸟鸣声,然后检索出包含这两个概念的图像,即树上的水果和鸟儿。短时组合性可以将不同模态的语义内容组合在一起,从而实现丰富多样的组合任务。
无需重新训练,我们就能升级使用 CLIP 嵌入的现有视觉模型,以使用来自音频等其他模态的 IMAGEBIND 嵌入。
Upgrading text-based detectors to audio-based.
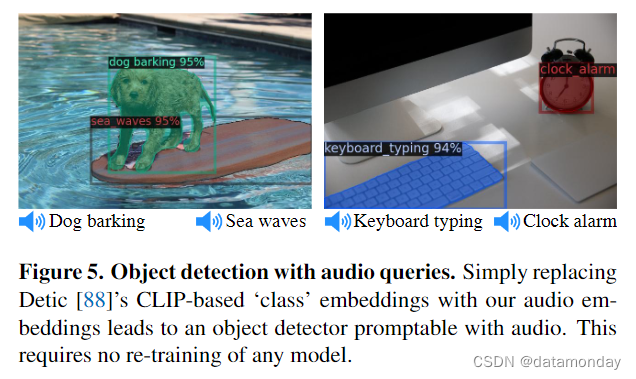
我们使用预先训练好的基于文本的检测模型 Detic [88],并简单地将其基于 CLIP 的 “类”(文本)嵌入替换为 IMAGEBIND 的音频嵌入。无需训练,这就创建了一个基于音频的检测器,可以根据音频提示检测和分割对象。如图 5 所示,我们可以用狗叫声来提示检测器,以确定狗的位置。
Upgrading text-based diffusion models to audio-based.
我们使用预先训练好的 DALLE-2 [61] 扩散模型(private reimplementation),并用我们的音频嵌入替换其提示嵌入。从图 1 中可以看出,我们可以重新利用扩散模型,使用不同类型的声音生成可信的图像。
5. Ablation Study
我们研究了针对不同模态学习联合嵌入空间的各种设计选择。由于消融实验的设置与第 4 节相似,我们仅指出主要的不同之处(详情见附录 C)。我们报告的是 ESC fold-1 在消融研究中的结果。对于图像,音频,深度和热模态,我们默认使用 ViTB 编码器,并训练 16 个 epoch(§ 4 中为 32 个epoch)。对于 IMU,我们使用 512 维宽,8 个头的轻量级 6 层编码器,训练 8 个 epoch。文本编码器遵循文献 [60],是一个宽度为 512 维的 12 层 Transformer。我们根据 CLIP 模型[60]初始化图像和文本编码器。
