必知必会的XPath详解:XPath从入门到精通
XPath从入门到精通
前言
大家好,我是小K,今天跟大家一起学习有关XPath的知识,初次了解XPath是在学习爬虫的过程中了解到的,想要精确的获取的数据,就可以选择XPath作为选择数据的一种工具,XPath在使用过程中也是相当快捷高效的。接下来就带大家熟悉XPath,同时带来一些XPath小技巧。
一、XPath是什么
XPath 定位 HTML 文档中的元素的工具
XPath 是一种表达语言,旨在支持XML文档的查询或转换。
XPath由万维网联盟(W3C) 于 1999 年定义。
XPath支持 XML 的应用程序(例如 Web 浏览器)和许多编程语言都支持 XPath。
XPath 语言基于XML 文档的树表示,并提供在树中导航、按各种标准选择节点的能力。
二、XPath的用途
XPath 用于在 XML 文档中通过元素和属性进行导航。当然作为一名爬虫程序员,更多的还是会将XPath应用于Python爬虫中。
三、XPath的优点
- XPath 可以选择 XML 文档中的任何节点,包括元素、属性、文本等。
- XPath 支持复杂的逻辑关系,例如选择任意层次的子节点,并且可以使用通配符和谓词进行筛选。
- XPath 可以在不同的环境中使用,例如在 XSLT 中使用 XPath 进行数据转换。
- 简单易学,容易上手,操作难度低。
废话不多说,进入干货阶段
四、XPath的基本语法
4.1 节点选取
使用路径表达式在XML文档中选取节点。节点是通过沿着路径选取的。
| 表达式 | 描述 | 实例 | 解析 |
|---|---|---|---|
nodename | 选取此节点的所有子节点。 | xpath('//div') | 选取了div节点的所有子节点 |
/ | 从根节点选取。 | xpath('/div') | 选取根节点下div标签 |
// | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 | xpath(‘'//div') | 选取所有div标签元素 |
. | 选取当前节点。 | xpath('./div') | 选取当前节点下的div标签 |
.. | 选取当前节点的父节点 | xpath('../div') | 选中当前节点的父节点下的div标签 |
@ | 选取属性。 | xpath('//@class') | 选取所有的class属性 |
4.2 谓语
谓语用来查找某个特定的节点或者包含某个指定值的节点,写在方括号[]中。
| 表达式 | 描述 | 实例 | 解析 |
|---|---|---|---|
[index] | 选取第index个元素 | /div/dl[1] | 选取div标签下第一个dl标签 |
[last()] | 选取div标签下最后一个元素 | /div/dl[last()] | 选取div标签下最后一个dl标签 |
[position()-4] | 选取最前面的3个元素 | /div/dl[position()-4] | 选取div标签下前3个dl标签 |
