HTTP协议请求详解
2023-12-14 00:22:37
??????今天给大家分享的是 HTTP 请求部分的基础知识。
🛩?🛩?🛩?希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教,大家一起学习交流!
??????动动你们发财的小手,点点关注点点赞!在此谢过啦!哈哈哈!😛😛😛


目录
?一、HTTP请求格式

为什么 HTTP 请求中要存在空行呢?
- 因为 HTTP 协议并没有规定报头部分的键值对有多少个,空行就相当于是 "报头的结束标记", 或者是 "报头和正文之间的分隔符"。
- HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的,如果没有这个空行, 就会出现 "粘包问题"。
二、 认识 URL?
2.1 URL基本格式
? ? ? ?平时我们俗称的
"
网址
"
其实就是说的
URL (Uniform Resource Locator
统一资源定位符
),互联网上的每个文件都有一个唯一的URL
,它包含的信息指出文件的位置以及浏览器应该怎么处理它,URL 的详细规则由因特网标准
RFC1738
进行了约定。
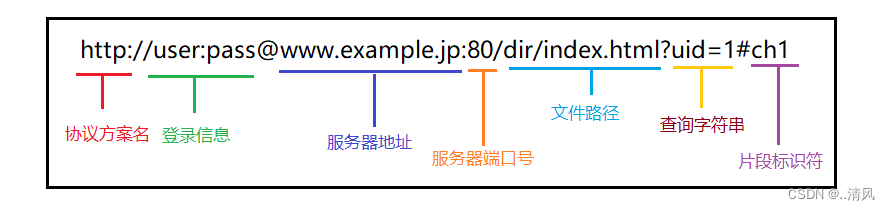
一个具体的
URL:
https://v.bitedu.vip/personInf/student?userId=10000&classId=100
可以看到, 在这个 URL 中有些信息被省略了。
- https : 协议方案名. 常见的有 http 和 https, 也有其他的类型。(例如访问 mysql 时用的 jdbc:mysql )
- user:pass : 登陆信息. 现在的网站进行身份认证一般不再通过 URL 进行了,一般都会省略
- v.bitedu.vip : 服务器地址,?此处是一个 "域名", 域名会通过 DNS 系统解析成一个具体的 IP 地址。
- 端口号: 上面的 URL 中端口号被省略了,当端口号省略的时候, 浏览器会根据协议类型自动决定使用哪个端口。例如 http 协议默认使用 80 端口, https 协议默认使用 443 端口.
- /personInf/student : 带层次的文件路径。
- userId=10000&classId=100 : 查询字符串(query string),本质是一个键值对结构,键值对之间使用 & 分隔,键和值之间使用 = 分隔。
- 片段标识: 此 URL 中省略了片段标识. 片段标识主要用于页面内跳转。
关于 query string?
query string 中的内容是键值对结构,其中的 key 和 value 的取值和个数, 完全都是程序猿自己约定的,我们可以通过这样的方式来自定制传输我们需要的信息给服务器。
URL 中的可省略部分
- 协议名: 可以省略, 省略后默认为 http://
- ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性),省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致。
- 端口号: 可以省略,省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自动设为 443。
- 带层次的文件路径: 可以省略. 省略后相当于 / ,有些服务器会在发现 / 路径的时候自动访问/index.html
- 查询字符串: 可以省略
- 片段标识: 可以省略
?关于 URL encode
- 像 / ? : 等这样的字符, 已经被url当做特殊意义理解了,因此这些字符不能随意出现。比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义。
- 转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
例如:

?"+" 被转义成了 "%2B" 。
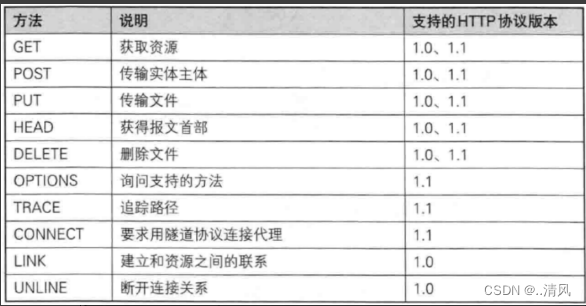
三、认识方法 method
3.1 GET 方法?
? ? ? ? GET
是最常用的
HTTP
方法,
常用于获取服务器上的某个资源。在浏览器中直接输入 URL,
此时浏览器就会发送出一个
GET
请求。
另外, HTML
中的
link, img, script
等标签
,
也会触发
GET
请求。
使用 Fiddler 观察 GET 请求
打开
Fiddler,
访问 搜狗主页
,
观察抓包结果。