5.1. Scaling the Image Encoder
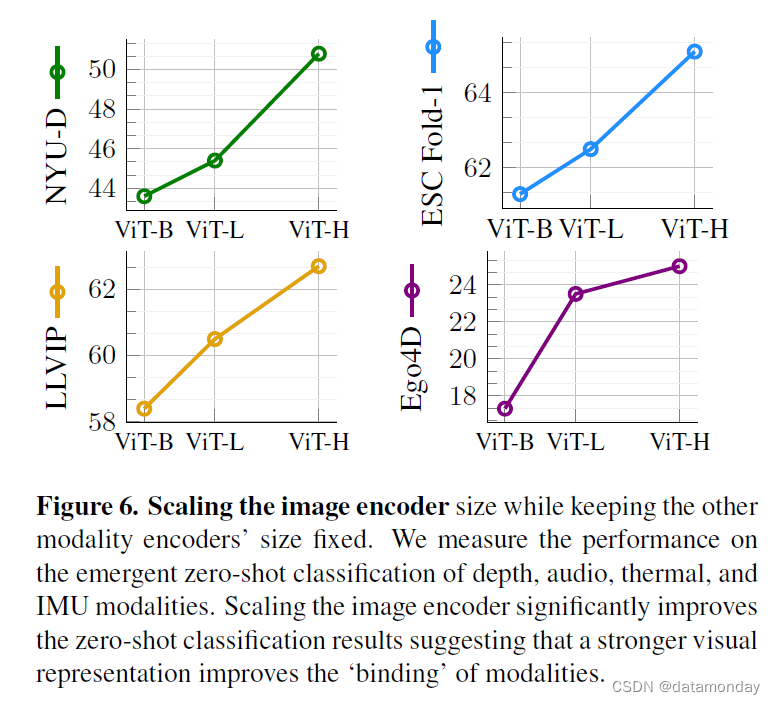
IMAGEBIND 的核心理念是将所有模态的嵌入与图像嵌入对齐。因此,图像嵌入在未见模态的新兴对齐中起着核心作用,我们研究了图像嵌入对新兴零样本性能的影响。我们改变图像编码器的大小,并训练深度,音频等模态的编码器以对齐图像表示。为了隔离图像表示的影响,我们固定了其他模态编码器的大小。在本实验中,我们使用了经过预训练的 CLIP(ViT-B 和 ViT-L)和 OpenCLIP(ViT-H)图像和文本编码器。图 6 中的结果显示,随着视觉特征的改善,IMAGEBIND 在所有模态上的突发零样本性能都有所提高。在深度和音频分类方面,ViT-H 图像编码器比 ViT-B 图像编码器分别提高了 7% 和 4%。因此,即使在非视觉模态下,更强的视觉特征也能提高识别性能。
5.2. Training Loss and Architecture
我们研究了训练设计选择对新出现的零样本分类的影响。我们重点研究了两种具有不同特征的模态:深度模态(视觉和空间)和音频模态(非视觉和时间)。我们发现,通过对这些不同模态的研究,可以做出稳健且可移植的设计决策。
Contrastive loss temperature.
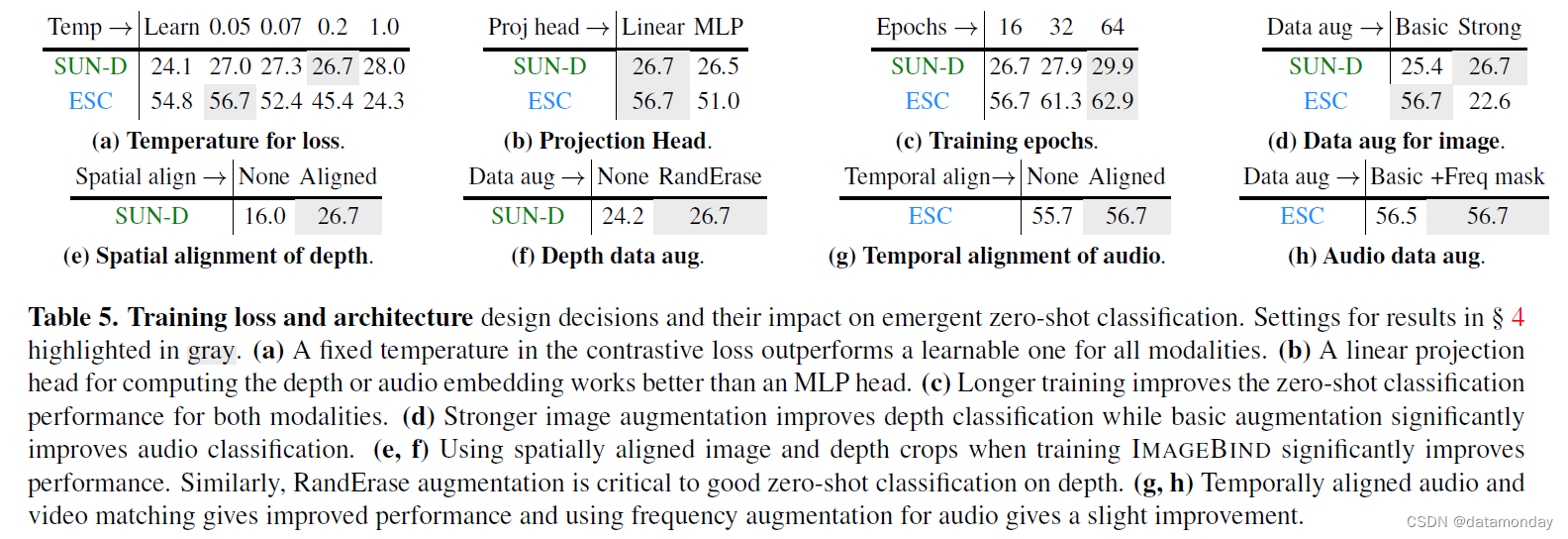
我们在表 5a 中研究了温度 τ ( 公式 1) 的影响。我们按照 [60] 的方法,使用初始化为 0.07 的可学习温度(以对数标度为参数)与各种固定温度值进行对比实验。与 [60] 不同的是,我们发现固定温度最适合深度,音频和 IMU 分类。此外,我们还发现,较高的温度更适合训练深度图,thermal图和 IMU 编码器,而较低的温度则最适合音频模态。
Projection head.
