ETL项目实战--学习笔记
ELT基本概念
1,什么时ELT?
E: Extract,数据抽取 => 抽取的是其他数据源中的数据
T: Transform,数据转换 => 将数据转换为统一的格式,消除异常值,缺失值,对于错误的逻辑进行修改
L: Load,数据加载 => 将不同数据源的数据处理后加载到数仓或者输出到指定位置
2,信息孤岛?
,由于业务系统之间各自为政、相互独立造成的数据孤岛现象尤为普遍,业务不集成、流程不互通、数据不共享。这给企业进行数据的分析利用、报表开发、分析挖掘等带来了巨大困难。
将相互分离的业务系统的数据源整合在一起,建立一个统一的数据采集、处理、存储、分发、共享中心。
3,常见的数据存储形式?
数据库中的表
Excel
CSV数据格式、TSV数据格式(其实就是CSV格式的数据,但是分隔符用的是制表位\t)
半结构化数据:数据中的一部分数据是结构化数据或者可以转换为结构化数据
JSON数据格式
XML数据格式
非结构化数据:
markdown文本
word文档
mp3
avi、mp4
ETL实战案例原理图
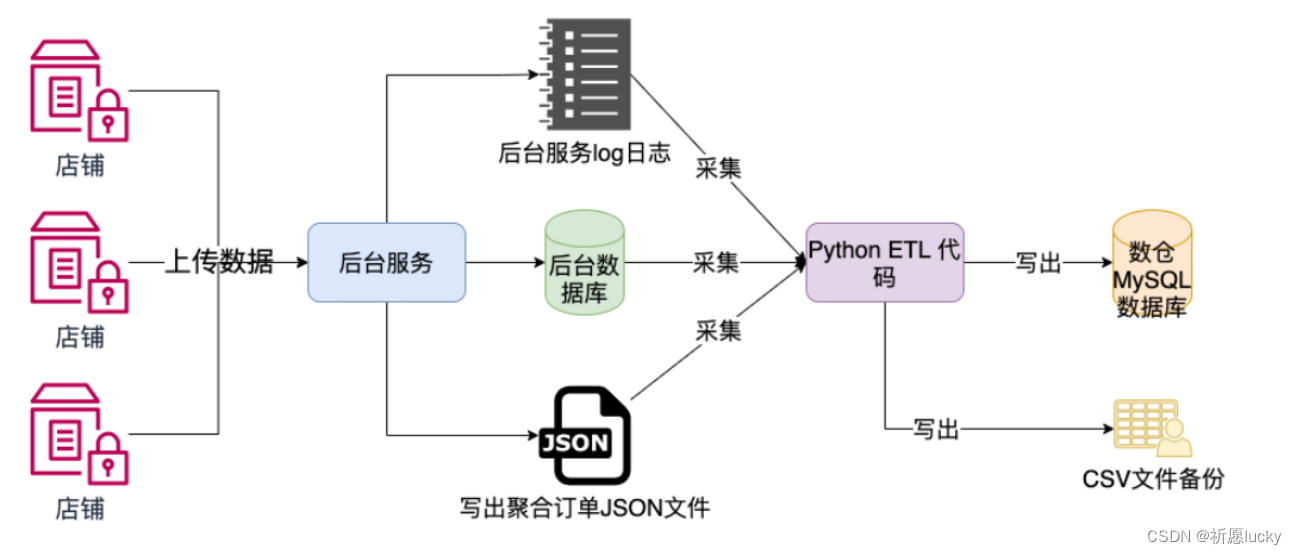
问题1: 这是一个什么行业的业务数据?
零售(电商、新零售)行业的数据
问题2: 这个案例中有哪几种数据源?
订单数据-JSON(Python与JSON)
商品库数据-MySQL(SQL、PyMySQL)
后台日志数据-后台服务log日志文件(文件类型、日志处理)
问题3: 这个案例中有哪几种数据去向?
数据仓库: 此处使用MySQL数据库模拟数据仓库。注:在真实开发场景下,不会使用该服务作为数仓(数据吞吐量不足)
CSV文件备份: 数据内容和数据仓库完全一致,主要为了做数据备份,恢复数据时使用
1,日志业务逻辑
核心思想: 获取全部的日志数据文件,与数据库中存储的已采集数据文件进行对比,得到未采集的数据文件进行操作
功能:实现后台访问日志数据采集的程序
思路:
① 获取后台访问日志文件夹下面有哪些日志文件
② 查询元数据库表中已经被采集的日志文件,来对比确定要采集新的访问日志文件
③ 针对待采集的新访问日志文件,进行数据采集(ETL操作->mysql->csv)
④ 将本次采集的访问日志文件,记录到元数据库的表中
2,商品业务逻辑
核心思想: 采集数据并记录采集的位置(id,行号,索引…),下一次采集先获取上一次采集的位置,然后继续操作
功能:数据源库中商品数据采集的主程序
思路:
① 查询元数据库表,获取上一次采集商品数据中 updateAt 的最大值
② 根据上一次采集商品数据中 updateAt 的最大值,查询数据源库商品表,获取继上一次采集之后,新增和更新的商品数据
③ 针对新增和更新的商品数据,进行数据采集(ETL->mysql->csv)
④ 将本次采集商品数据中的 updateAt 的最大值,保存到元数据库表中
3,订单业务逻辑
核心思想: 获取全部的JSON数据文件,与数据库中存储的已采集数据文件进行对比,得到未采集的数据文件进行操作
功能:实现订单数据采集的程序
思路:
① 获取订单文件夹下面有哪些订单JSON文件
② 查询元数据库表中已经被采集的订单JSON文件,来对比确定要采集新的订单JSON文件
③ 针对待采集的新订单JSON文件,进行数据采集(ETL操作->mysql->csv)
④ 将本次采集的订单JSON文件,记录到元数据库的表中
4,ETL项目结构
5个目录:
- config:保存整个ETL工程的配置信息
- model:保存项目的数据模型文件
- test:保存单元测试的代码文件
- util:保存项目的工具文件
- learn:保存项目开发过程中的一些基础知识讲解练习文件(实际不需要)
问题: 什么时候创建package 什么时候创建directory?
