CogVLM多模态大模型训练代码详细教程(基于vscode调试与训练)
文章目录
前言
今天(2023-12-29),我很开心,断断续续时间搞了一下CogVLM大模型训练代码,终于实现了CogVLM大模型训练。特别是我是基于vscode编辑器配置launch.json文件在RTX4090显卡实现多模态大模型训练。可能很多玩过大模型或显卡显存充足情况下,使用官网教程,顺利情况亦可实现该模型训练。然我介于显卡为云服务,不得不在一张4090显卡上实现代码解读与训练。而代码解读必然使用debug模式较佳,在多种编辑器中看到vscode能力,我实现deepspeed方式在vscode中训练大模型。同时,有关CogVLM模型训练的解读或代码资料较少。因此,本文将介绍如何训练CogVLM模型,重点是如何使用vscode在4090显卡上调试模型。当然,我的博客也分享了vscode使用deepspeed方法与CogVLM推理过程解读,感兴趣可参考我的博客。
一、cogvlm环境安装
按照官网方法安装:https://github.com/THUDM/CogVLM/tree/main
# CUDA >= 11.8
pip install -r requirements.txt
python -m spacy download en_core_web_sm
建议查看requirements.txt文件下载对应torch版本离线安装,特别注意2.0以上版本含有cudnn,如果你cuda安装有cudnn,则下载不含cudnn的版本。当然,你安装也可存在以下问题,如下:
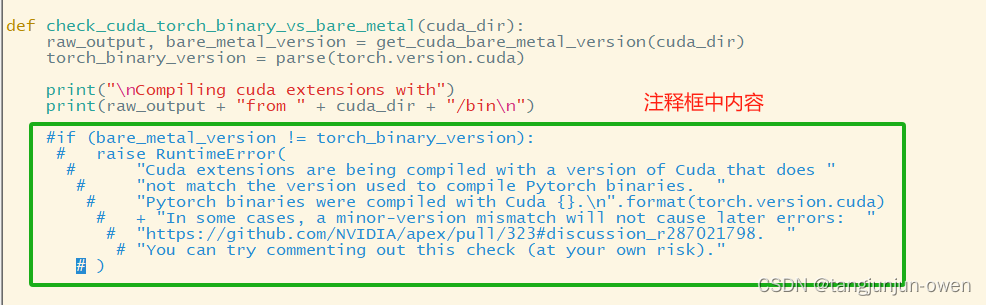
1、apex问题
github上下载apex离线安装会报错,大致原因是与torch版本兼容问题,可直接忽略,在setup.py文件中注释如下图框中内容即可:
最后,会提示安装成功,如下图:

