视频中自监督学习:「我的世界」下指令理解与跟随
本文介绍了北京大学人工智能研究院梁一韬助理教授所带领的 CraftJarvis 团队在「我的世界」环境下探索通用智能体设计的新进展,题为“GROOT: Learning to Follow Instructions by Watching Gameplay Videos”。
 ?
?
该研究的核心目标是探索能否摆脱文本数据的标注以及与环境的在线交互,而是仅通过观看游戏视频的方式来教会智能体理解世界、遵循指令,进而在开放世界下解决无穷的任务。考虑到视频数据广泛分布于互联网,而高质量的“文本-视频”数据对则难以获得,因此团队创新地提出使用一段“参考视频”作为指令的描述形式,并设计一套简洁的架构和自监督训练方法来联合学习指令空间和指令跟随策略。通过在本文提出的 Minecraft SkillForge 基准上进行细致的评测,该方法超过了目前现有的基线方法,并拉近了与人类玩家之间的差距。这对于复杂环境下通用智能体的设计有重要意义。
本文的第一作者是由梁一韬助理教授指导的博士生蔡少斐,通讯作者为梁一韬。论文的作者还包括北京大学的张博为、王子豪,UCLA 的刘安吉以及北京通用人工智能研究院的马晓健研究员。
 ?
?
?
论文题目: GROOT: Learning to Follow Instructions by Watching Gameplay Videos
论文链接:?https://arxiv.org/abs/2310.08235?
项目网站:GROOT: Learning to Follow Instructions by Watching Gameplay Videos
01. 研究背景
在开放世界下开发类人级别的具身智能体以解决开放式任务一直是人工智能领域长期以来追求的目标。随着 ChatGPT 的流行,近年来涌现了一批利用大语言模型(LLM)的规划推理能力来解决「我的世界」中复杂长期任务的尝试,如 DEPS、Voyager、GITM 等工作。然而,与理想的通用智能体相比,这些基于 LLM 的工作主要强调发掘语言模型的潜力而忽略了提升底层控制器(low-level controller)的重要性。事实上,底层控制器负责将 LLM 规划出来的 plan 映射到具体动作空间(键盘与鼠标操作),并与环境直接进行交互。因此,其掌握的技能库中技能的数量和质量决定了智能体能力上限。该团队的此项研究旨在构建具备指令理解能力的基础决策大模型。通过将技能库从有限推广至无限,实现了由封闭式指令向开放式指令理解的迈进。
02. 研究动机
2.1 自监督预训练范式促进大规模任务学习
自监督预训练范式已经相继在自然语言处理(NLP)和计算机视觉(CV)领域展现出了极强的泛化能力,大有统一深度学习的趋势。然而,在强化学习(RL)和决策控制领域的相关研究则相对滞后。本文作者认为预训练的学习范式对于构建决策大模型来说至关重要。考虑到任务的多样性,为每个任务单独定义一套奖励函数并让智能体在与环境交互的方式中学习是非常昂贵且不安全的。因此,利用网上的海量视频数据对智能体进行自监督预训练使其大规模“领悟”技能的道路则非常有前景。
2.2 “视频”做指令表达能力强,数据易收集
为了使预训练出来智能体能够理解人类的指令并执行相应的任务,必须对指令空间的形式进行定义。目前主流的指令形式主要包括「任务指示器」、「未来的结果」(又分为「未来的状态」、「预期的累计奖励」等)、「自然语言」。本文作者认为,尽管在这些指令形式下智能体容易使用“后见经验重放”之类的技巧学习,然而指令的表达能力却十分有限。以「未来的状态」举例,一张房屋的照片并不能告诉智能体房子是如何被建造出来的,因为其缺乏细致的过程性描述。此外,这种指令也存在很强的歧义性,例如一张站在房屋前的图片并不能让智能体区分是要构建这样一座房屋还是找到这样一座房屋。尽管对于过程描述足够细致的自然语言指令可以规避上述所说的问题,然而互联网上并不存在如此多高质量的“视频-文本”数据对可供训练。
观察到主流指令形式的局限性之后,研究团队旨在找到指令的表达能力与智能体学习的成本之间的平衡。作者发现视频形式的指令则可以同时兼顾这两个要求。一方面,一段“参考”视频可以描述完成任务所需的所有细节信息,具备极强的表达能力;另一方面,视频模态数据大规模分布在互联网上,因此训练数据十分易于收集。
03. 研究方法
 ?
?
 ?
?
