工具系列:PyCaret介绍_模型训练详细教程
工具系列:PyCaret介绍_模型训练详细教程
1. PyCaret初始化
1.1 setup
此函数在PyCaret中初始化实验,并根据函数中传递的所有参数创建转换流水线。在执行任何其他函数之前,必须调用设置函数。它接受两个必需参数:data和target。所有其他参数都是可选的。
示例
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 使用pycaret的classification模块,初始化一个分类器clf1,将数据集diabetes作为数据源,将目标变量设置为‘Class variable’
# 比较不同模型的性能
compare_models()
# 使用pycaret的classification模块,比较不同的分类模型的性能,并输出结果
任务:自动推断数据类型
当你运行设置函数时,PyCaret会自动推断数据集中所有变量的数据类型。如果推断正确,你可以按回车键继续。
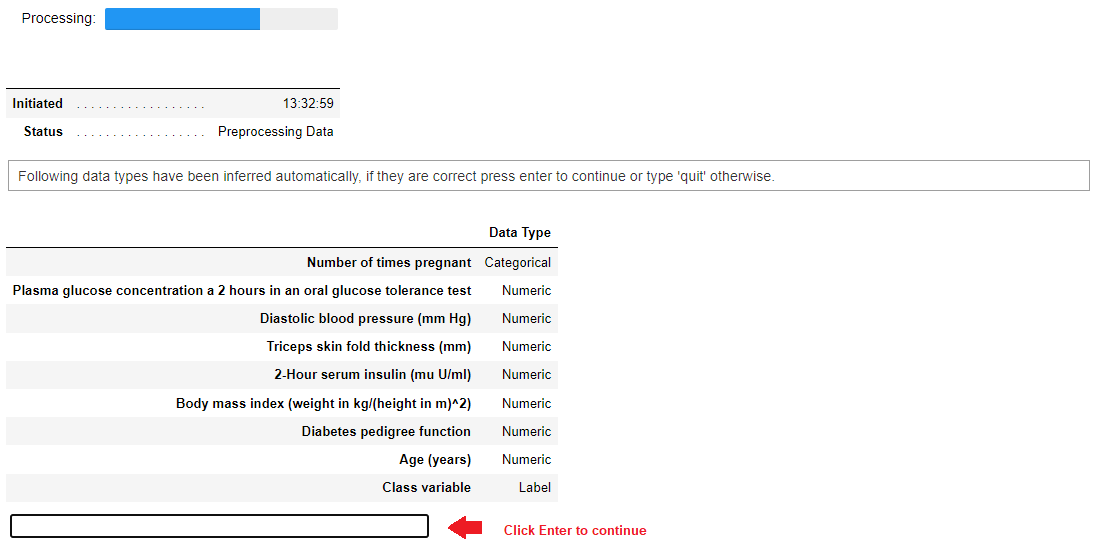
一旦您按下回车键继续,您将看到如下输出:
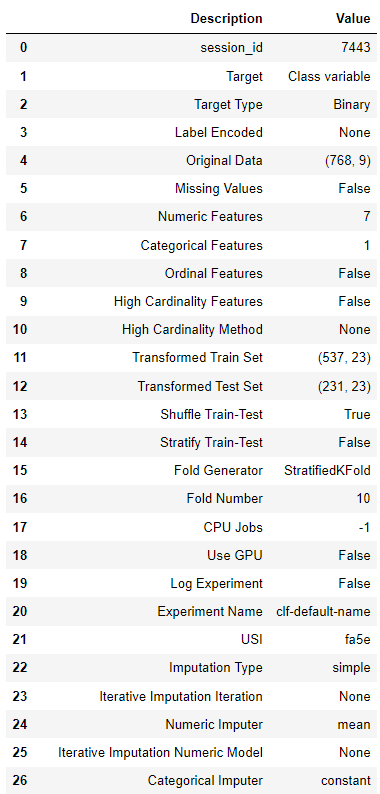
所有的预处理和数据转换都在setup函数中进行配置。有很多选项可供选择,从数据清洗到特征工程都可以进行配置。要了解更多关于所有可用的预处理的信息,请参阅此页面。
**注意:**如果您不想看到数据类型确认信息,可以在setup中传递silent=True来运行它,以避免任何中断。
必需参数
在setup函数中有很多参数,但只有两个是非可选的。
-
data: pandas.DataFrame\
****形状为(n_samples, n_features)的数据框,其中n_samples是样本数量,n_features是特征数量。
-
target: str\
****要传递的目标列的名称,以字符串形式。
**注意:**对于clustering、anomaly detection或NLP等无监督模块,不需要目标参数。
默认转换
在setup中的所有预处理步骤只是一个True或False的标志。例如,如果您想要对特征进行缩放,您将需要在setup函数中传递normalize=True。然而,默认情况下会发生三件事:
实验记录
PyCaret使用MLflow进行实验跟踪。可以通过在setup中启用一个参数来自动跟踪所有指标、超参数和其他关于机器学习模型的重要信息。
示例
# 加载数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
# 创建一个分类器对象clf1,并使用setup函数进行初始化设置
# data:要使用的数据集
# target:目标变量的名称
# log_experiment:是否记录实验日志
# experiment_name:实验的名称
clf1 = setup(data, target='Class variable', log_experiment=True, experiment_name='diabetes1')
# 模型训练
# 使用compare_models函数比较不同模型的性能,并选择最佳模型
best_model = compare_models()
为了初始化 MLflow 服务器,您必须从笔记本或命令行中运行以下命令。一旦服务器初始化完成,您可以在 https://localhost:5000 上跟踪您的实验。
# 初始化服务器
!mlflow ui
# 这行代码是用来启动MLflow的用户界面(UI)的命令。MLflow是一个开源的机器学习平台,可以帮助我们管理、追踪和部署机器学习模型。通过运行这行代码,我们可以在本地启动MLflow的用户界面,以便于我们查看和管理实验、模型和运行结果。
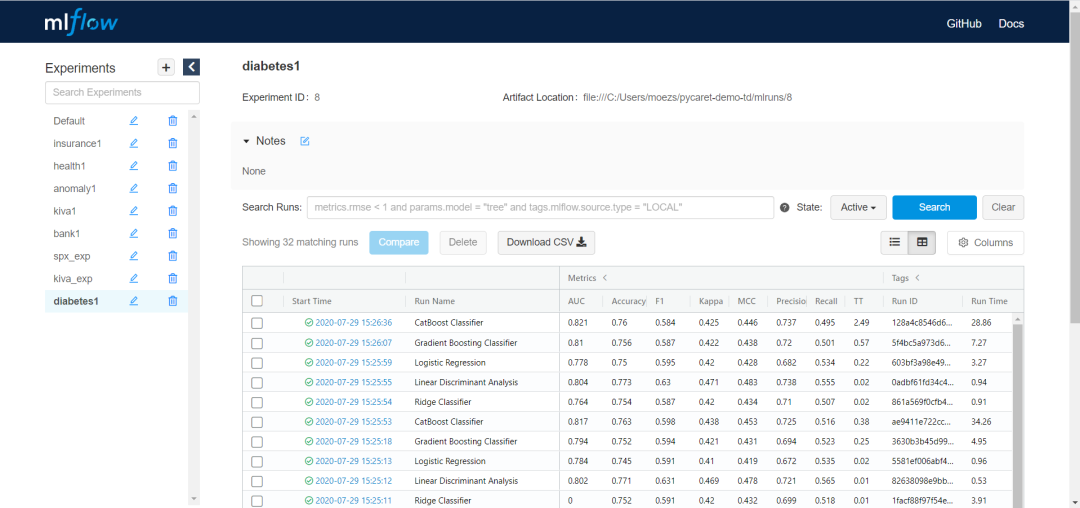
了解在PyCaret中的实验跟踪,请参见此页面。
模型验证
在setup函数中有许多参数与预处理或数据转换无直接关系,但它们作为模型验证和选择策略的一部分使用,例如train_size、fold_strategy或交叉验证的fold数量。要了解setup中所有模型验证和选择设置的更多信息,请参见此页面。
GPU支持
使用PyCaret,您可以在GPU上训练模型,并将工作流程加速10倍。要在GPU上训练模型,只需在setup函数中传递use_gpu = True。API的使用没有变化,但在某些情况下,必须安装其他库,因为它们未与默认版本或完整版本一起安装。要了解有关GPU支持的更多信息,请参见此页面。
示例
要查看PyCaret的其他模块中使用setup的用法,请参见以下内容:
**注意:**setup函数在Python中使用全局环境变量。因此,如果在同一脚本中两次运行setup函数,则会覆盖先前的实验。PyCaret的下一个主要版本将包括一个新的面向对象的API,通过类实例可以创建多个实例。
description: PyCaret中的训练函数
Train
compare_models
此函数使用交叉验证训练和评估模型库中所有可用的估计器的性能。此函数的输出是具有平均交叉验证分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
示例
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
best = compare_models()

compare_models函数根据sort参数中定义的标准,仅返回表现最佳的模型。对于分类实验,标准是Accuracy,而对于回归实验,标准是R2。您可以通过传递基于您想要进行模型选择的指标的名称来更改sort顺序。
更改排序顺序
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
best = compare_models(sort = 'F1') # 按F1值对模型进行排序,返回最佳模型
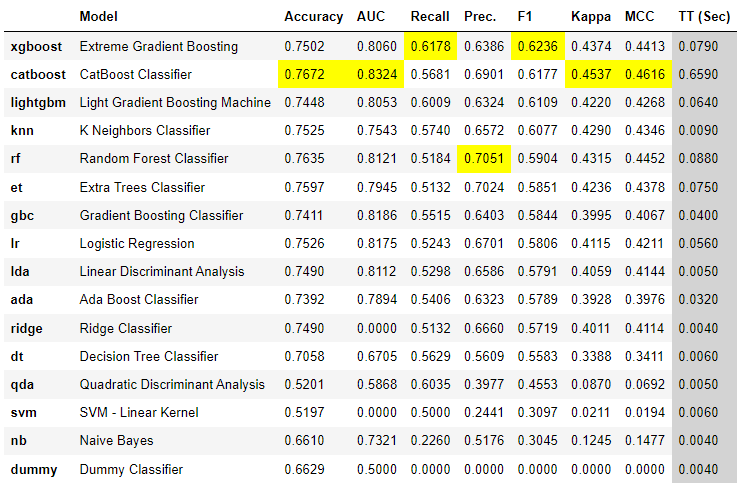
注意,现在评分网格的排序顺序已经改变,并且此函数返回的最佳模型是基于F1选择的。
# 打印输出变量best的值
print(best)

