Python综合数据分析_RFM用户分组模型
2024-01-10 06:00:49
文章目录
1.导入数据
import pandas as pd #导入Pandas
df_sales = pd.read_csv('data.csv') #载入数据
df_sales.head() #显示头几行数据

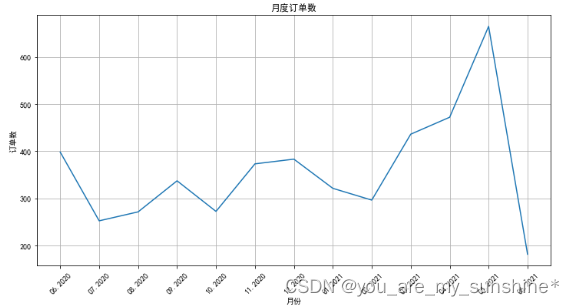
2.月度订单数据可视化
import matplotlib.pyplot as plt #导入Matplotlib的pyplot模块
#构建月度的订单数的DataFrame
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_orders_monthly = df_sales.set_index('消费日期')['订单号'].resample('M').nunique()
#设定绘图的画布
ax = pd.DataFrame(df_orders_monthly.values).plot(grid=True,figsize=(12,6),legend=False)
ax.set_xlabel('月份') # X轴label
ax.set_ylabel('订单数') # Y轴Label
ax.set_title('月度订单数') # 图题
#设定X轴月份显示格式
plt.xticks(
range(len(df_orders_monthly.index)),
[x.strftime('%m.%Y') for x in df_orders_monthly.index],
rotation=45)
plt.show() # 绘图
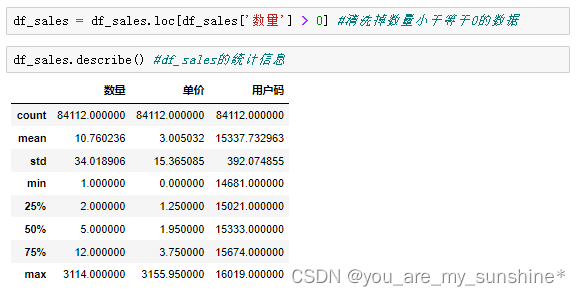
3.数据清洗
df_sales = df_sales.drop_duplicates() #删除重复的数据行
df_sales.isna().sum() # NaN出现的次数

df_sales.describe() #df_sales的统计信息

df_sales = df_sales.loc[df_sales['数量'] > 0] #清洗掉数量小于等于0的数据
df_sales.describe() #df_sales的统计信息
4.特征工程
df_sales['总价'] = df_sales['数量'] * df_sales['单价'] #计算每单的总价
df_sales.head() #显示头几行数据

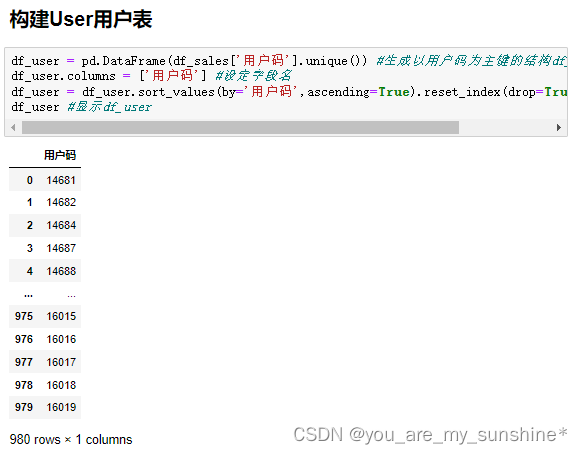
5.构建User用户表
df_user = pd.DataFrame(df_sales['用户码'].unique()) #生成以用户码为主键的结构df_user
df_user.columns = ['用户码'] #设定字段名
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #按用户码排序
df_user #显示df_user
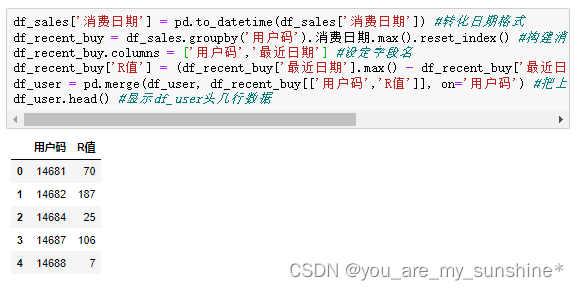
6.求R值
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_recent_buy = df_sales.groupby('用户码').消费日期.max().reset_index() #构建消费日期信息
df_recent_buy.columns = ['用户码','最近日期'] #设定字段名
df_recent_buy['R值'] = (df_recent_buy['最近日期'].max() - df_recent_buy['最近日期']).dt.days #计算最新日期与上次消费日期的天数
df_user = pd.merge(df_user, df_recent_buy[['用户码','R值']], on='用户码') #把上次消费距最新日期的天数(R值)合并至df_user结构
df_user.head() #显示df_user头几行数据
7.求F值
df_frequency = df_sales.groupby('用户码').消费日期.count().reset_index() #计算每个用户消费次数,构建df_frequency对象
df_frequency.columns = ['用户码','F值'] #设定字段名称
df_user = pd.merge(df_user, df_frequency, on='用户码') #把消费频率整合至df_user结构
df_user.head() #显示头几行数据