我们改变了每个编码器使用的投影头,从线性层到具有 768 个隐藏维度的 MLP。表 5b 中的结果显示,线性投影在两种模态下的表现都更好。这与 SimCLR [10] 等标准自监督方法形成了鲜明对比,后者的性能随着 MLP 投影头的使用而提高。
Training epochs.
我们改变了训练epoch数,并在表 5c 中报告了分类性能。在所有数据集中,对于两种模态,较长的训练时间都能持续提高出现零样本的性能。
Data augmentation for paired images.
在IMAGEBIND的训练过程中,我们会使用基本增强(裁剪,色彩抖动)或强增强(额外应用 RandAugment [12] 和 RandErase [86])对图像进行增强。附录 C 中说明了增强参数。当在 SUN RGB-D 数据集中的小样本(图像,深度)对上进行训练时,较强的增强有助于深度分类。但是,对于音频而言,对视频进行强增强会使任务变得过于艰巨,导致 ESC 值大幅下降 34%。
Depth specific design choices.
在表 5e 中,我们改变了用于训练的空间作物类型。根据 CMC [70],我们从相应的图像和深度对中使用了两种未对齐的随机裁剪,而我们默认使用的是空间对齐的随机裁剪。与 CMC 相反,我们发现随机裁剪严重降低了性能:在 SUN-D 上降低了 10%。与 vanilla 自监督学习不同,我们从图像文本对中学习到的图像表征更具语义性,因此空间错位裁剪会降低性能。在表 5f 中,我们发现 RandomErase [86] 提高了深度分类的性能。
Audio specific design choices.
我们使用时间对齐样本或未对齐样本进行视频音频对齐训练,并在表 5g 中测量最终性能。与深度分类的观察结果类似,时间对齐的样本会带来更好的性能。表 5h 显示,对音频使用频率掩码增强也能小幅提升性能。
Capacity of the audio and depth encoders.
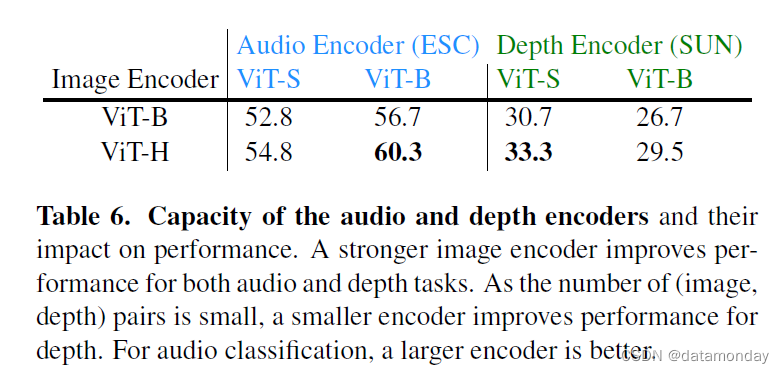
音频和深度编码器的容量及其对分类性能的影响见表 6。由于(图像,深度)数据集的规模相对较小,因此较小的深度编码器可以提高性能。相反,我们观察到较大的音频编码器也能提高性能,尤其是与大容量图像编码器搭配时。
Effect of batch size.
