MapReduuce配置&YARN集群部署并启动(非常详细!!)
2023-12-22 21:33:24
🐮博主syst1m 带你 acquire knowledge!
?博客首页——syst1m的博客💘
😘《CTF专栏》超级详细的解析,宝宝级教学让你从蹒跚学步到健步如飞🙈
😎《大数据专栏》大数据从0到秃头👽,从分析到决策,无所不能?
🔥 《python面向对象(人狗大战)》突破百万的阅读量,上过各种各样的官方大型专栏,python面向对象必学之一!🐽
🎉希望本文能够给读者带来帮助,更好地理解这个问题或解决你的困惑🐾
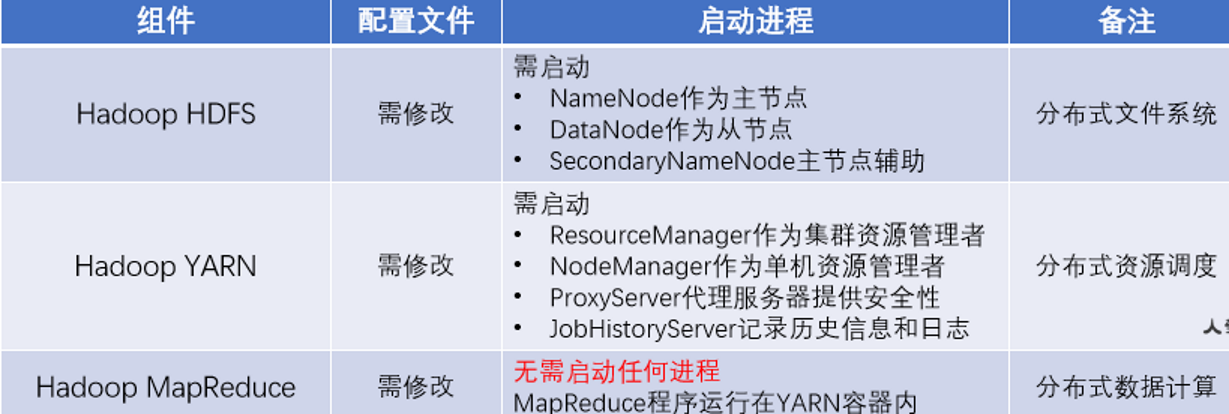
1.部署集群概述
1.1 修改YARN和MapReduce相关配置文件,仅修改YARN的相关进程(MapReduce无需启动进程,需要时会运行YARN内部(容器中))
1.2 查看YARN运行页面
1.3 环境概述
hadoop YARN分布式资源调度,会启动ResourceManager进程作为管理节点,NodeManager进程作为工作节点,ProxyServer,JobHistoryServer这两个辅助节点