只比较几个模型
如果您不想在整个模型库上进行赛马比赛,您可以使用include参数仅比较您选择的几个模型。
# 导入数据集
# 使用get_data函数从PyCaret库中导入diabetes数据集,该数据集是一个糖尿病患者的数据集,包含多个特征和一个目标变量。
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
# 使用setup函数来初始化PyCaret的分类任务设置,将数据集diabetes作为输入,并指定目标变量为'Class variable'。
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
# 使用compare_models函数来比较不同的分类模型,包括逻辑回归(lr)、决策树(dt)和轻量级梯度提升机(lightgbm)。
# 返回的best变量将包含最佳模型的信息。
best = compare_models(include = ['lr', 'dt', 'lightgbm'])

或者,您还可以使用exclude参数。这将比较除了传递给exclude参数的模型之外的所有模型。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
best = compare_models(exclude = ['lr', 'dt', 'lightgbm'])
# 导入get_data函数从pycaret.datasets模块中,获取名为'diabetes'的数据集,并将其赋值给变量diabetes
# 从pycaret.classification模块中导入所有内容,并将其赋值给变量clf1。使用setup函数对数据集diabetes进行初始化设置,指定目标变量为'Class variable'
# 使用compare_models函数比较模型的性能,并将最佳模型赋值给变量best。在比较模型时,排除'lr'、'dt'和'lightgbm'三个模型。

返回多个模型
默认情况下,compare_models只返回表现最好的模型,但如果你想要,你可以得到前N个模型而不仅仅是一个模型。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
# 选择3个最佳模型
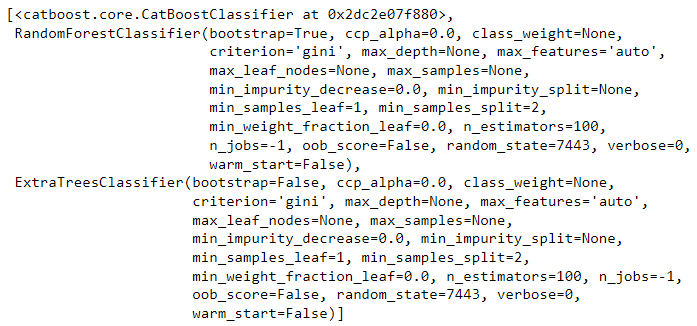
best = compare_models(n_select = 3)

请注意,结果没有变化,但是如果你检查变量 best ,它现在将包含一个包含前三个模型的列表,而不仅仅是之前看到的一个模型。
# 定义一个变量best,类型为list
type(best)
>>> list
# 打印变量best的值
print(best)
设置预算时间
如果您时间紧迫,并希望为此函数设置一个固定的预算时间,您可以通过设置budget_time参数来实现。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
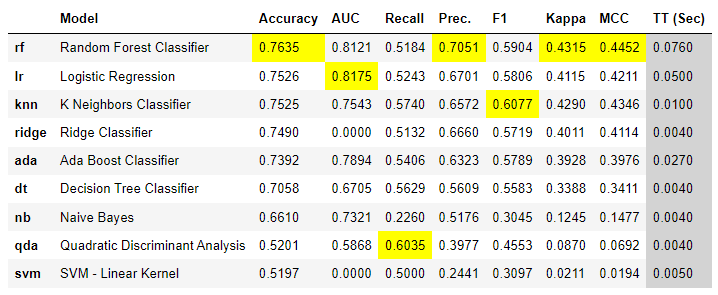
# 使用0.5秒的时间预算来比较模型
best = compare_models(budget_time = 0.5)
设置概率阈值
在进行二元分类时,您可以更改概率阈值或硬标签的截断值。默认情况下,所有分类器都使用0.5作为默认阈值。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
best = compare_models(probability_threshold = 0.25)
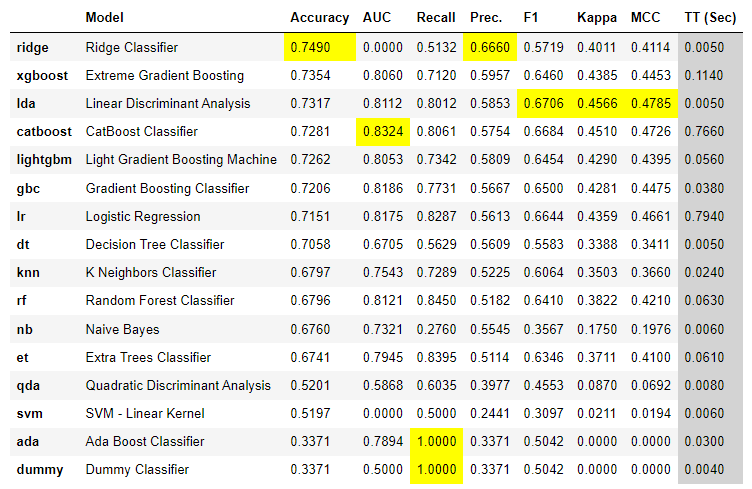
请注意,除了AUC之外,所有的指标现在都不同了。AUC不会改变,因为它不依赖于硬标签,其他所有指标都依赖于硬标签,现在使用probability_threshold=0.25来获取硬标签。
**注意:**此参数仅适用于PyCaret的分类模块。
禁用交叉验证
如果您不想使用交叉验证来评估模型,而只是训练它们并在测试/保留集上查看指标,您可以将cross_validation=False。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 比较模型
best = compare_models(cross_validation=False)
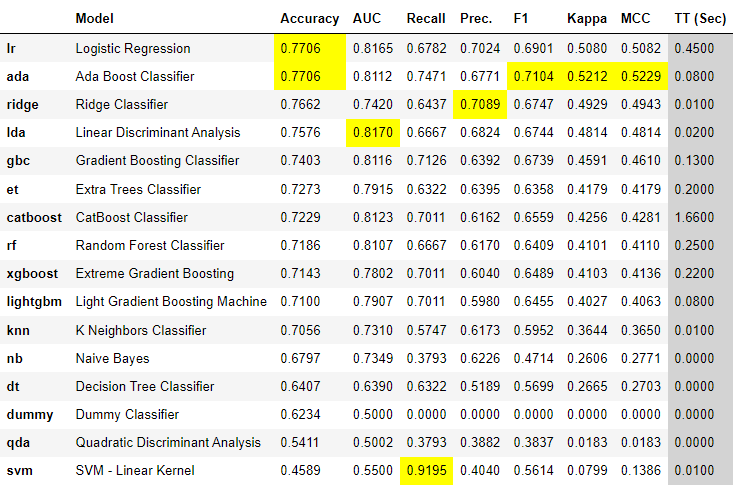
输出如下:
输出结果看起来非常相似,但是如果你仔细观察,指标现在是不同的,这是因为这些指标是在测试/留出集上计算的,而不是平均交叉验证分数。
在集群上进行分布式训练
为了在大型数据集上进行扩展,您可以使用一个名为parallel的参数,在分布式模式下在集群上运行compare_models函数。它利用Fugue抽象层在Spark或Dask集群上运行compare_models。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable', n_jobs = 1)
# 创建Pyspark会话
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# 导入并行后端
from pycaret.parallel import FugueBackend
# 比较模型
best = compare_models(parallel = FugueBackend(spark))

请注意,在使用本地 Spark 进行测试时,我们需要在设置中设置 n_jobs = 1,因为某些模型已经尝试使用所有可用的核心,并行运行这些模型可能会由于资源争用而导致死锁。
对于 Dask,我们可以在 FugueBackend 中指定 "dask",它将获取可用的 Dask 客户端。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable', n_jobs = 1)
# 导入并行后端
from pycaret.parallel import FugueBackend
# 比较模型
best = compare_models(parallel = FugueBackend("dask"))
# 以上代码是使用PyCaret库进行机器学习任务的示例代码。
# 首先,我们从`pycaret.datasets`模块中导入`get_data`函数,并使用`diabetes`作为参数来获取一个名为`diabetes`的数据集。
# 然后,我们从`pycaret.classification`模块中导入所有内容,并使用`setup`函数来初始化设置。在这里,我们将`diabetes`数据集作为输入数据,并指定`'Class variable'`作为目标变量。`n_jobs`参数设置为1,表示使用单个进程进行计算。
# 接下来,我们从`pycaret.parallel`模块中导入`FugueBackend`类,该类是一个并行计算后端。
# 最后,我们使用`compare_models`函数来比较不同的模型。`parallel`参数设置为`FugueBackend("dask")`,表示使用`FugueBackend`作为并行计算后端,并使用`dask`作为后端的实现。比较结果将存储在`best`变量中。
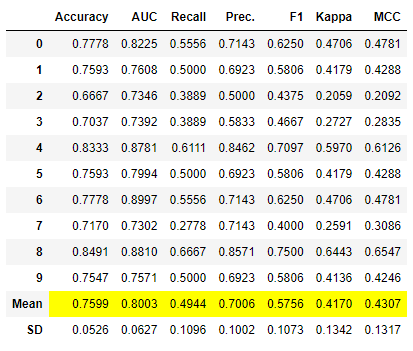
create_model
该函数使用交叉验证训练和评估给定估计器的性能。该函数的输出是一个包含每个折叠的CV得分的评分表。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。可以使用models函数访问所有可用的模型。
示例
要获取完整示例和与分布式执行相关的其他功能,请查看此示例。该示例还展示了如何实时获取排行榜。在分布式设置中,这涉及设置一个RPCClient,但Fugue简化了这一过程。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练逻辑回归模型
lr = create_model('lr')
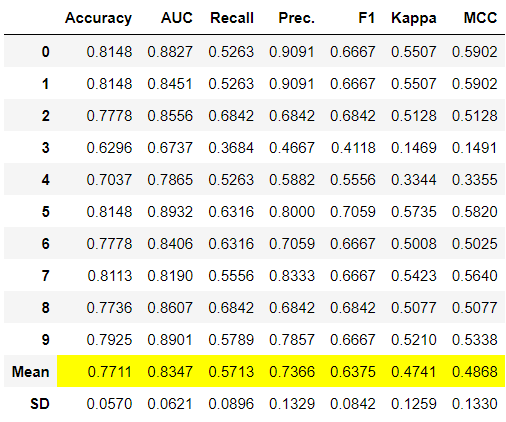
这个函数通过折叠显示性能指标,并显示每个指标的平均值和标准差,并返回训练好的模型。默认情况下,它使用10折,可以在setup函数中全局更改,也可以在create_model中局部更改。
更改折叠参数
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练逻辑回归模型
lr = create_model('lr', fold = 5)

模型库
要查看任何模块中可用模型的列表,可以使用 models 函数。
使用此函数返回的模型与上面的相同,但是使用了 5 折交叉验证进行性能评估。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 查看可用的模型
models()

带有自定义参数的模型
当您只运行create_model('dt')时,它将使用所有默认的超参数设置来训练决策树。如果您想要更改它,只需在create_model函数中传递属性即可。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练决策树模型
dt = create_model('dt', max_depth = 5)

