EVA-CLIP
2024-01-08 15:12:14
Abstract & Introducation
- EVA-CLIP: 一系列显著的提升CLIP训练时的效率和有效性。
- 用最新的表征学习, 优化策略,增强 使得EVA-CLIP在同样数量的参数下比之前的CLIP模型要好,且花费更小的训练资源。
- pre-trained EVA 来初始化CLIP的训练
- the LAMB optimizer
- randomly deopping input tokens
- speedup trick: flash attention
- 在ImageNet-1k val的成绩
- 82% zero-shot accuracy = EVA-02-CLIP-E/14 (5.0B-parameter)+ 9 biilion samples
- 80.4% zero-shot accuracy = EVA-02-CLIP-L/14 (430 million paramters) + 6 billion samples
Approach
- Better Initialization: pre-trained EVA weights to initializa the images encoder of EVA-CLIP
- Optimizer: LAMB, 为large-batch training设计的优化器。 its adaptive elementwise updating and layer-wise learning rates enhance training efficiency and accelerate convergence rates
- FLIP: we randomly mask 50% image tokens during training esulting in a significant reduction of time complexity by half.
Experiments
Settings
- Datasets: 2B = 1.6 billion (LAION-2B) + 0.4 billion (COYO-700M)
- 实验结果一目了然
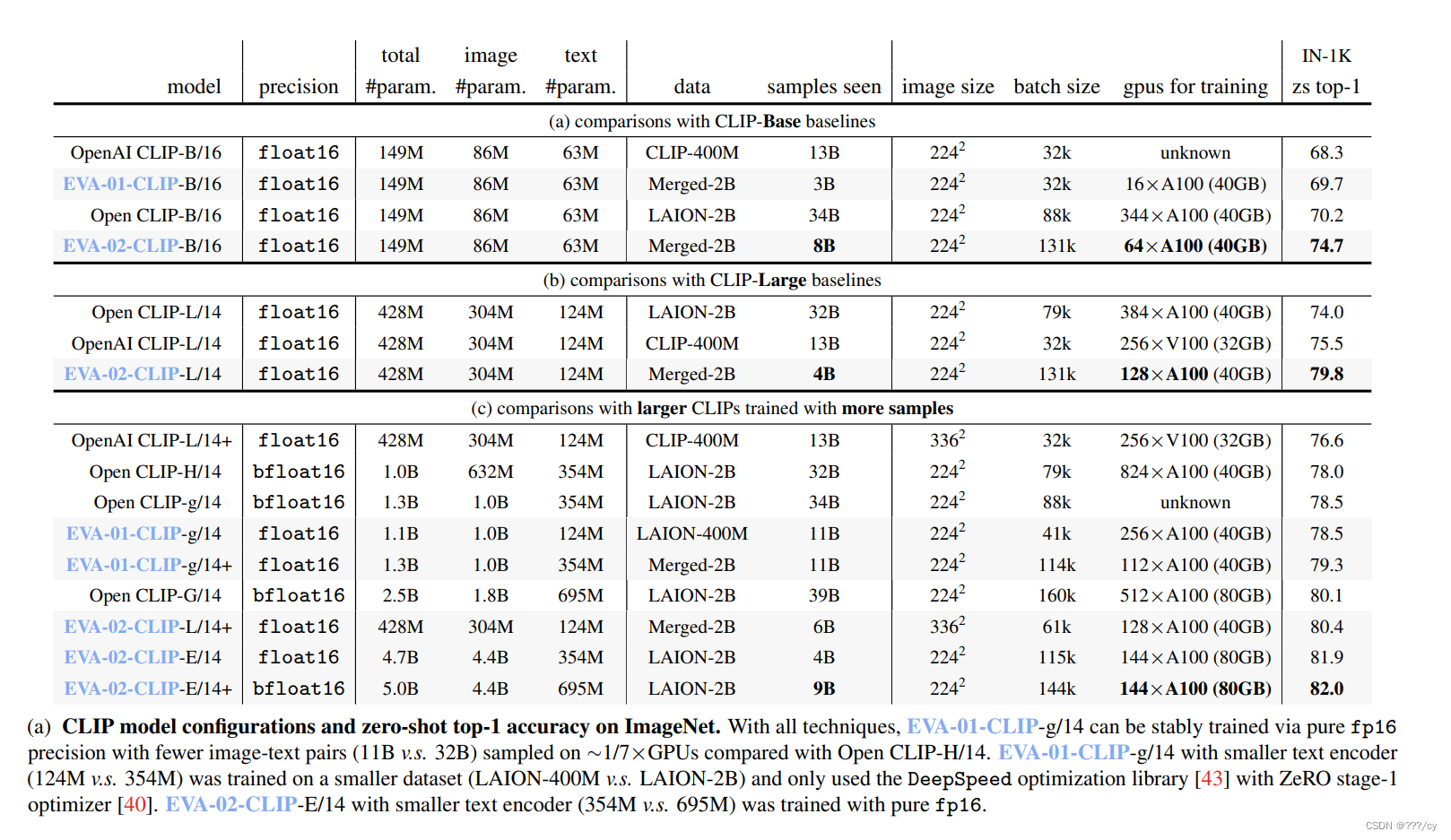
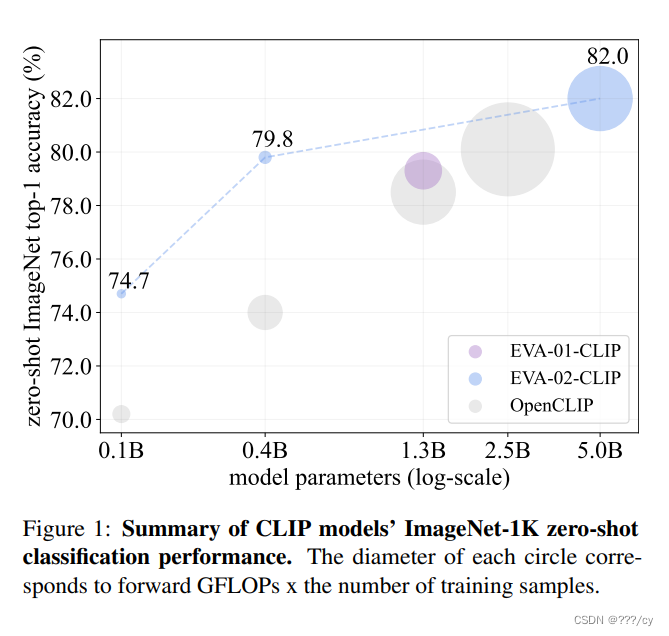
https://arxiv.org/pdf/2303.15389.pdf
文章来源:https://blog.csdn.net/qq_45842681/article/details/135451962
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!