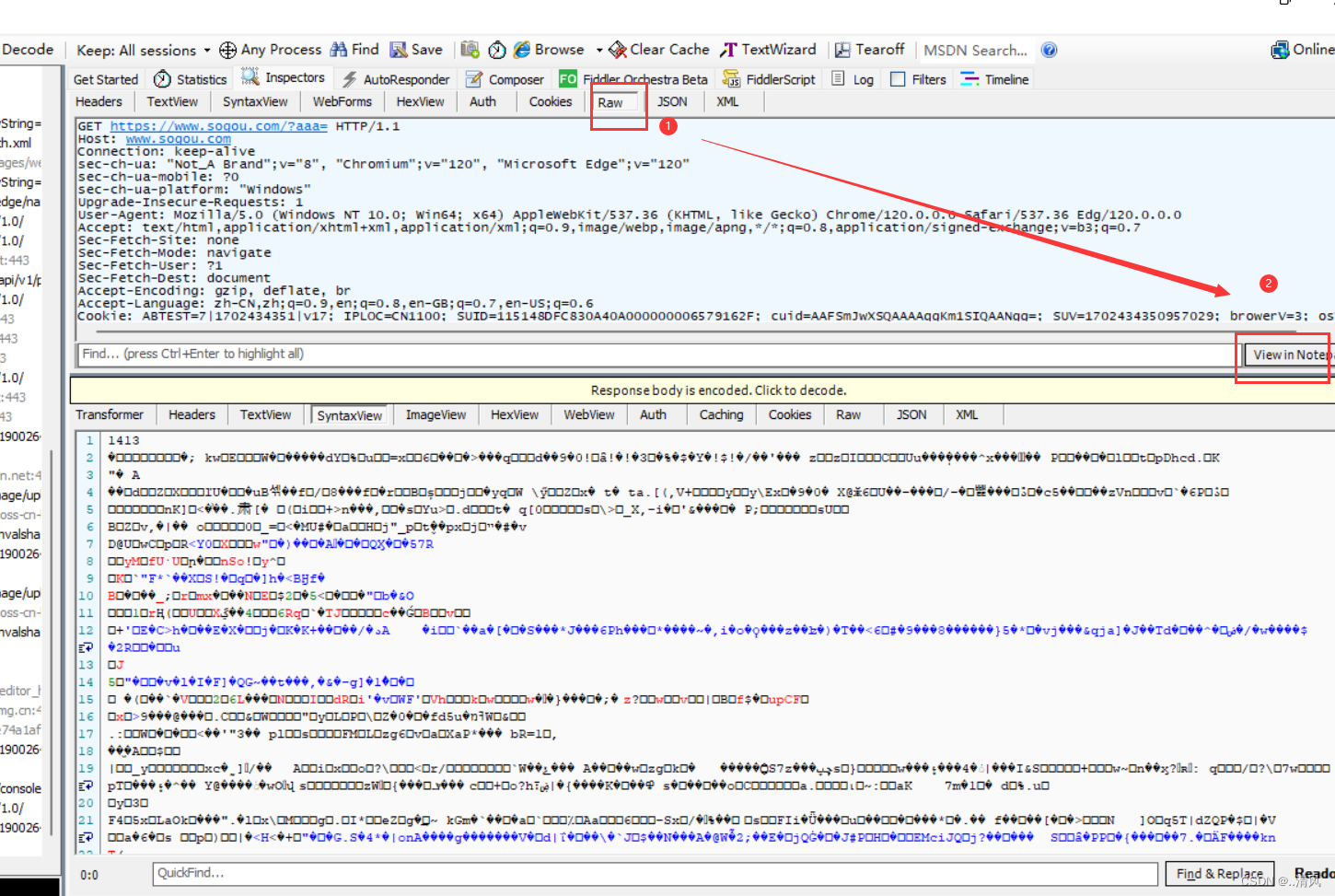

GET 请求的特点?
- 首行的第一部分为 GET
- URL 的 query string 可以为空, 也可以不为空
- header 部分有若干个键值对结构
- body 部分为空
3.2 POST 方法?
? ? ? ? ? ?POST
方法也是一种常见的方法,
多用于提交用户输入的数据给服务器
(
例如登陆页面
),通过 HTML
中的
form
标签可以构造
POST
请求
,
或者使用
JavaScript
的
ajax
也可以构造
POST
请求。
使用 Fiddler 观察 POST 方法(随便开一个登录的页面抓包即可)