# 输出决策树模型的参数
print(dt)

访问评分表格
在使用create_model之后,您所看到的性能指标/评分表格只是显示的,并不会返回。因此,如果您想要以pandas.DataFrame的形式访问该表格,您需要在create_model之后使用pull命令。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练决策树模型
dt = create_model('dt', max_depth = 5)
# 获取评分结果
dt_results = pull()
print(dt_results)
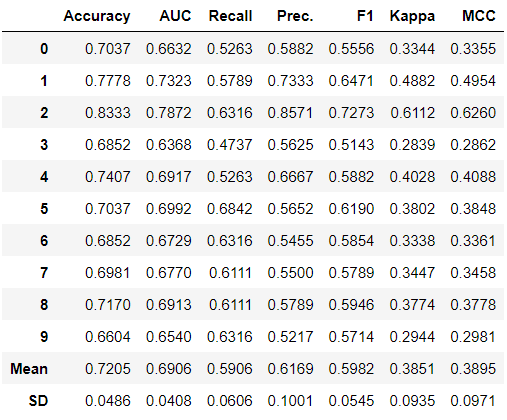
# 检查数据类型
type(dt_results)
>>> pandas.core.frame.DataFrame
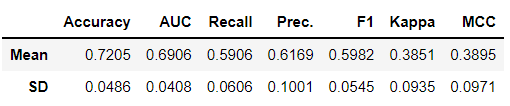
# 选择只包含均值和标准差的数据
dt_results.loc[['Mean', 'SD']]
禁用交叉验证
如果您不想使用交叉验证来评估模型,而只是训练它们并在测试/保留集上查看指标,您可以设置 cross_validation=False。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练模型,不使用交叉验证
lr = create_model('lr', cross_validation = False)

这些是测试/保留集上的度量指标。这就是为什么您只能看到一行,而不是原始输出中的12行。当您禁用cross_validation时,模型只会在整个训练数据集上进行一次训练,并使用测试/保留集进行评分。
返回训练分数
默认的评分网格显示了按折叠在验证集上的性能指标。如果您想要查看按折叠在训练集上的性能指标,以检查过拟合/欠拟合,您可以使用return_train_score参数。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练模型,不使用交叉验证
lr = create_model('lr', return_train_score = True)

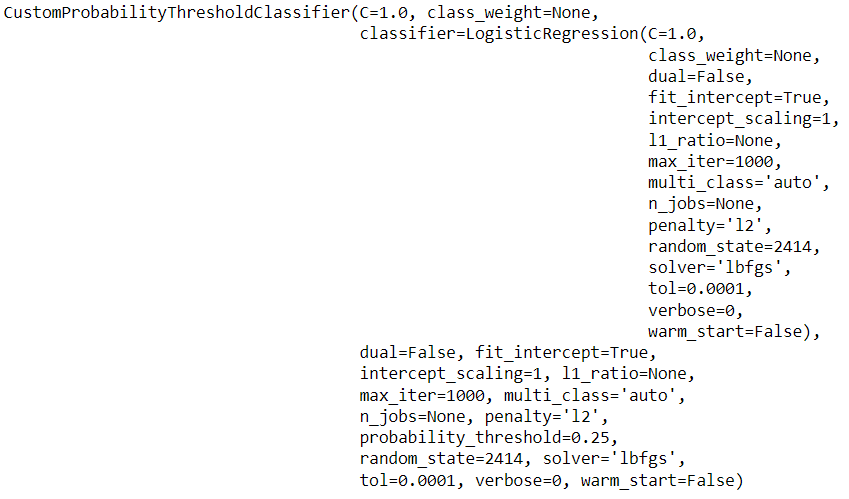
设置概率阈值
在进行二元分类时,您可以更改概率阈值或硬标签的截断值。默认情况下,所有分类器都使用0.5作为默认阈值。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 使用0.25的概率阈值训练模型
lr = create_model('lr', probability_threshold = 0.25)
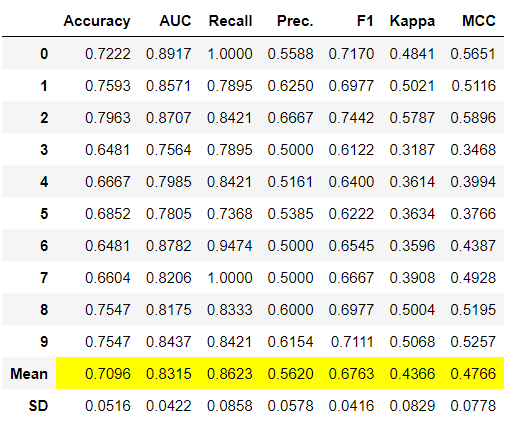
# 打印模型
print(lr)
在循环中训练模型
您可以在循环中使用create_model函数来训练多个模型,甚至是使用不同配置训练相同的模型,并比较它们的结果。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 在循环中训练模型
# 创建一个列表lgbs,其中包含了使用不同学习率的lightgbm模型
# 学习率的取值范围是从0到1,步长为0.1
lgbs = [create_model('lightgbm', learning_rate = i) for i in np.arange(0,1,0.1)]

type(lgbs)
>>> list
len(lgbs)
>>> 9
如果您想跟踪指标,就像大多数情况下一样,这是您可以做的方式。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 开始循环
models = [] # 存储模型
results = [] # 存储结果
for i in np.arange(0.1,1,0.1): # 在0.1到1之间以0.1为步长进行循环
model = create_model('lightgbm', learning_rate = i) # 创建lightgbm模型,学习率为i
model_results = pull().loc[['Mean']] # 提取模型结果中的'Mean'部分
models.append(model) # 将模型添加到models列表中
results.append(model_results) # 将模型结果添加到results列表中
results = pd.concat(results, axis=0) # 将results列表中的结果按行拼接起来
results.index = np.arange(0.1,1,0.1) # 将结果的索引设置为0.1到1之间以0.1为步长的数值
results.plot() # 绘制结果的图形化展示

训练自定义模型
您可以使用自己的自定义模型进行训练,或使用其他不属于 pycaret 的库中的模型。只要它们的 API 与 sklearn 保持一致,就可以轻松使用。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 导入自定义模型
from gplearn.genetic import SymbolicClassifier
sc = SymbolicClassifier()
# 训练自定义模型
sc_trained = create_model(sc)

# 创建了一个名为sc_trained的变量,用于存储训练好的符号分类器模型
sc_trained = gplearn.genetic.SymbolicClassifier
# 打印sc_trained的类型,可以看到它是gplearn.genetic.SymbolicClassifier类的一个实例
print(type(sc_trained))
# 打印sc_trained的值,即训练好的符号分类器模型的详细信息
print(sc_trained)

编写自己的模型
您也可以编写自己的类,其中包含fit和predict函数。PyCaret将与此兼容。以下是一个简单的示例:
# 加载数据集
from pycaret.datasets import get_data
insurance= get_data('insurance')
# 初始化设置
from pycaret.regression import *
reg1 = setup(data = insurance, target = 'charges')
# 创建自定义估计器
import numpy as np
from sklearn.base import BaseEstimator
class MyOwnModel(BaseEstimator):
def __init__(self):
self.mean = 0
def fit(self, X, y):
self.mean = y.mean() # 计算目标变量y的均值
return self
def predict(self, X):
return np.array(X.shape[0]*[self.mean]) # 返回一个长度为X的样本数量的数组,每个元素都是目标变量y的均值
# 创建一个实例
my_own_model = MyOwnModel()
# 训练模型
my_model_trained = create_model(my_own_model) # 使用自定义的估计器创建并训练模型

description: 在PyCaret中的MLOps和部署相关的功能
description: 在PyCaret中的优化功能
Pycaret模型优化
tune_model
该函数用于调整模型的超参数。该函数的输出是一个通过交叉验证得到的得分网格。根据optimize参数中定义的指标选择最佳模型。可以使用get_metrics函数访问交叉验证期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
示例
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 调整模型
tuned_dt = tune_model(dt)

比较超参数。
# 打印默认模型
print(dt)
# 打印调整后的模型
print(tuned_dt)

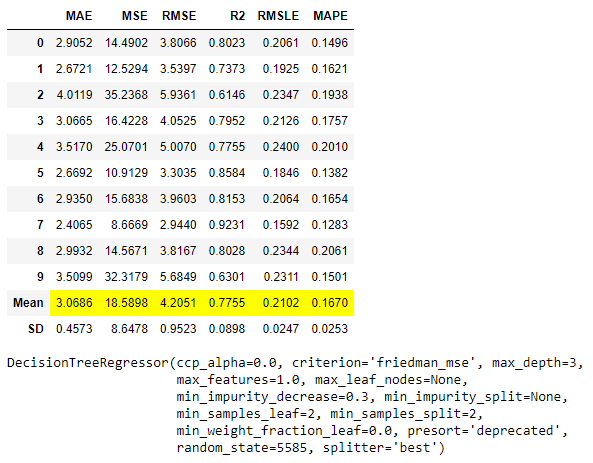
增加迭代次数
在一天结束时进行的超参数调整是一种受迭代次数限制的优化,最终取决于您可用的时间和资源。迭代次数由n_iter定义。默认情况下,它设置为10。
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 调整模型
tuned_dt = tune_model(dt, n_iter = 50)

10次和50次迭代的比较

选择指标
当你调整模型的超参数时,你必须知道要优化哪个指标。这可以在optimize参数下定义。默认情况下,对于分类实验,它被设置为Accuracy,对于回归实验,它被设置为R2。
# 加载数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(data = boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 调整模型
tuned_dt = tune_model(dt, optimize = 'MAE')

