千亿级工业大数据的最优方案!智光电气的时序数据库应用
小T导读:
此前,智光电气(股票代码:002169)子公司智光研究院在工业项目中使用基于 Apache Hadoop 的 CDH 集群来做时序业务数据的处理,但由于数据量级太大,处理占用了大量资源,导致集群有发生崩溃的风险。在此背景下,智光研究院选择应用? TDengine?进行技术升级,并产出本文分享应用经验。
作者:陈晓琪,智光研究院架构师,行业内多年开发与架构经验。
当前 TDengine 已成功应用于我司多个工业项目中,涵盖数万台各类工业设备的数据存储与查询。作为数据中台,TDengine 为上层应用提供了高效的历史数据查询,精确到秒级和分钟级粒度,帮助我们大幅提升了应用效率,同时减少了硬件和人力资源的消耗。
选型背景
在使用 TDengine 之前,我们使用的是基于 Apache Hadoop 的 CDH 集群。但是由于时序业务数据的量级太大,处理它们占用了太多的资源,这也导致集群的不稳定性增加,有频繁发生崩溃的风险。
因此,我们急需一款时序数据库(Time Series Database,TSDB)进行技术升级。经过充分测试后,团队最终决定把由 HBase 处理的、数据量最大的时序数据业务抽离出来,引入 TDengine 来降低 Hadoop 集群的压力,成为独立出来的数据中台。

我们的设备数据首先通过边缘网关进行采集,然后通过 MQTT 协议上报到工业互联网平台,报上来的数据经过物模型解析后发送到 Kafka 集群,再把原始数据和经过降采样计算的分钟级数据写入到 TDengine 集群当中,以实现高效的数据存储和查询。
经验分享
从一个时序数据库的初学者到使用者,我们最大的心得就是:
数据建模可以说是最重要的一个环节,也是关乎是否能够顺利用好 TDengine 的根基。
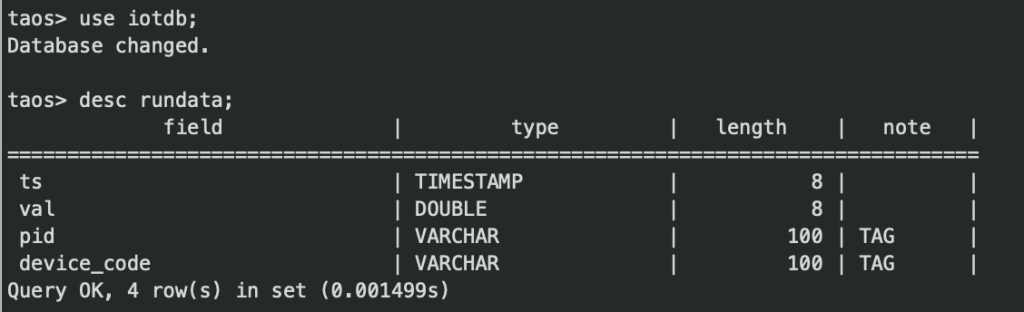
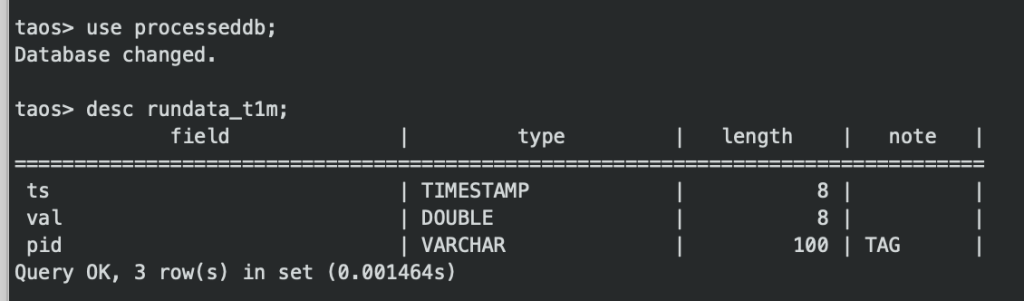
