阿里巴巴开源异构数据源离线/全量/增量同步工具 - DataX

😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志
🎐 个人CSND主页——Micro麦可乐的博客
🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战
🌺《RabbitMQ》本专栏主要介绍使用JAVA开发RabbitMQ的系列教程,从基础知识到项目实战
🌸《设计模式》专栏以实际的生活场景为案例进行讲解,让大家对设计模式有一个更清晰的理解
如果文章能够给大家带来一定的帮助!欢迎关注、评论互动~
阿里巴巴异构数据源离线同步工具 - DataX
前言
相信作为开发的小伙伴们在公司一定会遇到数据库数据同步的问题,比如SqlServer中的数据同步到Mysql、Mysql同步到Mysql另一个库等等,再比如遇到每天需要全量同步到不同数据库的需求,无论是采用Java代码来实现数据库间的同步还是使用数据库的调度任务处理起来都相当麻烦,如果还有其它的数据库类型,那么会涉及多套sql以及配置,那么有没有更简单的同步工具?答案是有的,就是本篇介绍的DataX
什么是DataX

阿里巴巴的DataX是一款开源的数据交换平台,用于实现不同数据源之间的数据同步和迁移。DataX的设计目标是提供一个通用、高效、易扩展的数据交换框架,适用于多种场景,包括数据仓库构建、数据迁移、数据同步等。
Datax在github上开源地址:https://github.com/alibaba/DataX
以下博主总结了阿里巴巴DataX一些重要特点和信息:
-
多数据源支持: DataX支持从不同种类的数据源抽取数据,包括关系型数据库(MySQL、Oracle等)、NoSQL数据库(MongoDB、HBase等)、大数据存储(Hadoop、Hive等)以及各种文件格式(JSON、CSV等)。
-
多通道传输: DataX支持多通道的数据传输,可以通过并行的方式提高数据传输效率。这对于大规模数据迁移和同步操作非常有用。
-
丰富的插件体系: DataX的插件体系十分丰富,用户可以通过配置选择适用于特定数据源和目标的插件。这种可插拔的架构使得DataX非常灵活,易于扩展和定制。
-
强大的性能优化: DataX在设计上注重性能优化,通过并行处理、内存管理和流式计算等技术手段,提高了数据交换的效率。
-
易用性: DataX提供了可视化的配置界面,使得用户能够通过简单的配置文件来定义数据同步任务。这降低了使用门槛,适用于不同层次的技术人员。
-
开源社区支持: DataX是开源项目,拥有庞大的开源社区支持。用户可以获取源代码、参与讨论、提出建议,使得DataX在不断的演进和改进中。

DataX支持哪些数据
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
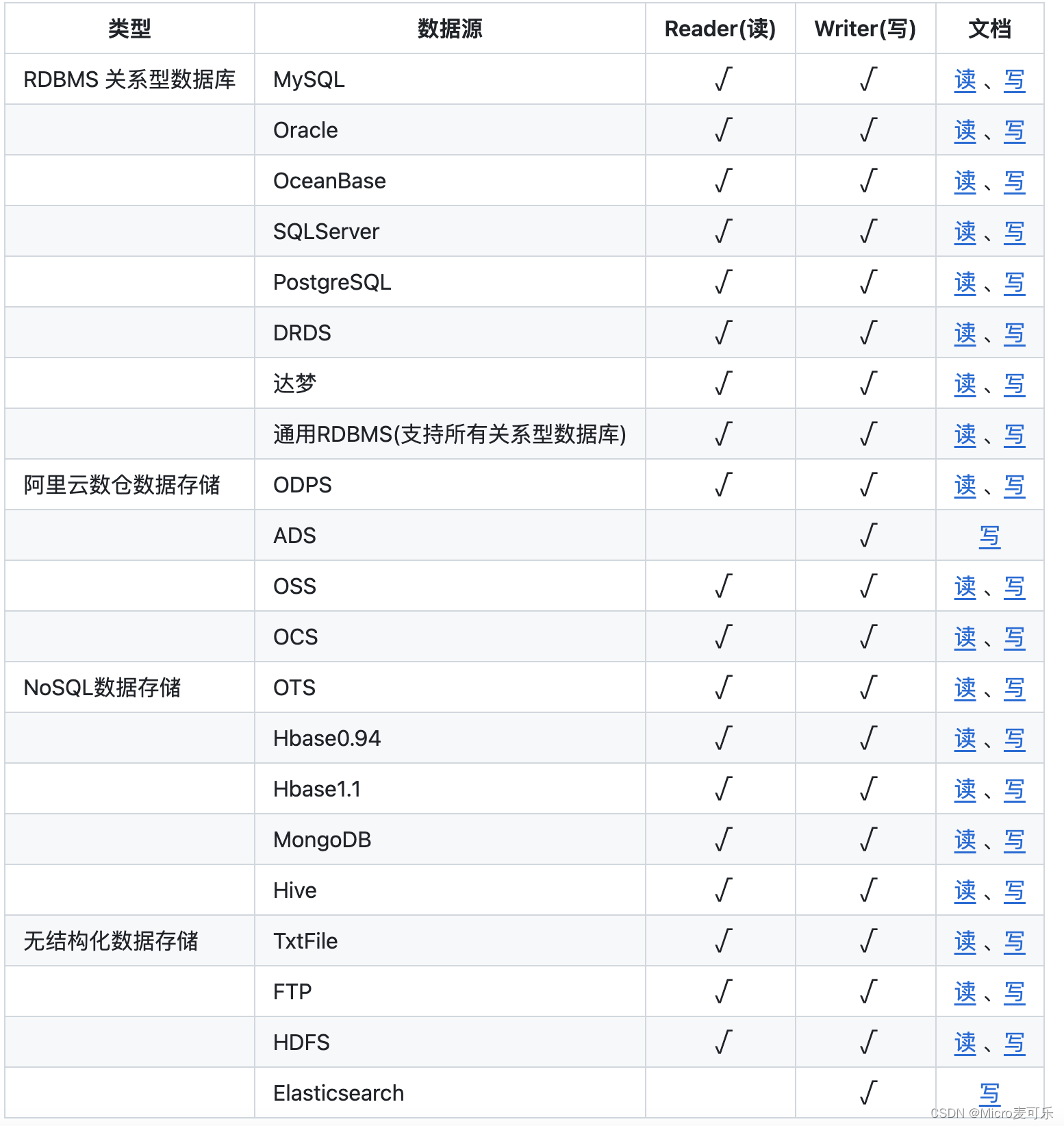
DataX框架设计

