Kotlin 笔记 -- Kotlin 语言特性的理解(二)
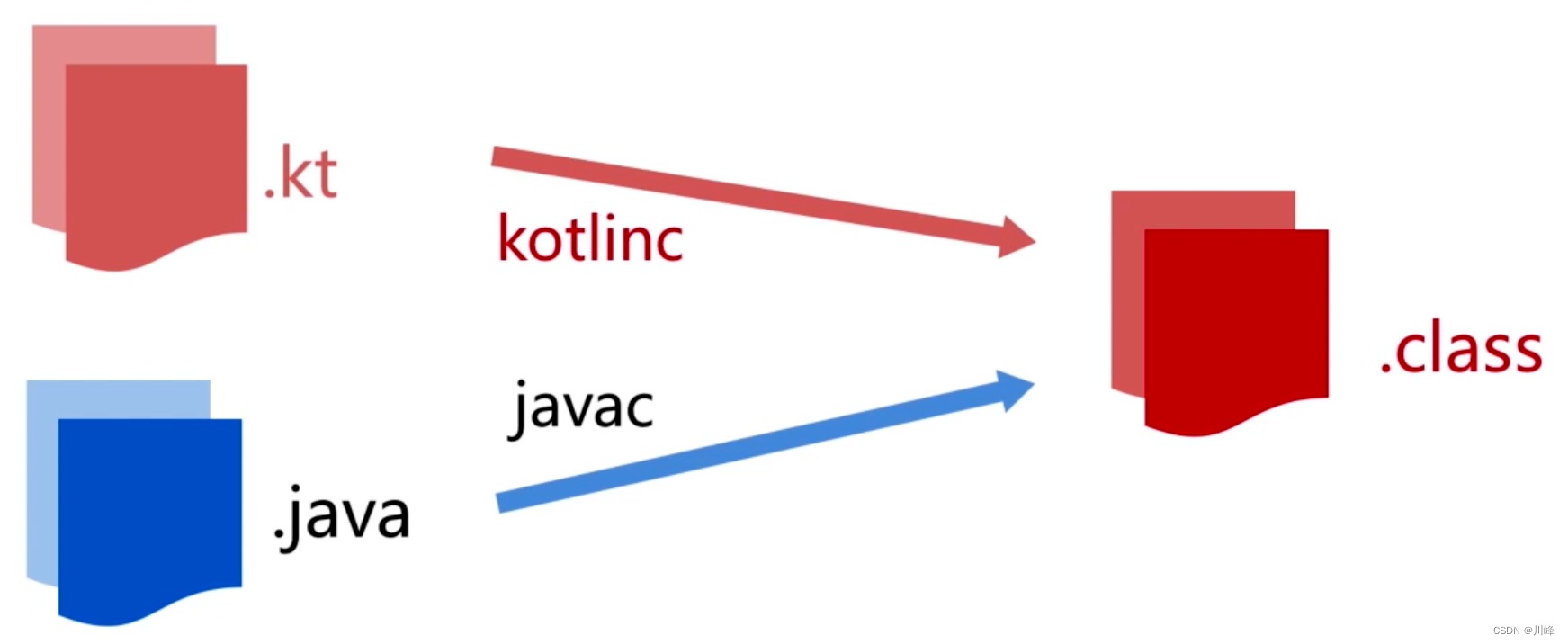
都是编译成字节码,为什么 Kotlin 能支持 Java 中没有的特性?
kotlin 有哪些 Java 中没有的特性:
- 类型推断、可变性、可空性
- 自动拆装箱、泛型数组
- 高阶函数、DSL
- 顶层函数、扩展函数、内联函数
- 伴生对象、数据类、密封类、单例类
- 接口代理、internal、泛型具体化
- … …
语言的编译过程
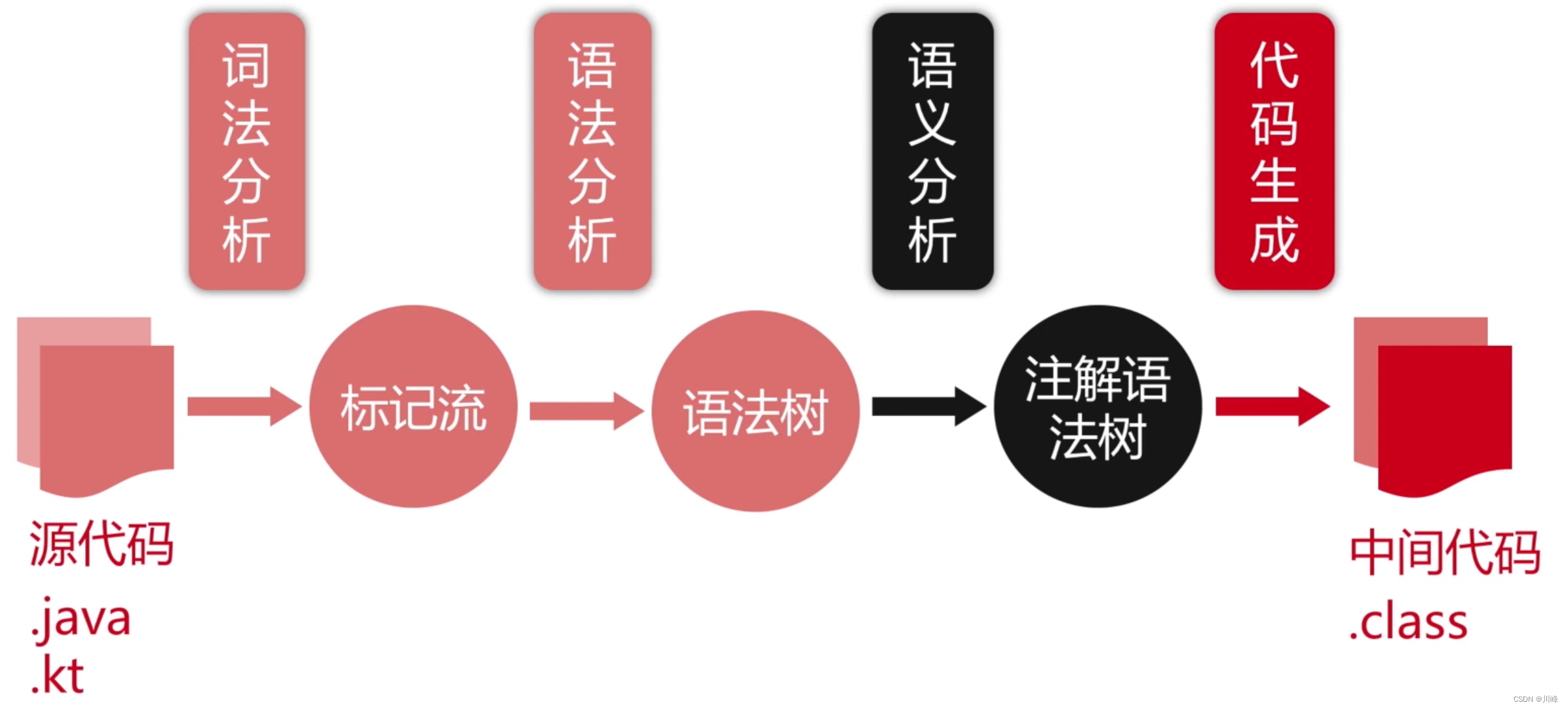
词法分析:
语法分析:
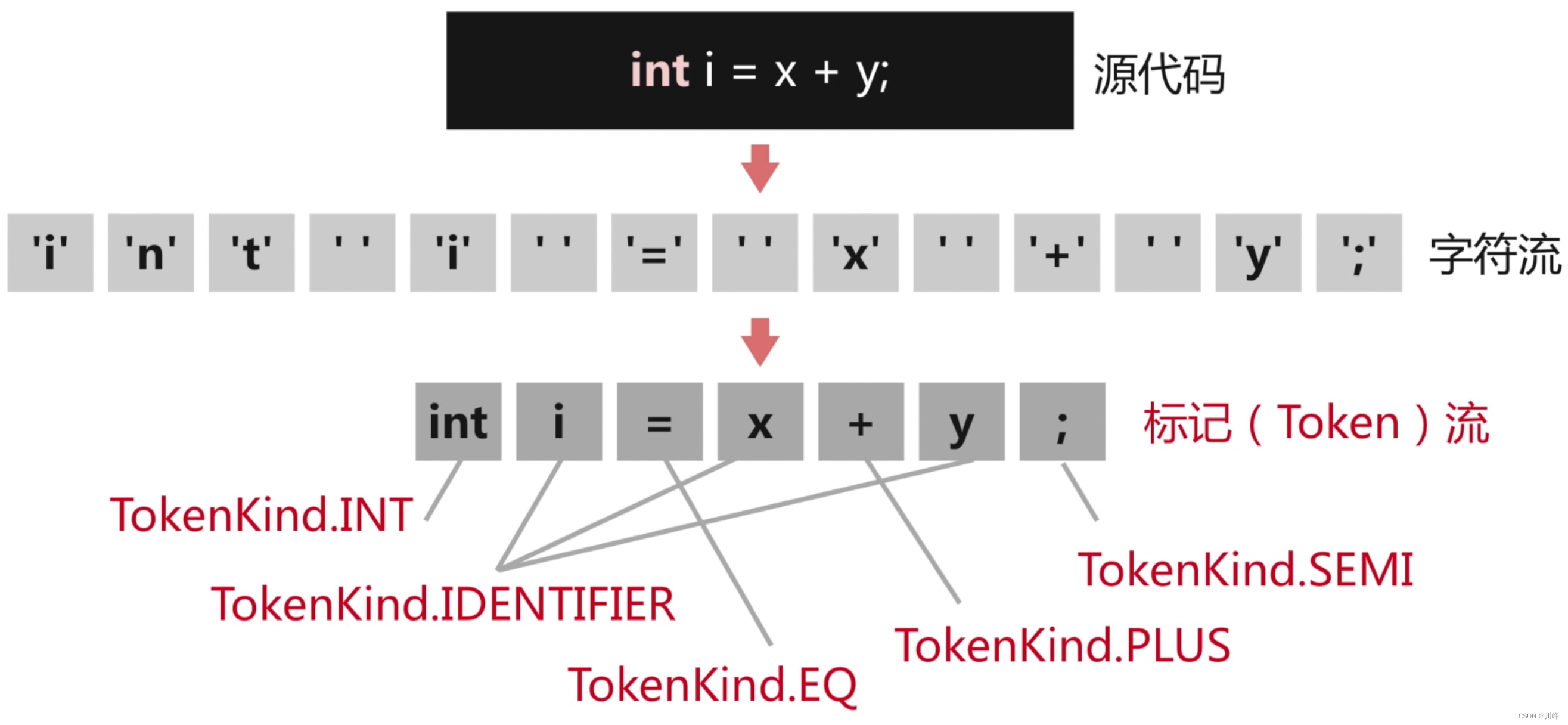
- 词法分析:把源码的字符流,转化成标记(Token)序列,标记是语言的最小语义单位,包括关键字、标识符、运算符、常数等;
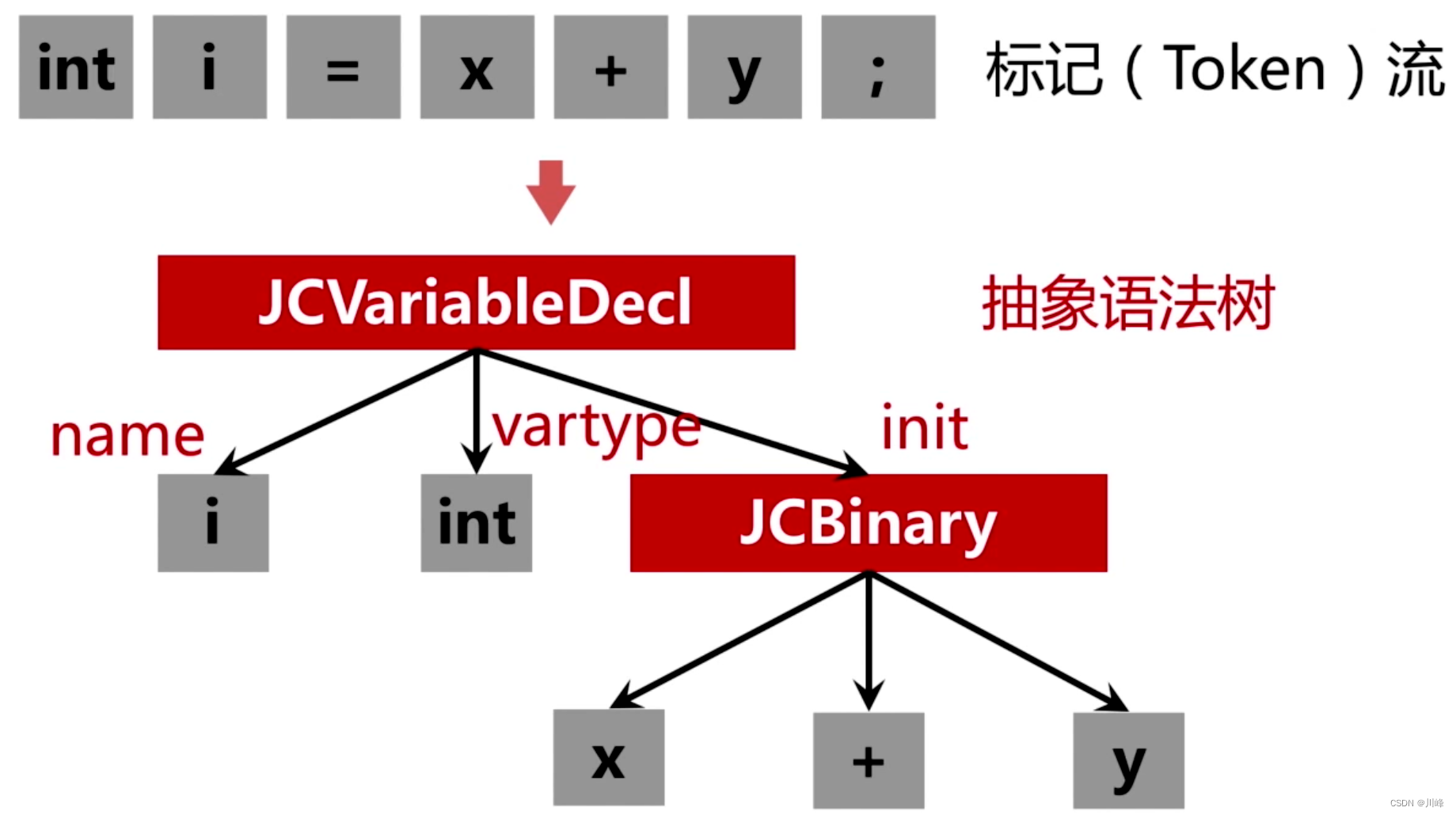
- 语法分析:把标记序列,组合成各类语法短句,判断标记序列在语法结构上,是否正确,输出树形结构的抽象语法树;
- 语义分析:结合上下文,检查每一个语法短句,语义是否正确,是否符合语言规范。(数据类型匹配、重复定义检测、访问合法性、静态分派、受检异常、语句可达性、展开语法糖…)
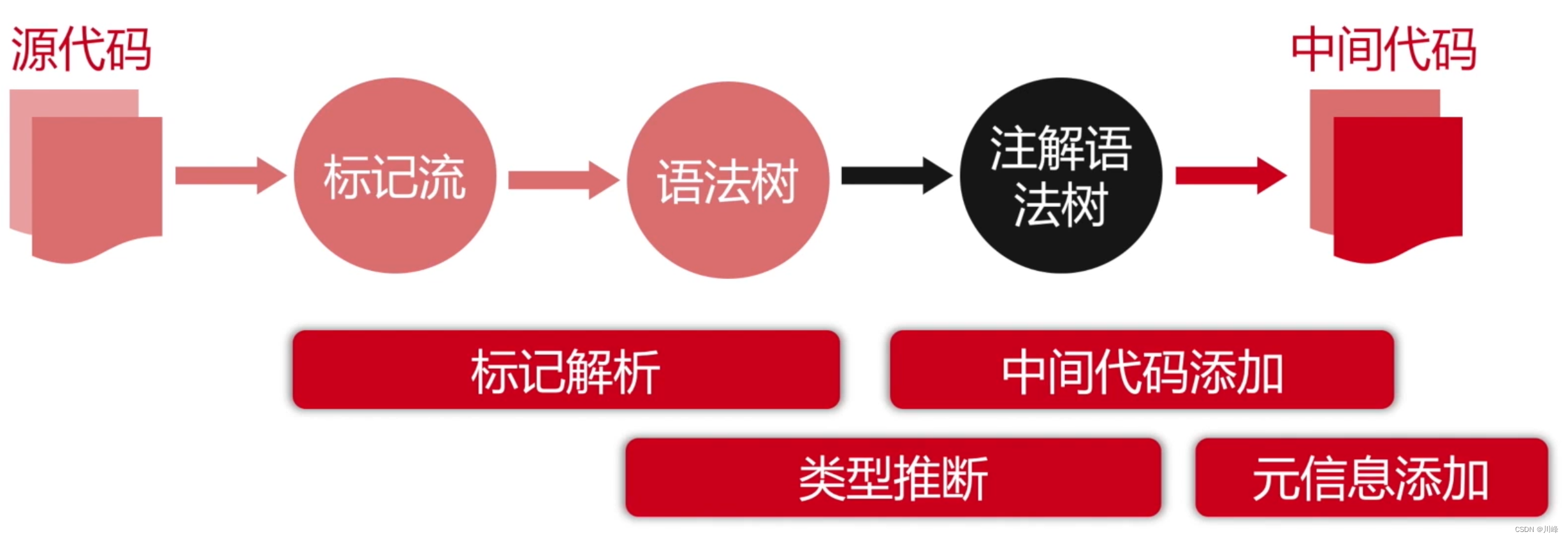
Kotlin 的类型推断
- 类型推断并不是不确定数据类型,相反是从上下文推断出一个明确的数据类型;
- 类型推断的意义在于,去掉代码中的冗余信息,提升研发效率;
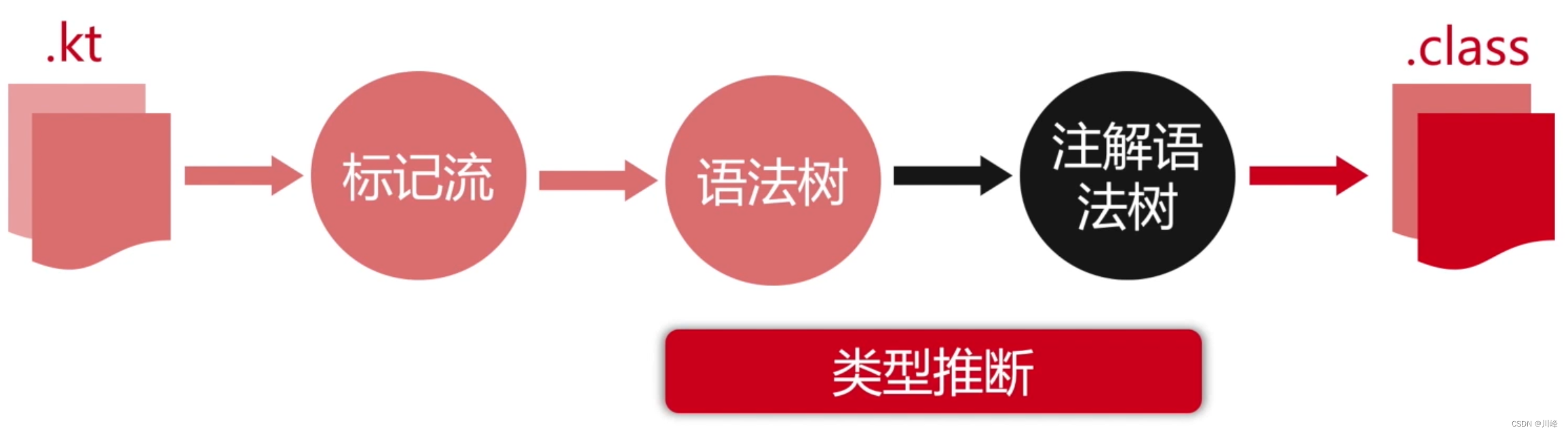
- 类型推断主要发生在语法分析和语义分析阶段,这个功能主要是通过编译器来实现的。
Kotlin 的拆装箱
// Java 的拆装箱
Integer x = 1; // 自动装箱
int y = x; // 自动拆箱
// kotlin 的拆装箱
var i : Int = 0 // 对应 Java 中的 int
var i : Int? = null // 对应 Java 中的 Integer
i = 0 // 对应 Java 中的 Integer.valueOf()
// kotlin 的拆装箱
val list = mutableListOf<Int>()
list.add(0) // Integer.valueOf()
Kotlin的装箱类型数组:
val ids : Array<Int> = arrayOf()