考虑到对降采样查询的大量需求,我们经过实际测试后发现,将这些计算量完全交给 TDengine 来做实时计算是不现实的。在此背景下我们选择在应用层先做好一层降采样计算,再写入数据库。为此我们将数据分为了原始数据和分钟级数据两类,对应到 TDengine 当中:iotdb 是原始数据,processeddb 是分钟级库。这种数据分类和存储方式也更加符合我们的需求。


当全量数据导入之后(几千亿行),我们又发现了新的查询性能问题,当时还以为 TDengine 的性能已经封顶了。之后在 TDengine 官方团队的协助定位下才找到核心问题——分钟级库与原始数据的写入频率差异过大,不能公用一套参数配置。
为了解决这一问题,后面官方根据我们实际的业务场景,分别对不同类型的数据进行建库建表,做了针对性的建模优化。然后我们又耐下心来,再次重新导入全量数据。
改造效果
经过官方协助优化后,数据块变得更加紧密,压缩率和查询写入性能均得到了大幅提升。
最终的成果如下:
写入存储方面,同样是列式存储,以半年的数据作为比较,三副本的 HBase 的总数据量占用是 10TB,TDengine 三副本的磁盘占用只有 2TB,存储成本仅为 HBase 的 20 %。(由于和其他应用共用,内存、CPU 方面不好估算,但成本均大幅降低)
在查询上,我们的业务主要就是针对 rundata_t1m(分钟级数据)、rundata(原始数据)这两张千亿级别的大型超级表的筛选、过滤、降采样。应用的查询性能和 SQL 筛选的时间范围相关较大,整体上的耗时大概在毫秒级至 2 秒内。
具体展示如下:
- 分钟级数据的 5 分钟级数据查询(取 5 分钟内最后的值)
select tbname, _wend - 1 as ts, LAST(val) AS val from rundata_t1m where tbname in ('b5Sk4IV6ld6-LErYYdQ1-ProcUsedPercent') and ts >= 1698768000000 and ts <= 1701100799000 partition by tbname interval(5m, 1a);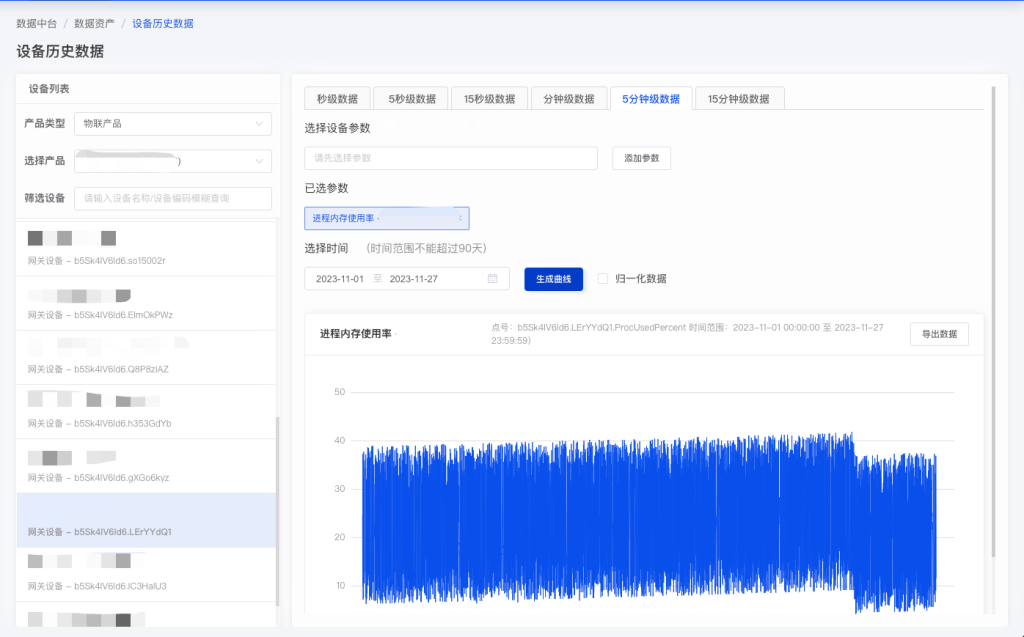