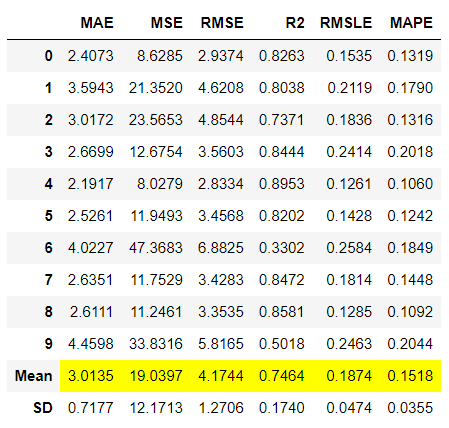
传递自定义网格
PyCaret已经为库中的所有模型定义了超参数的调整网格。然而,如果您希望,您可以通过使用custom_grid参数传递自定义网格来定义自己的搜索空间。
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 定义搜索空间
params = {"max_depth": np.random.randint(1, (len(boston.columns)*.85),20), # 随机生成20个max_depth值,范围为1到数据集列数的85%
"max_features": np.random.randint(1, len(boston.columns),20), # 随机生成20个max_features值,范围为1到数据集列数
"min_samples_leaf": [2,3,4,5,6]} # 给定5个min_samples_leaf值
# 调整模型
tuned_dt = tune_model(dt, custom_grid = params) # 使用定义的搜索空间对决策树模型进行调优
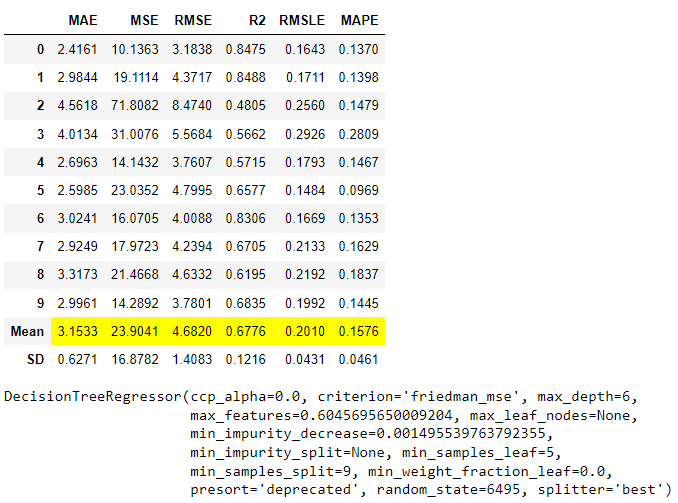
更改搜索算法
PyCaret与许多不同的超参数调整库无缝集成。这使您可以访问许多不同类型的搜索算法,包括随机搜索、贝叶斯搜索、optuna、TPE等等。只需更改一个参数即可实现所有这些功能。默认情况下,PyCaret使用sklearn的RandomGridSearch,您可以通过在tune_model函数中使用search_library和search_algorithm参数来更改。
# 加载数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 使用sklearn调整模型
tune_model(dt)
# 使用optuna调整模型
tune_model(dt, search_library = 'optuna')
# 使用scikit-optimize调整模型
tune_model(dt, search_library = 'scikit-optimize')
# 使用tune-sklearn调整模型
tune_model(dt, search_library = 'tune-sklearn', search_algorithm = 'hyperopt')



访问调谐器
默认情况下,PyCaret的tune_model函数仅返回调谐器选择的最佳模型。有时您可能需要访问调谐器对象,因为它可能包含重要属性,您可以使用return_tuner参数。
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 调整模型并返回调整器
tuned_model, tuner = tune_model(dt, return_tuner=True)

type(tuned_model), type(tuner)

# 打印tuner
print(tuner)

自动选择更好的模型
通常情况下,tune_model函数并不能提高模型的性能。事实上,它可能会使性能比默认超参数的模型更差。当您不是在Notebook中进行实时实验,而是在运行一个包含create_model --> tune_model或compare_models --> tune_model工作流程的Python脚本时,这可能会成为一个问题。为了解决这个问题,您可以使用choose_better函数。当设置为True时,它将始终返回一个性能更好的模型,这意味着如果超参数调整不能提高性能,它将返回输入的模型。
# 加载数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 调整模型
dt = tune_model(dt, choose_better = True)
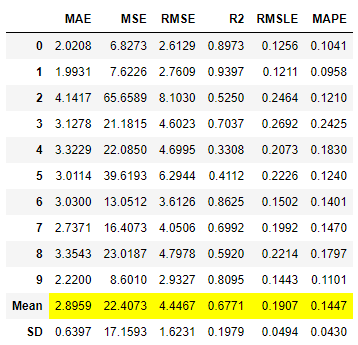
注意: choose_better 不会影响屏幕上显示的评分网格。评分网格将始终显示调谐器选择的最佳模型的性能,而不管输出性能是否小于输入性能。
ensemble_model
此函数对给定的估计器进行集成。此函数的输出是一个带有CV分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
示例
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 集成模型
bagged_dt = ensemble_model(dt)
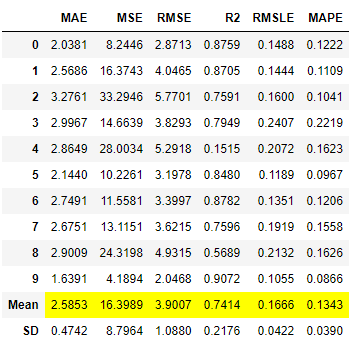
type(bagged_dt)
>>> sklearn.ensemble._bagging.BaggingRegressor
print(bagged_dt)
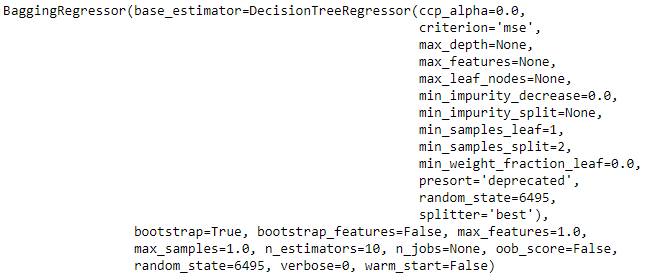
更改fold参数
# 加载数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 集成模型
bagged_dt = ensemble_model(dt, fold = 5)

方法:Bagging
Bagging,也称为_自助聚合_ ,是一种机器学习集成元算法,旨在提高统计分类和回归中使用的机器学习算法的稳定性和准确性。它还可以减少方差并帮助避免过拟合。虽然它通常应用于决策树方法,但它可以与任何类型的方法一起使用。Bagging是模型平均方法的特例。
使用此方法返回的模型与上面相同,但是使用5倍交叉验证进行性能评估。

方法:Boosting
Boosting是一种集成元算法,主要用于减少监督学习中的偏差和方差。Boosting属于机器学习算法家族,可以将弱学习器转化为强学习器。弱学习器被定义为与真实分类仅略微相关的分类器(它可以比随机猜测更好地标记示例)。相比之下,强学习器是与真实分类任意相关的分类器。

选择方法
您可以通过 ensemble_model 中的 method 参数来定义两种可能的方式来集成您的机器学习模型。
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 集成模型
boosted_dt = ensemble_model(dt, method = 'Boosting')

type(boosted_dt)
>>> sklearn.ensemble._weight_boosting.AdaBoostRegressor
print(boosted_dt)

增加估计器数量
默认情况下,PyCaret对于Bagging或Boosting都使用10个估计器。您可以通过更改n_estimators参数来增加估计器的数量。
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
dt = create_model('dt')
# 集成模型
ensemble_model(dt, n_estimators = 100)
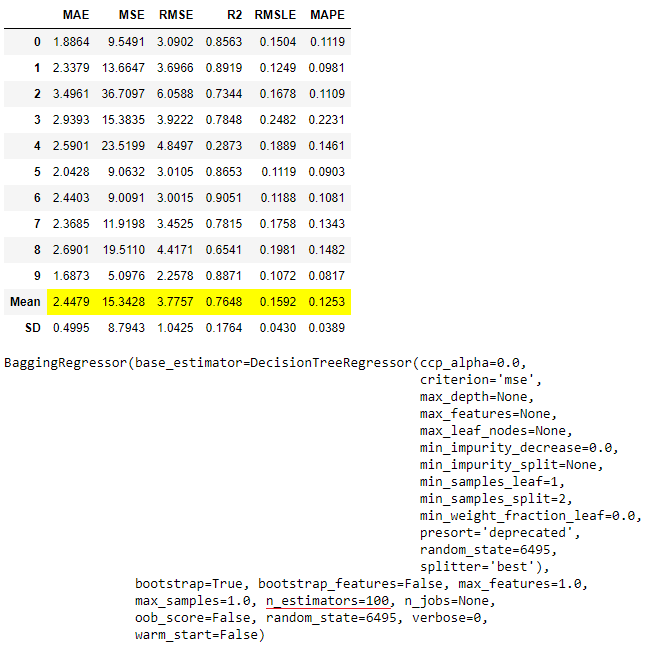
自动选择更好的模型
往往情况下,ensemble_model并不能提高模型的性能。事实上,它可能会使性能比没有使用集成的模型更差。当你不是在Notebook中进行实时实验,而是有一个运行create_model --> ensemble_model或compare_models --> ensemble_model的Python脚本时,这可能会成为一个问题。为了解决这个问题,你可以使用choose_better。当设置为True时,它将始终返回一个性能更好的模型,这意味着如果超参数调整不能改善性能,它将返回输入的模型。
# 导入数据集
from pycaret.datasets import get_data
boston = get_data('boston')
# 初始化设置
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# 训练模型
lr = create_model('lr')
# 集成模型
ensemble_model(lr, choose_better = True)

请注意,当choose_better = True时,从ensemble_model返回的模型是一个简单的LinearRegression,而不是BaggedRegressor。这是因为在集成之后模型的性能没有改善,因此返回输入模型。
blend_models
此函数对传入estimator_list参数的选择模型进行软投票/多数规则分类器的训练。此函数的输出是一个包含CV得分的得分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
示例
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 混合模型
blender = blend_models([lr, dt, knn]) # 将逻辑回归、决策树和K近邻模型混合在一起,形成一个新的模型

type(blender)
>>> sklearn.ensemble._voting.VotingClassifier
print(blender)

改变折叠参数
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 混合模型
blender = blend_models([lr, dt, knn], fold = 5) # 将逻辑回归、决策树和K近邻模型混合在一起,使用5折交叉验证训练混合模型
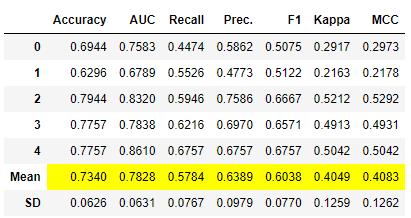
此模型返回的结果与上述相同,但是性能评估是使用5折交叉验证完成的。
动态输入估计器
您还可以使用compare_models函数自动生成输入估计器列表。这样做的好处是您无需更改脚本。每次都会使用前N个模型作为输入列表。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 混合模型
# 使用compare_models函数比较多个分类模型的性能,并选择其中的前3个模型
# 然后使用blend_models函数将这3个模型进行混合
blender = blend_models(compare_models(n_select = 3))

请注意这里发生了什么。我们将compare_models(n_select = 3)作为输入传递给了blend_models。内部发生的是,首先执行了compare_models函数,然后将前3个模型作为输入传递给了blend_models函数。
# 打印变量blender的值
print(blender)

在这个例子中,由compare_models评估的前3个模型是LogisticRegression、LinearDiscriminantAnalysis和RandomForestClassifier。
改变方法
当method = 'soft'时,它根据预测概率的总和的argmax来预测类别标签,这对于一组经过良好校准的分类器集合是推荐的。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 混合模型
blender_soft = blend_models([lr,dt,knn], method = 'soft') # 使用软投票方法混合逻辑回归、决策树和K近邻模型

当 method = 'hard' 时,它使用输入模型的预测(硬标签)而不是概率。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 混合模型
blender_hard = blend_models([lr,dt,knn], method = 'hard') # 使用硬投票方法混合逻辑回归、决策树和K近邻模型

