扩散模型(Diffusion Model)
扩散模型(Diffusion Model)
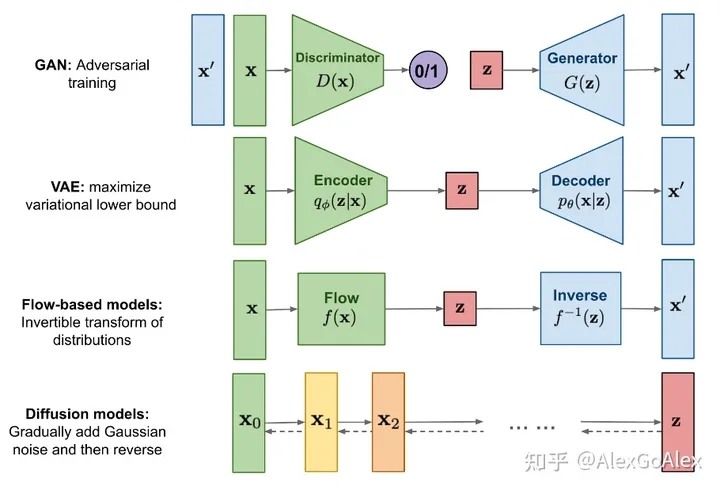
当前主要有四大生成模型:生成对抗模型、变分自动编码器、流模型以及扩散模型。
扩散模型(diffusion models)是当前深度生成模型中新SOTA。扩散模型在图片生成任务中超越了原SOTA:GAN,并且在诸多应用领域都有出色的表现,如计算机视觉,NLP、波形信号处理、多模态建模、分子图建模、时间序列建模、对抗性净化等。此外,扩散模型与其他研究领域有着密切的联系,如稳健学习、表示学习、强化学习。
下面学习李宏毅扩散模型课程的学习笔记。
简介
首先,先简单介绍一下Diffusion model,该模型有很多不同的变形,但以下的内容主要来自最知名的:
《Denosiing Diffusion Probabilistic Models(DDPM)》
基本原理
Diffusion Model是如何运作的,怎么生成一张图片的?
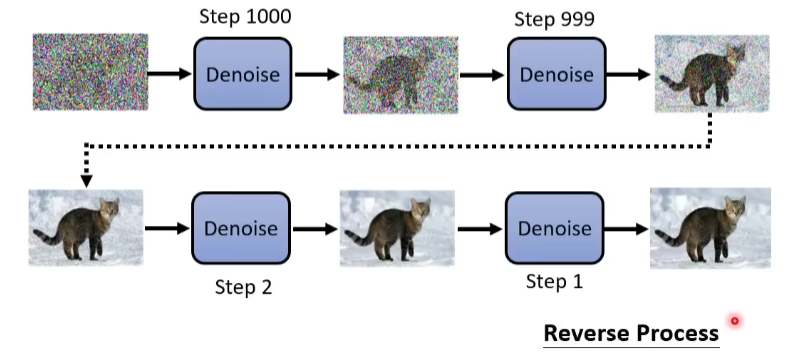
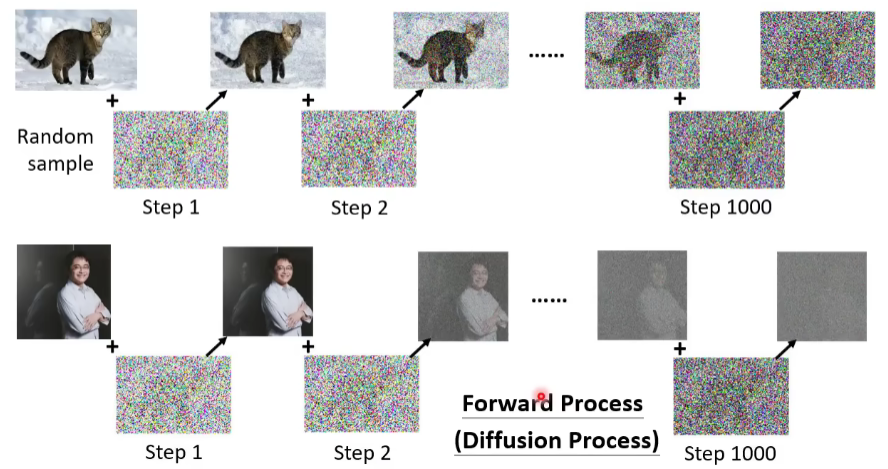
首先,你要从高斯分布里采样出一张和目标图片大小的“图片”,比如256*256,这个“图片”全是杂讯,然后输入Denoise网络,输出的图片的杂讯就稍微滤掉一点。然后再输入Denoise…重复该过程,直到出现目标图片。