- 支持泛型类型,所以默认不具备协变性,字节码实现对应
anewarray,相当于 Java 的Integer[]。
val ids : IntArray = IntArrayOf()
- 字节码实现对应
newarray,相当于 Java 的int[],性能较好。
Kotlin中的隐式装箱类总结:
- 可空的基本数据类型,会被编译成装箱类;
- 泛型中基本数据类型,在使用时,会自动拆装箱;
- 泛型数组,使用的是装箱类型。
由于自动拆装箱有性能损耗,出于性能考虑,在Kotlin中,应当尽量避免使用可空的基本数据类型,以及泛型数组; 尽量使用非可空类型。
Kotlin 中的高阶函数
高阶函数:在数学中,对应算子的概念,也就是对函数本身进行操作;在计算机语言中,高阶函数作为语言的一等公民,函数本身可以作为函数的输入,或是返回;高阶函数是函数式编程的基础条件。
高阶函数示例代码:
fun login(user: User, onFailed: (Int) -> Unit) : Boolean {
val stateCode = checkUser(user)
if (stateCode == SUCCESS) {
return true
} else{
onFailed(stateCode)
return false
}
}
val success = login(user) { code ->
// TODO 展示错误状态
}
当 lambda 当作函数参数进行传递时,它本质上是一个函数对象,最终要将上述代码翻译成 Java 的字节码,而在 Java 中是没有函数对象这种东西的,那么怎么办呢?所以为了应对这种情况,Kotlin 中定义了一系列的 “类函数” 的接口:Function0、Function1、Function2、…、Function22 总共有22个,定义如下:
public interface Function<out R>
public interface Function0<out R> : Function<R> {
public operator fun invoke():
}
public interface Function1<in P1, out R> : Function<R> {
public operator fun invoke(p1: P1):R
}
public interface Function2<in P1, in P2, out R> : Function<R> {
public operator fun invoke(p1: P1, p2: P2): R
}
......
