java高效读大文件(csv,text)的处理策略
2023-12-31 23:24:22
当我们在处理一个2G或者更大的文件数据时,往往是很耗系统性能的,处理不当可能造成系统崩溃。接下来介绍四种读取大文件的方式,以及每种方式的资源的调用情况。
方法1:Guava读取
由于我是用的windows系统,在 第一次测试时用了2G的文件,最后在读取文件时,读取了好久,最后报错堆内存溢出(由此可知,这种方式是基于内存进行一次性读取整个文件,文件越大,占用的资源越多)。然后 选用了一个624MB的csv文件进行测试。
代码示例如下:
@org.junit.Test
public void testGuavaReadFile() throws IOException {
//本次测试的这个outPut.csv文件的大小是624MB
String filePath = "D:\\outPut.csv";
File file = new File(filePath);
Long startTime = System.currentTimeMillis();
//进行文件的读取,返回结果:每行数据都是一个string字符串
List<String> lines = Files.readLines(file, Charsets.UTF_8);
for (String line : lines) {
// 在这里添加对每行数据的处理逻辑
System.out.println("Processing line: " + line);
}
Long endTime = System.currentTimeMillis();
long consume = (endTime - startTime)/1000;
System.out.println("************总共耗时:"+consume+"秒*****************");
}监控结果如下: ?
?
从上图可以看到:
时间消耗:20秒堆内存:最高2.5GCPU消耗:最高50%
?
方式2:Apache Commons IO普通方式?
代码如下:
@org.junit.Test
public void TestCommonsIoReadFile() throws IOException {
//本次测试的这个outPut.csv文件的大小是624MB
String filePath = "D:\\outPut.csv";
File file = new File(filePath);
Long startTime = System.currentTimeMillis();
//Apache Commons IO普通方式读取文件
List<String> lines = FileUtils.readLines(file, "UTF-8");
for (String line : lines) {
// 在这里添加对每行数据的处理逻辑
System.out.println("Processing line: " + line);
}
Long endTime = System.currentTimeMillis();
long consume = (endTime - startTime)/1000;
System.out.println("************CommonsIo方式总共耗时:"+consume+"秒*****************");
}运行结果:

从上图可以看出:?
?时间消耗:17秒CPU消耗:最高50%,平稳运行25%左右
方式3:java文件流
代码如下:
@org.junit.Test
public void TestJavaIoReadFile() throws IOException {
//本次测试的这个outPut.csv文件的大小是624MB
String filePath = "D:\\outPut.csv";
Long startTime = System.currentTimeMillis();
FileInputStream inputStream = null;
Scanner scanner = null;
try {
inputStream = new FileInputStream(filePath);
scanner = new Scanner(inputStream, "UTF-8");
while (scanner.hasNextLine()) {
//逐行读取文件内容
String line = scanner.nextLine();
System.out.println(line);
}
if (scanner.ioException() != null) {
throw scanner.ioException();
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (scanner != null) {
scanner.close();
}
}
Long endTime = System.currentTimeMillis();
long consume = (endTime - startTime)/1000;
System.out.println("************CommonsIo方式总共耗时:"+consume+"秒*****************");
}运行结果:
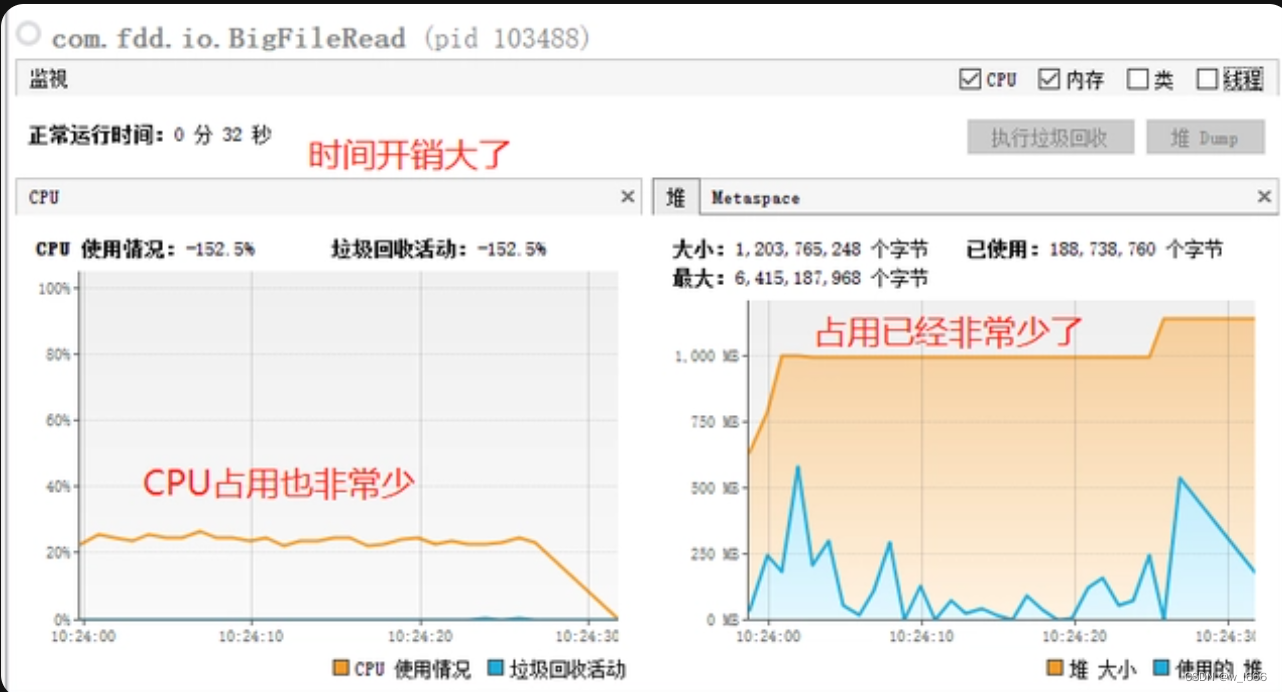 ?
?
从上图可以看出:
时间消耗:32秒,增加了一倍堆内存:最高1G,少了一半CPU消耗:平稳运行25%左右?
方式4:Apache Commons IO流?
代码如下:
@org.junit.Test
public void TestApacheCommonsIOReanFile() throws IOException {
//本次测试的这个outPut.csv文件的大小是624MB
String filePath = "D:\\outPut.csv";
Long startTime = System.currentTimeMillis();
LineIterator lineIterator = null;
try {
lineIterator = FileUtils.lineIterator(new File(filePath), "UTF-8");
while (lineIterator.hasNext()) {
String line = lineIterator.nextLine();
System.out.println(line);
}
} finally {
LineIterator.closeQuietly(lineIterator);
}
Long endTime = System.currentTimeMillis();
long consume = (endTime - startTime)/1000;
System.out.println("************CommonsIo方式总共耗时:"+consume+"秒*****************");
}?运行结果:

从上图可以看出:
时间消耗:16秒,最低堆内存:最高650M,少了一半
总结?:
从四种方式可以看出,性能最优的是Apache Commons IO流 对大文件的处理。
我们可以得出一个结论,如果我们想要读取一个大文件,选择了错误的方式,就有可能极大地占用我的内存和CPU,当文件特别大时,会造成意向不到的问题。
因此为了去解决这样的问题,有四种常见的读取大文件的方式。通过分析对比,发现,Apache Commons IO流是最高效的一种方式。
文章来源:https://blog.csdn.net/w_l666/article/details/135226207
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!