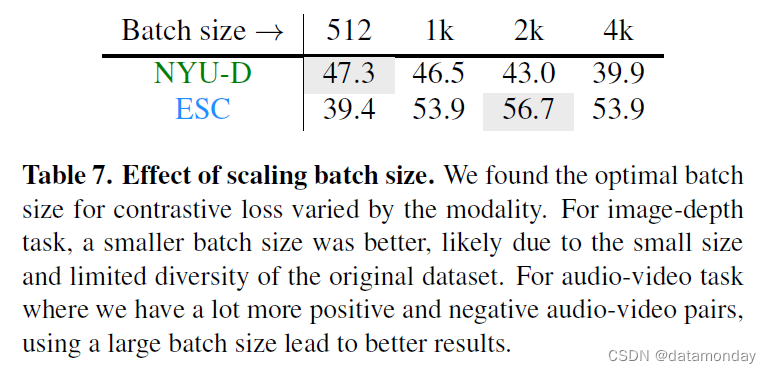
在表 7 中,我们评估了批量大小对所学表示的影响。如图所示,根据相应预训练数据集的大小和复杂程度,不同模态的批量大小会有所不同。
IMAGEBIND to evaluate pretrained vision models.
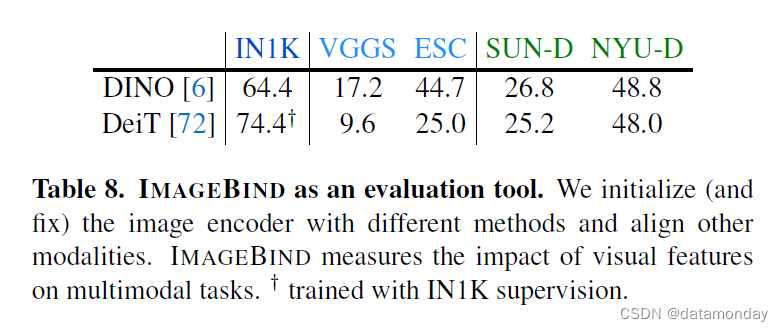
表 8 用 IMAGEBIND 评估预训练视觉模型。我们使用预训练模型对视觉编码器进行初始化并保持固定。我们使用图像配对数据来校准和训练文本,音频和深度编码器(详情见附录 B)。与有监督的 DeiT 模型相比,自监督的 DINO 模型在深度和音频模态上的新兴零样本分类能力更强。此外,新兴零样本性能与 ImageNet 上的纯视觉性能并不相关,这表明这些任务测量的是不同的属性。IMAGEBIND 可以作为衡量视觉模型在多模态应用中优势的重要工具。
6. Discussion and Limitations
IMAGEBIND 是一种简单实用的方法,可仅使用图像对齐来训练联合嵌入空间。我们的方法可以在所有模态中实现新兴对齐,这种对齐可以通过跨模态检索和基于文本的零样本摄任务来衡量。我们实现了跨不同模态的丰富的多模态组合任务,展示了评估非视觉任务的预训练视觉模型的方法,并将 Detic 和 DALLE-2 等模型升级为使用音频的模型。有多种方法可以进一步改进 IMAGEBIND。我们的图像对齐损失可以通过使用其他对齐数据得到丰富,例如与文本配对或相互配对的其他模态(如音频与 IMU)。我们的嵌入训练没有特定的下游任务,因此在性能上落后于专业模型。针对每项任务(包括检测等结构化预测任务)调整通用嵌入的更多研究将大有裨益。最后,新的基准(如我们的新兴零样本任务,用于衡量多模态模型的新兴能力)将有助于创造令人兴奋的新应用。我们的模型只是一个研究原型,不能随时用于实际应用(附录 F)。
A. Datasets and Metrics
Audioset (AS) [19].