Denoise的次数是是先定好的。通常会给Denoise一个次数编号,如下图中,编号由大(模糊杂讯)到小(清晰图片)。
这些从杂讯到图片的步骤就叫作 Reverse Process。
在概念上,有点类似米开朗斯洛说的:“雕像其实已经在大理石里面,我们不过是把不要的部分给去掉。”DIffusion Model就是假设图片信息本在杂讯里,我们不过是把不需要的杂讯给去掉。
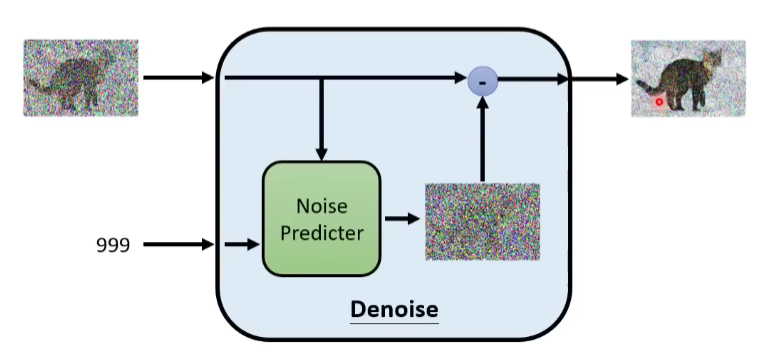
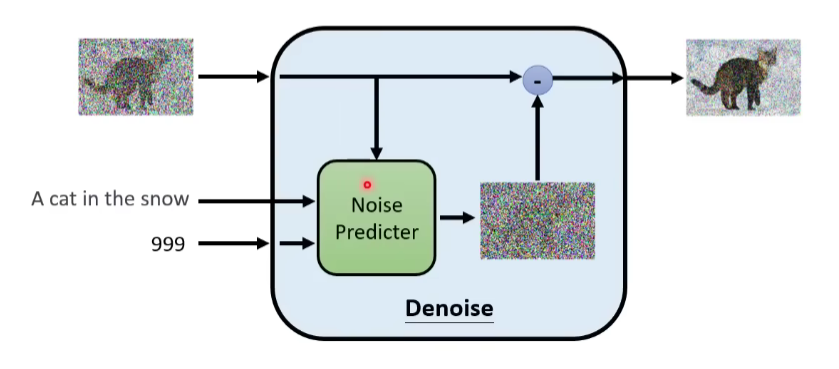
Denoise Model是同一个模型,反复在用。但是,因为每个Denoise Model输入的图片相比,状况差异非常大,所以如果是同一个模型,有可能表现不是很好,那怎么办呢?我们给Denoise Model不仅输入图片,同时输入一个数字(代表现在图片杂讯严重程度,),如下图,直接输入第几个Step的信息。

Denoise Model内部实际做了什么事情呢?
首先,里面有个Noise predictor噪声预测器,输入是杂讯图片x和y=一个数字(噪声程度),输出一张图片y,输出y减去x后的图片。
那可能有人问了,为什么要这么麻烦呢,为什么不是直接输入一张杂讯图片,输出Denoise的结果,直接训个端到端模型不行吗?