默认方法设置为auto,这意味着它将尝试使用soft方法,如果前者不受支持,则回退到hard方法,当您的输入模型之一不支持predict_proba属性时,可能会发生这种情况。
**注意:**方法参数仅在分类模块中可用。
更改权重
默认情况下,当混合它们时,所有输入模型都被赋予相等的权重,但您可以明确地传递要赋予每个输入模型的权重。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K最近邻模型
# 混合模型
blender_weighted = blend_models([lr,dt,knn], weights = [0.5,0.2,0.3]) # 使用加权平均法混合逻辑回归、决策树和K最近邻模型,权重分别为0.5、0.2和0.3
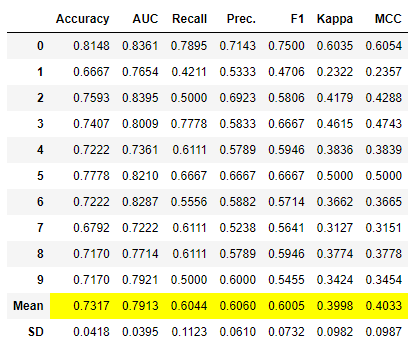
你也可以使用 tune_model 来调整混合器的权重。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K最近邻模型
# 混合模型
blender_weighted = blend_models([lr,dt,knn], weights = [0.5,0.2,0.3]) # 将逻辑回归、决策树和K最近邻模型混合,设置权重为[0.5,0.2,0.3]
# 调整混合模型
tuned_blender = tune_model(blender_weighted) # 调整混合模型的超参数
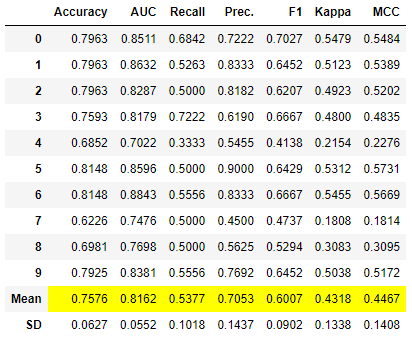
# 打印tuned_blender的值
print(tuned_blender)
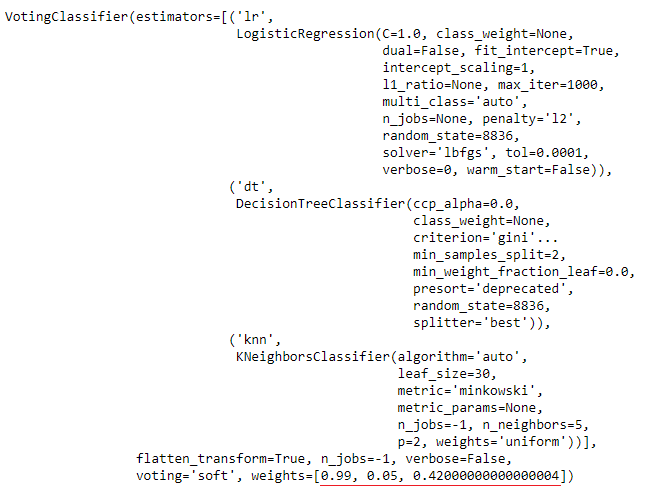
自动选择更好的模型
通常情况下,blend_models 不会提高模型的性能。事实上,它可能会使性能比混合模型更差。当您不是在笔记本中进行主动实验,而是有一个运行 compare_models --> blend_models 工作流的 Python 脚本时,这可能会成为一个问题。为了解决这个问题,您可以使用 choose_better。当设置为 True 时,它将始终返回性能更好的模型,这意味着如果混合模型不会提高性能,它将返回单个性能最佳的输入模型。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K最近邻模型
# 混合模型
blend_models([lr,dt,knn], choose_better = True) # 将逻辑回归、决策树和K最近邻模型混合在一起,选择最好的模型进行预测
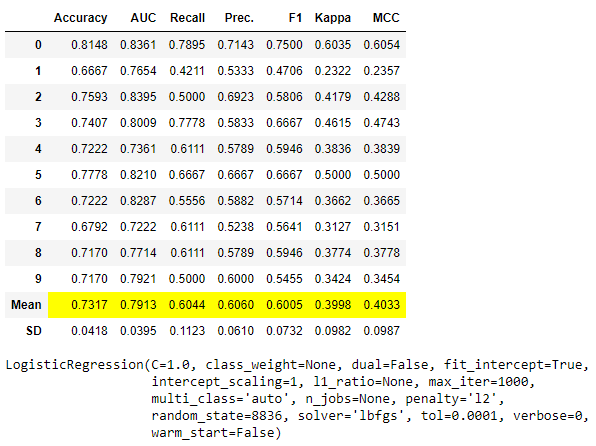
注意,由于choose_better=True,此函数返回的最终模型是LogisticRegression,而不是VotingClassifier,因为在所有给定的输入模型和混合器中,逻辑回归的性能最优化。
stack_models
此函数在estimator_list参数中传递的选择估计器上训练元模型。此函数的输出是一个带有CV得分的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
示例
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 堆叠模型
stacker = stack_models([lr, dt, knn]) # 将逻辑回归、决策树和K近邻模型堆叠起来

更改折叠参数
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 堆叠模型
stacker = stack_models([lr, dt, knn], fold = 5) # 将逻辑回归、决策树和K近邻模型堆叠起来,使用5折交叉验证训练堆叠模型
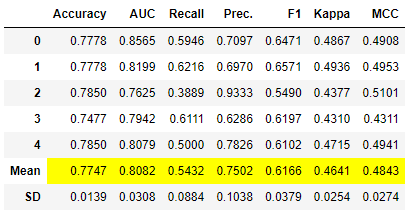
动态输入估计器
您还可以使用compare_models函数自动生成输入估计器列表。这样做的好处是您根本不需要更改脚本。每次都会使用前N个模型作为输入列表。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 堆叠模型
# 使用compare_models函数选择最佳的3个模型进行堆叠
stacker = stack_models(compare_models(n_select = 3))
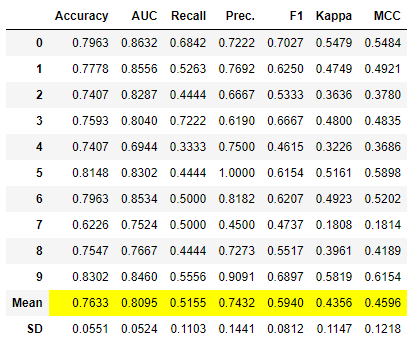
请注意这里发生了什么。我们将compare_models(n_select = 3作为输入传递给了stack_models。内部发生的是,compare_models函数首先被执行,然后将前3个模型作为输入传递给stack_models函数。
# 输出变量stacker的值
print(stacker)

在这个例子中,由compare_models评估的前3个模型是LogisticRegression、RandomForestClassifier和LGBMClassifier。
改变方法
您可以明确选择几种不同的方法来进行堆叠,或者传递auto以自动确定。当设置为auto时,它将按顺序调用每个模型的predict_proba、decision_function或predict函数。或者,您可以明确定义方法。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 堆叠模型
stacker = stack_models([lr, dt, knn], method = 'predict') # 将逻辑回归、决策树和K近邻模型堆叠起来,使用预测方法进行堆叠

更改元模型
当没有显式传递 meta_model 时,分类实验使用 LogisticRegression,回归实验使用 LinearRegression。您也可以传递一个特定的模型作为元模型。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 训练元模型
lightgbm = create_model('lightgbm') # 创建LightGBM模型
# 堆叠模型
stacker = stack_models([lr, dt, knn], meta_model = lightgbm) # 使用逻辑回归、决策树和K近邻模型作为基模型,使用LightGBM作为元模型
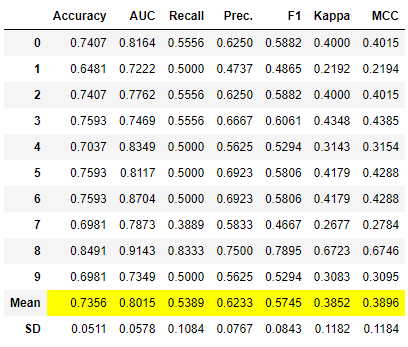
# 打印stacker的最终估计器
print(stacker.final_estimator_)

重叠
有两种方法可以堆叠模型。(i) 只使用输入模型的预测作为元模型的训练数据,(ii) 使用预测和原始训练数据来训练元模型。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练几个模型
lr = create_model('lr') # 创建逻辑回归模型
dt = create_model('dt') # 创建决策树模型
knn = create_model('knn') # 创建K近邻模型
# 堆叠模型
stacker = stack_models([lr, dt, knn], restack = False) # 将逻辑回归、决策树和K近邻模型堆叠在一起,不进行重新堆叠
optimize_threshold
该函数用于优化训练模型的概率阈值。它使用grid_interval参数中定义的步长在不同的probability_threshold上迭代性能指标。该函数将显示每个概率阈值下的性能指标图,并根据optimize参数下定义的指标返回最佳模型。
示例
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练模型
knn = create_model('knn')
# 优化阈值
optimized_knn = optimize_threshold(knn)
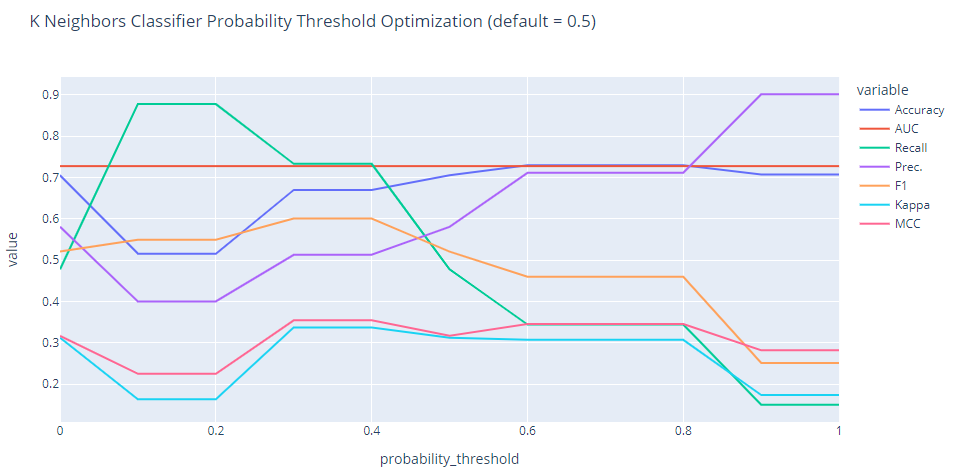
# 输出优化后的KNN模型
print(optimized_knn)

calibrate_model
该函数使用等温或逻辑回归来校准给定模型的概率。该函数的输出是一个带有每个折叠的CV分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
示例
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 训练模型
dt = create_model('dt')
# 校准模型
calibrated_dt = calibrate_model(dt)