8.求M值
df_revenue = df_sales.groupby('用户码').总价.sum().reset_index() #根据消费总额,构建df_revenue对象
df_revenue.columns = ['用户码','M值'] #设定字段名称
df_user = pd.merge(df_user, df_revenue, on='用户码') #把消费金额整合至df_user结构
df_user.head() #显示头几行数据

9.显示R、F、M值的分布情况
df_user['R值'].plot(kind='hist', bins=20, title = '新进度分布直方图') #R值直方图
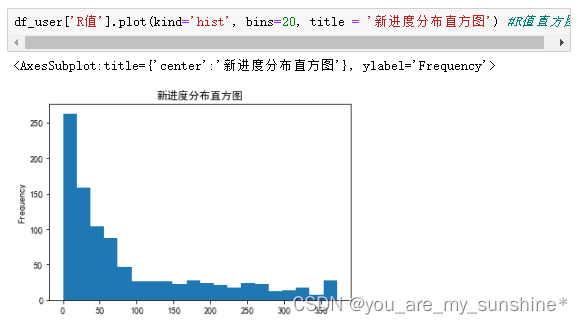
df_user.query('F值 < 800')['F值'].plot(kind='hist', bins=50, title = '消费频率分布直方图') #F值直方图
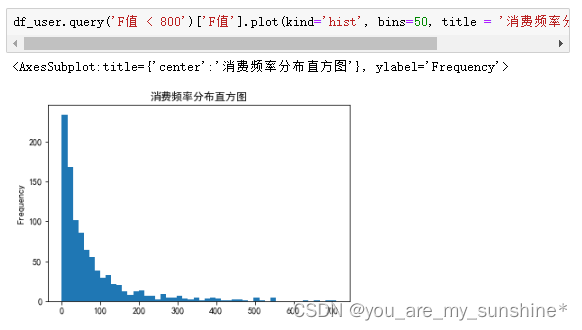
df_user.query('M值 < 20000')['M值'].plot(kind='hist', bins=50, title = '消费金额分布直方图') #M值直方图
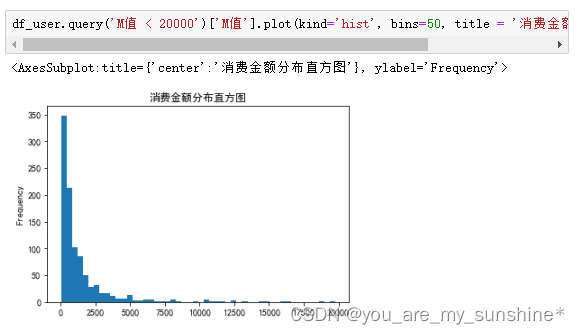
10.显示手肘图辅助确定K值
from sklearn.cluster import KMeans #导入KMeans模块
def show_elbow(df): #定义手肘函数
distance_list = [] #聚质心的距离(损失)
K = range(1,9) #K值范围
for k in K:
kmeans = KMeans(n_clusters=k, max_iter=100) #创建KMeans模型
kmeans = kmeans.fit(df) #拟合模型
distance_list.append(kmeans.inertia_) #创建每个K值的损失
plt.plot(K, distance_list, 'bx-') #绘图
plt.xlabel('k') #X轴
plt.ylabel('距离均方误差') #Y轴
plt.title('k值手肘图') #标题
show_elbow(df_user[['R值']]) #显示R值聚类K值手肘图
show_elbow(df_user[['F值']]) #显示F值聚类K值手肘图