public interface Function22<in P1, in P2, in P3, ......, in P22, out R> : Function<R> {
public operator fun invoke(p1: P1, p2: P2, p3: P3,....., p22: P22): R
}
所以对于前面的高阶函数示例代码,本质上实际长这样:
fun login(user: User, onFailed: Function1<Int, Unit>) : Boolean {
val stateCode = checkUser(user)
if (stateCode == SUCCESS) {
return true
} else{
onFailed.invoke(stateCode)
return false
}
}
val success = login(user, object: Function1<Int, Unit> {
override fun invoke(p1: Int) {
// TODO 展示错误状态
}
})
即便传入的是普通的函数引用,最终也会以object匿名内部类对象的形式进行传递。例如:
fun showFailedState(state: Int) {
// TODO 展示错误状态
}
val success = login(user, ::showFailedState)
上面代码实际长下面这样:
fun showFailedState(state: Int) {
// TODO 展示错误状态
}
val success = login(user, object: Function1<Int, Unit> {
override fun invoke(p1: Int) {
showFailedState(p1)
}
})
高阶函数的真实面目:
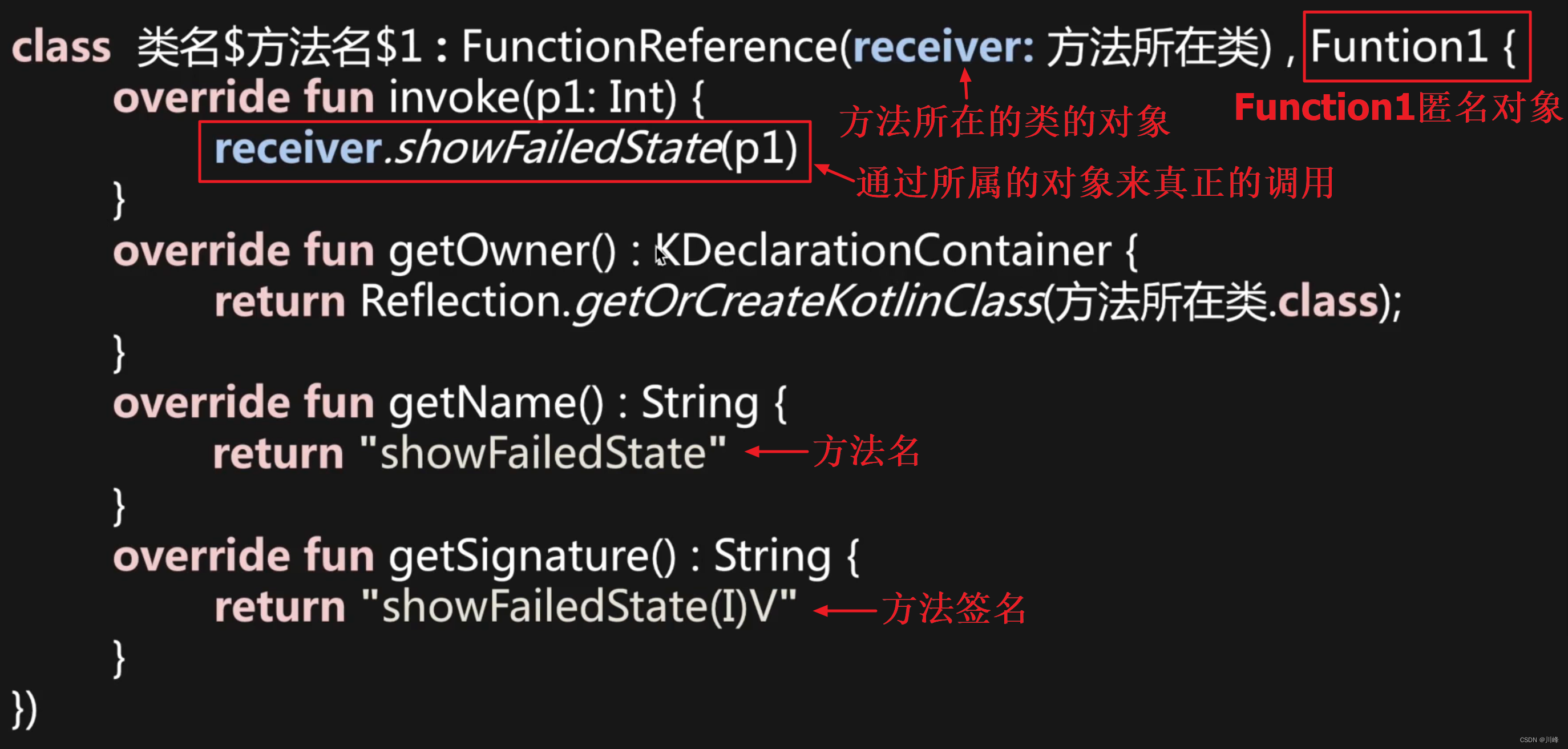
所以 Kotlin 中的高阶函数本质上是通过各种函数类型的对象进行桥接:
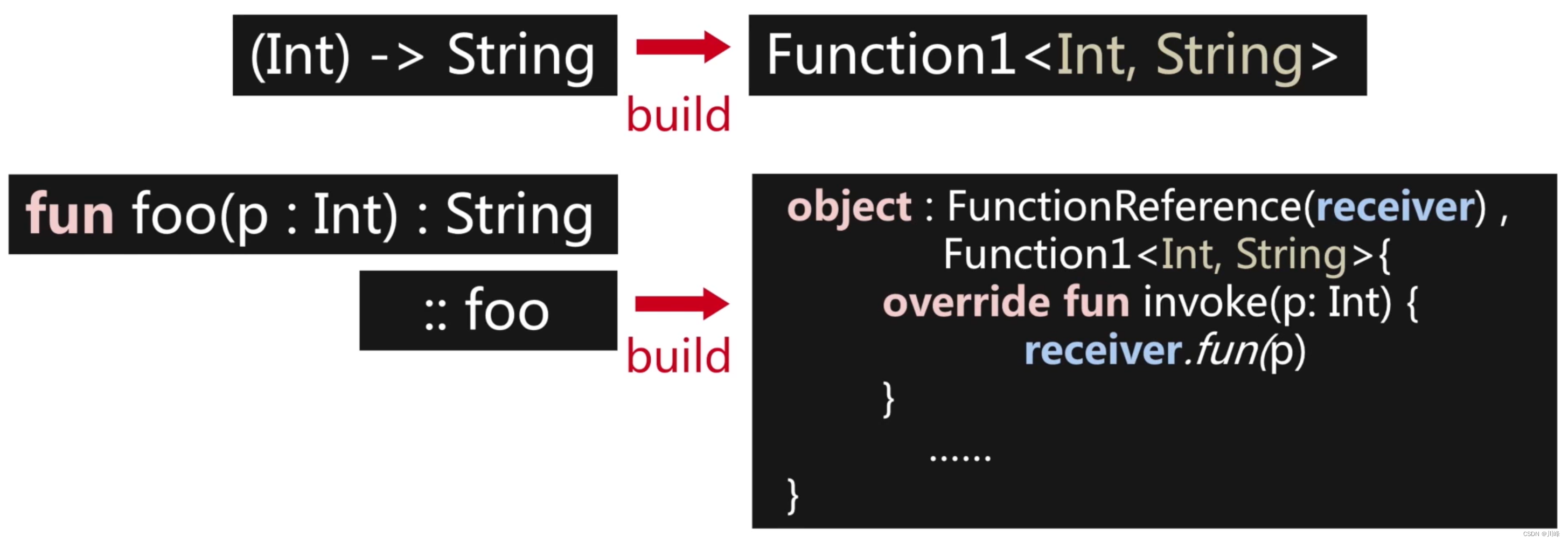
现在我们知道 Kotlin 中的高阶函数主要是通过中间代码添加手段来生成的:
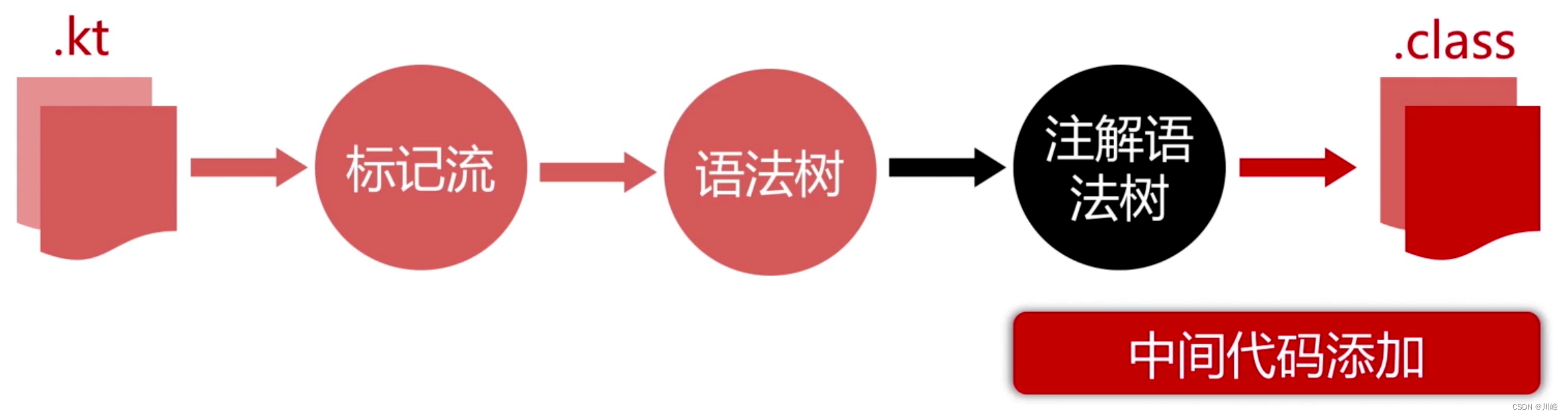
- 从性能上讲,高阶函数要创建实例,所以开销会增大。
- Kotlin 的匿名内部类,在和外部类有互动的时候,也会持有外部类的引用,存在一定的、潜在的内存泄漏的风险。
Kotlin 中的顶层函数
- Java 中的函数,必须在类的内部定义;
- 而 Kotlin 中允许在类的外部,定义文件级别的顶层函数以及变量。
// TimeUtils.kt
fun printTime() {
......// 打印当前时间
}
// Main.kt
import com.utils.printTime
fun main() {
printTime()
}
Kotlin 中的顶层函数翻译到 Java 字节码时,会自动生成一个以【文件名 + Kt】为命名的 Java 类来包装这个顶层函数,将其作为这个 Java 类的静态函数:
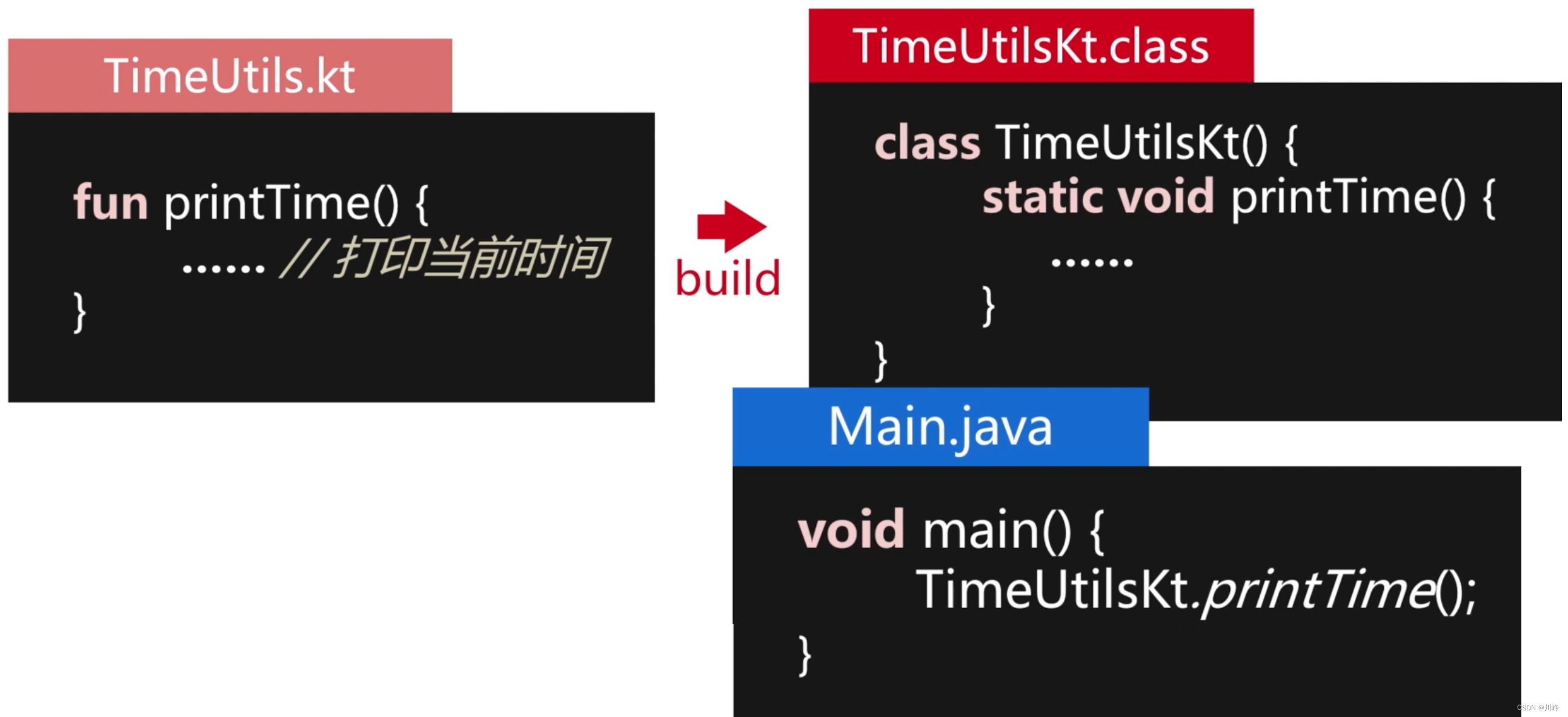
现在我们知道 Kotlin 中的顶层函数也是通过中间代码添加手段来生成的:
- 从字节码层面来说,所有的函数和变量都必须在类的内部;
- Kotlin 编译器在生成字节码时,会给顶层的函数及变量,创建一个所属的类,类名默认规则是文件名+
Kt; - Java 代码,可以通过这些以
Kt结尾的类,调用到这些在 Kotlin 中定义的顶层函数和变量。
Kotlin 中的扩展函数
// User.kt
data class User(val name: String, val age: Int)