# 打印calibrated_dt的值
print(calibrated_dt)

校准前后
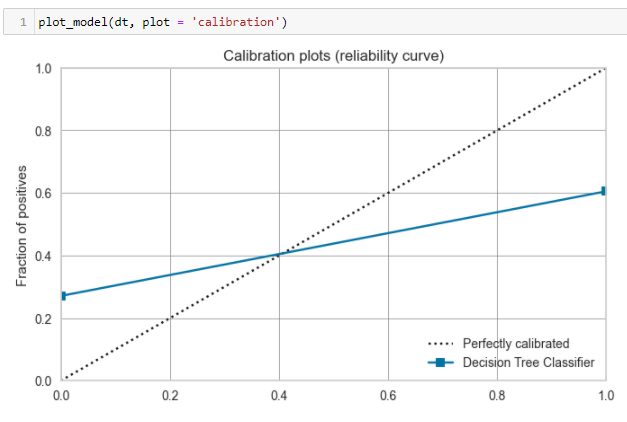

部署
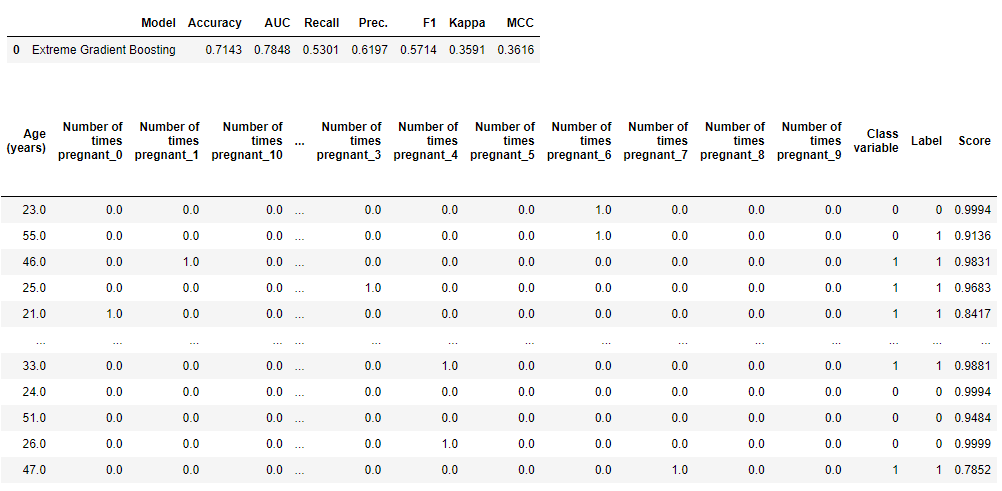
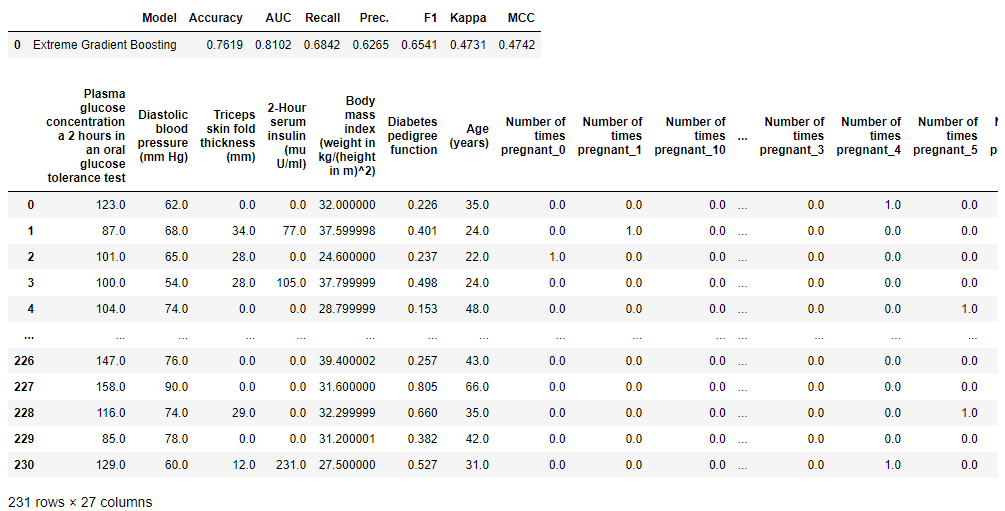
预测模型
该函数使用训练好的模型生成标签。当data为None时,它会在holdout数据集上预测标签和得分。
Hold-out预测
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
xgboost = create_model('xgboost')
# 在保留集上进行预测
predict_model(xgboost)
未见过的数据预测
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
xgboost = create_model('xgboost')
# 对新数据进行预测
new_data = diabetes.copy()
new_data.drop('Class variable', axis = 1, inplace = True)
predict_model(xgboost, data = new_data)

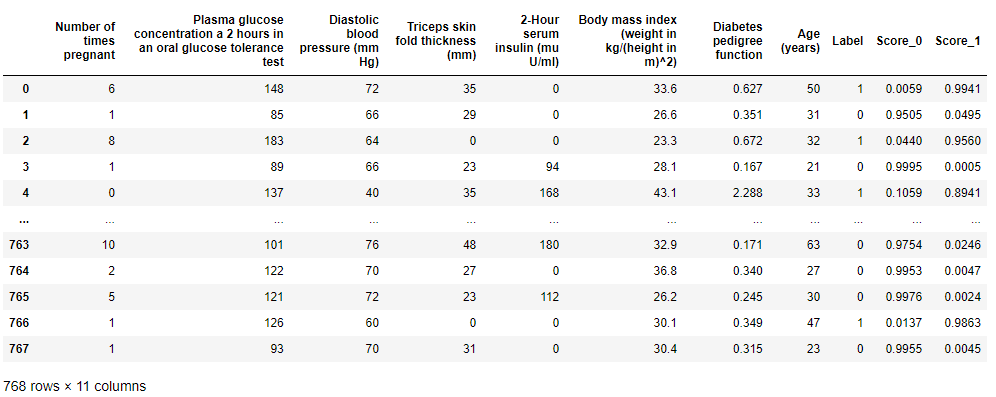
按类别的概率
注意: 这仅适用于分类用例。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
xgboost = create_model('xgboost')
# 对新数据进行预测
new_data = diabetes.copy()
new_data.drop('Class variable', axis = 1, inplace = True)
predict_model(xgboost, raw_score = True, data = new_data)
设置概率阈值
注意: 这仅适用于分类用例(仅限二分类)。
将预测概率转换为类标签的阈值。除非设置了此参数,否则它将默认为模型创建时设置的值。如果没有设置,则对于所有分类器,默认值将为0.5。仅适用于二分类。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
xgboost = create_model('xgboost')
# 设置概率阈值为0.3
predict_model(xgboost, probability_threshold = 0.3)
在留出数据上比较不同阈值的结果
监控数据漂移
可以使用drift_report参数生成交互式漂移报告。
# 导入必要的库
from pycaret.datasets import get_data # 从pycaret.datasets库中导入get_data函数,用于获取数据集
from pycaret.classification import * # 从pycaret.classification库中导入所有函数和类
# 加载数据集
diabetes = get_data('diabetes') # 使用get_data函数获取名为'diabetes'的数据集,并将其赋值给diabetes变量
# 初始化设置
clf1 = setup(data=diabetes, target='Class variable') # 使用setup函数对数据集进行初始化设置,将数据集diabetes作为输入数据,'Class variable'作为目标变量
# 创建模型
xgboost = create_model('xgboost') # 使用create_model函数创建一个名为'xgboost'的模型,并将其赋值给xgboost变量
# 在新数据上进行预测
predict_model(xgboost, drift_report=True) # 使用predict_model函数对新数据进行预测,并生成漂移报告




finalize_model
该函数在整个数据集上(包括保留集)训练给定的模型。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
rf = create_model('rf')
# 完成模型
finalize_model(rf)

deploy_model
该函数将整个机器学习流程部署到云端。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
lr = create_model('lr')
# 完成模型
final_lr = finalize_model(lr)
# 部署模型
deploy_model(final_lr, model_name = 'lr_aws', platform = 'aws', authentication = { 'bucket' : 'pycaret-test' })
# 将模型部署到AWS平台,模型名称为'lr_aws',认证方式为使用'pycaret-test'桶。

AWS
在将模型部署到AWS S3(‘aws’)之前,必须使用命令行界面配置环境变量。要配置AWS环境变量,请在python命令行中输入aws configure命令。以下信息是必需的,可以使用您的Amazon控制台帐户的身份和访问管理(IAM)门户生成:
-
AWS访问密钥ID
-
AWS秘密密钥访问
-
默认区域名称(可以在AWS控制台的全局设置下看到)
-
默认输出格式(必须留空)
GCP
要在Google Cloud Platform(‘gcp’)上部署模型,必须使用命令行或GCP控制台创建项目。创建项目后,必须创建服务帐户并将服务帐户密钥下载为JSON文件,以在本地环境中设置环境变量。
了解更多信息:https://cloud.google.com/docs/authentication/production
Azure
要在Microsoft Azure(‘azure’)上部署模型,必须在本地环境中设置用于连接字符串的环境变量。转到Azure门户上的存储帐户设置以访问所需的连接字符串。
- AZURE_STORAGE_CONNECTION_STRING(作为环境变量必需)
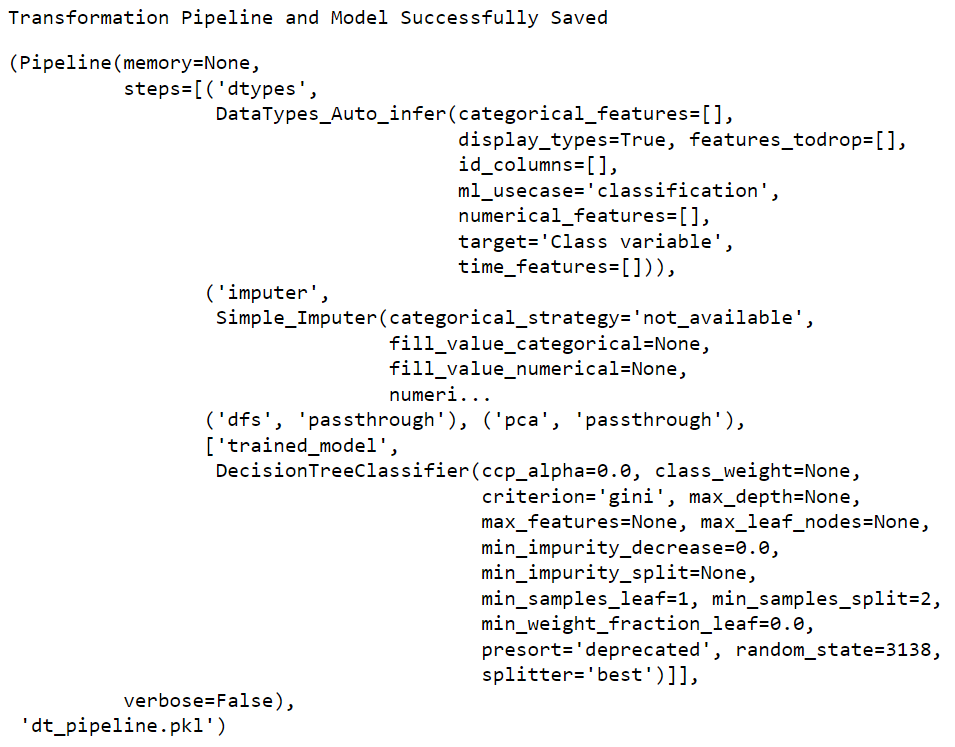
save_model
此函数将转换流水线和训练模型对象保存到当前工作目录中,以pickle文件的形式供以后使用。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
dt = create_model('dt')
# 保存流水线
save_model(dt, 'dt_pipeline')
load_model
该函数用于加载之前保存的管道模型。
# 导入数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 创建模型
dt = create_model('dt')
# 保存流水线
save_model(dt, 'dt_pipeline')
# 加载流水线
load_model('dt_pipeline')