POST 请求的特点 ?
- 首行的第一部分为 POST
- URL 的 query string 一般为空 (也可以不为空)
- header 部分有若干个键值对结构
- body 部分一般不为空,body 内的数据格式通过 header 中的 Content-Type 指定,body 的长度由header 中的 Content-Length 指定
GET 和 POST 的区别?
- 语义不同: GET 一般用于获取数据, POST 一般用于提交数据
- GET 的 body 一般为空, 需要传递的数据通过 query string 传递, POST 的 query string 一般为空, 需要传递的数据通过 body 传递
- GET 请求一般是幂等的, POST 请求一般是不幂等的(如果多次请求得到的结果一样, 就视为请求是幂等的)
- GET 可以被缓存, POST 不能被缓存
注意事项:
- ?关于语义: GET 完全可以用于提交数据, POST 也完全可以用于获取数据
- 关于幂等性: 标准建议 GET 实现为幂等的,实际开发中 GET 也不必完全遵守这个规则
- 关于安全性: 有些资料上说 "POST 比 GET 请安全",?这样的说法是不科学的,是否安全取决于前端在传输密码等敏感信息时是否进行加密, 和 GET POST 无关
- 关于传输数据量: 有的资料上说 "GET 传输的数据量小, POST 传输数据量大",这个也是不科学的, 标准没有规定 GET 的 URL 的长度, 也没有规定 POST 的 body 的长度,传输数据量多少, 完全取决于不同浏览器和不同服务器之间的实现区别
- 关于传输数据类型: 有的资料上说 "GET 只能传输文本数据, POST 可以传输二进制数据",这个也是不科学的,GET 的 query string 虽然无法直接传输二进制数据, 但是可以针对二进制数据进行 url encode
3.3 其他方法?
- PUT 与 POST 相似,只是具有幂等特性,一般用于更新
- DELETE 删除服务器指定资源
- OPTIONS 返回服务器所支持的请求方法
- HEAD 类似于GET,只不过响应体不返回,只返回响应头
- TRACE 回显服务器端收到的请求,测试的时候会用到这个
- CONNECT 预留,暂无使用
四、认识请求报头(Header)?
header
的整体的格式也是
"
键值对
"
结构,
每个键值对占一行,
键和值之间使用分号分割。这里我们了解几个常见的即可。
- Host :表示服务器主机的地址和端口
- Content-Length :表示 body 中的数据长度