该数据集用于训练和评估。该数据集包含来自 YouTube 的 10s 视频,注释为 527 个类别。该数据集由 3 个预定义的分集组成:包含约 2 万个视频的平衡分集,包含 1.8 万个视频的测试分集,以及包含约 200 万个视频的非平衡训练分集。在训练中,我们使用不带任何标签的 200 万个非平衡集,仅用于音视频匹配。对于表 2 中的零样本评估,我们使用测试集,并使用文本类别名称和附录 B.3 中所述的模板计算每个类别的对数。使用的指标是 top-1 准确率。
ESC-50 (ESC) [59].
我们使用该数据集以零样本方式评估学习到的表征。这里的任务是环境声音分类(ESC)。它由 2000 个 5 秒钟的音频片段组成,分为 50 个类别。它预定义了 5 次评估,每次评估由 400 个测试音频片段组成。在这项工作中,我们对每一折的评估集进行 0 次预测,并报告 5 折的平均性能。为便于计算,我们只使用第一折叠进行消融。所使用的指标是 top-1 准确率。
Clotho (Clotho) [17].
这是一个来自 Freesound 平台的带有文字说明的音频数据集。它由分别包含 2893 个音频片段和 1045 个音频片段的开发集和测试集组成,每个片段都与 5 个说明相关联。我们考虑文本→音频检索任务,并将 5 个相关说明中的每个说明视为单独的测试查询,然后从音频片段集中进行检索。使用的度量标准是 recall@K,即如果在检索的前 K 个音频片段中检索到了 ground truth 音频,则假定给定的测试查询被正确解决。
AudioCaps (AudioCaps) [37].
这是一个来自 YouTube 并附有文字说明的视听片段数据集。它由前面所述的 Audioset 数据集中的片段组成。我们使用 [53] 中提供的拆分方法1,删除了与 VGGSound 数据集重叠的片段。我们最终得到 48198 个训练片段,418 个验证片段和 796 个测试片段。我们只使用测试集对我们的模型进行零样本评估。任务是文本→音频检索,使用 recall@K 进行评估。
VGGSound (VGGS) [8].
该数据集包含约 20 万个长度为 10 秒的视频片段,注释了 309 个声音类别,包括人类动作,发出声音的物体和人与物体之间的互动。我们仅使用测试集(包含 14073 个片段)中的音频进行 0 次拍摄分类。评估采用 top-1 准确率指标。
SUN RGB-D (SUN).
我们使用 SUN RGB-D [69] 数据集训练集中提供的注册 RGB 和深度图(5K 对)来训练我们的模型。我们按照文献[21]分两步对深度图进行后处理–1)使用填充深度值;2)将深度图转换为差异值,以便进行比例归一化处理。该数据集仅用于训练,因此我们不使用任何元数据或类别标签。
SUN Depth-only (SUN-D).
我们只使用 SUN RGB-D [69] 数据集 val 分割中的~5K 深度图,并将其标记为 SUN Depth-only。该数据集仅用于评估,我们不使用 RGB 图像。我们对深度图的处理类似于 SUN RGB-D(填充深度,转换为色差)。我们使用数据集中的 19 个场景类别,并使用其类别名称来构建零样本分类模板。
NYU-v2 Depth-only (NYU-D).
我们仅使用NYU-v2 仅深度数据集 [66] 中的 794 个 val set 深度图进行评估。我们对深度图进行了类似于 SUN Depth-only 的后处理。我们使用数据集中的 10 个场景类别名称。第 10 个场景类别名为 “other”,对应 18 个不同的语义类别:
['basement', 'cafe', 'computer lab', 'conference room', 'dinette', 'exercise room', 'foyer', 'furniture store', 'home storage', 'indoor balcony', 'laundry room', 'office kitchen', 'playroom', 'printer room', 'reception room', 'student lounge', 'study', 'study room']
在零样本评价中,我们计算第 10 个类别的余弦相似度,即这 18 个类别名称中的最大余弦相似度。
LLVIP (LLVIP).