save_config
该函数将所有全局变量保存到一个pickle文件中,以便以后在不重新运行设置函数的情况下恢复。
# 加载数据集
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 保存配置
save_config('my_config')
load_config
该函数将pickle文件中的全局变量加载到Python环境中。
# 导入`load_config`函数
from pycaret.classification import load_config
# 调用`load_config`函数,加载名为'my_config'的配置文件
load_config('my_config')
convert_model
这个函数将训练好的机器学习模型的决策函数转换成不同的编程语言,比如Python、C、Java、Go、C#等。如果你想要将模型部署到无法安装正常Python环境来支持模型推断的环境中,这个函数非常有用。
# 加载数据集
from pycaret.datasets import get_data
juice = get_data('juice')
# 初始化设置
from pycaret.classification import *
exp_name = setup(data=juice, target='Purchase')
# 训练模型
lr = create_model('lr')
# 转换模型
convert_model(lr, 'java')

create_api
此函数接受一个输入模型,并创建一个用于推理的POST API。它只创建API,不会自动运行。要运行API,您必须使用!python运行Python文件。
# 加载数据集
from pycaret.datasets import get_data
juice = get_data('juice')
# 初始化设置
from pycaret.classification import *
exp_name = setup(data=juice, target='Purchase')
# 训练模型
lr = create_model('lr')
# 创建API
create_api(lr, 'lr_api')
# 运行API
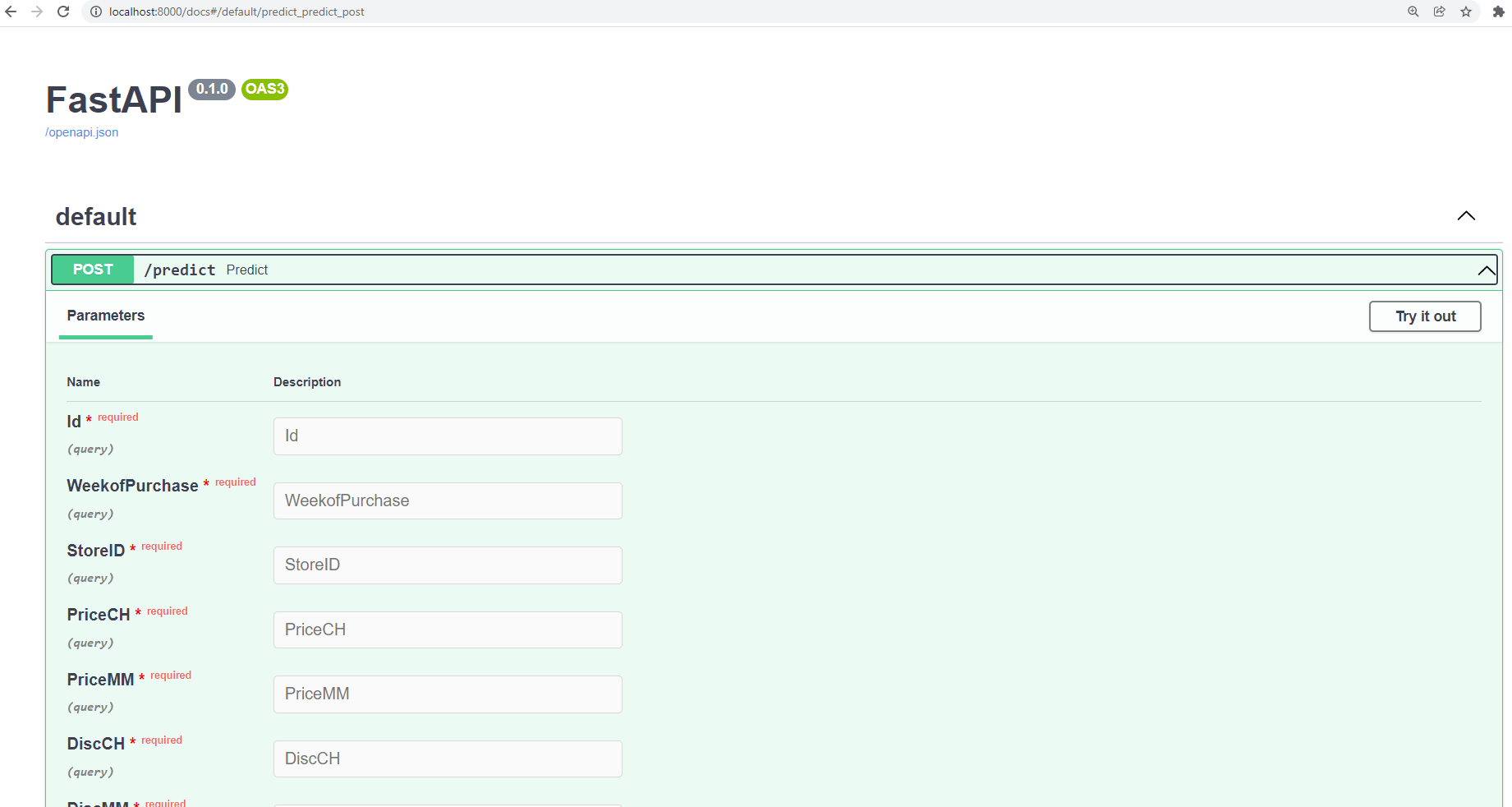
!python lr_api.py

一旦您使用!python命令初始化API,您可以在localhost:8000/docs上看到服务器。
create_docker
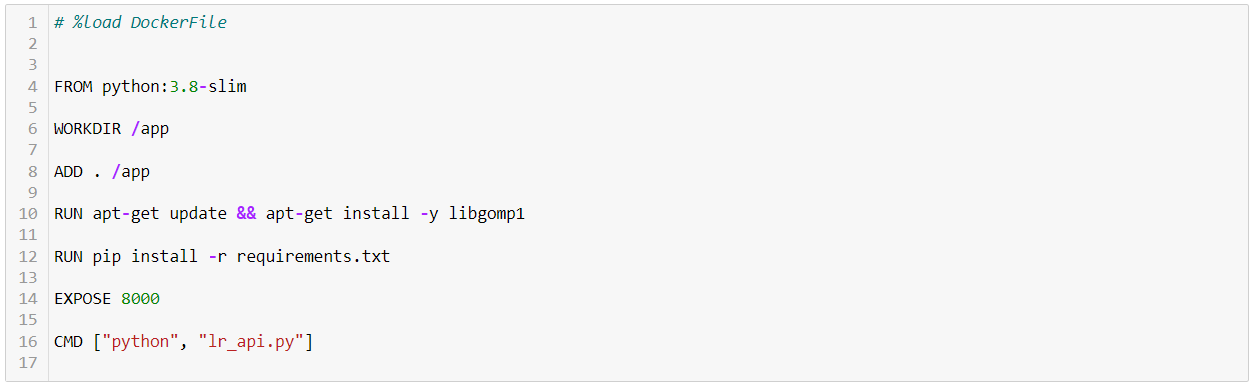
该函数用于创建一个Dockerfile和requirements.txt,用于将API端点投入生产。
# 导入数据集
from pycaret.datasets import get_data
juice = get_data('juice')
# 初始化设置
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
# 训练模型
lr = create_model('lr')
# 创建API
create_api(lr, 'lr_api')
# 创建Docker
create_docker('lr_api')

你可以看到为你创建了两个文件。

create_app
此函数创建一个基本的gradio应用程序进行推理。稍后将扩展为其他应用程序类型,如Streamlit。
# 加载数据集
from pycaret.datasets import get_data
juice = get_data('juice')
# 初始化设置
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
# 训练模型
lr = create_model('lr')
# 创建应用程序
create_app(lr)

描述:PyCaret中的其他功能
PyCaret其他
pull
返回最后打印的评分网格。在任何训练函数之后使用pull函数将评分网格存储在pandas.DataFrame中。
示例
# 加载数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target = 'Class variable')
# 比较模型
best_model = compare_models()
# 获取评分表
results = pull()