// UserExt.kt
fun User.isVip() : Boolean {
return ...
}
// 使用
val user = User("张三", 23)
if (user.isVip()) {
...
}
Kotlin 中的扩展函数翻译成 Java 就是 xxxKt 类中的静态方法:

所以 Kotlin 中的扩展函数也是通过中间代码添加手段来生成的:
Kotlin 中的 inline 函数
Kotlin 中的 inline + reified 可以用来解决泛型具体化的问题。
inline fun <reified T> getClassTag() : String {
return T::class.java.toString()
}
fun main() {
val clazz = getClassTag<MainActivity>()
println(clazz)
}

Kotlin 中的 inline 函数同样是通过中间代码添加手段来生成的:
inline函数除了能解决泛型具体化问题,还比一般的函数更有性能优势,因为代码的添加发生在编译时,运行时会减少一次虚拟机栈中栈帧的入栈出栈操作;inline函数的副作用是,会导致代码体积增长;
Kotlin 中的可变性检查
变量的可变性检查:
var name = "hello"
name = "world" // ok
val name = "hello" // final
name = "world" // error
集合的可变性检查:
// java 代码
final List<String> names = new ArrayList<>();
names.add("hello"); // OK
names = new ArrayList<String>(); // error
- Java 中的
final的义务只是保证引用不能被重新赋值
// kotlin 代码
var names = listOf<String>("hello") // kotlin.collections.List
names.add("world") // error
var names = mutableListOf("hello") // kotlin.collections.MutableList
names.add("world") // OK
可见 kotlin 中的listOf集合是一直“真不可变”集合,你不能往里面添加东西,要添加东西只能使用mutableListOf。
以上两种 kotlin 中的集合翻译成 Java 分别对应下面两种类型:
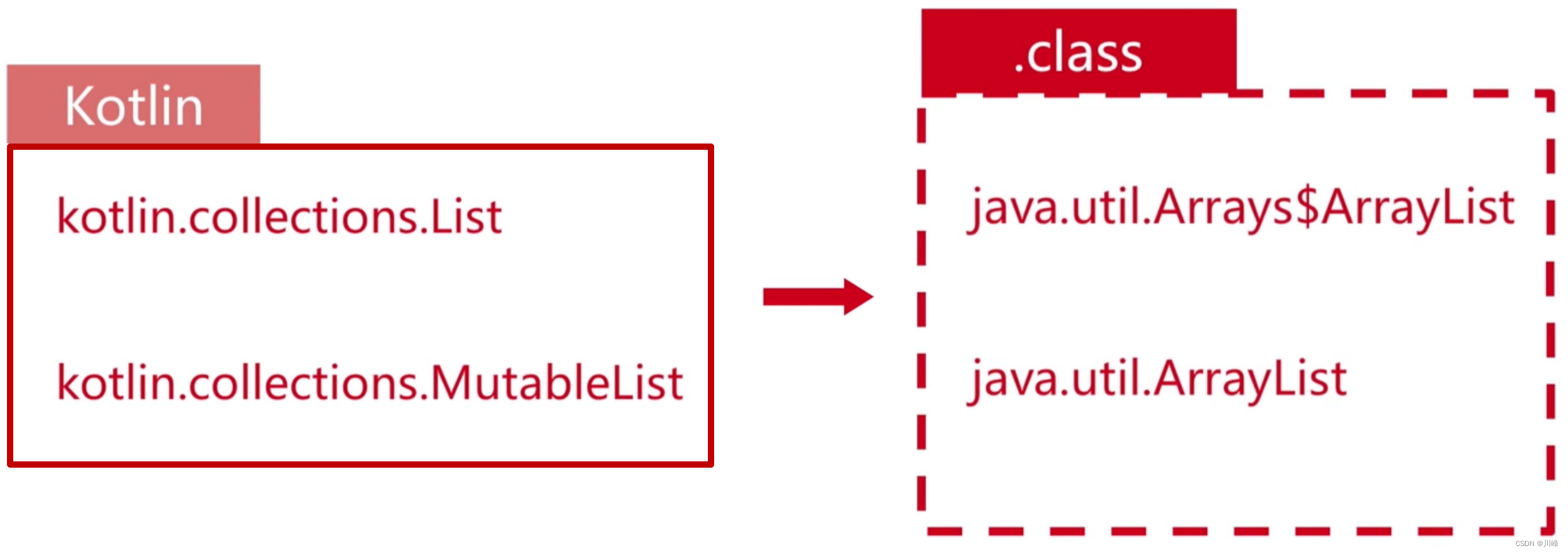
另外,kotlin 中的集合存在一个和 java 互调的坑:Kotlin 中不允许添加元素,但是 Java 中调用就可以添加元素,编译不会报错但是运行时会报错。例如:
// kotlin 代码
var names = listOf<String>("hello")
// java 代码
new DemoKt().getNames().add("world");
java 代码中这么调用的话运行时会抛出异常:java.lang.UnsupportedOperationException 。
Kotlin 中的可空性检查
类型的可空性检查:
// Operation.kt
var name : String = "hello"
var nameOrNull : String? = null
Java 是没办法感知 Kotlin 中的可空类型的,但是 IDE 可以,并且会给出警告。

IDE 能感知是因为字节码的元注解中携带了是否可空的信息:
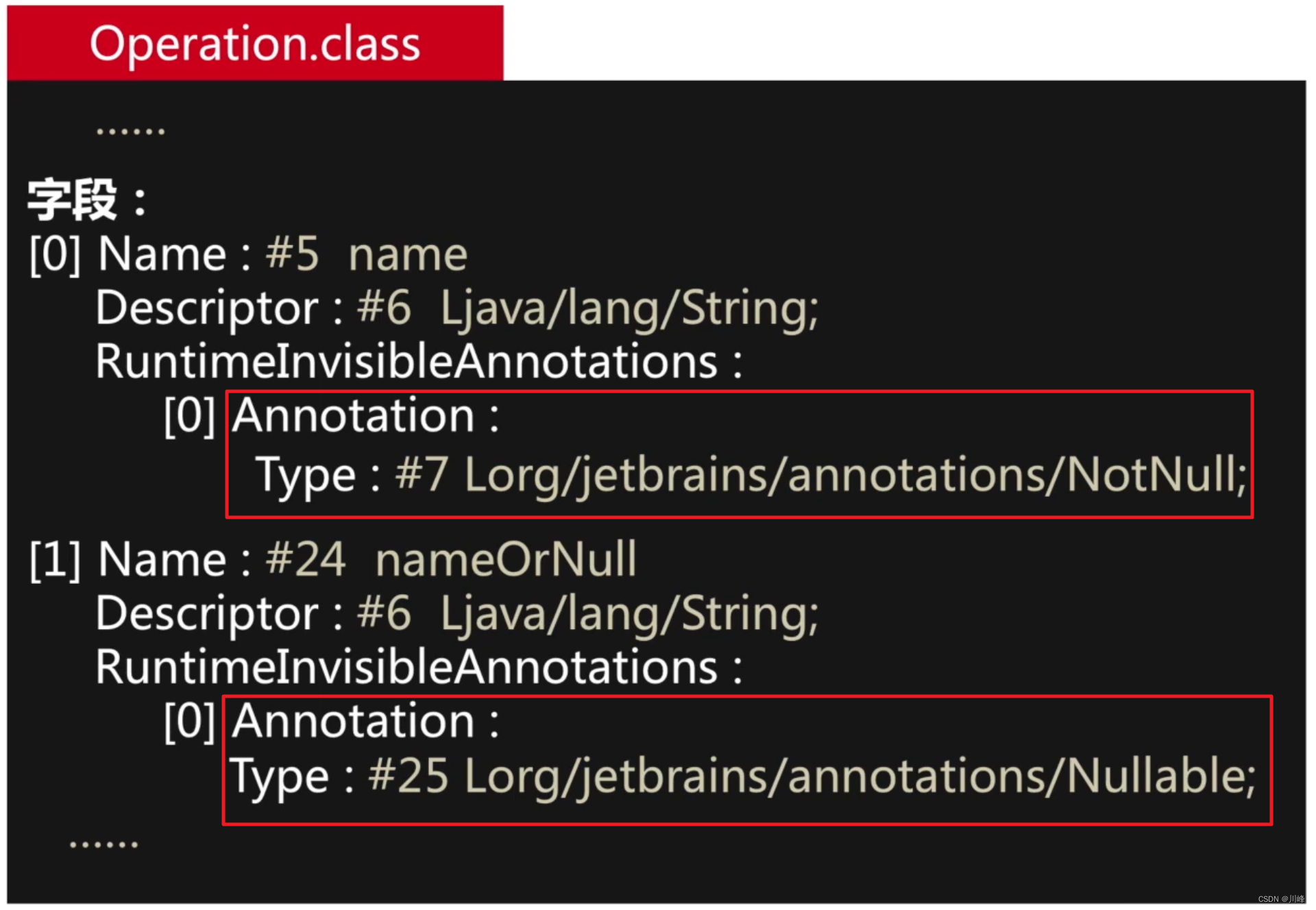
