Word2Vec详解: CBOW & Skip-gram和负采样
Word2Vec: CBOW & Skip-gram
如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 CBOW 模型。
而如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做 Skip-gram 模型。
CBOW 模型
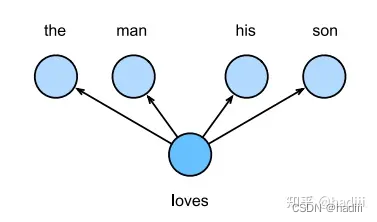
连续词袋模型(Continuous Bag of Words, CBOW)是一种常用的词嵌入模型,它与跳元模型有一些相似之处,但也有关键区别。连续词袋模型的主要假设是,中心词是基于其在文本序列中的周围上下文词生成的。例如,在文本序列 “the”, “man”, “loves”, “his”, “son” 中,如果我们选择 “loves” 作为中心词,并将上下文窗口设置为2,连续词袋模型会考虑基于上下文词 “the”, “man”, “his”, “son” 生成中心词 “loves” 的条件概率,即:
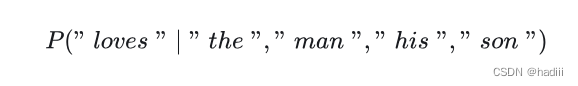
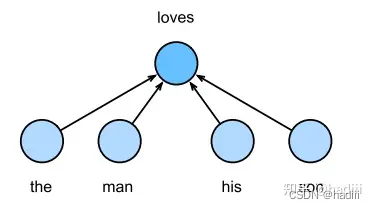
Skip-gram模型
跳元模型(Skip-gram model)是一种常用的词嵌入模型,它的基本假设是一个词可以用来生成其周围的单词。以文本序列 “the”, “man”, “loves”, “his”, “son” 为例,如果我们选择 “loves” 作为中心词,并将上下文窗口设置为2,跳元模型会考虑生成上下文词 “the”, “man”, “his”, “son” 的条件概率,即:
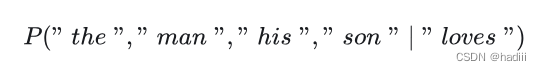
在跳元模型中,我们通常假设上下文词是在给定中心词的情况下独立生成的,这被称为条件独立性。因此,上述条件概率可以被重写为:
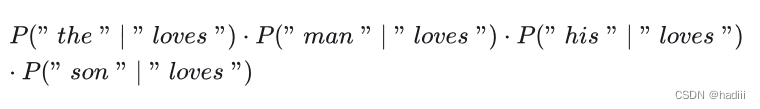
这意味着,我们可以分别计算每个上下文词在给定中心词的情况下的概率,然后将这些概率相乘,得到的结果就是所有上下文词在给定中心词的情况下的联合概率。这是跳元模型的基本工作原理。
跳元模型考虑了在给定中心词的情况下生成周围上下文词的条件概率
两种模型的网络结构
参考:
https://cs224d.stanford.edu/lecture_notes/notes1.pdf
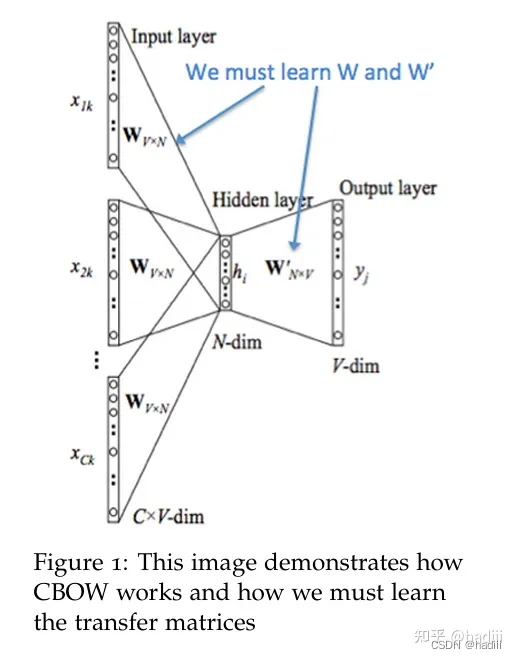
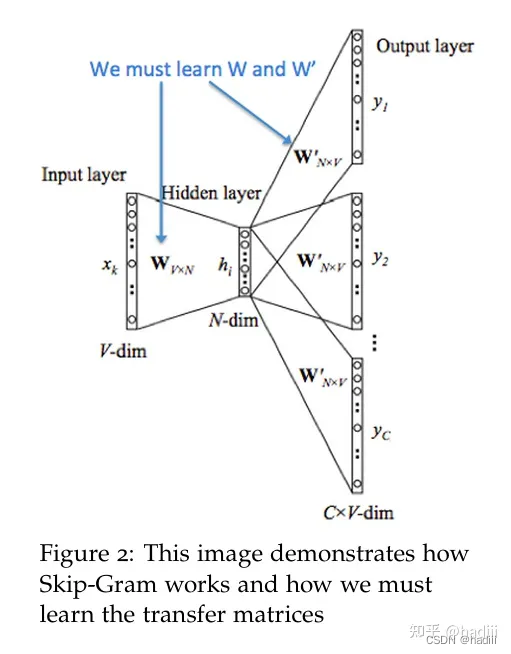
