【LeetCode刷题笔记(6-1)】【Python】【三数之和】【哈希表】【中等】
三数之和
三数之和
题目描述
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。
请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例
示例1
- 输入:nums = [-1,0,1,2,-1,-4]
- 输出:[[-1,-1,2],[-1,0,1]]
示例2
- 输入:nums = [0,1,1]
- 输出:[]
- 解释:唯一可能的三元组和不为 0 。
示例3
- 输入:nums = [0,0,0]
- 输出:[[0,0,0]]
- 解释:唯一可能的三元组和为 0 。
提示
- 3 <= nums.length <= 3000
- -105 <= nums[i] <= 105
解决方案1:【三层遍历查找】
对于解决【三数之和】这个问题,一种直观的解法是三层循环枚举所有可能的三元组,然后判断它们的和是否为零,但是这样的时间复杂度是 O(n3),对于较大的数组来说是不可接受的。
解决方案2:【哈希表】+【两层遍历】
在探讨【三数之和】这一算法题之前,我相信许多读者已经对【两数之和】有所涉猎。在我们深入理解题目要求时,我们明确了解决【两数之和】问题的核心是【如何高效查找目标值】。而【哈希表】以其迅速的查找速度脱颖而出,成为解决此类问题的得力助手。
现在,摆在我们面前的是【三数之和】问题,它与【两数之和】有着诸多相似之处。因此,我们很自然地会联想到运用【哈希表】来助力解决。这种思维跳跃不仅体现了我们对已知知识的灵活运用,更展示了我们在面对新问题时的敏捷思维。
与【三层遍历】相比,【哈希表】是一种以空间换时间的解决方案。首先,数组nums中可能存在大量值相同但索引不同的元素,如下所示:
nums1 = [0] * 10 + [1] * 10 + [-1] * 10
print(nums1)
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
对于这个问题而言,这些大量重复的元素显然是冗余的。我们的核心目标是在数组中找到N个不重复的三元组,在这些三元组中,元素之和为0 ==> 除了[0, 0, 0]这种特殊情况,其它任何数都不可能在一个三元组中重复三次(和不可能为0)。那么nums1实际上等价于数组[0, 0, 0, 1, 1, -1, -1] ==> 这意味着我们可以先对原数组nums先进行【去重】操作,形成一个新数组new_nums,在新数组中,除了0可以重复三次,其它值至多重复两次。
原数组【去重】的重要意义:某些情况可以显著降低整体算法的时间复杂度。比如说上面代码里的nums1,原来有30个元素,那么两层循环遍历的时间复杂度是O(n2),n=30; 如果对nums1进行去重,去重后的新数组实际上只包含7个元素,两层循环遍历的时间复杂度从O(302)将至O(72)!