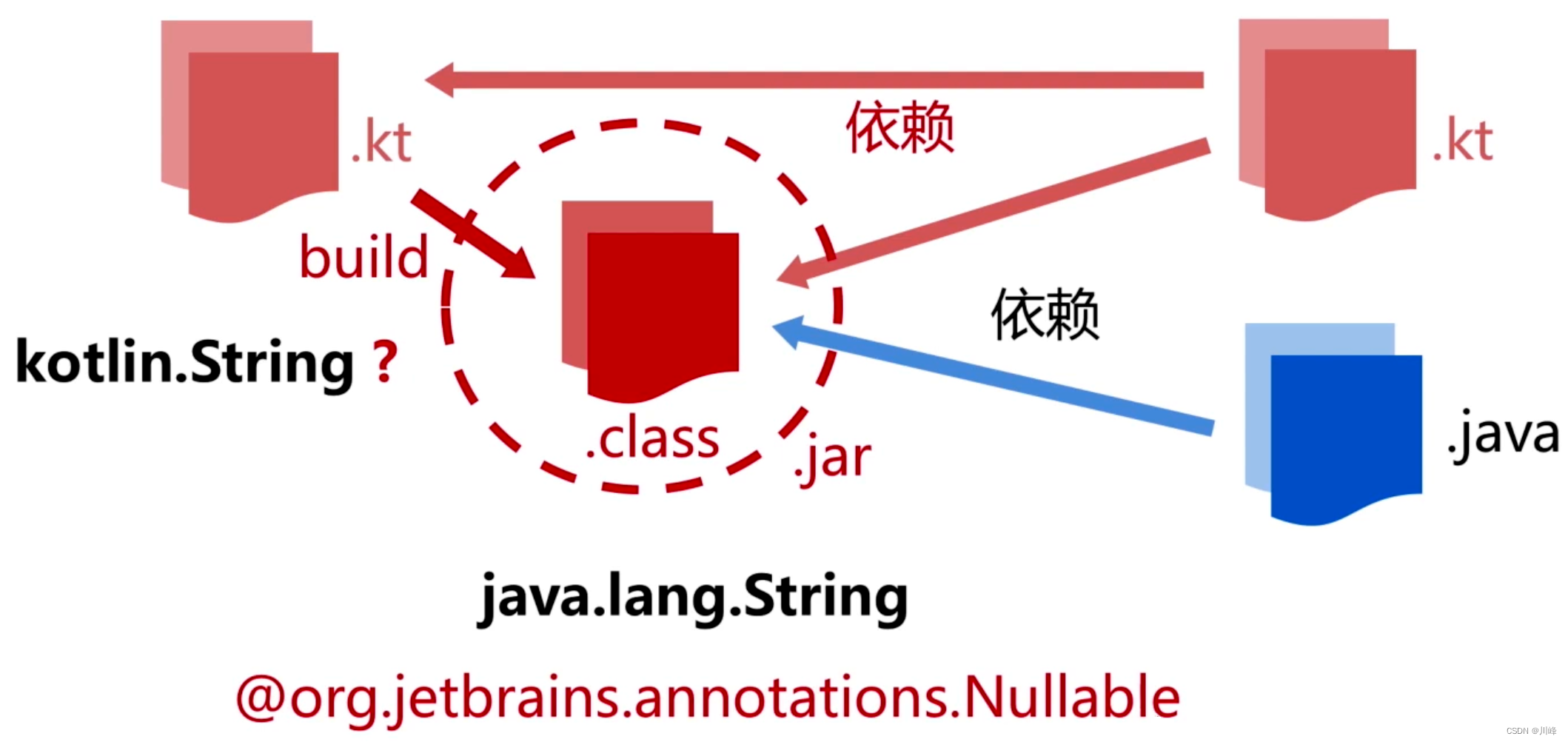
- Kotlin要保证扩展特性,能够保留到字节码中,而且是符合字节码规范的;
- Kotlin要保证扩展特性编译成的字节码,能够方便其他JVM语言(主要是Java)调用。
Kotlin 在可空性检查方面目前存在一个严重的缺陷:Kotlin 无法判断来自其他平台的变量可空性
这也是 Kotlin 和 Java 互调的另一个坑:Kotlin 无法判断来自 Java 平台的可空性,所以最靠谱的方法是使用一个可空类型来接收来自 Java 的变量。
例如:
// Operation.java
String name = null // 对 kotlin 来说是平台类型
// Kotlin 代码中最好使用 [可空类型] 来接收 [平台类型]
val name : String = Operation().name // 可以使用非空类型接受
val name : String? = Operation().name // 也可以使用可空类型接受
泛型类型的可空性检查:
val names = listOf<String?>("hello", null)
// 反射获取类型
val argument = this::names.returnType.arguments[0]
println(argument.type) // kotlin.String?
println(argument.type?.javaType?.typeName) // java.lang.String
println(argument.type?.isMarkedNullable) // true
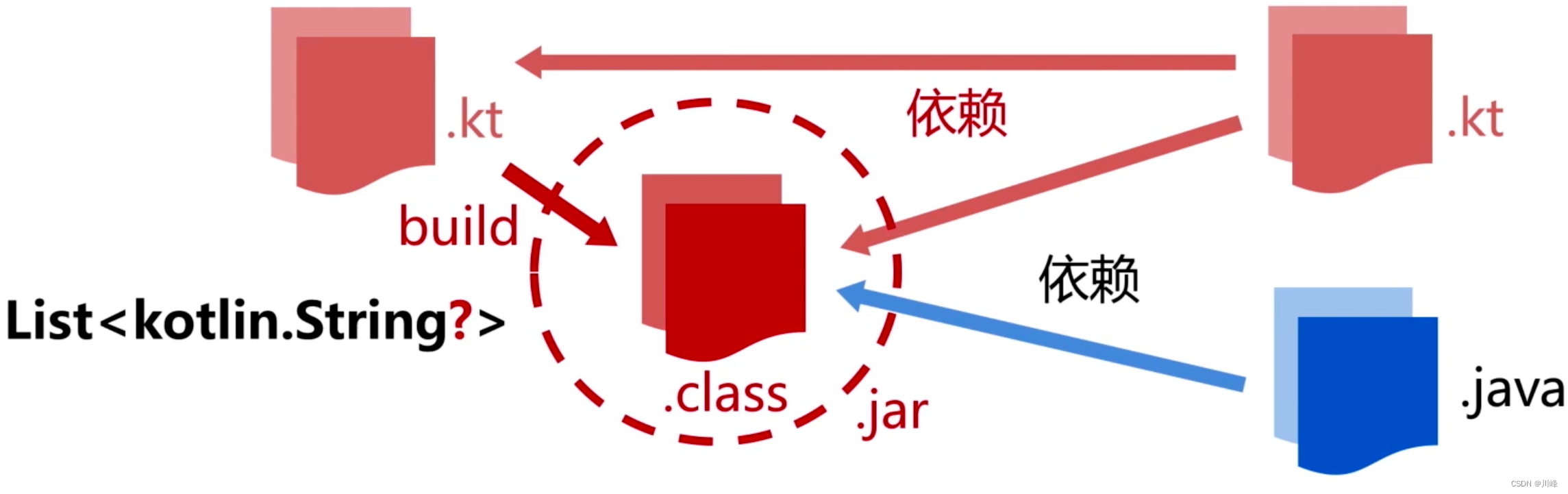
- 泛型类型会被擦除
- 泛型类型不能加元注解
那么这个是否可空的标记,被记录在哪里了??看下面示例代码:
// Operation.kt
class Operation {
val names = listOf<String?>("hello", null)
}
上面代码生成的class字节码文件中:

可以看到这里有一个运行时可见的元注解 Metadata,这个就是存储类型可空信息的关键
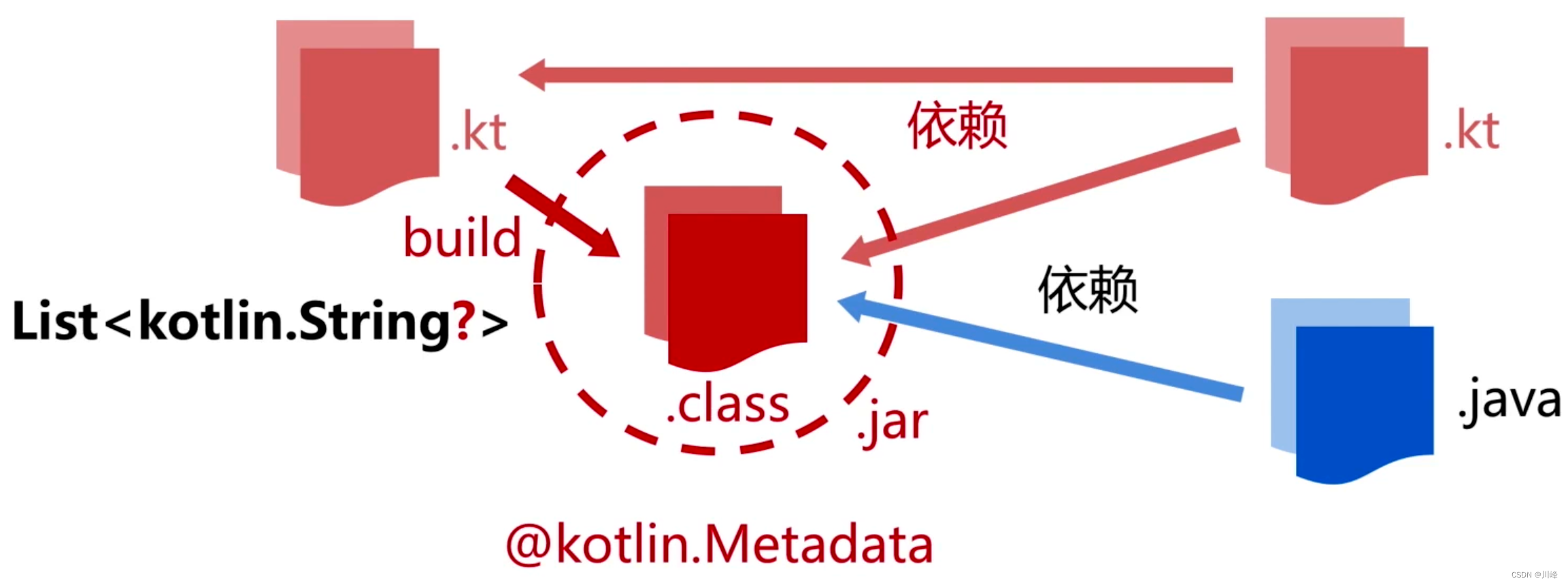
我们可以打印这个 Metadata 的注解类进行查看:
printin(Operation::class.java.getAnnotation(Metadata::class.java))
也可以直接反编译生成的Operation.class能够直接看到这个 @Metadata 的元注解的内容:

Kotlin 中的 Metadata 解析

可以在 build.gradle 中添加下面依赖库来解析 Metadata :
dependencies {
implementation "org.jetbrains.kotlinx:kotlinx-metadata-jvm:{version}"
}
该库专门用来解析 JVM 版本的 kotlin 的 metadata。
使用:
// 1.反射获取注解类
val annotation = Operation::class.java.getAnnotation(Metadata::class.java)
// 2.构建 ClassHeader
val classHeader = KotlinClassHeader(
kind = annotation.kind,
metadataVersion = annotation.metadataVersion,
bytecodeVersion = annotation.bytecodeVersion,
data1 = annotation.data1,
data2 = annotation.data2,
...