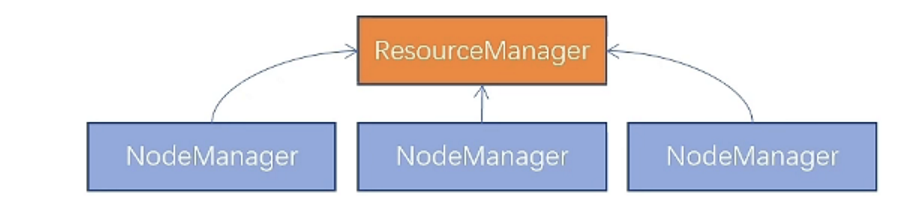
2.集群规划
有三台服务器,其中node1配置较高,集群如下:

3.MapReduce配置文件
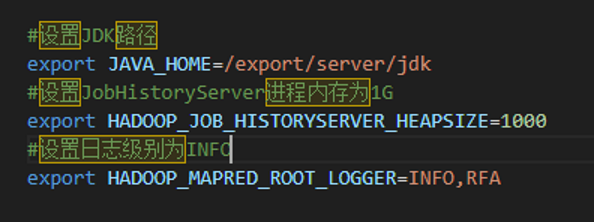
3.1 在$HADOOP_HOME/etc/hadoop文件夹内,修改mapred-env.sh文件,添加如下环境变量
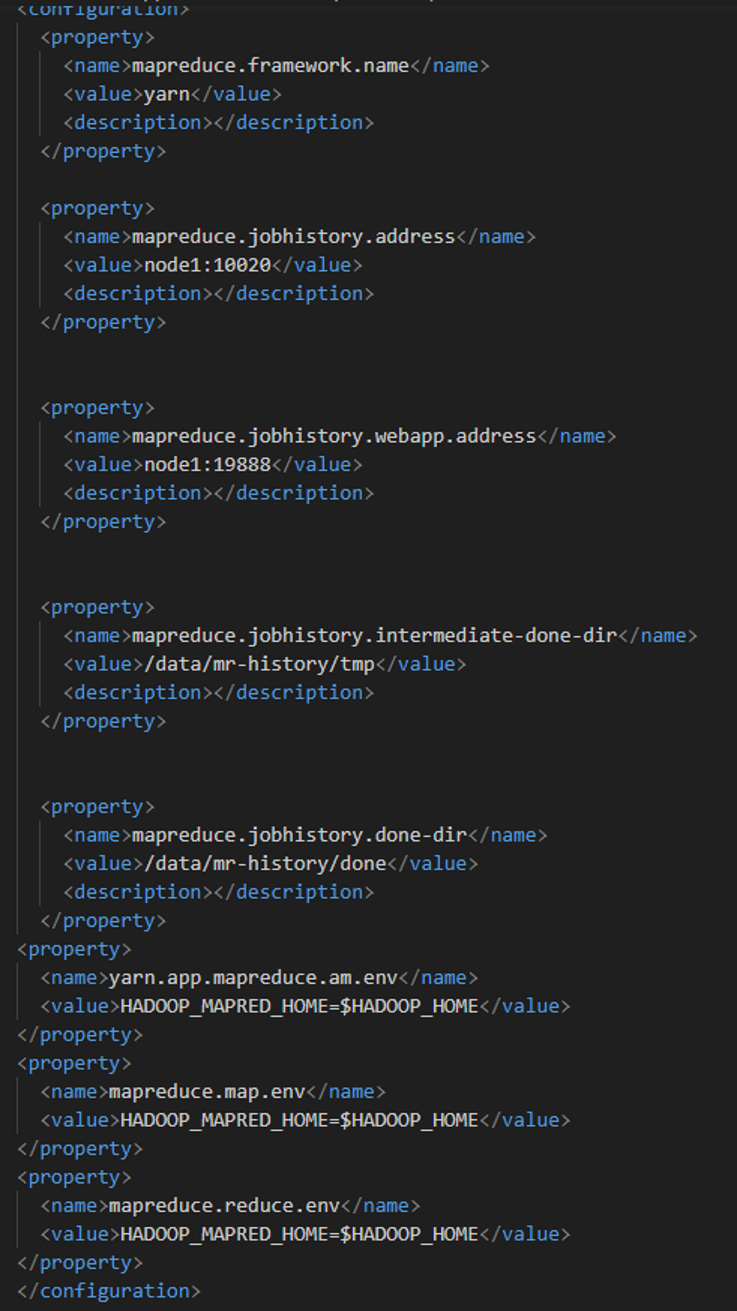
3.2 mapred-site.xml文件
3.3 yarn-env.sh文件
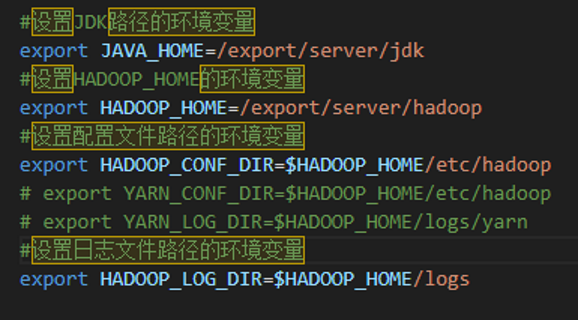
3.4 yarn-site.xml 核心配置
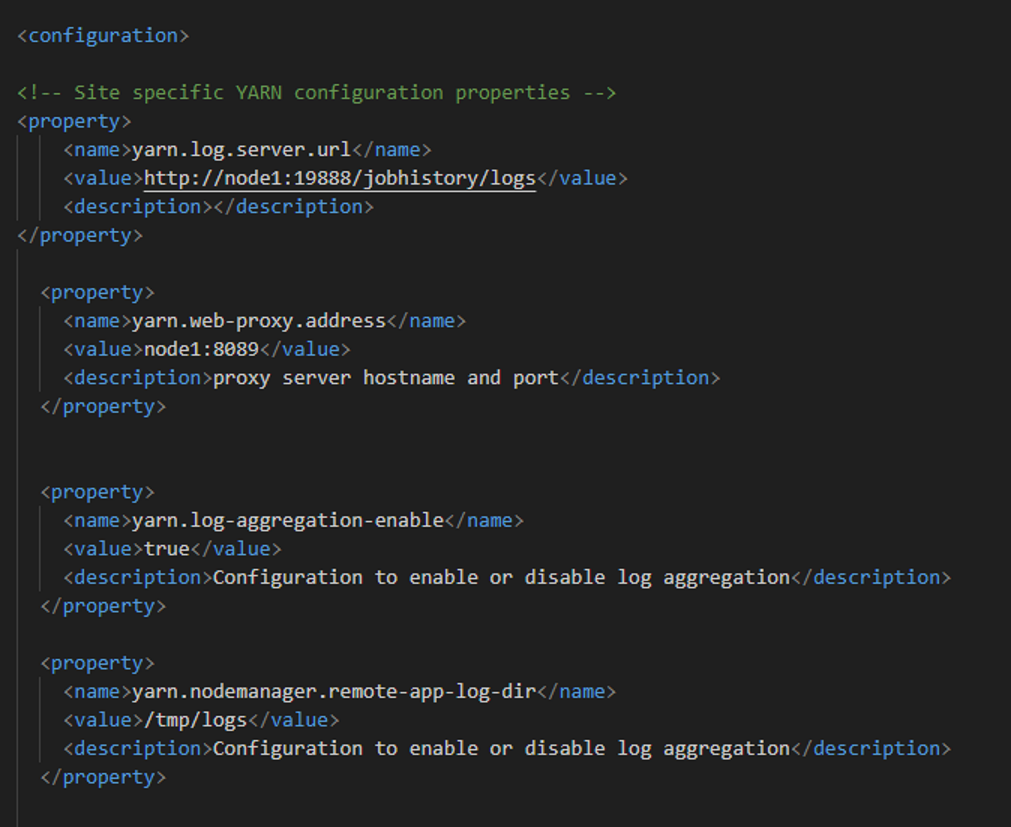
额外配置

3.5 分发文件
配置好文件之后,和之前的HDFS一样分发文件到root2,root3,分发到其他的服务器节点中