show_elbow(df_user[['M值']]) #显示M值聚类K值手肘图
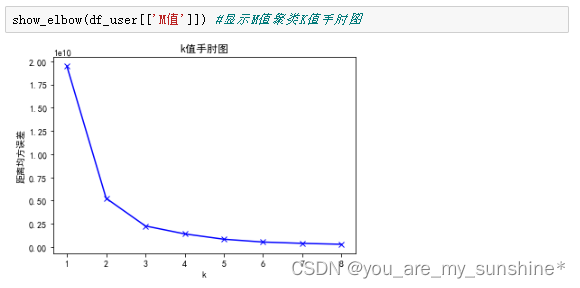
11.创建和训练模型
from sklearn.cluster import KMeans #导入KMeans模块
kmeans_R = KMeans(n_clusters=3) #设定K=3
kmeans_F = KMeans(n_clusters=4) #设定K=4
kmeans_M = KMeans(n_clusters=4) #设定K=4
kmeans_R.fit(df_user[['R值']]) #拟合模型
kmeans_F.fit(df_user[['F值']]) #拟合模型
kmeans_M.fit(df_user[['M值']]) #拟合模型

12.给R值聚类
df_user['R值层级'] = kmeans_R.predict(df_user[['R值']]) #通过聚类模型求出R值的层级
df_user.head() #显示头几行数据
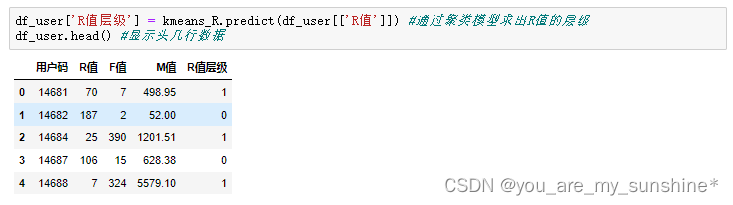
df_user.groupby('R值层级')['R值'].describe() #R值层级分组统计信息

13.给聚类后的层级排序
#定义一个order_cluster函数为聚类排序
def order_cluster(cluster_name, target_name,df,ascending=False):
new_cluster_name = 'new_' + cluster_name #新的聚类名称
df_new = df.groupby(cluster_name)[target_name].mean().reset_index() #按聚类结果分组,创建df_new对象
df_new = df_new.sort_values(by=target_name,ascending=ascending).reset_index(drop=True) #排序
df_new['index'] = df_new.index #创建索引字段
df_new = pd.merge(df,df_new[[cluster_name,'index']], on=cluster_name) #基于聚类名称把df_new还原为df对象,并添加索引字段
df_new = df_new.drop([cluster_name],axis=1) #删除聚类名称
df_new = df_new.rename(columns={"index":cluster_name}) #将索引字段重命名为聚类名称字段
return df_new #返回排序后的df_new对象
df_user = order_cluster('R值层级', 'R值', df_user, False) #调用簇排序函数
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
df_user.head() #显示头几行数据

df_user.groupby('R值层级')['R值'].describe() #R值层级分组统计信息
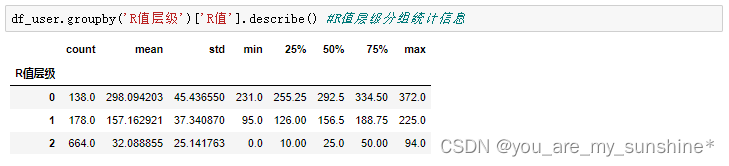
14.继续给F、M值聚类,并排序
df_user['F值层级'] = kmeans_F.predict(df_user[['F值']]) #通过聚类模型求出F值的层级
df_user = order_cluster('F值层级', 'F值',df_user,True) #调用簇排序函数
df_user.groupby('F值层级')['F值'].describe() #F值层级分组统计信息
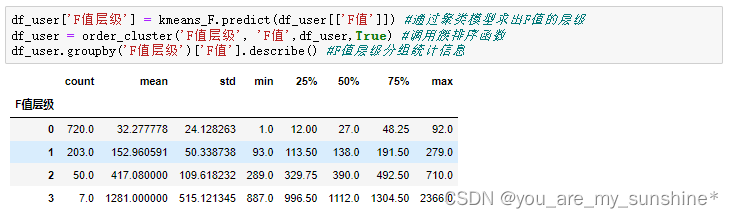
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
df_user.head()
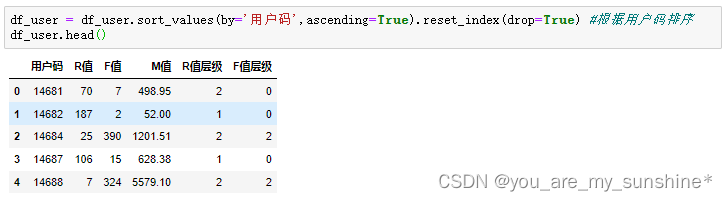
df_user['M值层级'] = kmeans_M.predict(df_user[['M值']]) #通过聚类模型求出M值的层级
df_user = order_cluster('M值层级', 'M值',df_user,True) #调用簇排序函数
df_user.groupby('M值层级')['M值'].describe() #M值层级分组统计信息
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #根据用户码排序
df_user.head() #显示头几行数据