)
// 3.获取 metadata
val metadata = KotlinClassMetadata.read(classHeader) as? KotlinClassMetadata.Class
// 4. 访问 metadata 中的信息
metadata.accept(
object : KmClassVisitor() { // 访问类
override fun visitProperty(flags: Flags, name: String, ...) : KmPropertyVisitor {
return object:KmPropertyVisitor() { // 访问属性
override fun visitReturnType(flags: Flags): KmTypeVisitor {
return object : KmTypeVisitor() { // 访问属性的类型
override fun visitArgument(flags: Flags,......): KmTypeVisitor { // 访问类型的泛型类型
val nullable = Flag.Type.IS_NULLABLE(flags)
println("property_name: $name argument_nullable: $nullable")
return this
}
}
}
}
}
}
)
控制台输出:
property_name: names argument_nullable: true
总结
| Kotlin 的解决手段 | 所实现的语言特性 |
|---|---|
| 编译器支持 | 类型推断 可变性检查 自动拆装箱 泛型数组 |
| 中间代码添加 | 高阶函数、顶层函数、扩展函数、内联函数 数据类、密封类、单例类、伴生对象、接口委托 泛型具体化 |
| 元注解 + Metadata 信息添加 | 类型的可空性信息 可见性信息 访问限定符 Kotlin 反射数据源支持 |
如何理解 Kotlin 中的函数式编程特性?
选择一门支持函数式编程的语言,并不是写出函数式代码的关键,转变看待问题的角度才是最重要的。
什么是函数式编程
下面看一个简单的局部算法问题:
data class User(val name: String, val age: Int)
val numbers = arrayOf(
User("zhangsan", 18),
User("lisi", 21),
User("wangwu", 25)
)
现在要找到这个 numbers 数组中大于18岁的用户的名字。
命令式解法的代码如下:
val results = mutableListOf<String>() // 结果的初始状态
for (index in numbers.indices) {
val user = numbers[index]
if (user.age > 18) { // index、user都是循环的状态
result.add(user.name)
}
} // 分支语句、赋值、add 都是操作状态的命令
- 命令式解法的视角:程序是一系列改变状态的命令,开发者关注的是状态。
函数式解法的代码如下:
val result = numbers.filter {
user -> user.age > 18
}.map { user ->
user.name
}
这里使用了一个 Kotlin 中集合的变换操作符 filter,它的定义如下:
public inline fun <T> Array<out T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate)
}
public inline fun <T, C : MutableCollection<in T>> Array<out T>.filterTo(destination: C, predicate: (T) -> Boolean): C {
for (element in this) if (predicate(element)) destination.add(element)
return destination
}
与之类似的还有比较常用的 map 变换操作符:
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(size), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Array<out T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}
其实现方式其实就是通过传递高阶函数(lambda表达式),在内部还是最原始的实现方式。
函数式编程的特点:
- 避免可变的状态。
- 程序是表达式和变换关系,而不是命令。
- 建立在数学的直觉上。
函数式编程中的重要概念
权责让渡
- 封装和抽象,隐藏实现细节。
- 将低层次的细节的控制权交给运行时,开发者只关注高层次的细节。
- 关注点分离原则。
计算机语言的进化,就是一个权责让渡的过程。面向对象编程中的抽象,也是一种权责让渡。
函数副作用
- 函数执行时,除了返回值外,还对外部产生了其他影响。
- 比如,修改了全局变量、外部变量或参数。
纯函数
- 输入与输出全是显式的:即,函数与外界沟通的唯一渠道就是参数或返回值。
- 纯函数是没有副作用的函数。
- 每次调用,只要给定同样的参数,就会得到同样的结果。
- 能够对应数学中函数的定义,是一种映射关系。(
f: A -> B)
函数式编程的 “三板斧” 模式
用 “三板斧” 模式代替迭代:
- 筛选(filter)
- 映射(map)
- 压缩(reduce/fold)
函数式解法的例子:
val result = numbers.filter { user ->
user.age > 18
}.map { user ->
user.name
}.reduce { acc, name ->
"$acc, $name" // "lisi, wangwu"
}
val result = numbers.filter { user -
user.age > 18
}.map { user->
user.name
}.fold(StringBuilder("Adult:")) { acc, name ->
builder.append(name).append(",") // "Audlt:lisi,wangwu,"
}
闭包
闭包 = 内部作用域 + 访问的外部变量
- 闭包必须是可引用的;
- 闭包必须是有状态的。
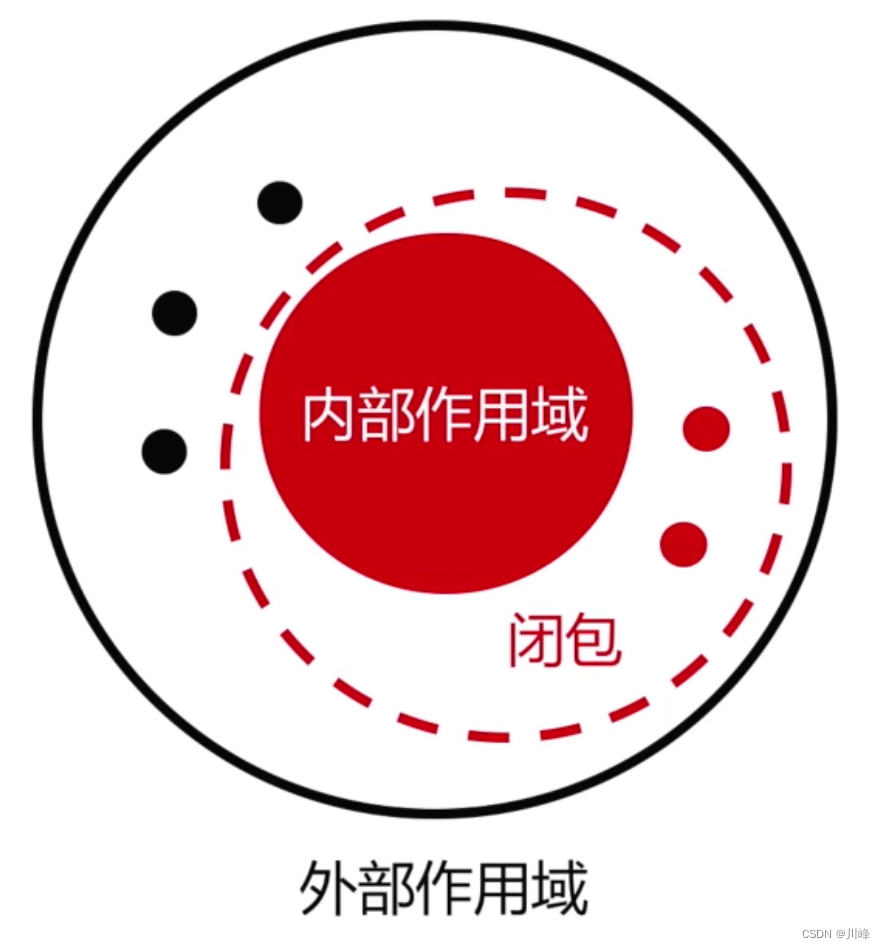
闭包拥有状态也是权责让渡和封装抽象的体现。
闭包的作用:
- 保护私有作用域;
- 保存上下文;
- 交出对状态的控制权,让开发者不关注状态。
记忆
- 只有纯函数,才能被记忆;
- 交出对状态的控制权,让开发者不关注状态。
函数式编程可以很容易实现记忆缓存的功能,例如:
fun loadImage(path : String): Bitmap? {
return createBitmap(File(path)) // 根据文件路径创建 bitmap
}
现在希望每次创建的Bitmap能被记忆在内存中,每次相同的文件路径,直接复用上次创建的缓冲。
函数式编程的代码:
fun loadImage(path : String): () -> Bitmap? {
var cache :Bitmap? = null
return {
if (cache != null) {
cache
} else {
val image = createBitmap(File(path))
cache = image
image
}
}
}
使用:
val load = loadImage("/file/icon.jpg")
load()
load()
柯里化
看下面代码:
fun volume(width : Int, depth : Int, height : Int) : Int {
return width * depth * height
}
val v = volume(3, 1, 4)
可以将上面的 volume 函数改造成下面的结构:
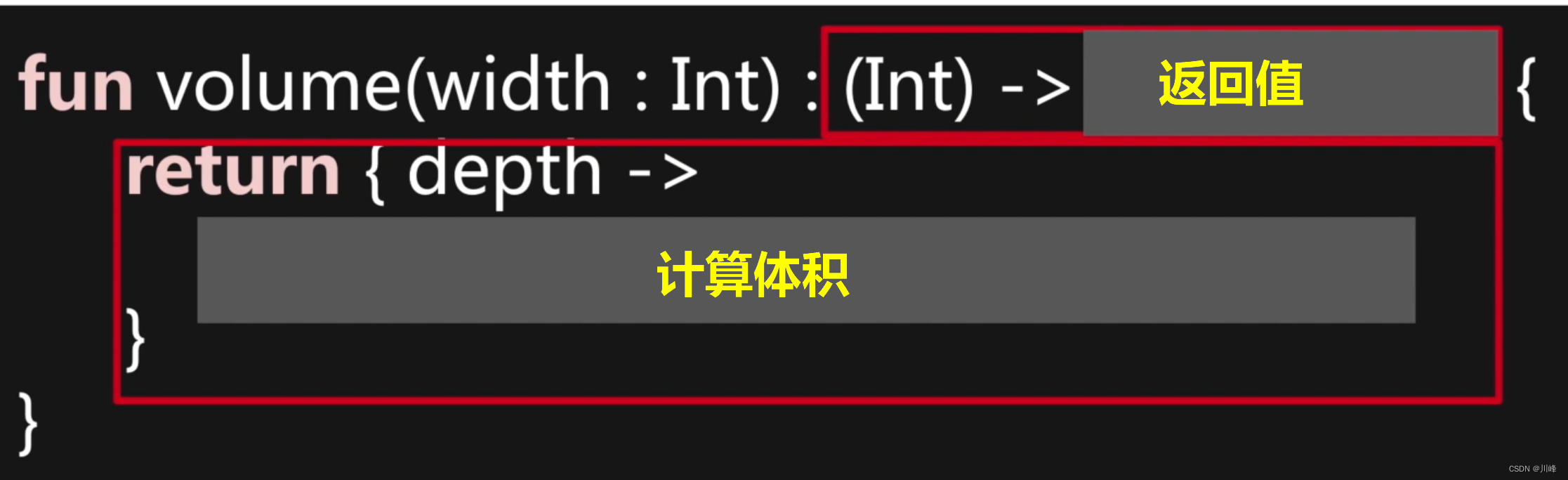
由于返回值是一个函数类型,因此就可以像下面这样调用:
volume(3)(1)
// 等价于
val v = volume(3)
v(1)
将上面的结构继续进一步改造:

于是就可以像下面这样调用:
val result = volume(3)(1)(4)
// 等价于
val v = volume(3)(1)
val result = v(4)
这就是柯里化:
- 柯里化就是把一个多参函数,转换为一连串的单参函数
- 柯里化就是不断的将返回值改为一个函数类型,这个返回值在调用的时候才会执行函数
柯里化的一个重要作用:函数部分施用
例如针对前面示例中的volume函数在使用时发现,大部分需要求体积的情况,宽度和深度都是一样的,只有高度不同。如下:
val v1 = volume(3, 1, 4)
val v2 = volume(3, 1, 1)
val v3 = volume(3, 1, 5)
通过柯里化就可以很好的解决:
可以先将宽高固定下来:
val area : (Int) -> Int = volume(3)(1)
然后调用返回的这个函数,传入不同的高度即可:
val v1 = area(4)
val v2 = area(1)
val v3 = area(5)
写这部分代码的开发者,完全不用关注前两个参数是什么,甚至不用关注底面积是怎么来的。这样就可以做到一定程度的函数复用和分离。
柯里化的作用:
- 让函数部分施用,提前带入一部分参数,用于复杂问题的分步求解;
- 推迟计算的执行,带入最后一个参数后,函数才真正开始执行;
- 隐藏一部分参数,交出这些参数的控制权,让开发者接触不到这些参数,提高安全性和稳定性。
柯里化的应用场景
例如:
makeUrl("http")("www.user.com")("home.html")
val urlByPath = makeUrl("http")("www.user.com")
val home = urlByPath("home.html")
val login = urlByPath("login.html")
柯里化只有在最后一个参数被传入时,才会执行,所以非常适合用于构建类似 url 这种对顺序和完整性有要求的内容。
尾递归优化
看一个简单的局部算法问题:
data class Product(val id: Int, val price: Double)
class Node<T>(val value: T, val next: Node<T>?)