2、en_core_web_sm问题
也许运行代码会有OSError: [E050] Can’t find model ‘en_core_web_sm’. 错误,这个是中文映射相关库,word2embeding相关内容,方法如下:
下载:
可以使用命令下载:python3 -m spacy download en_core_web_sm
也可以直接使用链接手动下载(链接来源命令):
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl
安装:
pip install en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl
通过运行:

二、launch.json文件配置
想要调试方式对CogVLM模型debug解读代码,必然需要配置launch.json文件内容。在这里,我假设使用finetune_cogvlm_lora.sh文件运行,我会给出如何将sh运行脚本配置launch.json文件,可debug方式解读代码。
1、finetune_cogvlm_lora.sh被配置内容
#! /bin/bash
# export PATH=/usr/local/cuda/bin:$PATH
# export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
NUM_GPUS_PER_WORKER=8
MP_SIZE=1
script_path=$(realpath $0)
script_dir=$(dirname $script_path)
main_dir=$(dirname $script_dir)
MODEL_TYPE="cogvlm-base-490"
VERSION="base"
MODEL_ARGS="--from_pretrained $MODEL_TYPE \
--max_length 1288 \
--lora_rank 10 \
--use_lora \
--local_tokenizer lmsys/vicuna-7b-v1.5 \
--version $VERSION"
# Tips: If training models of resolution 244, you can set --max_length smaller
OPTIONS_SAT="SAT_HOME=~/.sat_models"
OPTIONS_NCCL="NCCL_DEBUG=info NCCL_IB_DISABLE=0 NCCL_NET_GDR_LEVEL=2 LOCAL_WORLD_SIZE=$NUM_GPUS_PER_WORKER"
HOST_FILE_PATH="hostfile"
train_data="./archive_split/train"
valid_data="./archive_split/valid"
gpt_options=" \
--experiment-name finetune-$MODEL_TYPE \
--model-parallel-size ${MP_SIZE} \
--mode finetune \
--train-iters 800 \
--resume-dataloader \
$MODEL_ARGS \
--train-data ${train_data} \
--valid-data ${valid_data} \
--distributed-backend nccl \
--lr-decay-style cosine \
--warmup .02 \
--checkpoint-activations \
--vit_checkpoint_activations \
--save-interval 200 \
--eval-interval 200 \