如果你当前目录中的文件可能被其他文件引用就是用package
如果你当前文件目录中的文件不会被任何文件引用就使用directory 例如: logs learn
注意:目录命名时,如果该目录时package,则文件名称必须为标识符, 如果是directory那么只需要没有中文即可
模块
1,日志模块
import logging
核心理解:
① 导入模块 (自己的文件名不要和内置模块名称重名,否则内置模块无法使用)
② 日志管理对象: 负责日志的收集工作 – 相当于执法记录仪
③ 日志处理器: 负责日志的输出形式管理(终端/文件) - 相当于将记录仪连接的打印机
④ 日志格式: 负责日志的输出格式管理 - 相当于打印机中的墨盒
⑤ 绑定日志处理器到日志对象
⑥ 设置日志级别
⑦ 打印输出日志信息
2,time模块
time.time():获取当前时间的时间戳(以秒为单位)
time.time_ns():获取当前时间的时间戳(以纳秒为单位)
time.localtime():获取当前的本地时间,结果是一个 struct_time 类的对象
time.localtime(时间戳-秒):返回时间戳对应的本地时间,结果是一个 struct_time 类的对象
time.mktime(struct_time对象):返回时间对应的时间戳(秒为单位)
time.strftime(格式化字符串, 日期):将日期数据(struct_time对象)格式化一个字符串
time.strptime(日期字符串,格式化字符串):将日期字符串转换为一个日期数据(struct_time对象)
3,unittest模块
问题1:什么叫单元测试?
对于软件中最小的可测试单元进行检测或检查的方式就是单元测试
问题2: 单元测试在企业开发中一般是谁来写?
如果企业中测试工程师能力极强,可以由他来写,但是通常由开发人员来写,测试人员点击运行查看结果即可
4,os模块
os模块的作用:
os.getcwd():获取当前程序的运行工作路径
os.listdir(目录):获取指定目录下的内容,返回一个list
os.path模块的作用:
os.path.abspath(路径):返回指定路径的绝对路径
os.path.dirname(路径):返回指定路径的上一级路径
os.path.basename(路径):返回指定路径的最后一部分
os.path.join(路径1, 路径2):将两个路径进行拼接
os.path.isfile(路径):判断指定路径是不是一个文件,是返回True,否则返回False
os.path.isdir(路径):判断指定路径是不是一个文件夹,是返回True,否则返回False
5,pymysql模块
pymysql模块六步走
第一步:导入模块
第二步:创建连接
第三步:创建游标
第四步:定义SQL
第五步:执行SQL
第六步:关闭游标,关闭连接
6,函数递归
递归就是某个函数直接或者间接地调用自身的一种设计程序思想,这样原问题的求解就转换为了许多性质相同但是规模更小的子问题。
在实际工作中,递归有多种应用场景:
① 实现复杂的数学计算,如斐波那契数列,求汉诺塔
② 实现文件递归查询,递归查询某个目录以及子目录下的所有文件
递归三要素
① 明确你这个函数想要干什么
② 寻找递归结束条件
③ 找出函数的等价关系式
递归的优缺点
优点:
可以将一个复杂的问题简单化,拆分为多个嵌套的简单问题
使用递归可以减少代码量
缺点:
递归的性能消耗极大
如果递归的调用深度或者递归的出口没有限制完全,在使用时极易造成程序崩溃
递归的使用场景不容易辨别
import time
def recu(n):
if n==1:
return 1
else:
result = recu(n-1)*n
return result
'''
# i为天数
# 关系式 i*2+1
# 出口条件,天数等于i=1
num
f(1) = i*2+1 =3
f(2) = f(1)*2+1 = 7
fn = f(n-1)*2+1
'''
def func2(i):
if i==1:
return i*2+1
return func2(i-1)*2+1
'''
斐波那契数列
1 1 2 3 5 8 13 21 34 55
收敛条件:f(2)= f(1)+0
f(n) = f(n-1)+f(n-2)
'''
def funct2(n):
if n<=2:
return 1
return funct2(n-1)+funct2(n-2)
if __name__ == '__main__':
print(recu(3))
print(func2(3))
start = time.time()
print(funct2(34))
end = time.time()
print(end - start)
项目流程
'''
1,导包
2,创建日志对象
3,创建日志处理器
4,设置格式
5,绑定日志处理器到日志对象
6,设置日志级别
7,打印输出日志1
'''
from config import project_config as conf
import logging
class LoggingUtil(object):
def __init__(self,level = logging.INFO):
# 创建日志对象
self.logger = logging.getLogger()
# 设置日志级别
self.logger.setLevel(level)
def init_logger():
# 创建日志文件处理器
file_Handler = logging.FileHandler(
filename=conf.log_root_path+conf.log_name,
mode='a',
encoding='utf-8'
)
# 设置处理器格式
fmt = logging.Formatter('%(asctime)s - [%(levelname)s] - %(filename)s[%(lineno)d]:%(message)s')
file_Handler.setFormatter(fmt)
#调用类获取里面的日志对象,并重新起一个名字
logger = LoggingUtil().logger
# 绑定处理器与日志对象
logger.addHandler(file_Handler)