[@class] | 选取所有拥有class元素的标签 | /div/dl[@class = "a"] | 选取div标签下所有 |
4.3 XPath通配符
| 表达式 | 描述 | 实例 | 解析 |
|---|---|---|---|
* | 匹配任何元素节点 | /div/* | 选取div标签下所有子标签 |
@* | 匹配任何属性节点 | //title[@*] | 选取所有带有属性的title元素。 |
node() | 匹配任何类型的节点 | //div/node() | 选取div标签下任何标签,与*功能类似 |
4.4 选取多个元素
可以通过|来选择多个元素标签,如:
//div/h1 | //div/h2 选取 div标签下的所有 h1 和 h2 标签。
4.5 轴定义
| 轴名称 | 结果 |
|---|---|
ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
attribute | 选取当前节点的所有属性。 |
child | 选取当前节点的所有子元素。 |
descendant | 选取当前节点的所有后代元素(子、孙等)。 |
descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
following | 选取文档中当前节点的结束标签之后的所有节点。 |
namespace | 选取当前节点的所有命名空间节点。 |
parent | 选取当前节点的父节点。 |
preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
preceding-sibling | 选取当前节点之前的所有同级节点。 |
self | 选选取当前节点。 |
位置路径表达式
位置路径可以是绝对的,也可以是相对的。
绝对路径起始于正斜杠( / ),而相对路径不需要。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径:
/step1/step2/…
相对位置路径:
step1/step2/…
每个步均根据当前节点集之中的节点来进行计算。
| 实例 | 结果 |
|---|---|
child::h1 | 选取所有属于当前节点的子元素的 h1 节点。 |
attribute::class | 选取当前节点的 class属性。 |
child::* | 选取当前节点的所有子元素。 |
attribute::* | 选取当前节点的所有属性。 |
child::text() | 选取当前节点的所有文本子节点。 |
child::node() | 选取当前节点的所有子节点。 |
descendant::div | 选取当前节点的所有 div后代。 |
ancestor::div | 选择当前节点的所有 book 先代。 |
ancestor-or-self::div | 选取当前节点的所有 div先辈以及当前节点。 |
child::*/child::div | 选择当前节点的所有 div先代。 |
