R语言——R函数、选项参数、数学统计函数(六)
目录
一、R函数

1.lm()
lm()是R语言中经常用到的函数,用来拟合回归模型。它是拟合线性模型最基本的函数
lm()格式如下:
fit<-lm(formula,data)其中,formula指要拟合的模型形式,data是一个数据框,包含了用于拟合模型的数据。结果对象(本例中是fit)存储在一个列表中,包含了所拟合模型的大量信息。表达式(formula)形式如下:
Y~X1+X2..Xn举例,输入:
a<-c(1,2,3,4,5)
b<-c(2,4,6,8,10)
mydata<-data.frame(a,b)
fit<-lm(a~b,mydata)
summary(fit)结果会显示: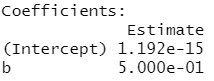
所以a,b的关系可表示为:
a=0.000000000000001192+0.5*b
2.函数返回值及输入数据格式
????????使用函数时要注意函数的返回值类型,比如有些函数返回值是列表,那就不能将其运用到使用向量的环境中。
????????有些函数只能处理矩阵,有些函数既能处理矩阵也能处理数据框,使用函数时,需要知道每个函数的输入数据格式,否则就会出错。
输入数据类型
向量:sum,mean,sd,range,median,sort,order
矩阵或数据框:cbind,rbind
数字矩阵:heatmap
3.使用help(函数名)可以查看函数的帮助文档。
二、选项参数
一般的选项函数可以分为三部分:输入控制部分、输出控制部分以及调节部分。
- 输入控制选项
常用选项:
file:接一个文件data:一般指要输入一个数据框
x:表示单独的一个对象,一般都是向量,也可以是矩阵或者列表
x和y:函数需要两个输入变量
x,y,z:函数需要三个输入变量
formula:公式
na.rm:删除缺失值
- 输出控制选项:在R中,函数一般都是屏幕输出结果,每个函数的返回值也比较固定,所以输出控制选项并不多。
- 调节参数
调节参数
1.根据名字判断选项的作用
color:选项明显用来控制颜色
select:与选择有关
font:与字体有关
font.axis:就是坐标轴的字体
lty:是 line type
lwd:是 line width
method:软件算法
2.选项接受哪些参数
main:字符串,不能是向量
na.rm:TRUE 或者 FALSE
axis:side参数只能是1到4
fig:包含四个元素的向量
三、数学统计函数
1.概率统计函数
R概率分布:
d 概率密度函数
p 分布函数
q 分布函数的反函数
r 产生相同分布的随机数
正态分布函数:
dnorm(x,mean,sd,log)
pnorm(q,mean,sd,lower.tail,log.p)
qnorm(p,mean,sd,lower.tail,log.p)
rnorm(n,mean,sd)
与离散分布相关的函数:

与正态分布一样,在每种分布名称前面加上d、p、q、r就可以构成函数名。
如:
dgeom(x,prob,log=FALSE)
pgeom(q,prob,lower.tail=TRUE,log.p=FALSE)
qgeom(p,prob,lower.tail=TRUE,log.p=FALSE)
rgeom(n,prob)
runif(n):随机生成n个0到1之间的数。
runif(n,min=1,max=100):随机生成n个从1到100之间的随机数。
2.描述性统计函数
summary函数:
mycars <- mtcars[c("mpg","hp","wt","am")]
summary(mycars)
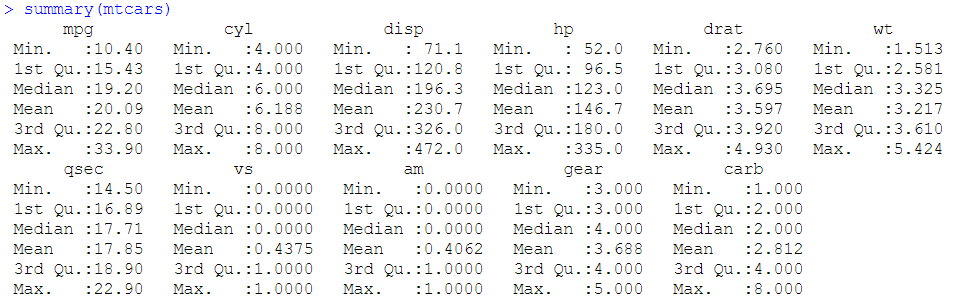
fivenum函数:与summary函数类似
fivenum(mycars$hp)
Hmisc包中的describe函数:
describe(mycars)
pastecs包中stat.desc函数:计算种类繁多的描述性统计量,参数x是一个数据框或时间序列
stat.desc(mycars)
psych包中describe函数:
describe(mycars)
describe(mycars,trim=0.1) #去掉10%的最低值最高值部分
很多情况下,我们需要对数据进行分组描述,这时候可以使用aggregate函数,aggregate函数能够对数据按照指定的分组信息进行统计,将分组信息通过一个列表指定出来:
library(MASS)
aggregate(Cars93[c("Min.Price","Price","Max.Price","MPG.city")],by=list(Manufacturer=Cars93$Manufacturer),mean)
aggregate函数的缺点是一次只能计算一个统计函数。
使用doBy包中的summaryBy函数:
summaryBy(mpg+hp+wt~am,data=mycars,FUN=mean)
使用psych包中的describeBy函数:
describeBy(mycars,list(am=mycars$am))
3.频数统计函数
(1)一维
mtcars$cyl <- as.factor(mtcars$cyl)
split(mtcars,mtcars$cyl) #结果按照cyl分类
table(mtcars$cyl) #频数统计
table(cut(mtcars$mpg,c(seq(10,50,10)))) #频数统计
prop.table(table(mtcars$cyl)) #频率值,即频数除以总数
(2)二维:返回列联表
library(vcd)
table(Arthritis$Treatment,Arthritis$Improved) #统计两个量的频数,返回的结果是一个二维的列联表
或者
with(data = Arthritis,table(Treatment,Improved))
或者
xtabs(~Treatment+Improved,data = Arthritis)
(3)对列联表进行边际频数统计
边际频数统计:
x <- xtabs(~Treatment+Improved,data = Arthritis)
margin.table(x,1) #按行进行边际频数统计
margin.table(x,2) #按列进行边际频数统计
边际频率统计:
prop.table(x,1) #按行进行边际频率统计
prop.table(x,2) #按列进行边际频率统计
将边际频数的和添加到频数表中:
addmargins(x)
addmargins(x,1)
addmargins(x,2)
(4)三维
y <- xtabs(~Treatment+Improved+Sex,data = Arthritis)
ftable(y) #将结果转换为一个评估式的列联表
四、参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!