原数组【去重】代码如下:
# 创建哈希表,记录去重后的新数组元素,方便后续遍历查找目标值。
hash_map = {} # 哈希表的键为新数组元素值,值为元素值在新数组的新下标num_idx
num_idx = 0 # 新数组的下标初始化为0
new_nums = [] # 用新的数组记录去重后的数组
# 遍历原数组
for idx, num in enumerate(nums):
# 当前元素不在哈希表中
if num not in hash_map:
hash_map[num] = [num_idx] # 创建新的键-值对,记录该元素
# 记录去重后仍保留的数组元素
new_nums.append(num)
num_idx += 1
else: # 当前元素已在哈希表中
# 如果该元素已在哈希表中记录两次
if len(hash_map[num]) == 2:
if num == 0: # 除非该元素是0,否则不再记录
hash_map[num].append(num_idx)
new_nums.append(num)
num_idx += 1
# 如果该元素已在哈希表中记录一次
elif len(hash_map[num]) == 1:
# 在哈希表中再次记录该元素
hash_map[num].append(num_idx)
# 新数组同时记录该元素
new_nums.append(num)
num_idx += 1
# 其它情况不做任何处理
else:
pass
当有了哈希表hash_map后,便可以通过【两层遍历】在哈希表中查找目标值来得到有效的三元组。
算法步骤:
- 第一层循环:遍历数组元素
nums[i]—>i从0–>n,n为新数组的元素个数,执行步骤(2); - 第二层循环:遍历数组元素
nums[j]—>j从i+1–>n,n为新数组的元素个数,执行步骤(3); - 若
nums[i] + nums[j]的相反数-(nums[i] + nums[j])不存在于哈希表hash_map中,则返回步骤(1); 若存在,说明找到可能正确的三元组,执行步骤(4); - 遍历哈希表中键【
-(nums[i] + nums[j])】对应的每个索引k—> k至多有三个不同的值(分别是三个0元素所对应的索引),执行步骤(5); - 若
k=i或者k=j, 说明这个元素三元组将出现重复的元素(同一索引),不符合题意,返回步骤(1)<— 第一次去重:避免在元素三元组中出现同一元素(同索引的元素) ;若k!=i and k!=j,说明当前的三个索引i,j,k互不相同,可能是正确的三元组,执行步骤(6);
【细节】:尽管三个索引i,j,k互不相同,但仍然不能保证由索引三元组对应的元素三元组不会在结果列表中出现重复 <— 不同的索引三元组可能对应同一种元素三元组; - 参考字母异位词分组的解决方案,对当前三个索引所生成的结果列表
[new_nums[k], new_nums[i], new_nums[j]]进行【排序】。因为一旦出现重复的三元组结果(如[1, 0, -1] 和[0, 1, -1]),它们虽然顺序不同,但排序结果一定是相同!
检查排序后的元素三元组sorted_result是否存在于哈希表is_used_results中,若已存在,说明出现了重复的元素三元组,不符合题意,返回步骤(1)<— 第二次去重:避免出现重复的元素三元组,尽管三个索引i,j,k互不相同 ;若不存在,说明这个元素三元组是无重复的,执行步骤(7); - 将元素三元组保存于结果列表
result_list中,重复执行步骤1-7,直到循环结束。
【细节】既然已经有一个结果列表result_list记录元素三元组,为什么不直接判断排序后的元素三元组sorted_result是否存在于结果列表result_list中,而是重新创建一个哈希表is_used_results来协助判断?
答:因为哈希表的查找速度非常快!!!,如果在列表中查找,可能会超时!
完整代码如下:
