2DPASS激光雷达点云语义分割简介
导读
香港中文大学深圳深度比特实验室提出了一种基于二维图像先验辅助的激光雷达点云语义分割 (2DPASS)。不同于先前的多模态方法(训练和推理阶段均需要成对的图像和点云数据作为输入),该方法仅在训练阶段利用额外的图像数据,从相机数据中获取更丰富的语义和结构信息,并将其提炼蒸馏至三维语义分割网络中。在测试阶段,该方法可实现实时感知,无需图像数据输入,即可实现又快又准的三维语义分割,并在多个大型语义分割比赛(SemanticKITTI单帧、多帧和Nuscenes)都达到了最先进的水平。
 论文地址:
论文地址:
https://arxiv.org/pdf/2207.04397.pdf
GitHub:
https://github.com/yanx27/2DPASS
一、研究动机
随着越来越多的方法同时使用相机和激光雷达传感器捕获互补信息,通过多模态数据融合的语义分割已经实现了巨大的进步。这些基于融合的方法首先将点云投影到图像平面上来建立三维点和二维像素之间的映射,基于该映射,这些模型将相应的图像信息融合到点云,并获得最终的语义分割结果。然而,上述方法却有以下不可避免的局限性:
1.在一些情况下,相机和激光雷达之间的视野不同,而无法建立点到像素的映射关系。如SemanticKITTI数据集中相机的视野仅占据激光雷达视野的一小部分(如下图),这极大地限制了基于融合的方法的应用。
2.基于融合的方法往往需要消耗更多的计算资源,因为它们在训练和推理阶段需要同时处理图像和点云数据,这为自动驾驶应用的实时性带来了巨大的挑战。

二、方法
为了解决上述两个问题,该团队提出了一种基于二维图像先验的训练方案,2D Priors Assisted Semantic Segmentation (2DPASS),以促进三维点云上的表征学习。2DPASS具有以下的优势:
通用性:2DPASS不限制所使用的三维语义分割模型的类型,可应用在多种已有的模型上提升其效果。
高效性:额外的二维图像仅在训练阶段使用,在部署模型进行推理时,2DPASS仅使用三维点云作为输入。
有效性:即使激光雷达与图片仅有一小部分的重叠区域,2DPASS依旧能有效地提升模型,并在两大基准数据集上达到最先进的水平。
如下图所示,2DPASS首先从原始相机图像中随机抽取一个区域作为二维输入,将裁剪后的图像和点云分别经过独立的2D和3D编码器,并提取两个主干网络中的多尺度特征。然后,其通过多尺度-多模态到单模态知识蒸馏 (Multi-Scale Fusion-to-Single Knowledge Distillation,MSFSKD) 增强三维网络。该方法即充分利用纹理和颜色感知的二维先验,同时保留原始的三维的特定知识。最后,2DPASS利用每个尺度的二维和三维特征生成语义分割预测,由三维点云标签进行监督。在实时推理过程中,2DPASS丢弃与图像相关的分支,与基于融合的多模态方法相比,有效地避免了额外的计算负担。