其实也可以,有人也确实这么做过,不过多数论文还是选择训一个噪声预测器。你想想,生成一张杂讯和生成一张猫的图片的难度是不一样的,可能learn一个噪声预测器是比较简单的,而learn一个端到端的模型是比较困难的。
那如何训练训一个噪声预测器Noise Predictor呢?
Denoise Model的任务我们已经知道了,那里面的Noise predictor要怎么训呢。
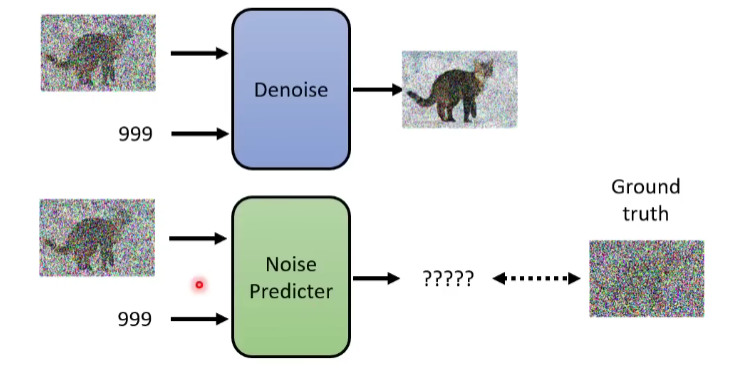
我们训练一个网络的时候就得有成对的数据才能训练呀,你要训Noise predictor输出一张杂讯图,就得有个ground truth呀,是不?
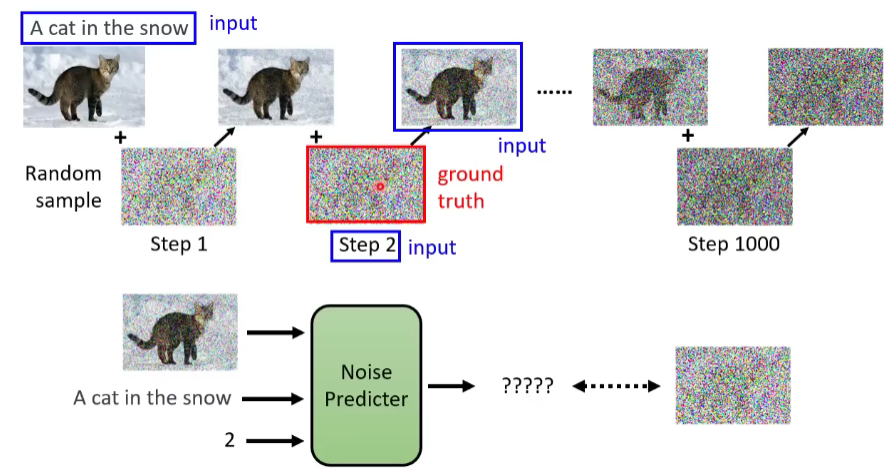
其实Noise predictor的训练资料是我们人为创造出来的。自给自足了。就是从database先拿出一张图片出来,人为给它加上噪声,产生有点噪声的图片,再加一些噪声上去,产生包含更多噪声的图片…以此类推, 最后整张图片全被噪声模糊了。然后把database里所有图片都这么加一遍噪。这个加噪声的过程,就叫做Forward Process,或者Diffusion process,前向处理。
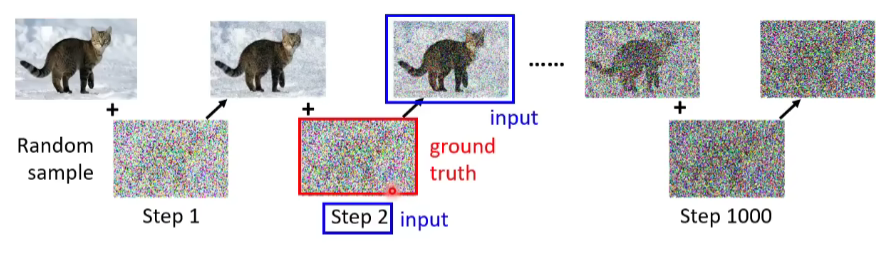
做完前向处理的过程,我们就有Noise predictor的训练资料了。
对Noise predictor来说,输入就是如下蓝色框框的两部分,那么输出就是预测的噪声,即红色框的部分。
Text-to-Image任务
但是我们不止需要图片,在Text-to-Image任务中,需要把文字引入进来。