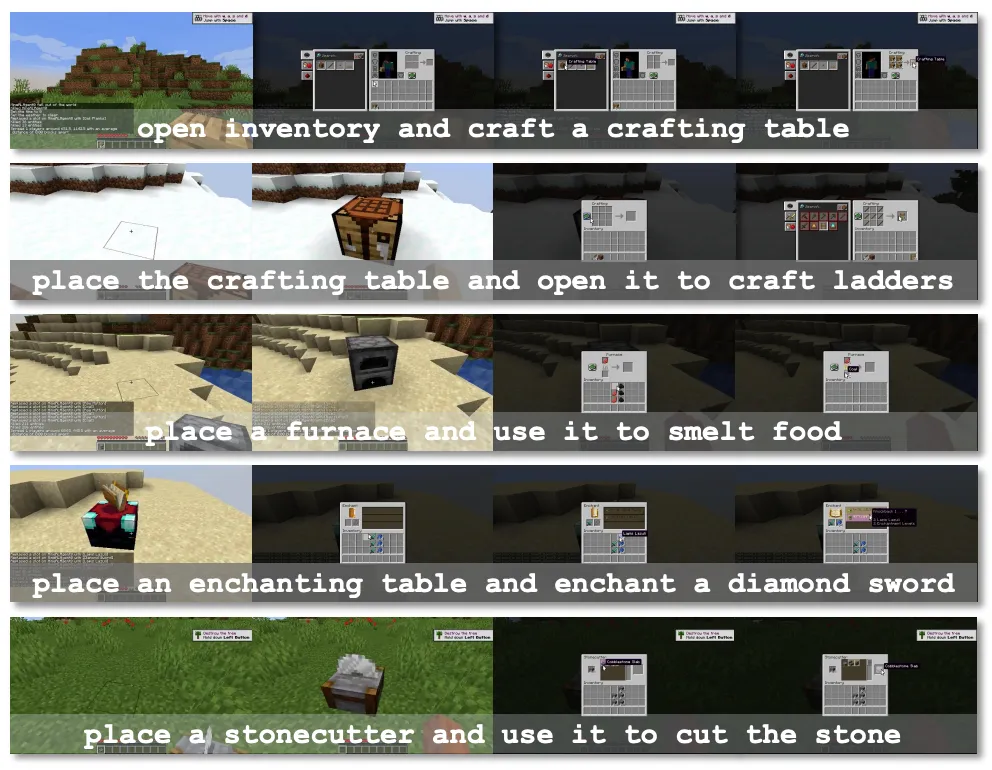
遵循上述设计原则,研究团队采用了流行的编码器-解码器架构来实现整个模型,并命名为 GROOT。具体来说,研究团队采用了非因果 Transformer 来实现视频编码器,用于提取视频中蕴含的语义信息;采用了一个因果 Transformer 作为解码器(即策略)用于遵照指令的语义信息在环境中做出相应的行为。在训练过程中,输入到编码器的视频和送到解码器中状态序列是完全一致的,模型在 KL 散度的约束下使用行为克隆进行自我模仿。在推理过程中,将输入到编码器中的视频换成任意一段描述某个任务执行过程的参考视频,智能体便可与环境进行交互从而完成相应的任务。
04. 评测基准
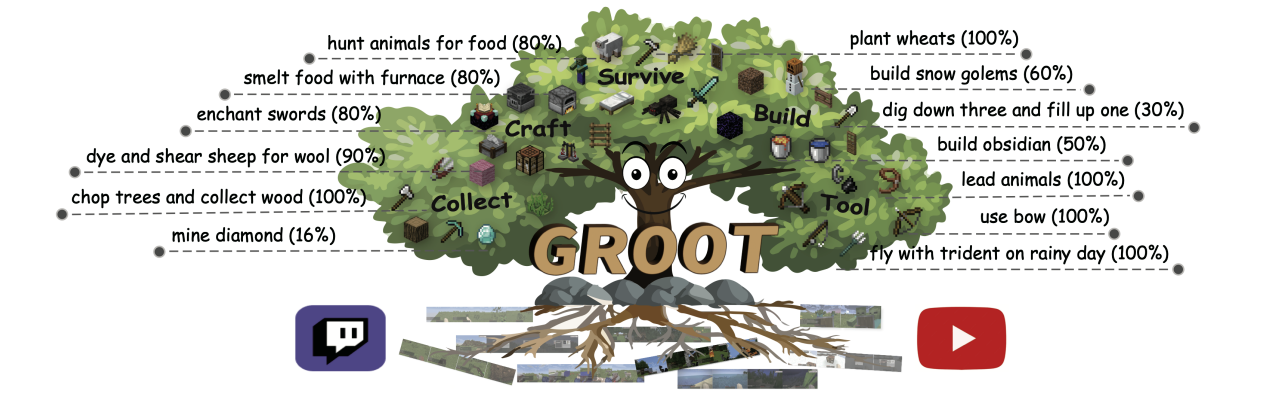
「我的世界」 环境具备极高的自由度,为了全面评估 GROOT 在解决复杂多样化任务上的能力。研究团队提出了一组新的评测基准「Minecraft SkillForge」。该基准包含了 「我的世界」 环境中的 30 个基础任务,涵盖「资源收集」、「生存维持」、「物品制作」、「自由探索」、「工具使用」和「结构建造」6 大类别。以下展示了「结构建造」、「对敌战斗」和「资源收集」三大类任务。
 ?