LLVIP 数据集[32]由 RGB 图像和热图像(红外弱光)对组成。该数据集是在室外环境中使用固定相机观测街景时收集的,包含在弱光下拍摄的 RGB 图像和红外图像(8~14um 频率)。RGB 热图像对已在数据集发布中登记。训练时,我们使用包含 12025 对 RGB 图像和红外图像的 train 集。评估时,我们使用包含 3463 对 RGB 和热图像的 val set。由于原始数据集是为检测而设计的,因此我们对其进行后处理,以完成二分类任务。我们裁剪掉行人边界框和随机边界框(与行人的长宽比和大小相同),以创建一个总计 15809 个框(7931 ‘person’ boxes)的平衡集。在零样本分类中,我们对 ‘person’ 类使用以下类名:['person', 'man', 'woman', 'people'],对背景类使用:['street', 'road', 'car', 'light', 'tree']。
Ego4D (Ego4D) [23].
对于 Ego4D 数据集,我们考虑的任务是场景分类。在 Ego4D 数据集中的 9,645 个视频中有 108 个独特的场景。我们过滤掉了所有标注了一个以上场景的视频,这样就有 7,485 个视频只标注了一个场景。对于每个视频,我们选择所有包含同步 IMU 信号和对齐旁白的时间戳。我们对每个时间戳周围的 5 秒钟片段进行采样。数据集被随机分割,这样我们就有 510,142 个片段用于训练,68,865 个片段用于测试。在训练过程中,我们只使用视频帧及其相应的 IMU 信号。我们使用测试片段来衡量零样本场景分类性能,其中 IMU 信号的每个片段都被分配了视频级场景标签作为其 groud truth。
A.1. Data Representations
我们使用标准的 RGB 和 RGBT 表示图像和视频。对于视频,我们使用 2 帧剪辑,灵感来自最近关于 ViT 式视频架构的研究 [16, 71],其中一个视频片段为 2×16×16 (T×H×W )。我们扩大了视觉编码器的权重以处理时空片段,并在推理时汇总多个 2 帧片段的特征。因此,我们可以在视频中直接使用根据图像-文本数据训练的模型。
我们使用单通道图像来处理热数据(thermal data),因为这是当前红外热传感器返回数据的自然形式[32]。对于单视角深度,我们尝试了不同的编码方式,包括 Kinect 等传感器返回的绝对深度[66],反深度[62],色差[62]和 HHA[25, 26]。总的来说,我们发现色差表示法(单通道图像)效果最好。对于音频,我们使用原始波形处理成 mel-spectrograms [22],如正文所述。对于 IMU,我们使用 6 × T 张量来表示 IMU 传感器随时间变化的读数序列。
B. Evaluation details
我们现在描述在这项工作中使用的评估设置。
B.1. Inference implementation details
Audio/Video: 对于这两种时态(无论是在预训练时一起操作还是在推理时分别操作),我们都会抽取固定长度的片段进行操作。在训练过程中,我们随机抽取一个片段,长度一般为 2 秒。在推理时,我们对多个片段进行均匀采样,以覆盖输入样本的全部长度。例如,对于 5 秒的 ESC 视频,我们将取样 ? 5 2 ? = 3 个片段。对于视频片段,我们从每个片段中抽取固定数量的帧。对于音频,我们以 16KHz 的频率对每个原始音频波形进行采样处理,然后使用 25ms 的汉明窗口(跳频长度为 10ms)提取 128 个频点的对数融化频谱图。因此,对于 t 秒的音频,我们会得到 128 ×100t 维的输入。