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
# 创建哈希表,记录去重后的新数组元素,方便后续遍历查找目标值。
hash_map = {} # 哈希表的键为新数组元素值,值为元素值在新数组的新下标num_idx
num_idx = 0 # 新数组的下标初始化为0
new_nums = [] # 用新的数组记录去重后的数组
# 遍历原数组
for idx, num in enumerate(nums):
# 当前元素不在哈希表中
if num not in hash_map:
hash_map[num] = [num_idx] # 创建新的键-值对,记录该元素
# 记录去重后仍保留的数组元素
new_nums.append(num)
num_idx += 1
else: # 当前元素已在哈希表中
# 如果该元素已在哈希表中记录两次
if len(hash_map[num]) == 2:
if num == 0: # 除非该元素是0,否则不再记录
hash_map[num].append(num_idx)
new_nums.append(num)
num_idx += 1
# 如果该元素已在哈希表中记录一次
elif len(hash_map[num]) == 1:
# 在哈希表中再次记录该元素
hash_map[num].append(num_idx)
# 新数组同时记录该元素
new_nums.append(num)
num_idx += 1
# 其它情况不做任何处理
else:
pass
result_list = [] # 存放元素三元组
n = len(new_nums)
is_used_results = set() # 创建哈希表,协助判断元素三元组是否重复
for i in range(n):
for j in range(i+1, n):
if -(new_nums[i] + new_nums[j]) in hash_map:
for k in hash_map[-(new_nums[i] + new_nums[j])]: # 查找目标值, 依次返回目标值索引k
if k == i:
continue # 第一次去重,避免元素三元组出现重复的元素
elif k == j:
continue # 第一次去重,避免元素三元组出现重复的元素
else:
sorted_result = tuple(sorted([new_nums[k], new_nums[i], new_nums[j]]))
if sorted_result in is_used_results: # 涉及查找时,用哈希表最快
pass # 第二次去重,避免结果列表中出现重复的元素三元组
else:
result_list.append([new_nums[k], new_nums[i], new_nums[j]])
is_used_results.add(sorted_result)
return result_list
运行结果:
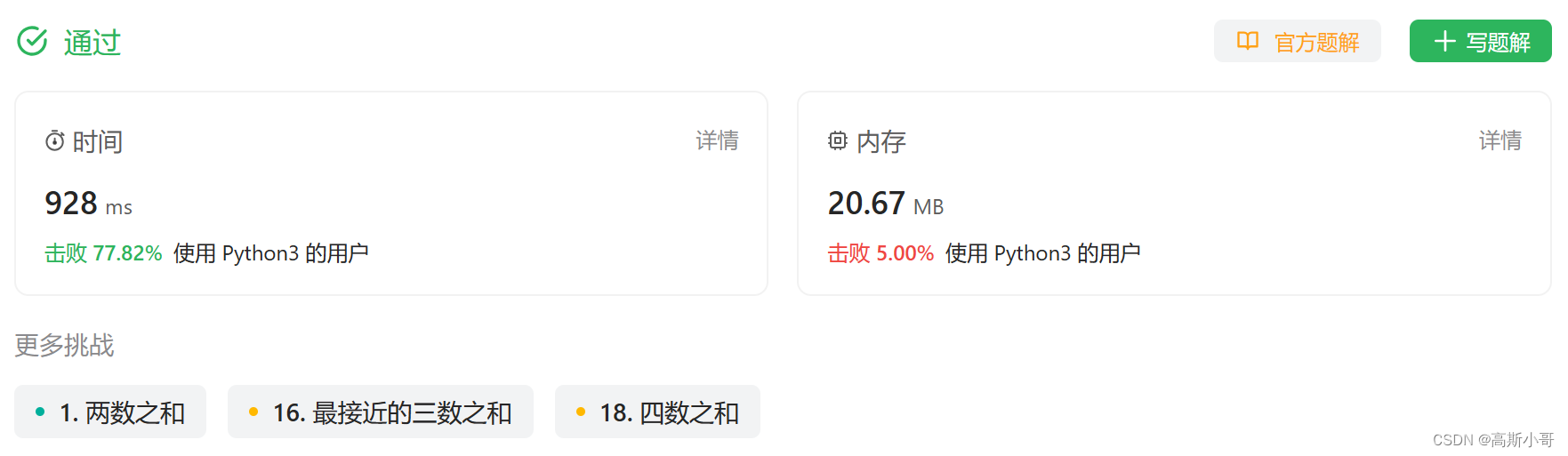
复杂度分析
- 时间复杂度:O(N2),其中 N 是新数组
new_nums元素的数量。- 双层循环遍历新数组 ===> O(N2)
- 空间复杂度:O(N)
- 需要用哈希表和列表存放新数组 ===> O(N)
结束语
- 亲爱的读者,感谢您花时间阅读我们的博客。我们非常重视您的反馈和意见,因此在这里鼓励您对我们的博客进行评论。
- 您的建议和看法对我们来说非常重要,这有助于我们更好地了解您的需求,并提供更高质量的内容和服务。
- 无论您是喜欢我们的博客还是对其有任何疑问或建议,我们都非常期待您的留言。让我们一起互动,共同进步!谢谢您的支持和参与!
- 我会坚持不懈地创作,并持续优化博文质量,为您提供更好的阅读体验。
- 谢谢您的阅读!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!