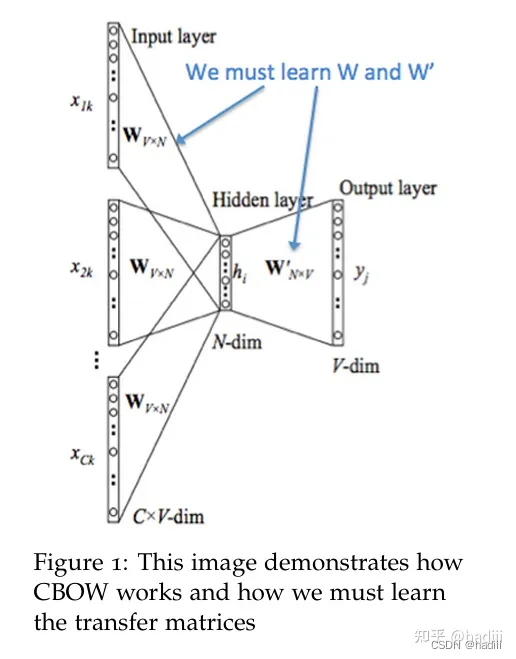
Word2Vec 模型本质上可以就是一个简单的神经网络,它包含一个输入层、一个隐藏层,以及一个输出层。在这个网络中,并没有激活函数应用于隐藏层的节点,而是直接将输入传递到隐藏层,然后再传递到输出层。这种结构可以被视为全连接(fully connected)或密集(dense)层的网络,因为每个输入节点都与隐藏层的每个节点相连,隐藏层的每个节点又都与输出层的每个节点相连。
在 Word2Vec 中,输入层和输出层的节点数等于词汇表的大小(用 one-hot 编码表示),而隐藏层的节点数等于我们想要学习的嵌入向量的维度。尽管结构上类似于全连接网络,但 Word2Vec 的目标并不是执行传统的分类或回归任务,而是学习词的向量表示,这些向量可以捕捉词之间的语义信息。词嵌入(embeddings)是通过两个权重矩阵来学习的:输入矩阵(通常称为W)和输出矩阵(通常称为W’)。这两个矩阵的维度分别是VN和NV,其中V是词汇表的大小,而N是嵌入向量的维度。
在训练过程中,每个单词都会通过它的索引与输入矩阵W相对应,这样每个单词就会有一个与之对应的嵌入向量。这个向量就是输入矩阵W中的一行。当模型完成训练后,这个输入矩阵W就可以作为词嵌入矩阵使用。
负采样
在原始的Word2Vec模型中,我们使用softmax函数来计算目标词的概率。这需要对词汇表中的每个词进行权重更新,这在大词汇表中是非常耗时的。而负采样是一种优化训练Word2Vec模型的方法。它的核心思想是,对于每个训练样本,我们不仅考虑正例(目标词),还随机选取一小部分的负例(即非目标词)进行更新权重,而不是词汇表中的所有单词。如此一来,我们将多分类转变了一系列二分类问题。因而可以只更新部分权重。
具体来讲:
- 在训练神经网络时,我们通常使用梯度下降算法来更新权重。在Word2Vec中,权重实际上是单词的向量表示。在不使用负采样的情况下,softmax函数要求我们更新所有单词的向量,因为它需要计算整个词汇表上的概率分布。然而,当使用负采样时,我们改为优化一个简化的问题,即二分类问题,我们只关心目标词(正
例)和少量随机选取的非目标词(负例)的概率。 - 在负采样中,对于每个训练样本(目标词和上下文词对),我们首先更新目标词的向量表示,使得它更可能与上下文词一起出现。接着,我们从词汇表中随机选择K个负例,并更新这些负例的向量表示,使得它们与上下文词一起出现的概率降低。这意味着,对于每个训练样本,我们只更新1个正例和K个负例的向量,而不是整个词汇表的向量。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!