?
 ?
?
 ?
?
 ?
?
?
 ?
?
 ?
?
「挖三填一」是 「我的世界」 中安全度过黑夜的有效方法,它描述了构建一个简易庇护所所需的步骤:垂直向下挖掘 3 个泥土,抬头将 1 个泥土放置在上方做成封闭空间。
「蜘蛛进行搏斗」指玩家需要在保证生存的情况下使用钻石剑击杀尽可能多的蜘蛛。
「收集水草」任务指的是玩家需要跳进海中,潜泳游到海底破坏水草方块。
该评测基准既包含一些常见的任务(如收集木头、羊毛、草),也包含一些十分罕见的任务(如挖三填一、建造雪傀儡、切割石块)。因此该基准可以充分反应模型的泛化能力,对未来 「我的世界」 下多任务智能体的研究也有较大的意义。
05. 实验结果
5.1 天梯系统与人工评测
由于任务的多样性,并不存在一种统一的指标来评估所有任务。因此,研究团队使用 Elo Rating 系统结合人工比较的方式评估了 GROOT 与现有基线在「Minecraft SkillForge」基准上的性能差异。如图所示,可以发现 GROOT (1829 分)显著超越了目前所有的基线方法(1679 分),进一步缩小了与人类玩家(2034 分)的差异。如中间图所示,在一些不常见的任务(如「架构建造」和「工具使用」)上,相比之前的最优方法 STEVE-1,GROOT 获得了很高的对战胜率(>83%)。
 ?
?
5.2 程序性任务评测结果
右图展示了 GROOT 和基线方法在 9 种代表性任务上的成功率对比。GROOT 除了在所有任务上都取得领先优势之外,也是唯一一个在「装备附魔」、「挖三填一」、「建造雪傀儡」任务上取得非零成功率的智能体。
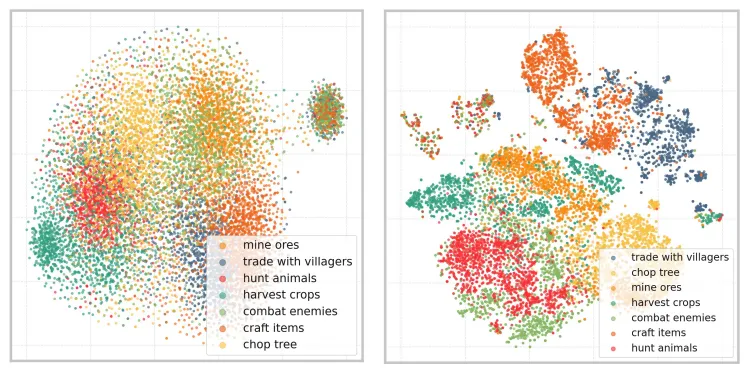
5.3 指令空间 t-SNE 可视化结果
 ?
?
为了直观了解指令空间的学习情况,研究团队额外展示了训练前后指令空间在 7 种类别任务视频上的编码效果。可以发现,经过自监督训练之后,指令空间的表达能力得到了极大的提升。在没有任何语义标签辅助下,仅通过自监督预训练就可以较好地提取视频中存在的语义信息。
5.4 组合多个指令解决复杂长期任务
 ?
?