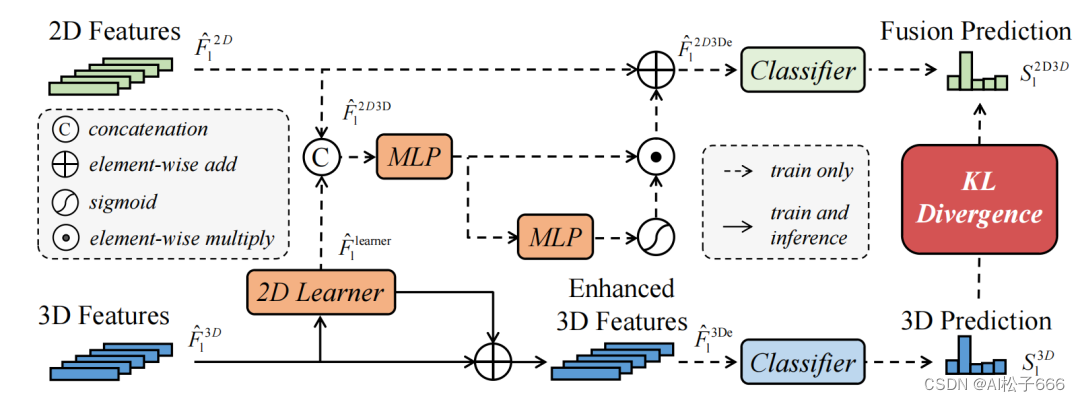
其中,MSFSKD是2DPASS的关键,其目的是利用多尺度的二维先验信息,通过融合再蒸馏的方式,提高每个尺度的三维特征表示。具体如下图所示:
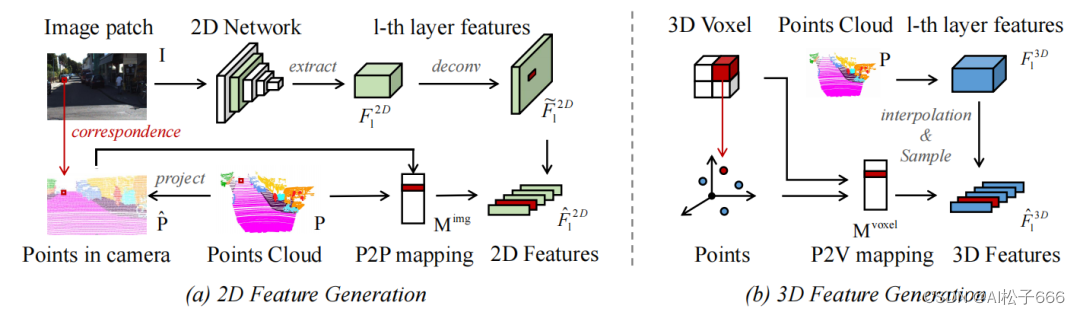
首先,对于每个2D和3D主干网络的每个尺度,2DPASS都会提取相应的特征,并将其映射成原始点云的尺度。有了相互对齐的2D和3D特征,其采用先融合后蒸馏的方式将2D网络的先验信息在训练中传输给3D网络。
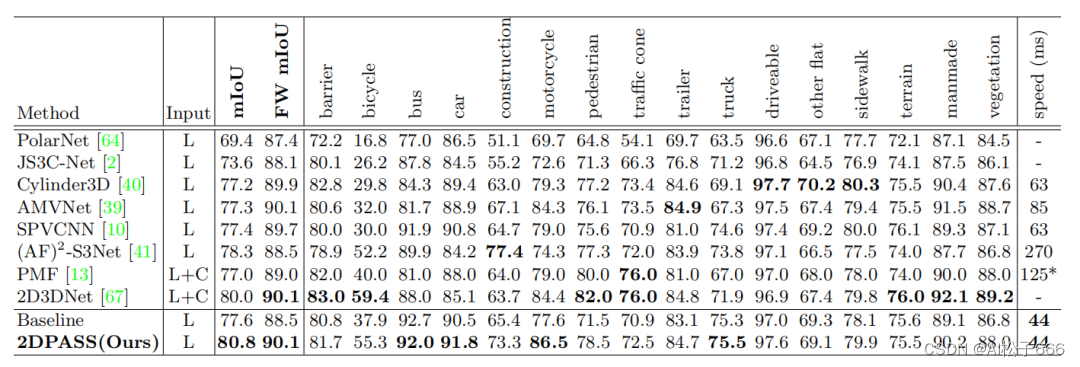
三、实验效果
在论文提交时,2DPASS在SemanticKITTI数据集的单帧和多帧语义分割比赛中均登顶榜首,并在Nuscenes数据集上也达到了最先进的精度。
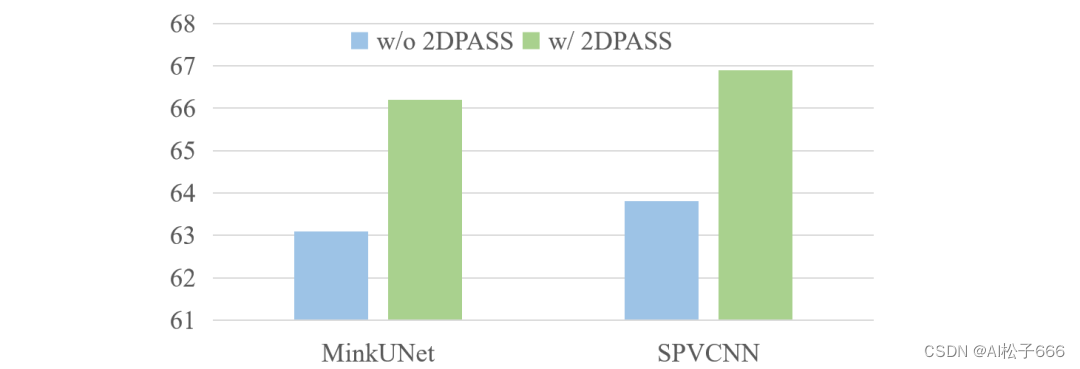
同时,2DPASS对于其他的点云语义分割网络(如MinkowskiNet和SPVCNN)也能产生显著的提升。
四、可视化结果
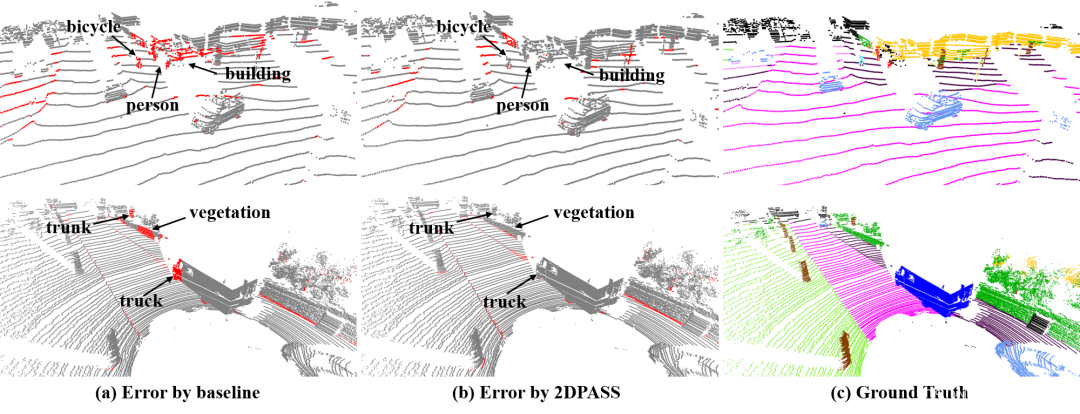

五、结语
本文介绍了一个基于二维先验辅助的激光雷达点云语义分割算法2DPASS,其在模型训练阶段从多模态数据中获取更丰富的语义和结构信息将其提炼到点云分割网络中。该方法具有良好的通用性,且在推理时仅基于点云数据输入即可实现又快又准的三维语义分割。该方法在SemanticKITTI数据集单帧和多帧语义分割,以及Nuscenes数据集都达到了最先进的水平。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!