【大数据】Hadoop生态未来发展的一些看法
大数据的起源
谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代,被称为Google的三驾马车
?大数据的价值

而算来大数据已经快发展到20年,而在近几年吹的比较热的数据中台也在慢慢变得去中台化,从Gartner发布的技术成熟度曲线图来看,数据中台未成熟即面临淘汰
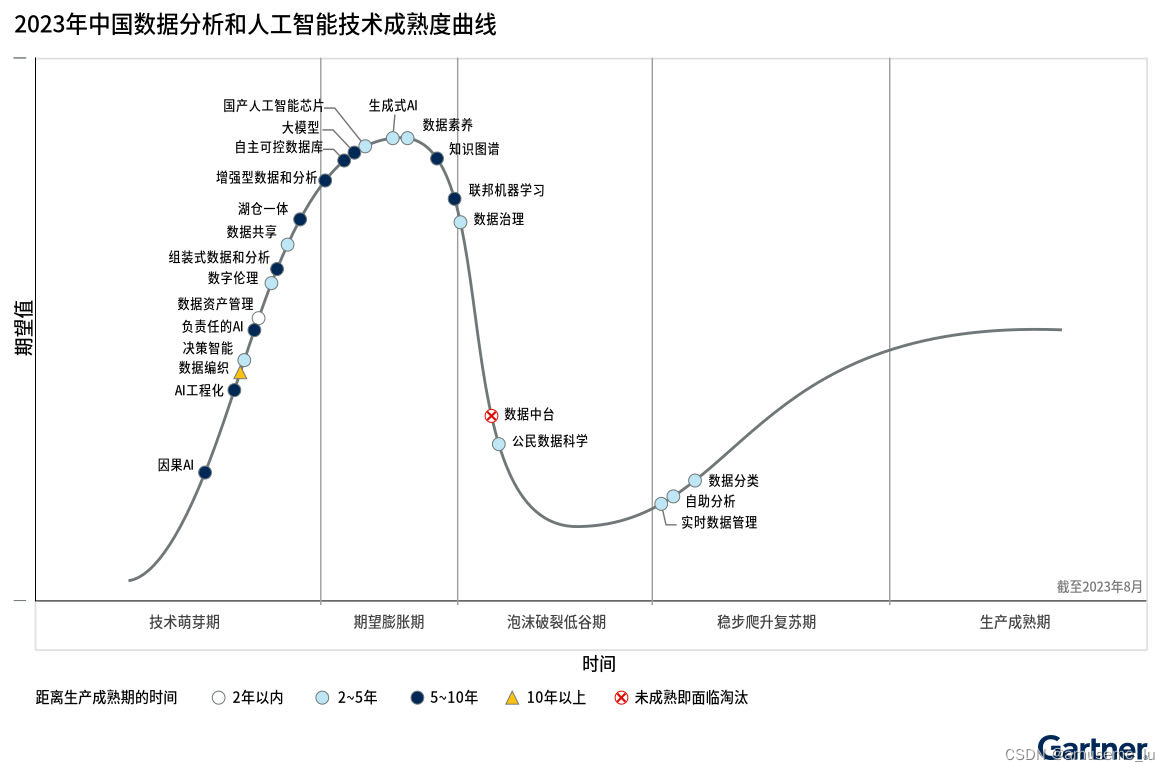
?
Hadoop生态成功的核心价值还是在一个中心化的平台上实现跨业务的数据分析、挖掘工作,依托海量数据找到以前不可能做到的规律和相关性,为业务提供有价值的数据分析结果。

当越来越多的人意识到这种价值的时候,就有了开源和商业分析平台的出现,开源以Hadoop生态以主,而国外商业公司以Cloudera和Hortonworks为主,而在2018年,这两家公司的合并宣告着整个分析工具平台的统一

整个Hadoop的关注度也在降低,一个原因是技术已经相对比较成熟,另外市场覆盖度也比较大了,类似十几年前的操作系统,慢慢这些组件都会成为下一个操作系统或操作系统内核,提供了成熟、稳定的版本更新

后hadoop时代的一些看法
存储系统:
- 数据的多化性需求导致了对象存储系统的爆发,如MinIO、SeaweedFS和基于HDFS的Zone等系统,还有一批融合了结构化与非结构化数据存储的数据湖系统
- 人工智能的爆发导致对于存储的时延、带宽要求越来越高,催生出了一批为高性能数据处理场景设计的系统,如JuiceFS、Alluxio等系统
调度系统:
- 人工智能的发展催生了除CPU外的GPU、NPU等异构资源的管理,包括Yarn和K8s的功能也越来越接近,越来越一致,也会逐步吃掉原来属于高性能计算调度引擎Slurm的部分市场
- 调度系统也支持不同的计算框架,如Spark、Flink、Pytorch、Tensorflow等
计算系统:
- 随着处理实效的要求越来越高,计算会从批处理向实时处理方向发展,或者统一到实时处理框架,如Spark或Flink等
- 随时人工智能的发展,人工智能计算框架也会逐步融入到大数据的体系中
整体来看,随着后Hadoop时代,大数据生态技术慢慢会成为像操作系统一样的稳定软件,公司的普及率也会越来越大,不管是使用公有云提供的服务,还是使用成熟的商业化产品,所带来的企业使用成本也会相对降低,也推动企业数字化转型的速度和力度,所以未来我们应该更关注在使用这些工具能给业务带来的价值,类似我们在一个成熟的操作系统上能开发出多少能真正给企业、人个产生价值的App,这些才能我们未来需要关注的点。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!