「我的世界」 中存在很多任务需要串行执行多个指令才可以解决,其中最经典的就是「钻石挑战」。钻石稀疏地分布于 「我的世界」 地下 7-12 层的位置。为了方便展现 GROOT 在解决「钻石挑战」上的表现,作者通过给智能体一把铁镐简化了钻石挑战任务,即省略了制作铁镐的过程。现在智能体只需向下挖掘到指定层数,再水平挖掘(可能需要很久)挖到💎即可。作者初始化给智能体的指令是一段向下挖掘的视频,并实时检测智能体高度,当高度到达 12 时,将给智能体的指令切换为一段描述水平挖掘的视频。研究团队发现 GROOT 可以以 16% 的较高成功率挖到💎。而相较而言,以「未来的结果」作为指令形式的STEVE-1 则无法获得钻石。作者推测,这可能是由于「未来的结果」无法表达水平挖掘这一概念,因此容易掉到基岩层并卡住,从而导致任务失败。
06. 结论与展望
本文提出了一种通过观看游戏视频来学习遵循指令的预训练范式。作者认为视频指令是一个很好的目标空间形式,它不仅表达了开放式任务,还可以通过自我监督进行训练。基于此,研究团队在 「我的世界」 中构建了一个名为 GROOT 的编码器-解码器 Transformer 架构智能体。无需依赖任何标注数据,GROOT 表现出非凡的指令跟随能力并霸榜 Minecraft SkillForge 基准。此外,作者还展示了它在「钻石挑战」任务中作为下游控制器的潜力。研究团队相信这种架构和训练范式具有很强的应用前景,并希望将其应用于更复杂的开放世界环境。
07. 相关工作
CraftJarvis 团队长期关注于在开放世界下构建自主智能体。除了构建指令跟随智能体 GROOT 完成开放世界下的短期任务,团队还使用预训练的大语言模型作为 Planner 来增强智能体完成长期任务的能力。
7.1 DEPS
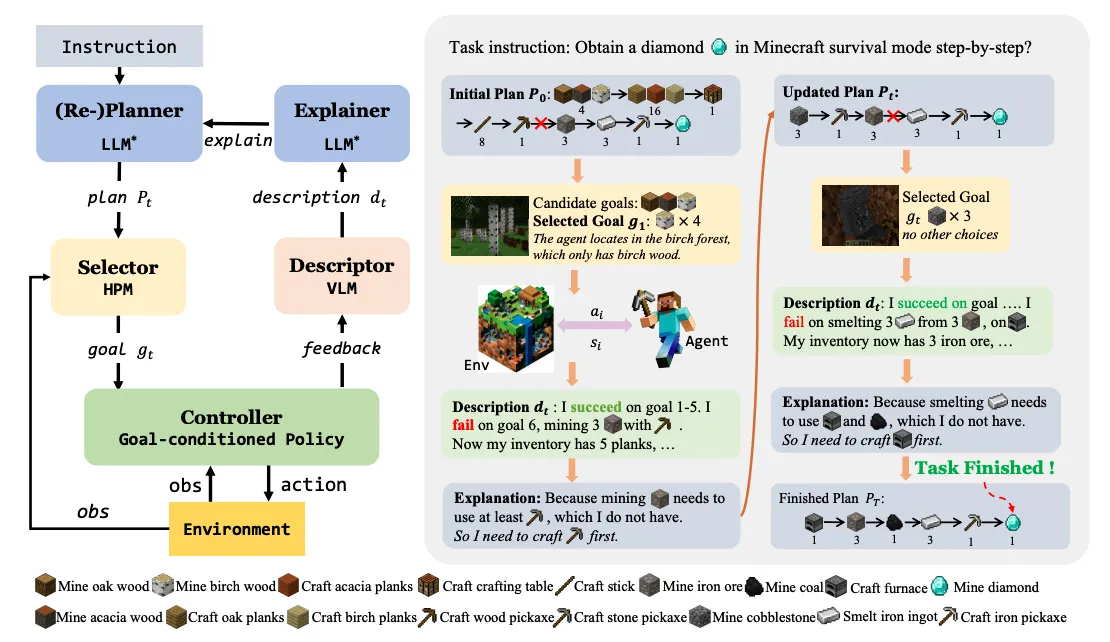
DEPS 是第一个使用大语言模型在开放世界 「我的世界」 上进行任务规划和任务执行的智能体。DEPS 基于大语言模型设计了一个包括“描述、解释、规划并选择”的流程,通过整合计划执行过程的描述并在规划阶段遇到失败时大语言模型提供的自我解释反馈,从而在初步 LLM 生成的计划失败时更好的修正错误并重新规划。此外,它还包括一个目标选择器,这是一个可学习的模块,根据预估完成步骤来对候选子目标进行排序,从而提高语言计划在开放世界下的可执行性。DEPS 可以在「我的世界」环境中零样本的实现长序列任务,例如在生存模式下从头开始获得钻石。
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents?
arXiv:?https://arxiv.org/pdf/2302.01560.pdf?
该文章被收录于NeurIPS 2023,并在ICML 2023的TEACH Workshop上被评选为最佳论文。
 ?