回忆一下之前做这个任务时,我们也需要大量成对的资料(文字-图片),ImageNet用100万张图训的,LAION用58.5亿张图片训的,难怪现在的模型能产生非常好的效果。
你可以去搜一下LAION里的图片,里面真的是啥都有,比如猫的图片,不仅有中文对应,还有日文和英文。
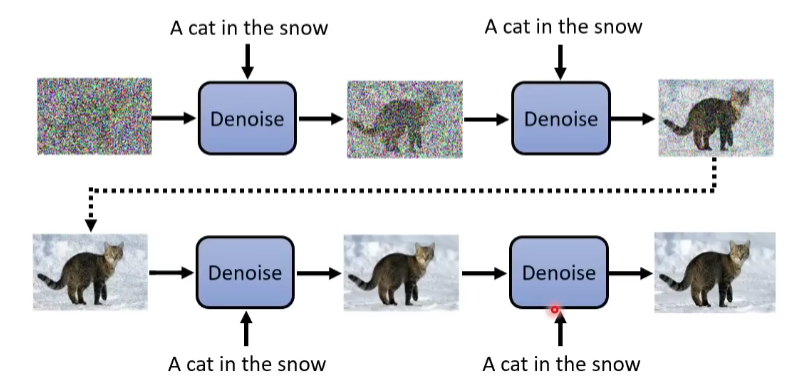
那这个任务中的Denoise是怎么做的?
非常简单,把文字加入进去就行。
那Denoise Model中的Noise predictor要怎么放呢?
和上面一样,对Noise predictor来说,输入就是如下蓝色框框的部分,之前是两部分,现在又多了一部分文字,即3个input,输出就是预测的噪声,即红色框的部分。
Denoising Diffusion Probabilitistic Models:
原始论文中的算法:

Stable Diffusion
今天比较好的图像生成模型,即使不是stable diffusion模型,它的套路也和stable diffusion差不多。今天就是介绍它后面的套路是什么。
简介
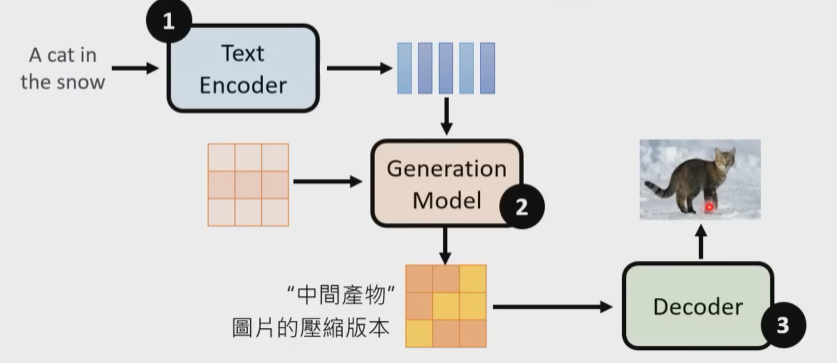
一般里面都有三个组件,如下图。
1.Text encoder:把一段文字编码成一组向量
2.Generation Model:输入杂讯和文字的向量,输出一个“中间产物”(就是图片被压缩后的样子,可能人能看清,可能看不清)
3.Decoder:输入“中间产物”,输出图片
通常,这三个组件要分开训练,然后再组合起来。
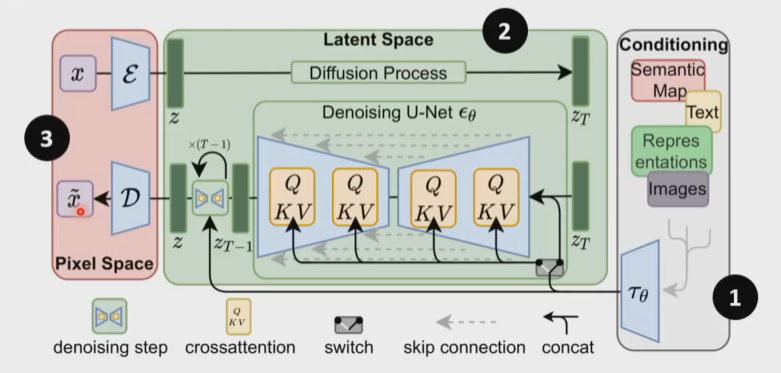
stable diffusion:
论文地址:http://arxiv.org/abs/2112.10752
