【JVM】对象创建过程
1、对象创建的过程
1、类加载、解析、初始化:虚拟机遇到new时先检查此指令的参数是否能在常量池中找到类的符号引用,并检查符号引用代表的类是否被加载、解析、初始化,若没有则先进行类加载。
2、对象内存分配:类加载检查通过后,虚拟机为新生对象分配内存,对象所需内存大小在类加载完成后便可完全确定。分配内存的任务等同于从堆中分出一块确定大小的内存。(具体分配策略见:JVM内存分配策略-MarchOn)
根据内存是否规整(即用的放一边,空闲的放另一边,是否如此与所使用的垃圾收集器是否带有压缩整理Compact功能有关),分配方式分为指针碰撞(Serial、ParNe等收集器)和空闲列表(CMS收集器等)两种
并发控制:可能多个对象同时从堆中分配内存因此需要同步,两种解决方案:虚拟机用CAS配上失败重试保证原子操作;把内存分配动作按线程划分在不同空间中进行,即每个线程预先分配一块线程本地缓冲区TLAB,各线程在各自TLAB为各自对象分配内存。
3、对象的初始化:对象头和对象实例数据的初始化
2、对象的内存布局
布局:
对象头:标记字(32位虚拟机4B,64位虚拟机8B) + 类型指针(32位虚拟机4B,64位虚拟机8B)+ [数组长(对于数组对象才需要此部分信息)]
实例数据
对齐填充:对于64位虚拟机来说,对象大小必须是8B的整数倍,不够的话需要占位填充
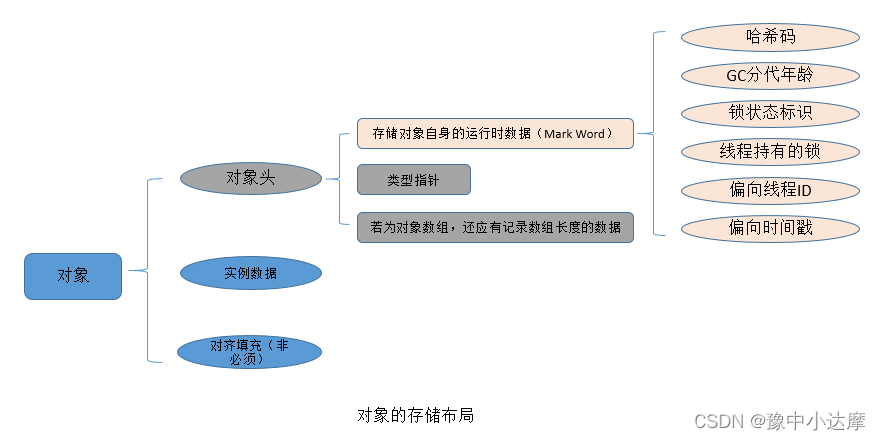
对象头用于存储对象的元数据信息:
Mark Word 部分数据的长度在32位和64位虚拟机(未开启压缩指针)中分别为32bit和64bit,存储对象自身的运行时数据如哈希值等。Mark Word一般被设计为非固定的数据结构,以便存储更多的数据信息和复用自己的存储空间。
类型指针 指向它的类元数据的指针,用于判断对象属于哪个类的实例。
实例数据存储的是真正有效数据,如各种字段内容,各字段的分配策略为longs/doubles、ints、shorts/chars、bytes/boolean、oops(ordinary object pointers),相同宽度的字段总是被分配到一起,便于之后取数据。父类定义的变量会出现在子类定义的变量的前面。
对齐填充部分仅仅起到占位符的作用,并非必须。
示例(以HashMap<Long,Long>为例):
其只有Key和Value是有效数据,共28B=16B,包装成Long对象后分别具有了8B标记字和8B的类型指针,共24B2=48B;两个对象组成Map.Entry后多了16B对象头、一个8B的next字段、4B的int类型的hash字段,还必须添加4B的空白填充。共32B;最后还有对HashMap中对此Entry的8B的引用。所以空间利用率为 16B / (48B+32B+8B) ≈ 18%
32位虚拟机 VS 64位虚拟机:
由于指针膨胀和各种数据类型对齐补白的原因,运行于64位系统上的Java应用需要消耗更多的内存(通常比32位的增加10%~30%的内存开销) ;此外,64位虚拟机的运行速度比32位的大约有15%左右的性能差距。
不过,64位虚拟机也有它的优势:首先能管理更多的内存,32位最多4GB,实际上还受OS允许进程最大内存的限制(Windows下2GB);其次,随着硬件技术的发展,计算机终究会完全过渡到64位,虚拟机也将过渡到64位。
3、对象的访问定位
对象的访问定位也取决于具体的虚拟机实现。当我们在堆上创建一个对象实例后,就要通过虚拟机栈中的reference类型数据来操作堆上的对象。现在主流的访问方式有两种(HotSpot虚拟机采用的是第二种):
使用句柄访问对象。即reference中存储的是对象句柄的地址,而句柄中包含了对象实例数据与类型数据的具体地址信息,相当于二级指针。
直接指针访问对象。即reference中存储的就是对象地址,相当于一级指针。
两种方式有各自的优缺点。当垃圾回收移动对象时,对于方式一而言,reference中存储的地址是稳定的地址,不需要修改,仅需要修改对象句柄的地址;而对于方式二,则需要修改reference中存储的地址。从访问效率上看,方式二优于方式一,因为方式二只进行了一次指针定位,节省了时间开销,而这也是HotSpot采用的实现方式。下图是句柄访问与指针访问的示意图。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!