IMU: 对于 IMU,我们以与旁白对齐的时间戳为中心,采样固定长度的 5 秒钟片段。对于每个片段,我们会得到一个 6×2000 维的输入,并以每个片段为独立测试样本,测量场景分类的零样本性能。
B.2. Few-shot evaluation details
对于图 3 中使用 ESC 和 SUN 数据集得出的小样本(few-shot)结果,我们对每个类别抽取了 k 个训练样本,其中 k∈ {1, 2, 4, 8}。我们固定了 k 个样本,使我们的模型和基线模型在训练时使用的样本完全相同。对于包括基线在内的所有小样本评估,我们都冻结了编码器参数,只训练线性分类器。
Audio: 在使用 ESC 进行音频小样本训练时,我们的模型和基线使用学习率为 1.6 × 10-3,权重衰减为 0.05 的 AdamW 进行训练,共训练 50 个 epoch。
Depth:对于使用 SUN 进行的小样本深度训练,我们的模型和基线使用 AdamW 进行训练,学习率为 10-2,权重衰减为 0.05,训练时间为 60 个epoch。
B.3. Zero-shot evaluation details
Query Templates。在所有评估中,我们都使用了 CLIP [60] 的默认模板集。请注意,由于我们只使用与图像相关的语义/文本监督,因此对于音频和深度等非视觉模态,我们也使用了相同的模板。
B.4. Qualitative evaluation details
Cross-modal nearest neighbors.
我们对温度缩放后的嵌入特征进行检索。使用余弦距离计算最近邻。在图 1 中,我们展示了来自 ESC 的音频检索,来自 IN1K 和 COCO 的图像检索,来自 SUN-D 的深度检索以及来自 AudioCaps 的文本检索。
Embedding arithmetic.
在运算时,我们再次使用温度缩放后的嵌入特征。我们对特征进行 ?2 归一化处理,并将缩放 0.5 后的嵌入特征相加。如上所述,我们利用组合特征使用余弦距离执行近邻检索。在图 1 中,我们展示了 IN1K 和 ESC 的图像和音频组合,并展示了 IN1K 的检索结果。
Audio→Image Generation.
在根据音频片段生成图像方面,我们依靠的是内部复制的 DALLE-2 实现[61]。在 DALLE-2 中,为了根据文本提示生成图像,图像生成模型依赖于由预训练的 CLIP-L/14 文本编码器生成的文本嵌入。由于 IMAGEBIND 自然地将 CLIP 的嵌入空间与本文提出的其他模态的嵌入空间进行了对齐,因此我们可以升级 DALLE-2 模型,用这些新的未见模态来生成图像。在 DALLE-2 的图像生成模型中,我们只需使用 IMAGEBIND 音频编码器生成的温标音频嵌入作为 CLIP 文本嵌入的代理,即可实现音频到图像的零样本生成。
Detecting objects using audio.
我们使用 IMAGEBIND ViT-B/32 编码器从 ESC 验证集中提取所有音频描述符,总共得到 400 个描述符。我们使用现成的基于 CLIP 的 Detic [88] 模型,并将音频描述符用作 Detic 的分类器,以取代基于 CLIP 文本的 “类” 嵌入。图 5 中的定性结果使用了 0.9 的分数阈值。
C. Pretraining details
C.1. Best setup
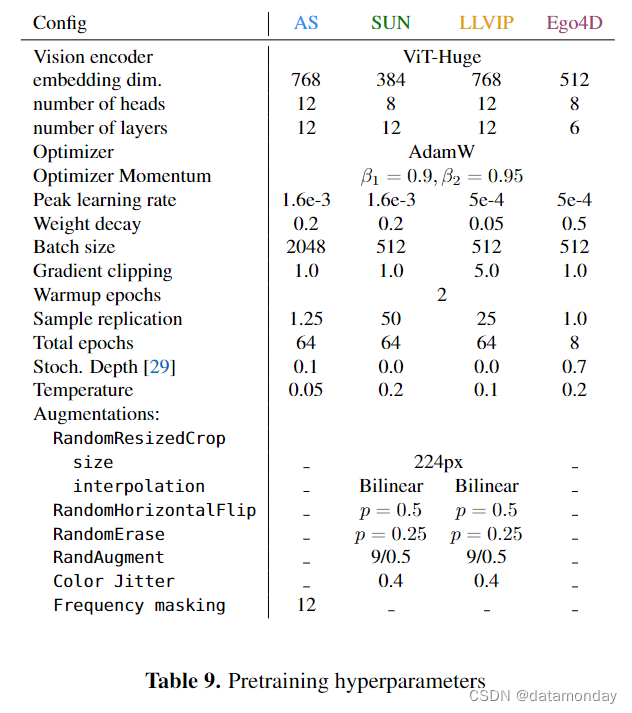
在表 9 中,我们详细介绍了用于对表 4 中的每个模型进行预训练的超参数。我们的实验是在 32GB V100 或 40GB A100 GPU 上完成的。
Contrastive loss batch size vs. modalities.