# 导入pandas库,用于处理数据
import pandas as pd
# 创建一个DataFrame对象,命名为results
results = pd.DataFrame()
# 查看results的类型
type(results)
# 输出结果为pandas.core.frame.DataFrame,表示results是一个DataFrame类型的对象
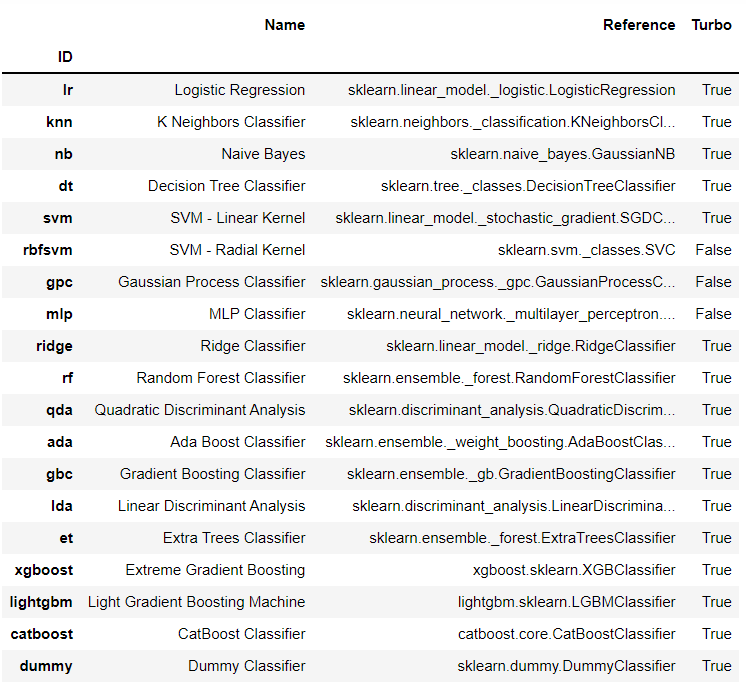
模型
返回一个包含导入模型库中所有可用模型的表格。
示例
# 加载数据集
from pycaret.datasets import get_data # 导入get_data函数,用于获取数据集
data = get_data('diabetes') # 使用get_data函数获取名为'diabetes'的数据集,并将其赋值给变量data
# 初始化设置
from pycaret.classification import * # 导入pycaret.classification模块中的所有函数和类
clf1 = setup(data, target='Class variable') # 使用setup函数对数据进行初始化设置,设置目标变量为'Class variable',并将结果赋值给变量clf1
# 检查模型库
models() # 调用models函数,显示可用的模型库
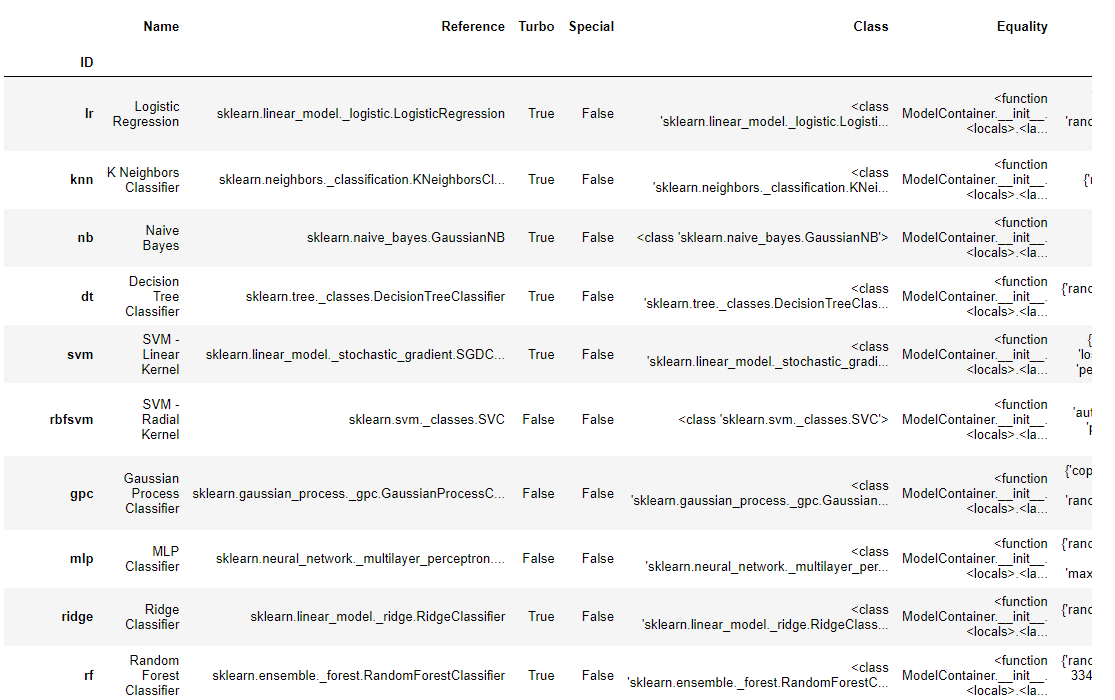
如果你想看到比这更多的信息,你可以传递 internal=True。
# 加载数据集
from pycaret.datasets import get_data # 导入get_data函数,用于获取数据集
data = get_data('diabetes') # 使用get_data函数获取名为'diabetes'的数据集,并将其赋值给变量data
# 初始化设置
from pycaret.classification import * # 导入pycaret.classification模块中的所有函数和类
clf1 = setup(data, target='Class variable') # 使用setup函数对数据进行初始化设置,设置目标变量为'Class variable',并将设置结果赋值给变量clf1
# 检查模型库
models(internal=True) # 调用models函数,查看可用的模型库,并将internal参数设置为True,以显示内部模型库的详细信息
get_config
该函数用于检索在初始化setup函数时创建的全局变量。
示例
# 导入所需的库
from pycaret.datasets import get_data # 导入获取数据集的函数
from pycaret.classification import * # 导入分类模块中的所有函数
# 加载数据集
data = get_data('diabetes') # 获取名为'diabetes'的数据集
# 初始化设置
clf1 = setup(data, target='Class variable') # 设置数据集和目标变量为'Class variable'
# 获取X_train
get_config('X_train') # 获取配置中的X_train参数值

set_config函数重置全局变量。
示例
# 导入数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target = 'Class variable', session_id = 123)
# 重置环境种子
set_config('seed', 999)
get_metrics
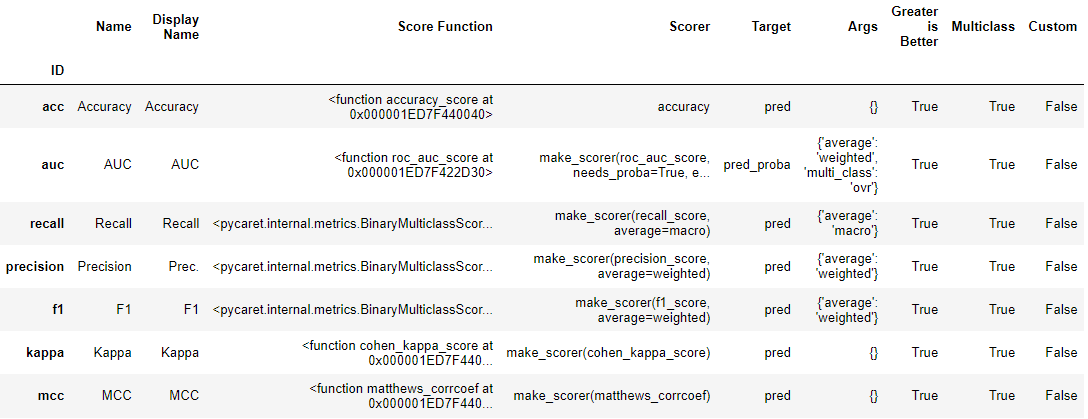
返回度量容器中所有可用度量的表格。所有这些度量都用于交叉验证。
# 导入数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target = 'Class variable', session_id = 123)
# 获取评估指标
get_metrics()

add_metric
向度量容器中添加自定义度量。
# 加载数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target='Class variable', session_id=123)
# 添加评估指标
from sklearn.metrics import log_loss
add_metric('logloss', 'Log Loss', log_loss, greater_is_better=False)

现在,如果您检查度量容器:
# 定义一个函数get_metrics,用于获取指标信息
def get_metrics():
# 从数据库中获取指标数据
metrics_data = get_data_from_database()
# 对指标数据进行处理和计算
processed_data = process_metrics_data(metrics_data)
# 将处理后的指标数据保存到文件中
save_data_to_file(processed_data)
# 打印指标数据的摘要信息
print_summary(processed_data)
# 从数据库中获取指标数据的函数
def get_data_from_database():
# 连接数据库
connection = connect_to_database()
# 查询指标数据
query = "SELECT * FROM metrics"
result = connection.execute(query)
# 将查询结果转换为列表形式
metrics_data = result.fetchall()
# 关闭数据库连接
connection.close()
# 返回指标数据
return metrics_data
# 对指标数据进行处理和计算的函数
def process_metrics_data(metrics_data):
# 对指标数据进行处理和计算的逻辑
processed_data = []
for data in metrics_data:
# 处理和计算逻辑
processed_data.append(process_data(data))
# 返回处理后的指标数据
return processed_data
# 将处理后的指标数据保存到文件中的函数
def save_data_to_file(processed_data):
# 打开文件,以追加模式写入数据
file = open("metrics_data.txt", "a")
# 将处理后的指标数据逐行写入文件
for data in processed_data:
file.write(data + "\n")
# 关闭文件
file.close()
# 打印指标数据的摘要信息的函数
def print_summary(processed_data):
# 计算指标数据的总数
total_count = len(processed_data)
# 计算指标数据的平均值
total_value = sum(processed_data)
average_value = total_value / total_count
# 打印指标数据的摘要信息
print("指标数据总数:", total_count)
print("指标数据平均值:", average_value)

remove_metric
从指标容器中移除一个指标。
# 移除指标
remove_metric('logloss') # 移除名为'logloss'的指标
没有输出。让我们再次检查度量容器。
# 定义一个函数get_metrics,用于获取指标数据
def get_metrics():
# 从数据库中获取数据
data = fetch_data_from_database()
# 对数据进行处理,得到指标数据
metrics = process_data(data)
# 打印指标数据
print(metrics)
# 从数据库中获取数据的函数
def fetch_data_from_database():
# 连接数据库
connection = connect_to_database()
# 查询数据
query = "SELECT * FROM table"
data = connection.execute(query)
# 关闭数据库连接
connection.close()
# 返回查询结果
return data
# 对数据进行处理的函数
def process_data(data):
# 对数据进行处理,得到指标数据
metrics = calculate_metrics(data)
# 返回指标数据
return metrics
# 计算指标数据的函数
def calculate_metrics(data):
# 对数据进行计算,得到指标数据
metrics = perform_calculations(data)
# 返回指标数据
return metrics
# 执行计算的函数
def perform_calculations(data):
# 执行计算,得到指标数据
metrics = []
for item in data:
metric = item * 2
metrics.append(metric)
# 返回指标数据
return metrics
# 调用获取指标数据的函数
get_metrics()
automl
该函数根据optimize参数返回当前设置中所有训练模型中的最佳模型。可以使用get_metrics函数访问评估的指标。
示例
# 加载数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target = 'Class variable')
# 比较模型
top5 = compare_models(n_select = 5)
# 调整模型
tuned_top5 = [tune_model(i) for i in top5]
# 集成模型
bagged_top5 = [ensemble_model(i) for i in tuned_top5]
# 混合模型
blender = blend_models(estimator_list = top5)
# 堆叠模型
stacker = stack_models(estimator_list = top5)
# 自动机器学习
best = automl(optimize = 'Recall')
print(best)

get_logs
返回一个实验日志表。只有在初始化setup函数时设置log_experiment = True时才有效。
示例
# 加载数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target = 'Class variable', log_experiment = True, experiment_name = 'diabetes1')
# 比较模型
top5 = compare_models()
# 查看机器学习日志
get_logs()

get_system_logs
从当前活动目录中读取并打印logs.log文件。
示例
# 导入数据集
from pycaret.datasets import get_data
data = get_data('diabetes')
# 初始化设置
from pycaret.classification import *
clf1 = setup(data, target = 'Class variable', session_id = 123)
# 检查系统日志
from pycaret.utils import get_system_logs
get_system_logs()

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!