该模型也是三块,与刚才说的三个组件对应起来。如1号编码器,不过它的输入不仅有文字。2号生成器。3号解码器。
DALL-E系列:
论文地址:
http://arxiv.org/abs/2204.06125
http://arxiv.org/abs/2102.12092
该模型也是三块,与刚才说的三个组件对应起来。三招鲜。
1号编码器,编码文字;2号生成模型试了两个,autoregressive自回归,因为输入已经是先做了一些处理以后的,而且也不用一下子生成完整图片(不然运算量太大),只是生成图片的压缩版本,所以也许用自回归的方法还可以。其次也可以用扩散Diffusion model。最后3号decoder。
Imagen
谷歌公司提出的。http://imagen.research.google/
论文地址:
http://arxiv.org/abs/2205.11487
还是三招鲜套路。1号文本编码器;但2号输出的就已经是人类能看懂的图片了,不过是很小的图片,6464的。然后通过3号解码器输出10241024的大图。
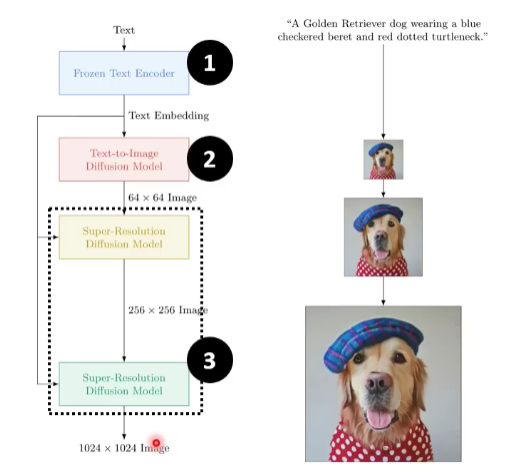
下面我们学习这三招鲜里面的细节。
Text Encoder
可以用GPT,bert等作为文字text encoder。
这个文字的encoder对最后的结果影响很大。如下图所示。
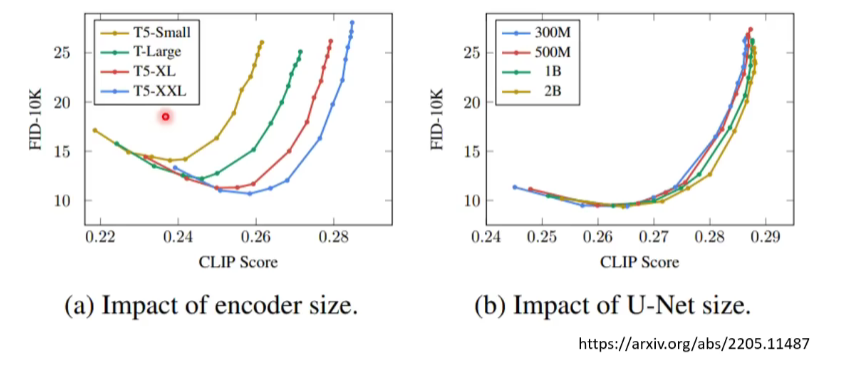
用了FID和CLIP两个指标来评价encoder的好坏。FID的值越小代表生成的图片越好;CLIP分越大越好。所以图的值越往右下角越好。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!