4.6 XPath 运算符
XPath 表达式可返回节点集、字符串、逻辑值以及数字。
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | 计算两个节点集 | //div | //h1 | 返回所有拥有 div 和 h1元素的节点集 |
+ | 加法 | 6 + 4 | 10 |
– | 减法 | 6 – 4 | 2 |
* | 乘法 | 6 * 4 | 24 |
div | 除法 | 8 div 4 | 2 |
= | 等于 | value=5 | 判断value是否等于5,等于返回True,否则False |
!= | 不等于 | value!=5 | 判断value是否等于5,不等于返回True,否则False |
< | 小于 | value<5 | 判断value是否小于5,小于返回True,否则返回False |
<= | 小于 | value<=5 | 判断value是否小于等于5,小于等于返回True,否则返回False |
> | 小于 | value>5 | 判断value是否大于5,大于返回True,否则返回False |
>= | 小于 | value>=5 | 判断value是否大于等于5,大于等于返回True,否则返回False |
or | 或 | value=5 or value=6 | 或关系,满足一个就返回True |
and | 或 | value=5 and value=6 | 并关系,满足一个就返回True |
五、案例分析
5.1 爬取猪八戒上pyhon兼职信息数据
- 获取网页信息
import requests
from lxml import etree
url = "https://taiyuan.zbj.com/sem_search/f/?kw=python"
res = requests.get(url)
- HTML对源代码进行解析
html = etree.HTML(res.text)
- 获取页面上每条项目的数据
div_l = html .xpath('/html/body/div[6]/div/div/div[3]/div[5]/div[1]/div/div')
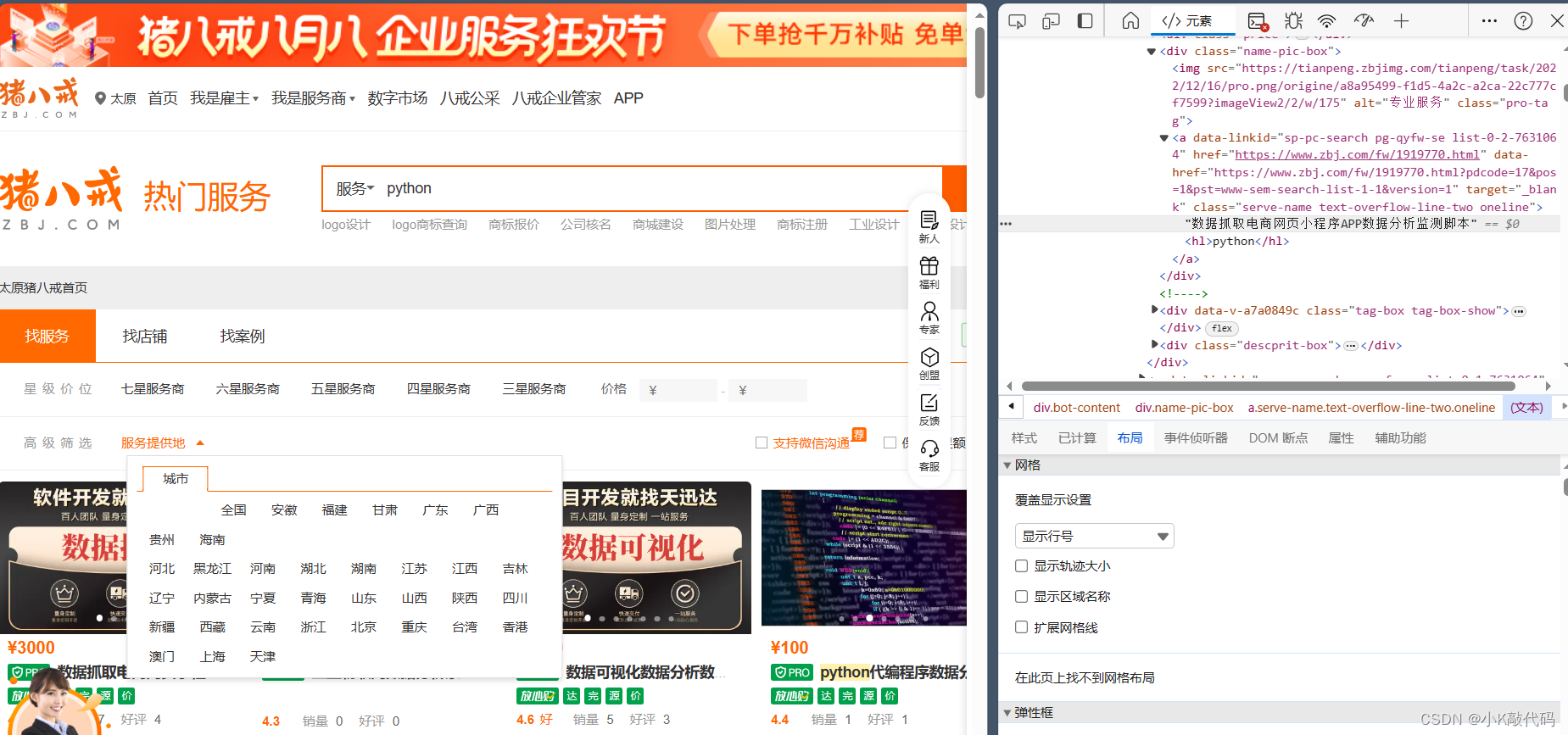
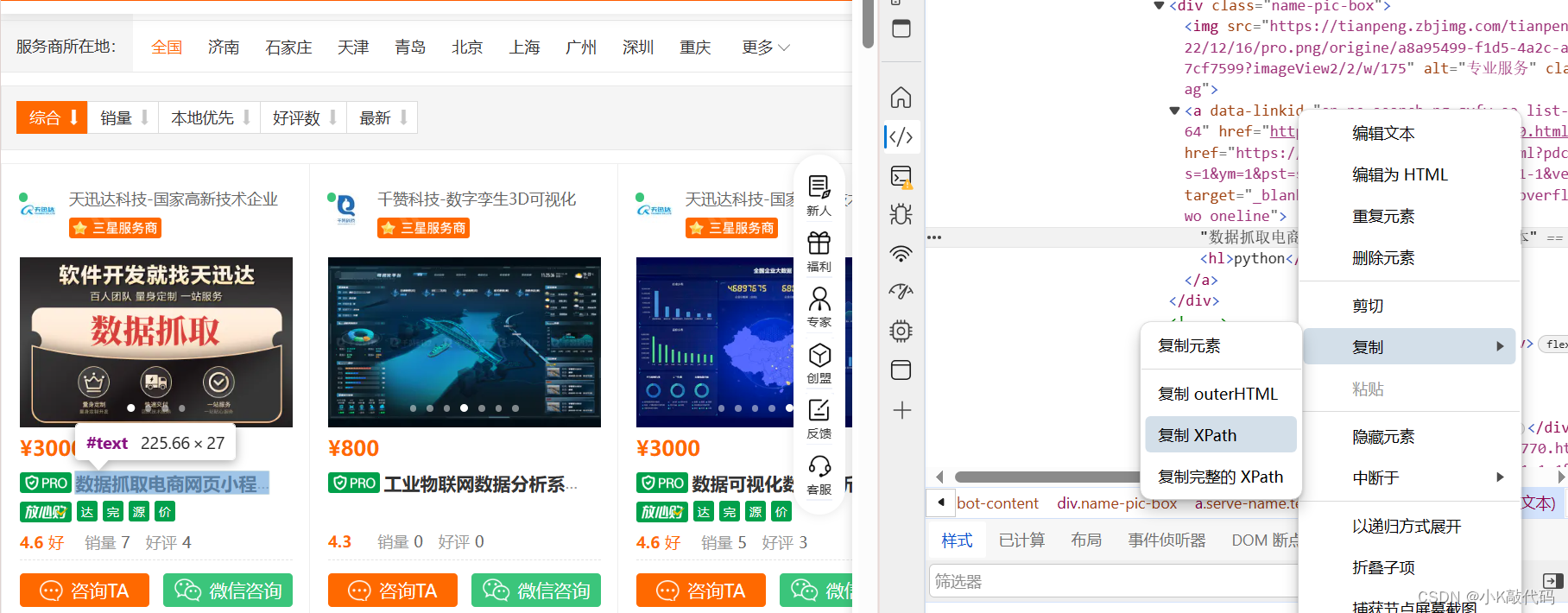
这里有一个小技巧,可以快速找到我们想要数据的xpath路径。
F12查看源代码,用选择器选中我们想要的数据,右键 复制->复制路径->复制XPath路径(这里以Edge浏览器为例,谷歌浏览器可能为英文)。
- 遍历每个项目
r div in div_l:#每一个项目信息
#获取项目名称
result1 = div.xpath('.//div[@class="name-pic-box"]/a/text()')
print(result1 )
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!