--save "./checkpoints" \
--eval-iters 10 \
--eval-batch-size 1 \
--split 1. \
--deepspeed_config test_config_bf16.json \
--skip-init \
--seed 2023
"
run_cmd="${OPTIONS_NCCL} ${OPTIONS_SAT} deepspeed --master_port 16666 --hostfile ${HOST_FILE_PATH} finetune_cogvlm_demo.py ${gpt_options}"
echo ${run_cmd}
eval ${run_cmd}
set +x
2、launch.json文件配置
将上面的sh文件配置成launch.json文件,内容如下:
{
"version": "0.2.0",
"configurations": [
{
"name": "finetune_cogvlm_lora",
"type": "python",
"request": "launch",
"program": "/home/ubuntu/anaconda3/envs/cogvlm/bin/deepspeed",
"console": "integratedTerminal",
"justMyCode": true,
"args": [
//"--hostfile","./hostfile.txt",
"finetune_demo/finetune_cogvlm_demo.py",
//"${file}",
"--experiment-name", "cogvlm-base-490",
"--model-parallel-size", "1",
"--mode", "finetune",
"--train-iters", "800",
"--resume-dataloader",
"--from_pretrained", "cogvlm-base-224",
"--max_length", "1288",
"--lora_rank", "10",
"--use_lora",
"--local_tokenizer", "lmsys/vicuna-7b-v1.5",
"--version", "base",
"--train-data", "/home/CogVLM-main/archive_split/train",
"--valid-data", "/home/CogVLM-main/archive_split/valid",
"--distributed-backend", "nccl",
"--lr-decay-style", "cosine",
"--warmup",".02",
"--checkpoint-activations",
"--vit_checkpoint_activations",
"--save-interval", "200",
"--eval-interval", "200",
"--save", "./checkpoints",
"--eval-iters", "10",
"--eval-batch-size", "1",
"--split", "1.",
"--deepspeed_config", "test_config_bf16.json",
"--skip-init",
"--seed", "2023"
],
"env": {
//"SAT_HOME": "~/.sat_models",
"NCCL_DEBUG": "info",
"NCCL_IB_DISABLE": "0",
"NCCL_NET_GDR_LEVEL": "1",
"LOCAL_WORLD_SIZE": "1",
"CUDA_VISIBLE_DEVICES": "0",