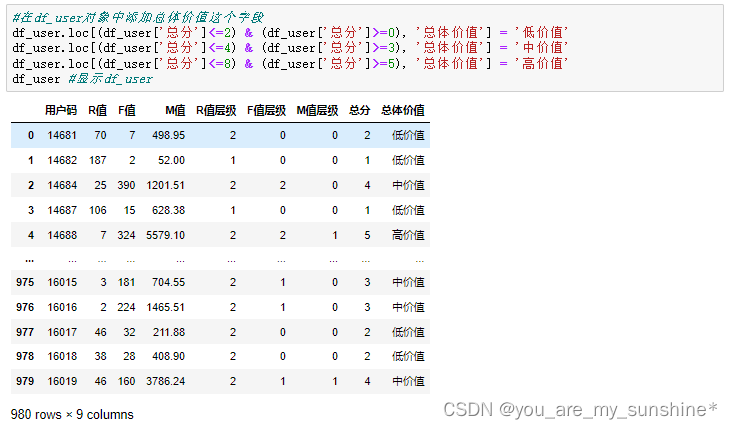
15.为用户整体分组画像
df_user['总分'] = df_user['R值层级'] + df_user['F值层级'] + df_user['M值层级'] #求出每个用户RFM总分
#在df_user对象中添加总体价值这个字段
df_user.loc[(df_user['总分']<=2) & (df_user['总分']>=0), '总体价值'] = '低价值'
df_user.loc[(df_user['总分']<=4) & (df_user['总分']>=3), '总体价值'] = '中价值'
df_user.loc[(df_user['总分']<=8) & (df_user['总分']>=5), '总体价值'] = '高价值'
df_user #显示df_user
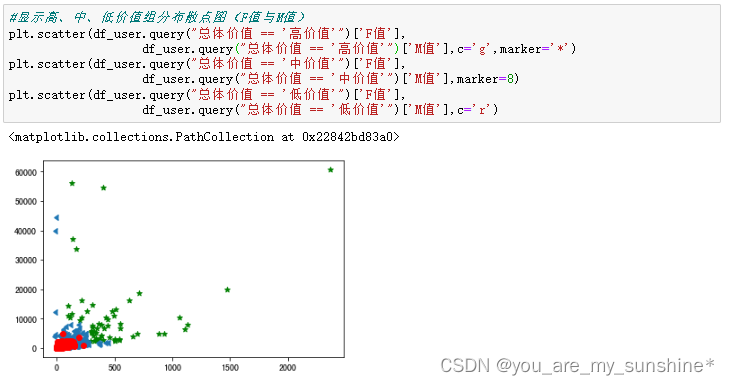
#显示高、中、低价值组分布散点图(F值与M值)
plt.scatter(df_user.query("总体价值 == '高价值'")['F值'],
df_user.query("总体价值 == '高价值'")['M值'],c='g',marker='*')
plt.scatter(df_user.query("总体价值 == '中价值'")['F值'],
df_user.query("总体价值 == '中价值'")['M值'],marker=8)
plt.scatter(df_user.query("总体价值 == '低价值'")['F值'],
df_user.query("总体价值 == '低价值'")['M值'],c='r')
参考资料:极客时间
文章来源:https://blog.csdn.net/weixin_42504788/article/details/135492159
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!