val firstNode = Node(Product( 1, 180.99),
Node(Product(,2 , 299.99),
Node(Product (3, 999.00 ), null)))
现在要找到链表中第一个价格大于900的商品。
利用函数式编程可以这样来做:
fun <T> find(node: Node<T>, predicate: (T) -> Boolean ): T? {
return when {
predicate(node.value) -> node.value
node.nextNode == null -> null
else -> find(node.nextNode)
}
}
val result = find(firstNode) { product ->
product.price > 900
}
其实就是一个递归调用,当然也可以写成纯递归调用方式:
fun findProduct(node: Node<Product>): Product? {
return when {
node.value.price > 900 -> node.value
node.nextNode == null -> null
else -> findProduct(node.nextNode)
}
}
val result = findProduct(firstNode)
这种写法不如前一种好,因为前面一种写法交出了对状态的控制权,让开发者不关注状态,是真正的函数式编程。
但是递归调用存在一个最大的问题是可能导致栈溢出,因此没有循环好。
在 kotlin 中可以通过 tailrec 关键字进行尾递归优化:
tailrec fun <T> find(node: Node<T>, predicate: (T) -> Boolean ): T? {
return when {
predicate(node.value) -> node.value
node.nextNode == null -> null
else -> find(node.nextNode)
}
}
什么是尾调用递归:
- 让递归函数中所有的递归操作都出现在函数的末尾。
- 尾递归优化不会导致栈溢出。
我们将加 tailrec 和不加 tailrec 两种情况的代码翻译成字节码查看其区别:
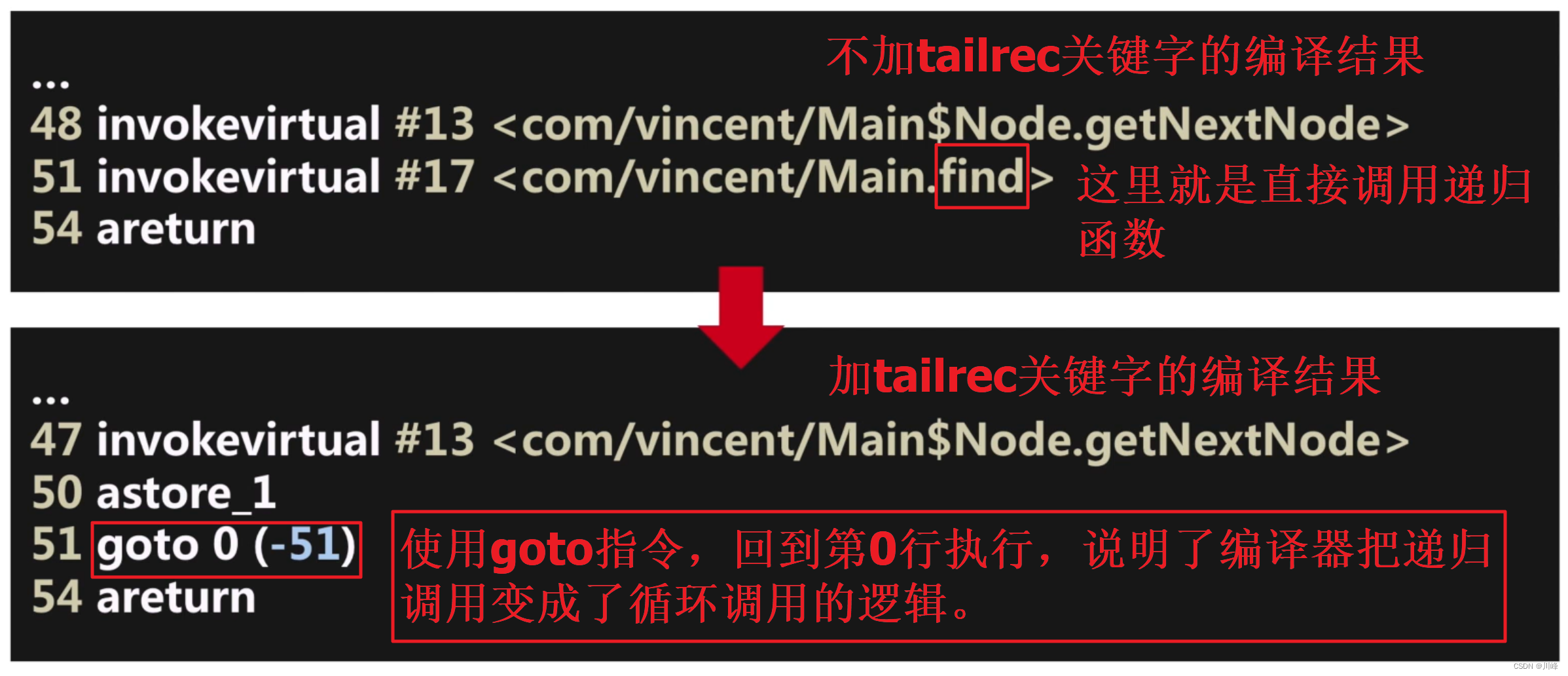
所以 kotlin 尾递归优化之所以没有栈溢出问题,本质是将代码转化成了循环调用。
不相交联合体
Java 中习惯通过异常来处理错误分支,但是函数抛出异常就代表函数有了副作用。
在函数式编程中,如何抛出异常或者处理错误?
@Throws(IllegalUserException::class)
fun checkPermission(user : User) : Boolean {
return when {
user.illegal() -> throw IllegalUserException()
user.isMember() -> true
else -> false
}
}
上面代码中,有一个 when 的分支抛出了异常,抛出异常就属于函数的副作用,它会打破原有的业务逻辑,对外部调用者来说,对该函数的期望是返回 true 或 false 。
一种简单粗暴的办法是可以函数返回一个Pair类型同时包含异常信息和Boolean信息:
fun checkPermission(user : User) : Pair<Boolean?, Exception?>
这种方式可行,但是不够方便简洁,不优雅。有没有办法让函数有时返回Boolean,有时返回Exception?