虽然对比损失确实需要更大的批处理量,但这一要求并没有随着模态数量的增加而增加。如附录 B 所述,我们的实验(表 2)一次采样一对模态的迷你批次:(视频,音频)的批次大小为 2K,(图像,深度),(图像,热)和(视频,IMU)的批次大小为 512。这些批次大小小于之前工作中使用的大于 32K 的批次大小[10, 60]。
Combining modalities.
在表 4 中,我们展示了将音频和视频模态相结合的结果。我们通过从每个样本的两种模态中提取嵌入,并计算这些嵌入的线性组合来进行组合。我们将视频的权重定为 0.95,音频的权重定为 0.05,结果发现这种组合的效果最好。
C.2. Ablation setup
我们在第 5 节的评估中使用了以下设置。与最佳设置不同的是,所有消融实验的视觉编码器和特定模态编码器都使用了 ViT-Base。除非另有说明,否则模型都进行了 16 个epoch的训练。
表 5b 详细说明了线性头和 MLP 头之间的差异: 在我们的实验中,MLP 头并没有提高性能。

D. Additional Results
Qualitative results.
我们在附带的视频中显示了其他结果(以及音频)。
Practical applications of disparate modalities.
例如,由于 IMU 传感器无处不在(手机,AR/VR 头显,健康追踪器),IMAGEBIND 允许用户使用文本查询搜索 IMU 数据库(无需 IMU 文本对训练)。基于 IMU 的文本搜索可应用于医疗保健/活动搜索。例如,在图 7 中,我们展示了给定文本搜索查询的 IMU(及附带视频)检索示例。检索到的 IMU 样本显示为 3 通道加速计(Acc)和陀螺仪(Gyro)记录,与文本查询相匹配。

E. Additional Ablations
Design choices in losses.
由于特定模态编码器的训练是为了与冻结图像编码器保持一致,因此我们尝试使用 ?2 回归目标。对于 ZS SUN 的 top-1 准确率,我们观察到回归作为唯一目标(25.17%)或与对比目标(29.04%)共同使用时都有不错的表现。但是,与只使用对比目标(31.74%)相比,回归目标的性能并没有提高。
F. Ethical considerations
IMAGEBIND 可学习多种模态的联合嵌入。这种嵌入旨在将不同模态中语义相关的概念联系起来。然而,这种嵌入也可能会产生非故意的关联。因此,包括IMAGEBIND在内的联合嵌入模型必须从衡量这种关联及其影响的角度进行仔细研究。IMAGEBIND 利用的是基于大型网络数据的预训练模型所学习到的图像-文本嵌入,不同的研究[60]都证明了该模型存在偏差。为了学习音频,热,深度和 IMU 等其他模态的联合嵌入,我们利用了附录 A 中提到的数据集。因此,这些联合嵌入只限于数据集中的概念。例如,我们使用的 thermal 数据集仅限于室外街道场景,而 depth 数据集仅限于室内场景。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!