- 分钟级数据的 15 分钟级数据查询(取 15 分钟内最后的值)
select tbname, _wend - 1 as ts, LAST(val) AS val from rundata_t1m where tbname in ('b5Sk4IV6ld6-LErYYdQ1-ProcUsedPercent') and ts >= xxx and ts <= xxx partition by tbname interval(15m, 1a);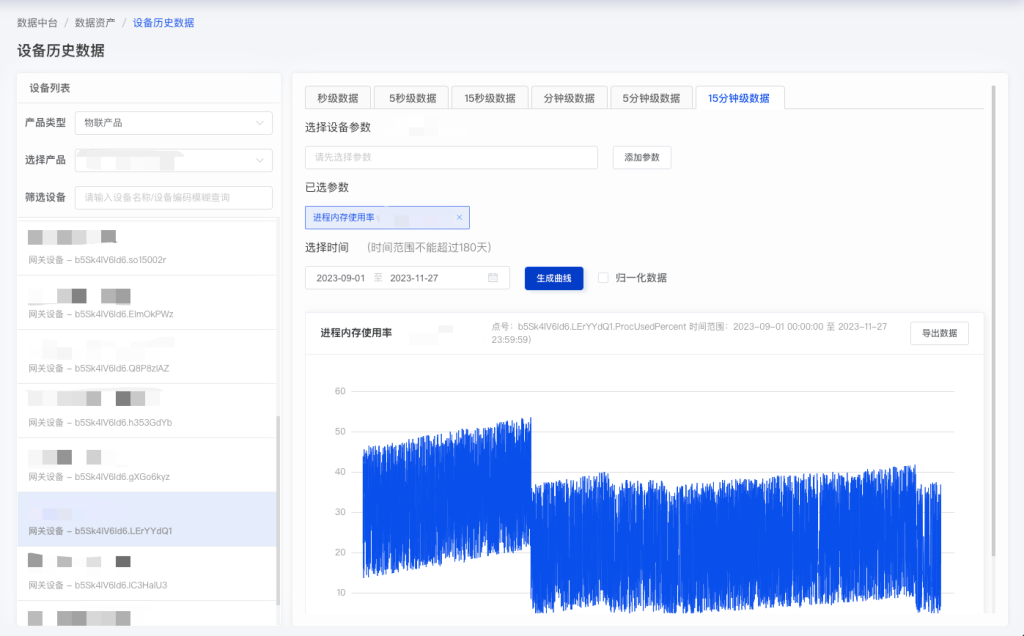
- 原始数据的秒级数据查询
select tbname, _wend - 1 as ts, LAST(val) AS val from rundata where tbname in ('b5Sk4IV6ld6-LErYYdQ1-ProcUsedPercent') and ts >= xxx and ts <= xxx partition by tbname interval(1s, 1a);
写在最后
TDengine 作为一款出色的国产时序数据库,在实际应用中真正地为我们提供了巨大帮助。因此,我们决定整理成文,希望能够吸引更多的企业和开发者加入我们的行列,共同探索 TDengine 的优势和潜力。让我们一起共同推动国产数据库技术的发展!
企业简介:
智光研究院(广州)有限公司【智光电气(股票代码:002169)下属子公司】,是一家在能源动力技术领域具有深厚行业背景和创新研发能力的应用技术研究机构。凭借丰富的行业背景和创新研发能力,智光研究院在综合能源工业互联网平台应用、大型工业设备状态监测和智能运维管理、能源系统数字化管理和能量优化、新能源、储能、电动化等方面取得了多项成果。目前已成功投入使用综合能源服务工业互联网平台和多个垂直领域应用系统。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!