不相交联合体
- 一种类型,有两种不同类型的 “左值” 和 “右值”,但是在使用时,有且只能同时有一种 “左值” 或者 “右值”,不能同时拥有两者。

实现不相交联合体:
sealed class Either<L, R> {
data class Left<L, R>(val value: L) : Either<L, R>()
data class Right<L, R>(val value: R) : Either<L, R>()
}
sealed class Result<D, E> {
data class Normal<D, E>(val value: D) : Result<D, E>()
data class Unexpected<D, E>(val value: E) : Result<D, E>()
}
使用:
fun checkPermission(user : User) : Result<Boolean, Exception> {
return when {
user.illegal() -> Result.Unexpected(IllegalUserException())
user.isMember) -> Result.Normal(true)
else -> Result.Normal(false)
}
}
说白了就是将异常信息作为返回结果的一部分封装到实体类。返回的不同实体类是具有排他性的,可以通过 kotlin 的密封类做到这一点。
函数式编程中的设计模式
面向对象的设计模式在函数式编程中的归宿:
- 被吸收为语言的一部分。例如 Kotlin 中的
object单例类、by接口委托代理、… - 新语言或范式,提供了全新的解决方案。例如 Kotlin 中的元编程、扩展函数、…
- 设计模式依然成立,但实现方式有所变化
基于继承的模版方法模式:
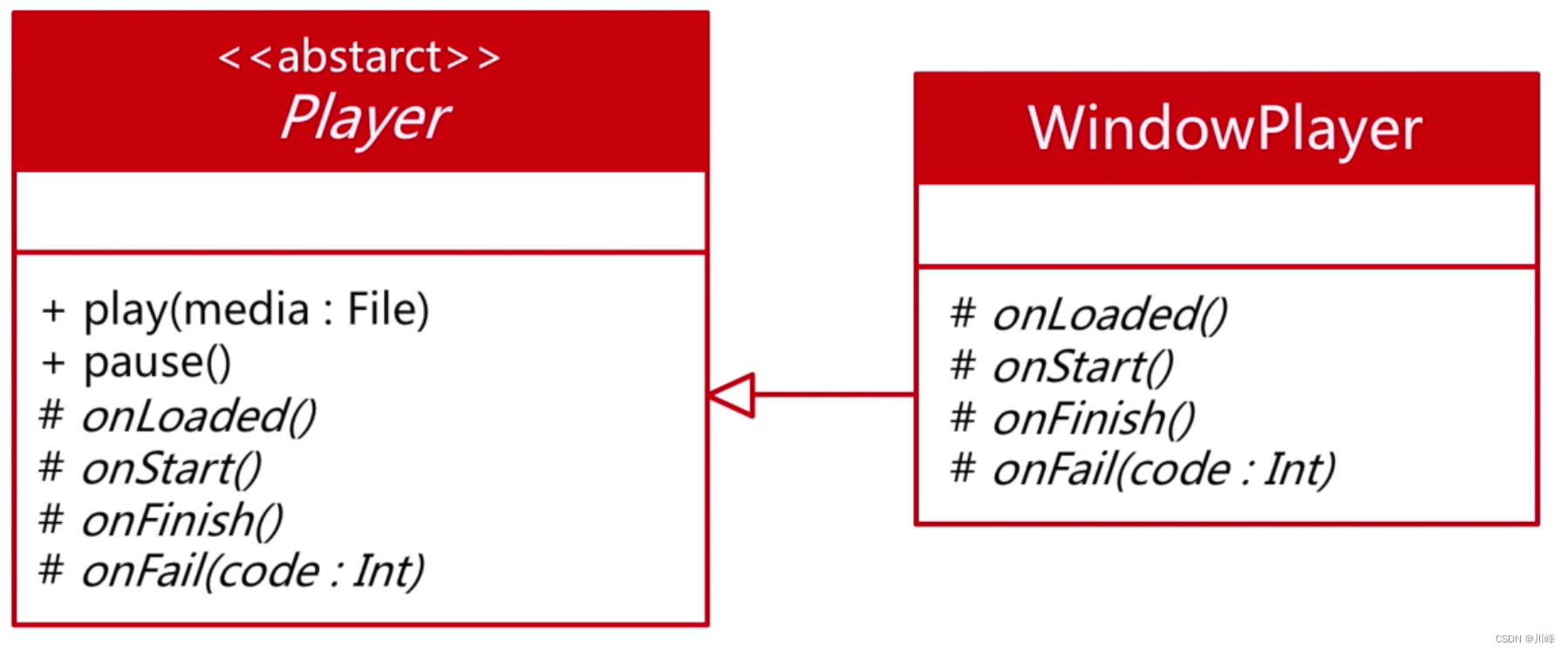
按照 Java 的思路设计代码如下:
abstract class Player {
fun play(media: File) { ... }
fun stop() { ... }
abstract fun onLoaded()
abstract fun onStart()
abstract fun onFinish()
abstract fun onFail(code: Int)
}
但是同样的 Java 代码到了 Kotlin 中,就可以借助高阶函数直接传函数回调参数,而无需一个抽象类了。
Kotlin 中高阶函数实现模版方法模式:
class Player (
val onLoaded : () -> Unit,
val onStart : () -> Unit,
val onFinish : () -> Unit,
val onFail: (Int) -> Unit,
) {
fun play(media: File) { ...... }
fun stop() { ...... }
}
在使用的时候,也不需创建子类实例对象了,直接构造传参即可:
val player = Player(
onLoaded = {
// TODO 隐藏 Loading UI
},
onStart = {
// TODO 显示进度条、播放时间、停止键
},
onFinish = {
// TODO 关闭播放器窗口
},
onFail = { code ->
// TODO 错误提示
}
)
- 组合优于继承。
策略模式:
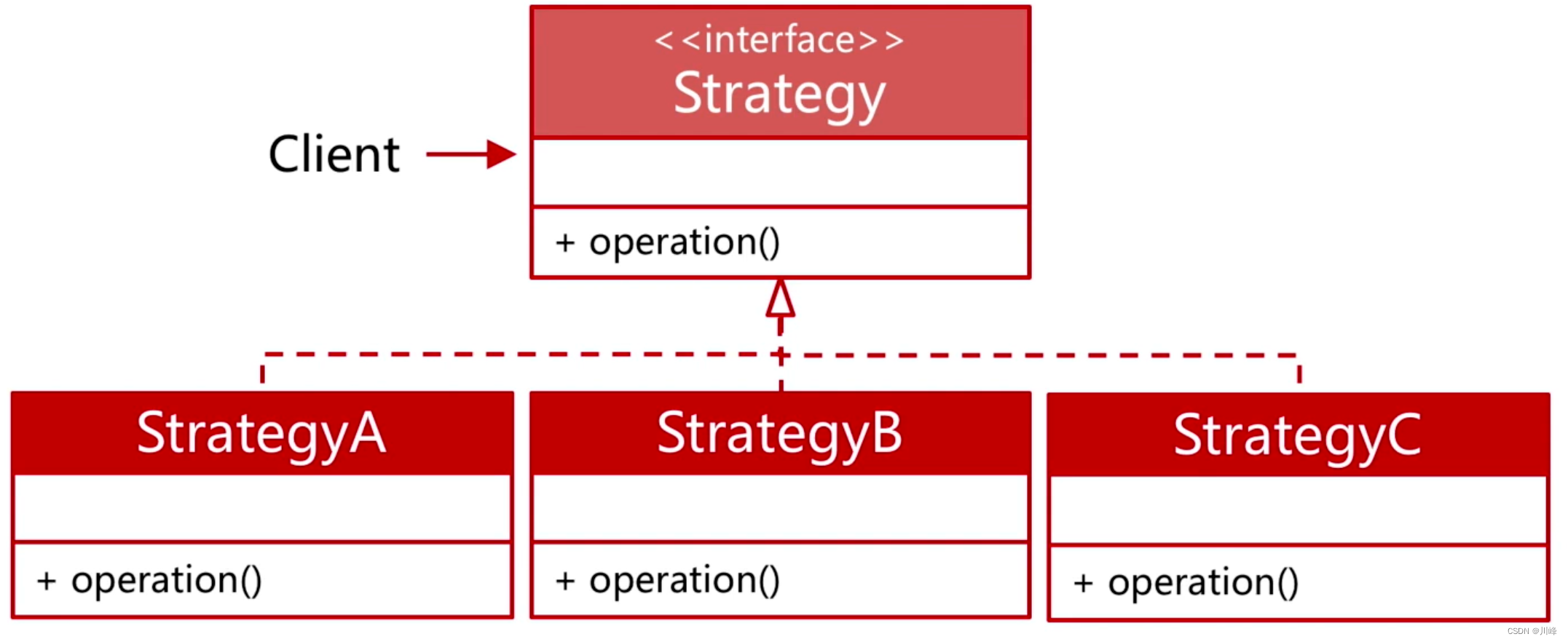
- 定义一系列解决同一问题的不同算法,让他们之间可以随意切换,而不影响到调用者。
在函数是一等公民的世界里,策略模式变得没有意义,或者说不用写专门的代码去实现它,因为函数类型天生就支持返回不同的类型。

Java 代码实现的不同策略类在 Kotlin 中只需要传递对应的函数类型的参数即可。
构建者模式 - 柯里化
例如前面提到柯里化构建 url 的例子就是一个建造者模式:
makeUrl("http")("www.user.com")("home.html")
val urlByPath = makeUrl("http")("www.user.com")
val home = urlByPath("home.html")
val login = urlByPath("login.html")
柯里化还能在 Builder 模式功能的基础上,保证参数传入的有序性和完整性
val builder = buildDialog ("通知")(R.drawable.icon)
builder("请更新App!")("ok") { view ->
// 点击事件
}
builder("正在加载...")("好") { view ->
// 点击事件
}
注意:Kotlin 中可以通过构造函数的命名参数和可选参数天然的支持构建者模式。
函数式编程中的 OO 原则
函数对象可以满足面向对象中的 OO 设计原则:
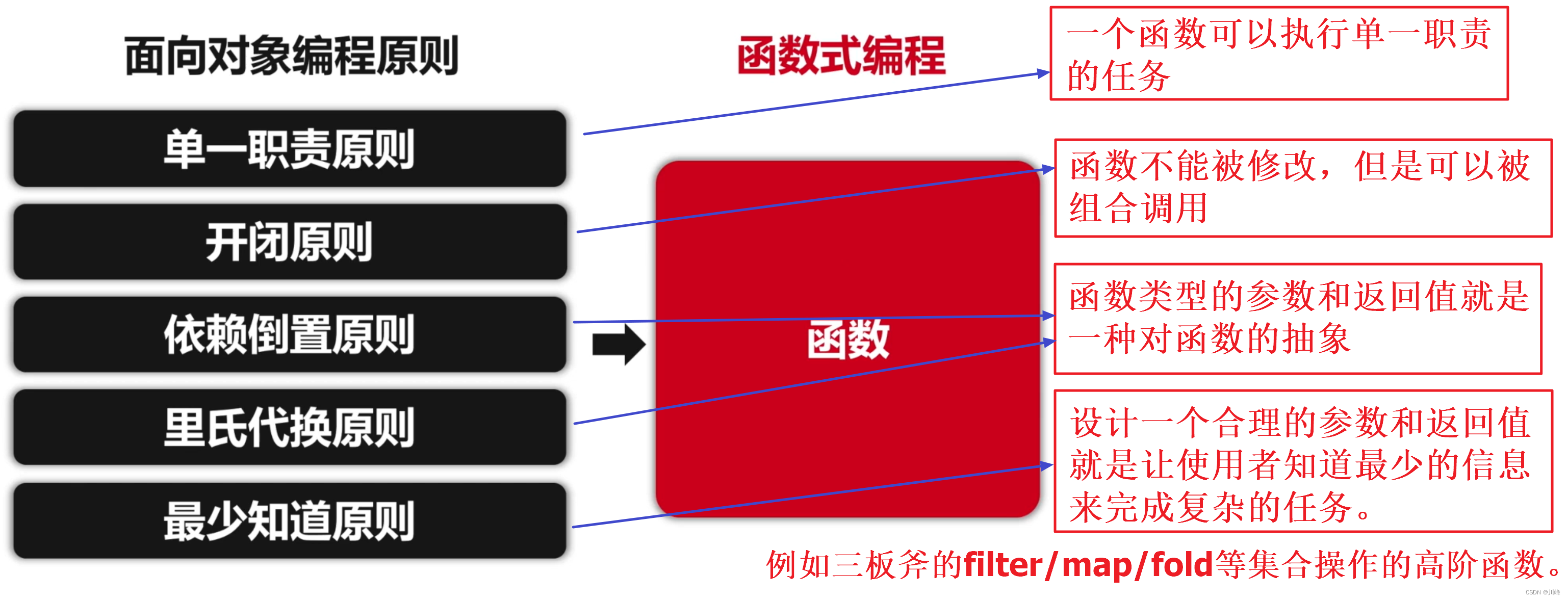
在函数式编程中,设计模式也变得简单了很多,面向对象的设计模式的思想是高度抽象化,而函数式编程中则会借助语言特性进行平铺打散。
- 一些面向对象的设计模式,实际上是 “用面向对象的方式” 解决 “只有面向对象才会碰到的问题”。
- 函数式编程和面向对象思维并不是矛盾对立的,在 Kotlin 中借助函数式编程可以:
① 提高局部代码的开发效率;
② 应用数学原理。
如果单纯从编程语言的角度来看,面向过程的语法通常要比面向对象的语法要简化一些,因为不需要封装和继承,也没有多态与抽象。只要语言特性支持的好,在函数式编程中实现面向对象的 OO 原则并不是难事。
函数式编程的要点
- 函数是一等公民:函数可以像普通变量一样被创建、修改,可以像变量一样传递、返回,或是在函数中嵌套函数。
- 引用透明性:函数的运行不依赖于外部变量或 “状态”,只依赖于输入的参数,任何时候只要参数相同,调用函数所得到的返回值总是相同的。(纯函数)
- 权责让渡:将低层次的细节的控制权交给运行时,开发者只关注高层次的细节。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!