机器学习---随机森林
1、使用决策树来做回归或者预测值
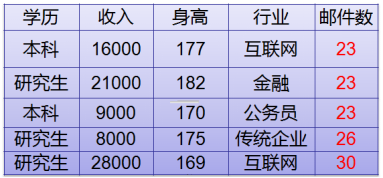
如上图,使用学历、收入、身高、行业使用决策树来预测收到的邮件数。可以将邮件数分为几类(也可以按照其他列,将邮件数分类),比如邮件数<=23封属于A类,邮件数大于23<邮件数<=30为B类,A类中取邮件的平均数,B类中也取邮件的平均数。就是可以将某些列作为分类条件划分邮件数的类别,再取邮件数的平均数,这样可以使用决策树来预测大概值的范围。
2、决策树预剪枝和后剪枝
决策树对训练集有很好的分类能力,但是对于未知的测试集未必有好的分类能力,导致模型的泛化能力弱,可能发生过拟合问题,为了防止过拟合问题的出现,可以对决策树进行剪枝。剪枝分为预剪枝和后剪枝。
预剪枝:就是在构建决策树的时候提前停止。比如指定树的深度最大为3,那么训练出来决策树的高度就是3,预剪枝主要是建立某些规则限制决策树的生长,降低了过拟合的风险,降低了建树的时间,但是有可能带来欠拟合问题。
后剪枝:后剪枝是一种全局的优化方法,在决策树构建好之后,然后才开始进行剪枝。后剪枝的过程就是删除一些子树,这个叶子节点的标识类别通过大多数原则来确定,即属于这个叶子节点下大多数样本所属的类别就是该叶子节点的标识。选择减掉哪些子树时,可以计算没有减掉子树之前的误差和减掉子树之后的误差,如果相差不大,可以将子树减掉。一般使用后剪枝得到的结果比较好。
剪枝可以降低过拟合问题,如下图:

当来一条数据年龄为中年,信用高,孩子个数是4个时,没有办法分类。可以通过剪枝,降低过拟合问题。

3、随机森林
随机森林是由多个决策树组成。是用随机的方式建立一个森林,里面由很多决策树组成。随机森林中每一棵决策树之间都是没有关联的。得到随机森林之后,对于一个样本输入时,森林中的每一棵决策树都进行判断,看看这个样本属于哪一类,最终哪一类得到的结果最多,该输入的预测值就是哪一类。

随机森林中的决策树生成过程是对样本数据进行行采样和列采样,可以指定随机森林中的树的个数和属性个数,这样当训练集很大的时候,随机选取数据集的一部分,生成一棵树,重复上面过程,可以生成一堆形态各异的树,这些决策树构成随机森林。
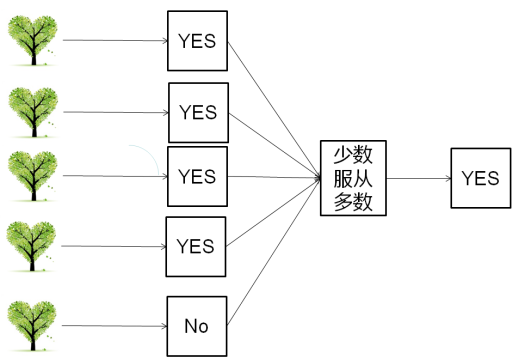
随机森林中的每个决策树可以分布式的训练,解决了单棵决策树在数据量大的情况下预算量大的问题。当训练样本中出现异常数据时,决策树的抗干扰能力差,对于随机森林来说也解决了模型的抗干扰能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!