Datax的架构采用FrameWork+plugin构建,其中:
-
Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework -
Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端 -
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。
DataX核心架构
DataX 开源版本支持单机多线程模式完成同步作业运行,从整体架构设计非常简要说明DataX各个模块相互关系

Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理
Task:由Job切分出来,是Datax的最小单元,每隔Task负责一部分数据的同步工作
Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5. TaskGroup:负责启动Task
DataX安装
系统要求
jdk1.8+
python运行环境(推荐python2.6.x)
DataX下载有两种方式,一种是直接下载压缩包,另外一种是下载源码自己手动编译,这里我们使用压缩包的方式
下载datax的压缩包:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
下载后上传或移动至自己需要的存放的目录开始解压
tar -zxf datax.tar.gz
进入datax的bin目录,运行自检脚本
cd datax/bin/
python datax.py -r streamreader -w streamwriter
如果看到了生成的JSON配置模版即代表安装成功,如下
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
DataX同步Mysql数据
由于博主本机上只安装了mysql,这里就暂时演示同步mysql的操作,还是通过命令获取配置模板
脚本获取的配置模版会生成在DataX安装目录下job文件夹
python datax.py -r mysqlreader -w mysqlwriter
cd进入job文件夹对生成的配置模版进行对应参数的配置,一下简单标注一些参数说明,具体的其他参数可以参考官方文档,这里就不赘述了
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [], #需要同步的列
"connection": [ #连接信息
{
"jdbcUrl": [],
"table": [] #同步表
}
],
"password": "", #密码
"username": "", #用户名
"where": "" #筛选条件
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [], #写入段的列名,与上面需要同步的值的位置保持一致
"connection": [ #连接信息
{
"jdbcUrl": "",
"table": []
}
],
"password": "", #密码
"preSql": [], #执行写入之前做的事情
"session": [], # DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
"username": "", #用户名
"writeMode": "" #控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
为了方便测试,我们新建两个表,一个有数据一个空数据
CREATE TABLE `goods`(
`id` int(4) not null auto_increment,
`name` varchar(32) not null,
PRIMARY KEY(id)
)
CREATE TABLE `goods2`(
`id` int(4) not null auto_increment,
`name` varchar(32) not null,
PRIMARY KEY(id)
)
INSERT INTO `goods` VALUES (1,'方便面')
INSERT INTO `goods` VALUES (2,'矿泉水')
INSERT INTO `goods` VALUES (3,'花生')
修改模版参数,以博主本机为例
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/test"],
"table": ["goods"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test",
"table": ["goods2"]
}
],
"password": "123456",
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
编辑完成保存最后运行
# 注意博主目录此刻还是在bin目录
python datax.py ../job/mysql2mysql.json
注意控制台输出成功信息后,检查数据表可以看到数据已经同步过去了
总结
本章仅仅演示了mysql间的数据同步,如果需要其它同步,可以在评论区留言或者查阅官方文档。最后总结一下,DataX框架通过插件化架构、任务分治和并发处理、流式计算等设计特点,实现了一个通用、高效、易扩展的数据交换平台。这使得DataX成为企业在构建数据仓库、进行数据迁移和实现数据同步等方面的理想选择。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!