代码随想录算法训练营第二十天 | 二叉搜索树
目录
力扣题目
用时:2h
力扣题目记录
654.最大二叉树
? ? ? ? 这个题和昨天的中后序构造二叉树很像,就是遍历找到最大值,然后分割区间,递归
class Solution {
private:
// 在左闭右开区间[left, right),构造二叉树
TreeNode* traversal(vector<int>& nums, int left, int right) {
if (left >= right) return nullptr;
// 分割点下标:maxValueIndex
int maxValueIndex = left;
for (int i = left + 1; i < right; ++i) {
if (nums[i] > nums[maxValueIndex]) maxValueIndex = i;
}
TreeNode* root = new TreeNode(nums[maxValueIndex]);
// 左闭右开:[left, maxValueIndex)
root->left = traversal(nums, left, maxValueIndex);
// 左闭右开:[maxValueIndex + 1, right)
root->right = traversal(nums, maxValueIndex + 1, right);
return root;
}
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return traversal(nums, 0, nums.size());
}
};617.合并二叉树
? ? ? ? 这个题目使我深刻体会到了用指针和用值的区别,所以导致题目做的很复杂
用值
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if (root1 == NULL && root2 == NULL)
{
return nullptr;
}
TreeNode* root = new TreeNode();
if (root1 == NULL && root2 != NULL)
{
root->val = root2->val;
root->left = mergeTrees(nullptr, root2->left);
root->right = mergeTrees(nullptr, root2->right);
}
else if (root1 != NULL && root2 == NULL)
{
root->val = root1->val;
root->left = mergeTrees(root1->left, nullptr);
root->right = mergeTrees(root1->right, nullptr);
}
else
{
root->val = root1->val + root2->val;
root->left = mergeTrees(root1->left, root2->left);
root->right = mergeTrees(root1->right, root2->right);
}
return root;
}
};用指针
class Solution {
public:
TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {
if (t1 == NULL) return t2; // 如果t1为空,合并之后就应该是t2
if (t2 == NULL) return t1; // 如果t2为空,合并之后就应该是t1
// 修改了t1的数值和结构
t1->val += t2->val; // 中
t1->left = mergeTrees(t1->left, t2->left); // 左
t1->right = mergeTrees(t1->right, t2->right); // 右
return t1;
}
};700.二叉搜索树中的搜索
? ? ? ?二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
? ? ? ? 基于以上特性,使用递归和迭代都比较方便
递归
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == NULL || root->val == val) return root;
TreeNode* result = NULL;
if (root->val > val) result = searchBST(root->left, val);
if (root->val < val) result = searchBST(root->right, val);
return result;
}
};迭代
一提到二叉树遍历的迭代法,可能立刻想起使用栈来模拟深度遍历,使用队列来模拟广度遍历。
对于二叉搜索树可就不一样了,因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
中间节点如果大于3就向左走,如果小于3就向右走,如图:

所以迭代法代码如下:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
while (root != NULL) {
if (root->val > val) root = root->left;
else if (root->val < val) root = root->right;
else return root;
}
return NULL;
}
};98.验证二叉搜索树
? ? ? ? 基于二叉搜索树的特点,用中序遍历,拿到的应该是一个有序数组
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
public:
bool isValidBST(TreeNode* root) {
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
}
};在递归遍历的过程中直接判断是否有序的话也可以,有两个陷阱
- 陷阱1
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case:
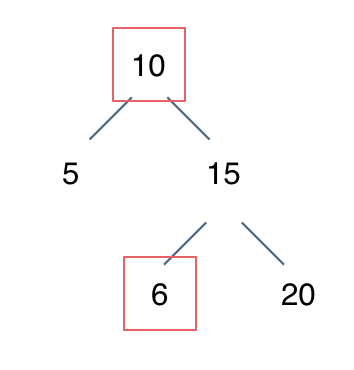
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
- 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值。
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值 又要怎么办呢?文中会解答。
代码如下:
bool left = isValidBST(root->left); // 左
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val; // 中
else return false;
bool right = isValidBST(root->right); // 右
return left && right;
整体代码如下:
class Solution {
public:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val;
else return false;
bool right = isValidBST(root->right);
return left && right;
}
};
以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
如果测试数据中有 longlong的最小值,怎么办?
不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面节点的数值来比较。
代码如下:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};总结
-
了解了二叉搜索树
-
二叉树的题目本质上要依赖于四种遍历方法?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!