"PYDEVD_DISABLE_FILE_VALIDATION": "1",
}
}
]
}
注:最重要是vscode如何使用deepspeed运行大模型
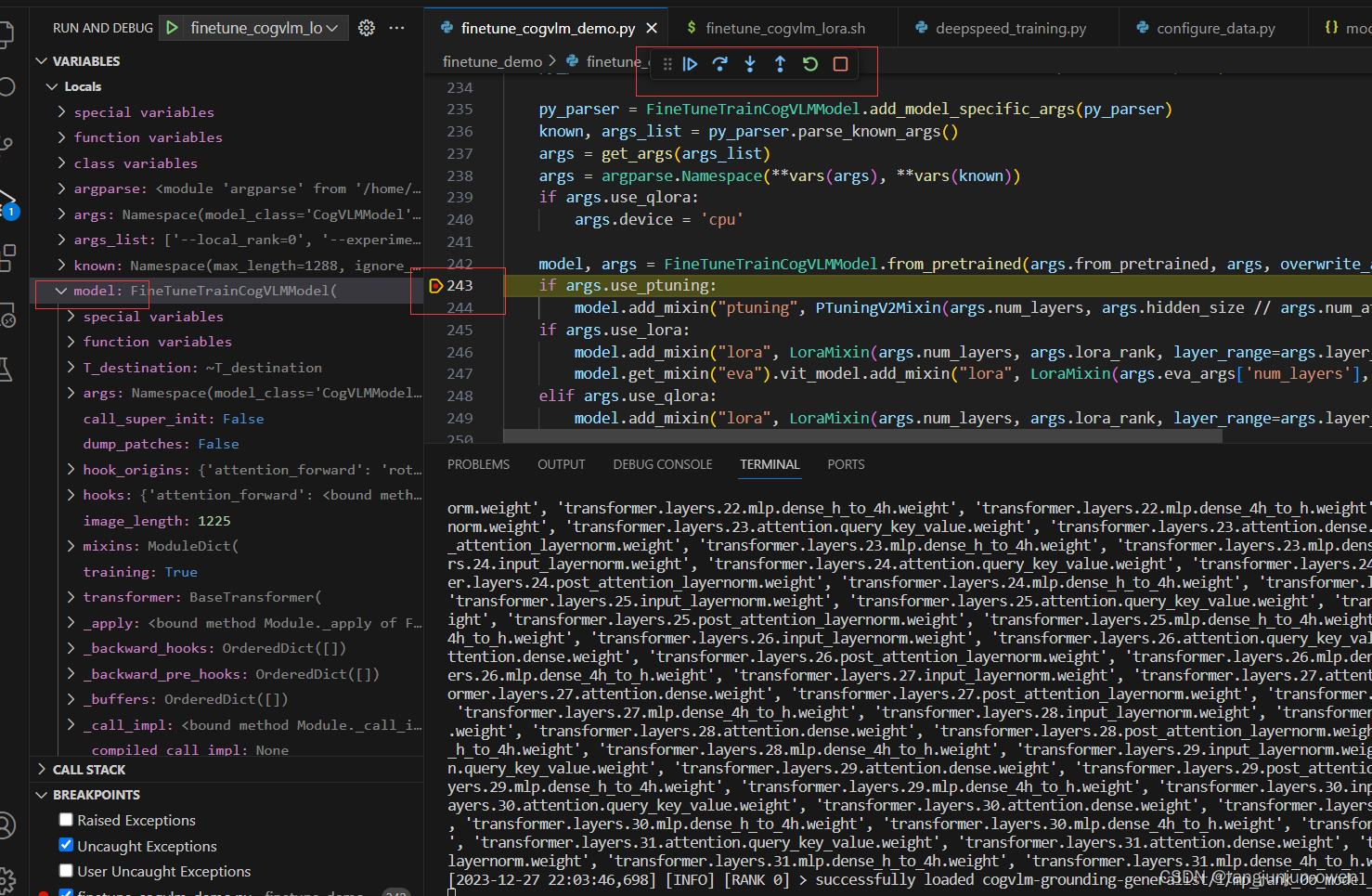
3、debug调试展示
按照以上内容即可实现如下debug方式,解决sh无法debug模型变成可debug方式,大大提高代码解读和修改。
三、训练源码解读
1、权重问题
模型中使用的相关权重,可参考官网和我的博客http://t.csdnimg.cn/53d2C
2、数据问题
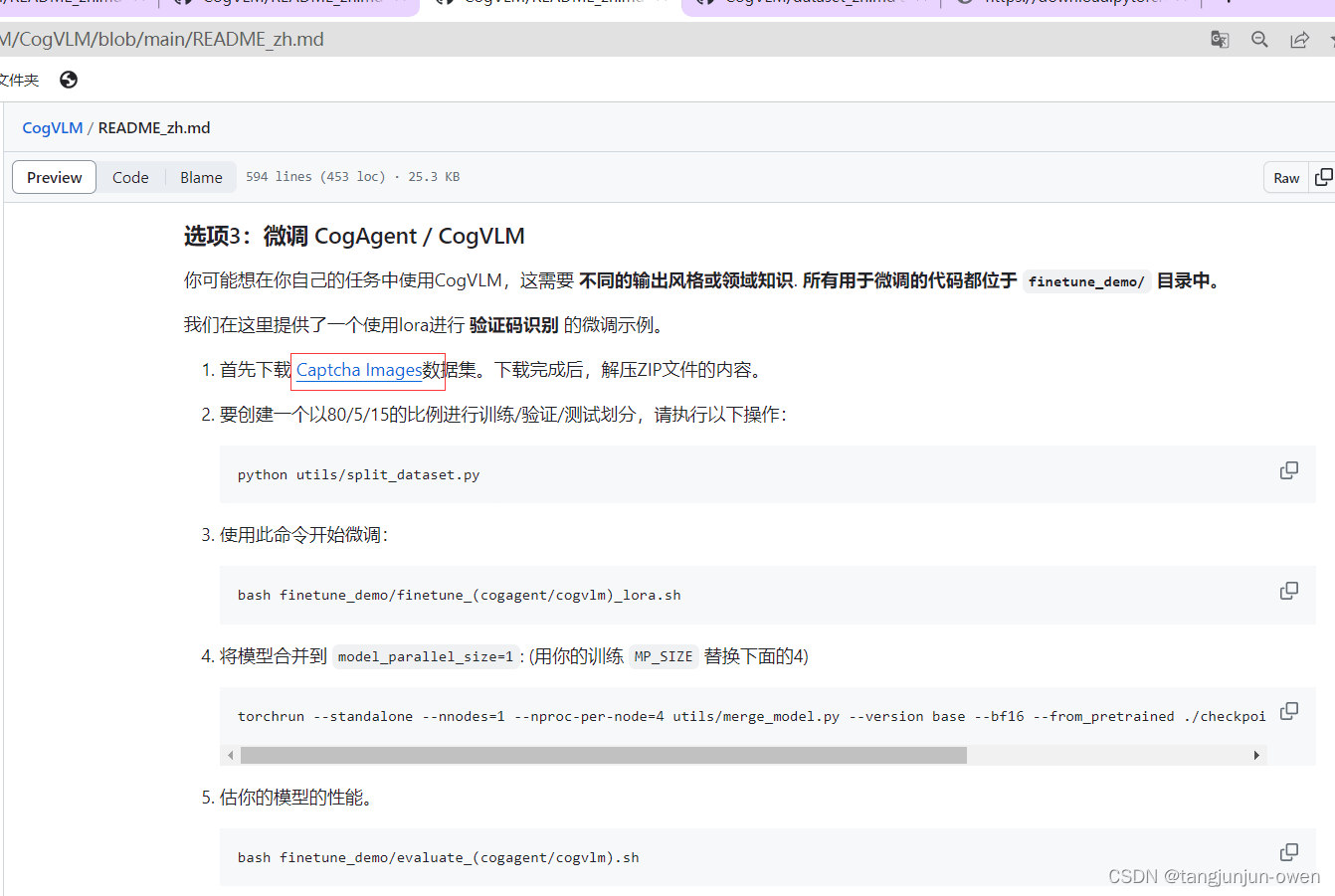
数据参考官网:https://github.com/THUDM/CogVLM/blob/main/README_zh.md
使用下图步骤处理数据,如下:
3、训练模型参数修改
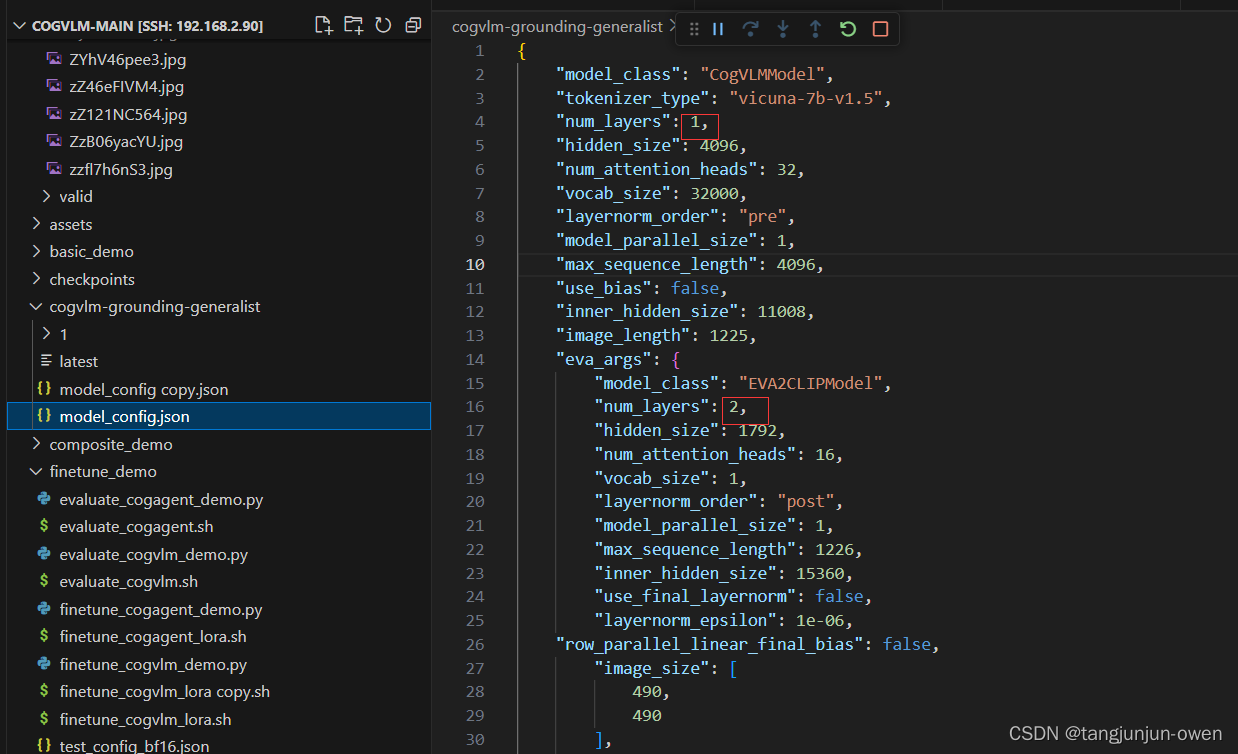
如果你的显卡不足,但又想解读源码,可更改模型文件模型层数,如下红框内容修改,即可实现源码解读。我修改如下,使用cogvlm-grounding-generalist模型,在4090显卡上大约占9个G左右。
4、训练源码解读
finetune源码集成代码文件为finetune_cogvlm_demo.py内,模型加载依然使用from_pretrained,之后和我之前博客点击这里说的类似,我将不在解读。
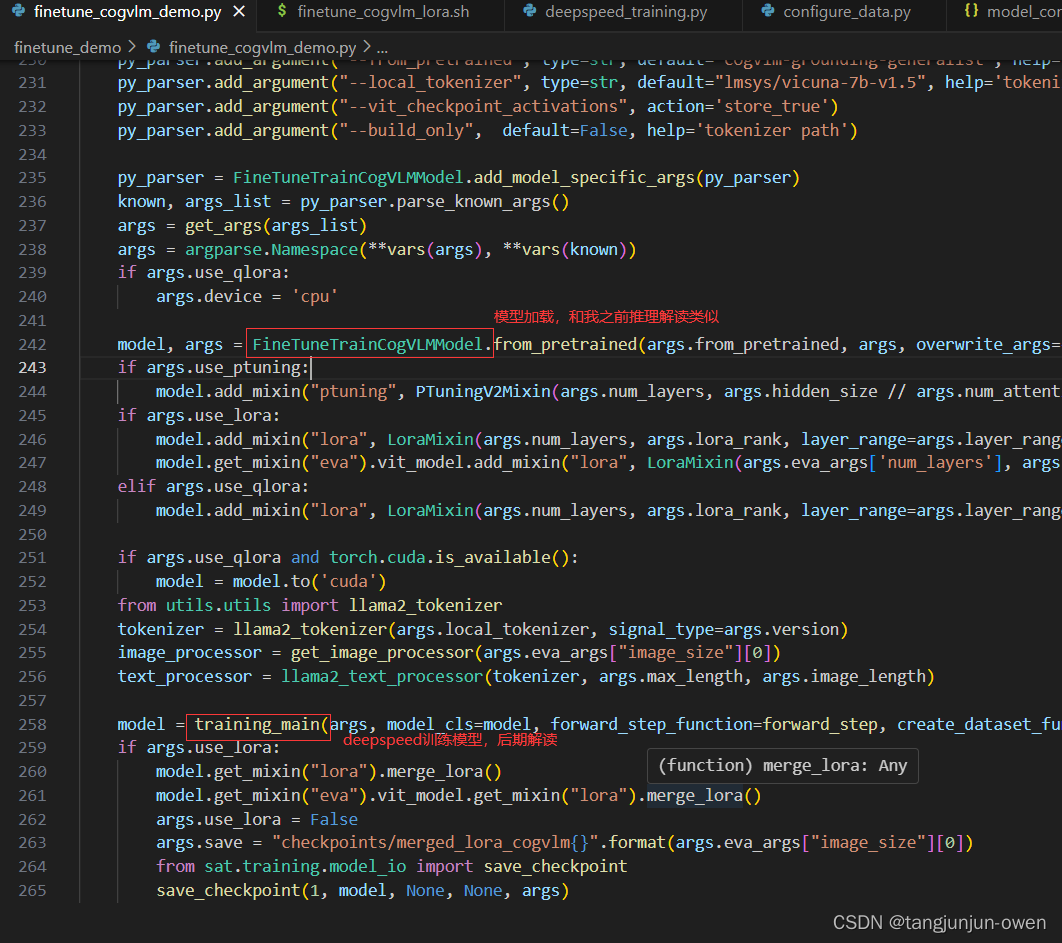
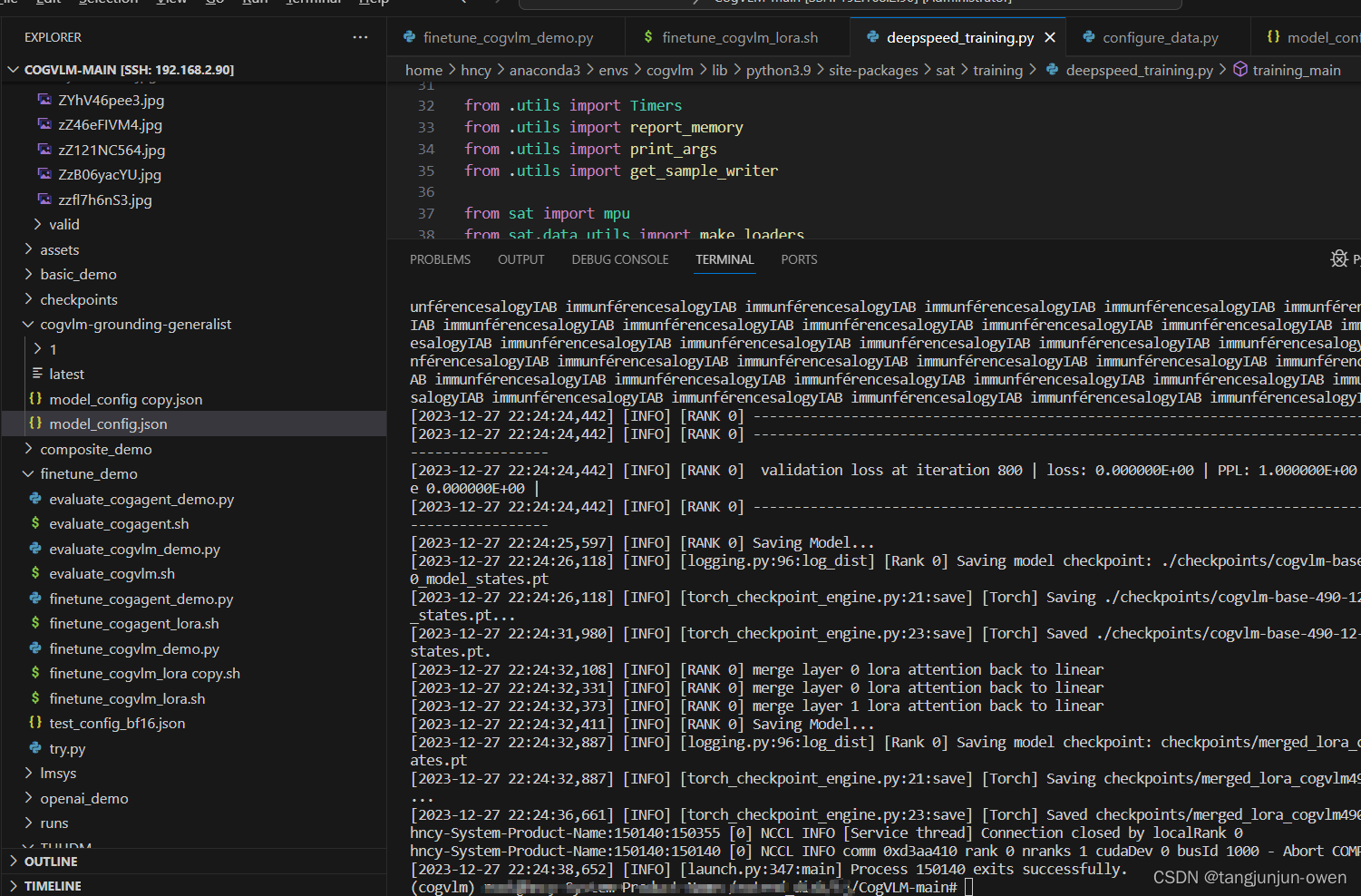
5、训练结果展示
当训练完后,依然会保存和cogvlm-grounding-generalist文件夹一样的内容,值权重值不一样。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!