- Content-Type:表示请求的 body 中的数据格式
- User-Agent (简称 UA)
表示浏览器
/
操作系统的属性,
形如:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/91.0.4472.77 Safari/537.36
- Windows NT 10.0; Win64; x64 表示操作系统信息。
- AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 表示浏览器 信息。?
- Referer
表示这个页面是从哪个页面跳转过来的,
形如
https://v.bitedu.vip/login
如果直接在浏览器中输入
URL,
或者直接通过收藏夹访问页面时是没有
Referer
的。
- Cookie
? ? ? ? Cookie 中存储了一个字符串
,
这个数据可能是客户端
(
网页
)
自行通过
JS
写入的
,
也可能来自于服务器
(
服务器在 HTTP
响应的
header
中通过
Set-Cookie
字段给浏览器返回数据
)。
? ? ? ?往往可以通过这个字段实现
"
身份标识
" 的功能,
每个不同的域名下都可以有不同的 Cookie, 不同网站之间的 Cookie 并不冲突。
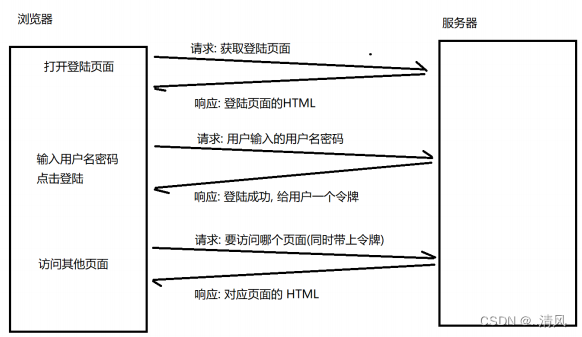
? ? ? 比如,有些时候,登录了一个网站之后,后续再访问这个网站的其他页面,都不必重新登录。为了实现身份识别的效果,不仅需要cookie来支持,也需要一个session机制来支持。首次访问网站并登录成功,网站会设定一个身份标识sessioId,身份标识通过服务器返回给浏览器,并保存再cookie中,接下来要访问该网站的其他页面时,cookie会存在于请求报头中,向服务器发出请求,这样就起到了身份识别效果。
?五、认识请求正文
那我就抓取一下当前写博客的这个页面:
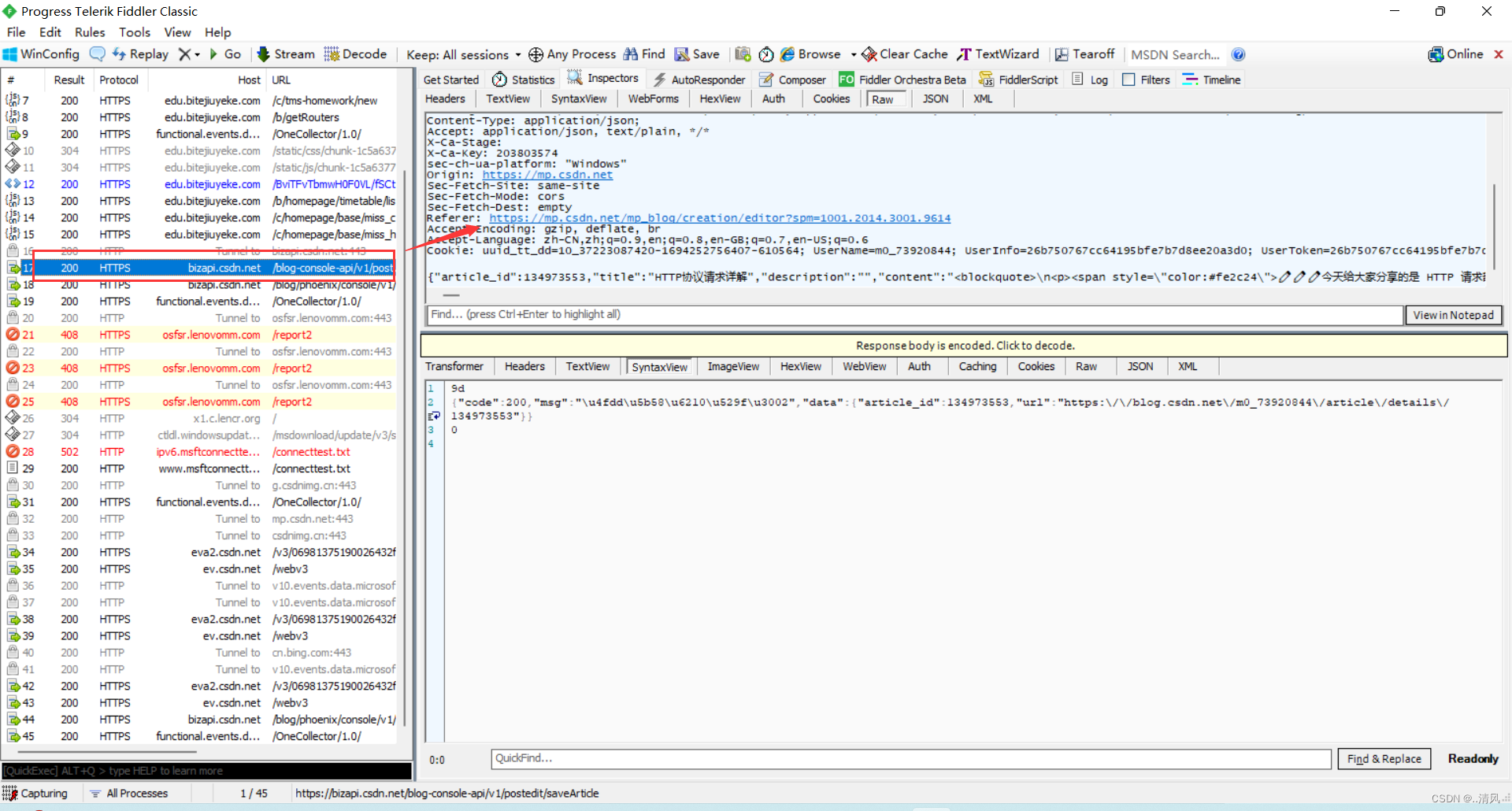
空行下面的便是正文部分:?

🌈🌈🌈好啦,今天的分享就到这里!
🌈🌈🌈希望各位看官读完文章后,能够有所提升!
🎉🎉🎉创作不易,还希望各位大佬支持一下!
??????点赞,你的认可是我创作的动力!
???收藏,你的青睐是我努力的方向!
??????评论:你的意见是我进步的财富!

文章来源:https://blog.csdn.net/m0_73920844/article/details/134973553
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!