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml root2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml root3:`pwd`/
分发完成配置文件,就可以启动YARN的相关进程了
4.启动集群
集群启动命令介绍:
一键启动YARN集群:$HADOOP_HOME/sbin/start-yarn.sh
会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定哪台机器上启动resourcemanager
会基于workers文件配置的主机启动NodeManager
一键停止YARN集群:$HADOOP_HOME/sbin/stop-yarn.sh
在当前机器,单独启动或停止进程
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager | nodemanager | proxyserver
start和stop决定启动和停止
历史服务器启动和停止
$HADOOP_HOME/bin/mapred --daemon start | stop | historyserver
4.1 启动YARN集群
在root1服务器,以hadoop用户执行
首先执行:$HADOOP_HOME/sbin/start-yarn.sh

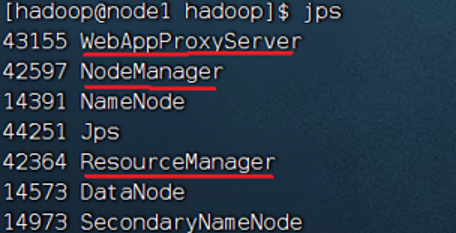
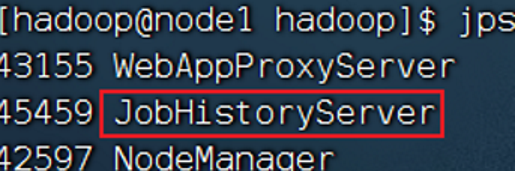
之后执行$HADOOP_HOME/bin/mapred --daemon start historyserver(历史服务器)
访问root1:8088页面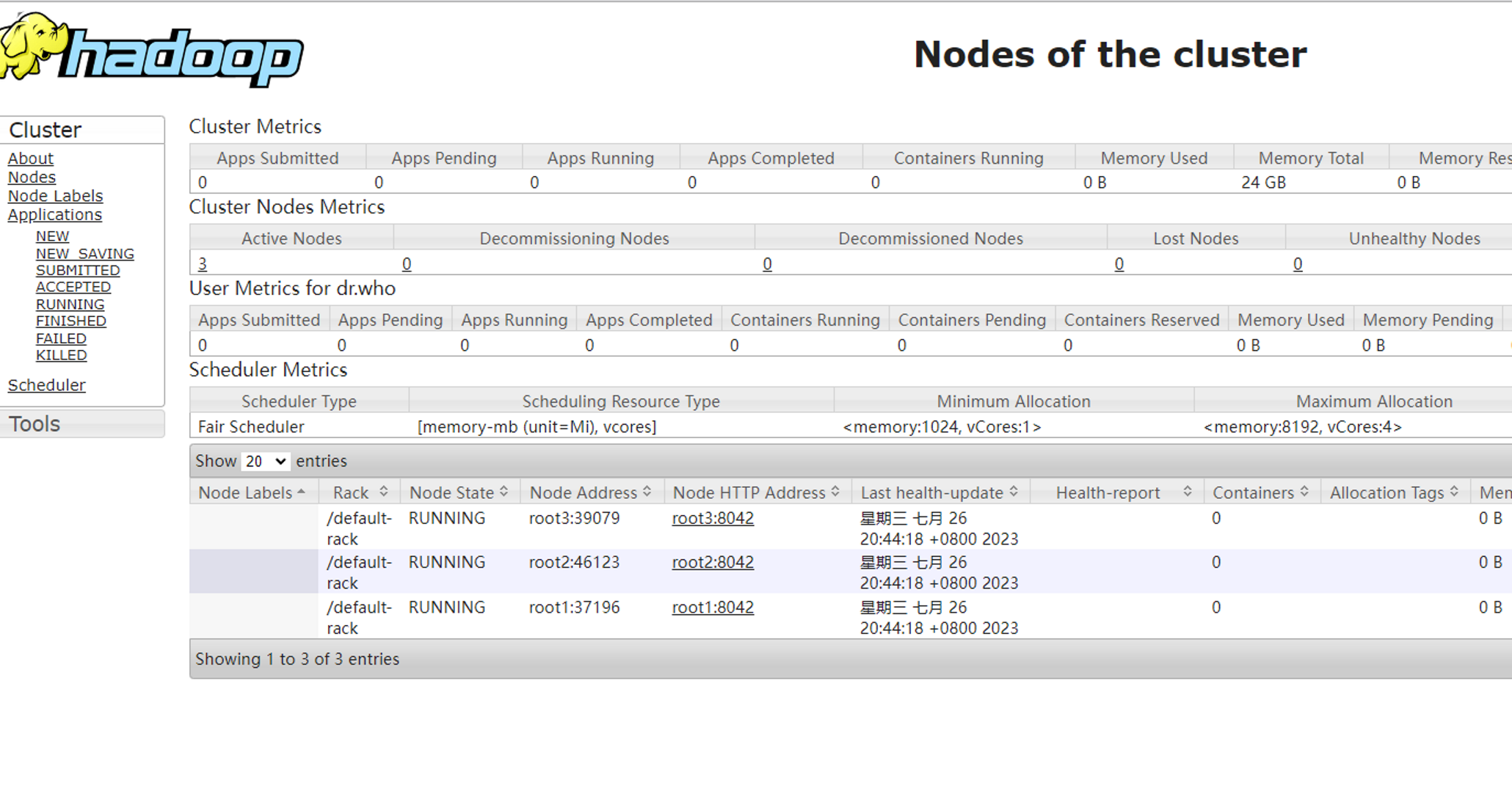
5.总结
今天的MapReduuce配置&YARN集群部署,算是大数据学习路上的必经之路,虽然说配置文件中的内容非常多,其实分段理解,还不算什么特别难的的东西,跟着教程慢慢来,注意中间的配置文件内容别出错了,启动就直接ok了,最后看到这样的web页面也是成就感满满
文章来源:https://blog.csdn.net/hexiaan/article/details/135160691
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!