return logger
if __name__ == '__main__':
logger = init_logger()
timeLearn
import time
# python中time模块的相关方法
# 获取当前时间的时间戳
print(time.time())
print("输出一个数字")
# 睡眠多少秒,以秒为单位
# timeLearn.sleep(2)
print("两秒后输出另一个数字")
print(time.time())
# 输出当前时间戳,以ns为单位
print(time.time_ns())
#获取当前的本地时间,结果是一个struct_time类的对象
print(time.localtime())
struct_time = time.localtime()
print(struct_time.tm_year)
# 可以将时间戳转换为struct_time对象形式
print(time.localtime(1703488853.8195534))
# 将时间转换为时间戳
print(time.mktime(struct_time))
#把struct_time对象类转换为标准的时间子字符串格式(2023-12-25 15-26-13)
ts = time.strftime('%Y-%m-%d %H-%M-%S',time.localtime())
print(ts)
#将日期字符串,格式化字符串,转换为struct_time
st_time = time.strptime('2023年12月25日','%Y年%m月%d日')
print(st_time)
# 总结常用的只有四个
# 获取时间戳字符串
print(time.time())
time.sleep(0.1)
# 以结构化对象(struct_time) 的形式输出
print(time.localtime())
print(time.strftime('%Y-%m-%d %H-%M-%S', time.localtime()))
测试模块unittest
# 第一步:导入TestCuse类
from unittest import TestCase
# 编写自定义的测试类,要求必须要继承unittest模块中的TestCase类
class TestFileUtil(TestCase):
# 第三步:定义setUp以及tearDown方法,用于初始化以及程序收尾工作
def setUp(self) -> None:
print('当每一个单元测试方法啊执行前会自动调用一次setUp()方法')
pass
# 第四负编写单元测试方法用于实现对程序进行单元测试,命名必须采用test_
def test_func1(self):
print("方法被测试")
return True
def test_func2(self):
print("不加test方法2不会被执行")
def test_func3(self):
print("方法3被执行")
return True
def tearDown(self) -> None:
print('当每一个单元啊测试方法执行后会自动调用一次tearDown()方法')
pass
import unittest
from util import file_utils
#编写一个自定义测试类,必须要继承TestCase
class TestFileUtil(unittest.TestCase):
# 定义setup() 以及tearDown()
def setUp(self) -> None:
pass
def test_get_new_by_compare_lists(self):
a_list = ['1.txt','2.txt']
b_list = ['1.txt','2.txt','3.txt']
c_list = file_utils.panduan(a_list,b_list)
self.assertListEqual(['3.txt'],c_list)
def tearDown(self)-> None:
pass
# 定义测试代码
if __name__ == '__main__':
pass
文件抽取模块
import os
def get_dir_files_list(path = './',recusion = False):
# 参数1:path获取文件列表的目标路径
print(os.getcwd())
path_list = []
# 2,获取指定目录下的所有文件
file_names = os.listdir(path)
for i in file_names:
abs_path = os.path.join(path,i) #想对路径
#把相对路径转换为绝对路径
if os.path.isfile(abs_path):
path_list.append(os.path.abspath(abs_path))
else:
#如果判断recusion为True就执行迭代功能(调用当前函数再次执行1)
if recusion:
dir = get_dir_files_list(abs_path,True)
print(dir)
return path_list
# 参数2:recursion是否再获取文件列表过程中递归
def get_new_by_compare_lists(processed_list,all_list):
# 参数1:processed_list已经处理过的文件列表
new_list = []
for i in all_list:
if i not in processed_list:
new_list.append(i)
# 参数2:all_list所有文件的列表
return new_list
if __name__ == '__main__':
print(get_dir_files_list('./',True))
print(get_new_by_compare_lists([1, 2], [1, 2, 3, 4, 5, 6]))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!