?
7.2 JARVIS-1
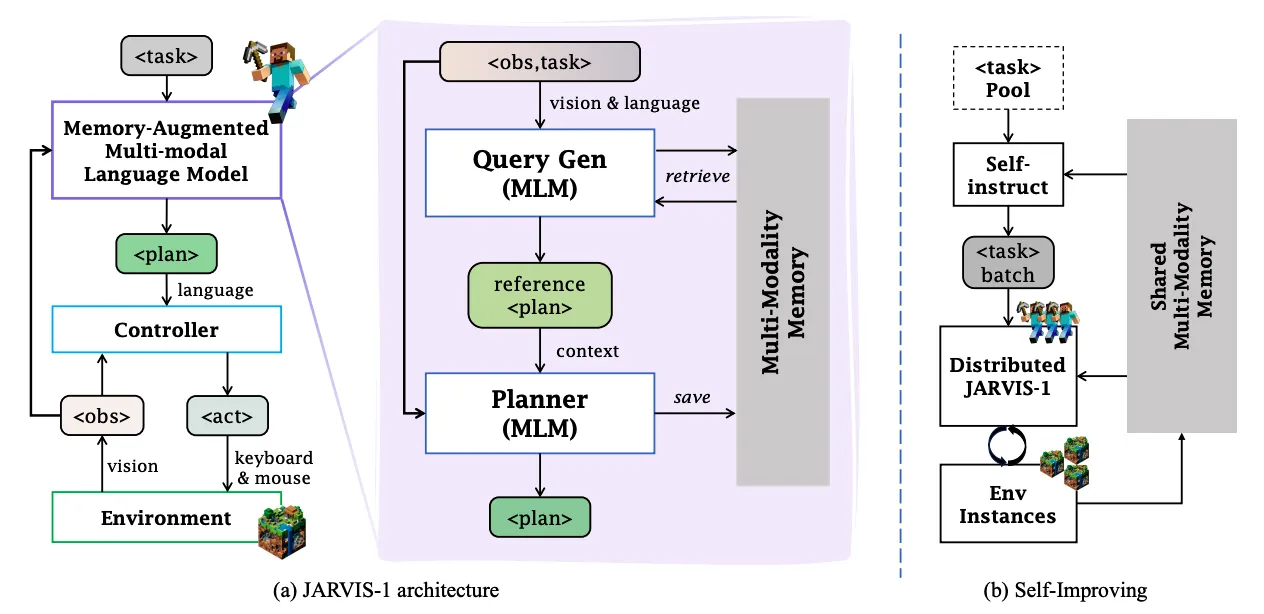
JARVIS-1?是一个开放世界智能体,基于预训练的多模态语言模型,能够感知多模态输入(视觉观察和人类指令),生成复杂计划,并在「我的世界」中执行具身控制。JARVIS-1?还配备了一个多模态记忆,它利用预训练知识和实际游戏生存经验来提高规划能力。JARVIS-1?是现有「我的世界」中最通用的智能体,能够使用与人类一致的控制和观察空间完成200多个不同任务,从短期任务(例如“砍树”)到长期任务(例如“获得一把钻石镐”)。在经典的长期任务“获得钻石镐”中,JARVIS-1?的成功率为当前最先进智能体的5倍,并能成功完成更长时间跨度和更具挑战性的任务。
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models?
arXiv:?https://arxiv.org/pdf/2311.05997.pdf?Project:?JARVIS-1: Open-world Multi-task Agents with Memory-Augmented Multimodal Language Models
 ?
?
08. 本文作者
蔡少斐,北京大学人工智能研究院博士生,CraftJarvis 研究团队成员之一,导师是梁一韬教授。他的研究兴趣主要包括决策大模型、语言大模型以及游戏智能。他已在 CVPR 、NeurIPS 等人工智能顶会上发表过多篇论文,并专注于开放世界下智能体决策控制研究。担任 ICML、NeurIPS 、 ICLR 等国际学术会议审稿人。
王子豪,北京大学人工智能研究院博士生,CraftJarvis 研究团队成员之一,导师为梁一韬教授。曾获国家奖学金、北京市优秀毕业生等荣誉。主要研究方向为开放世界下多任务智能体的构建,尤其关心基于基础模型的智能体的泛化能力。近年来在CVPR、NeurIPS等人工智能顶会上发表多篇论文,曾获ICML研讨会最佳论文奖。担任ICML、NeurIPS、ICLR等多个国际机器学习会议审稿人。
个人主页: https://zhwang4ai.github.io
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!