【无标题】
2023-12-25 23:27:56
安装依赖
pip install transformers==4.32.0
pip install accelerate
pip install tiktoken
pip install einops
pip install transformers_stream_generator==0.0.4
pip install scipy
pip install auto-gptq optimum
使用
模型
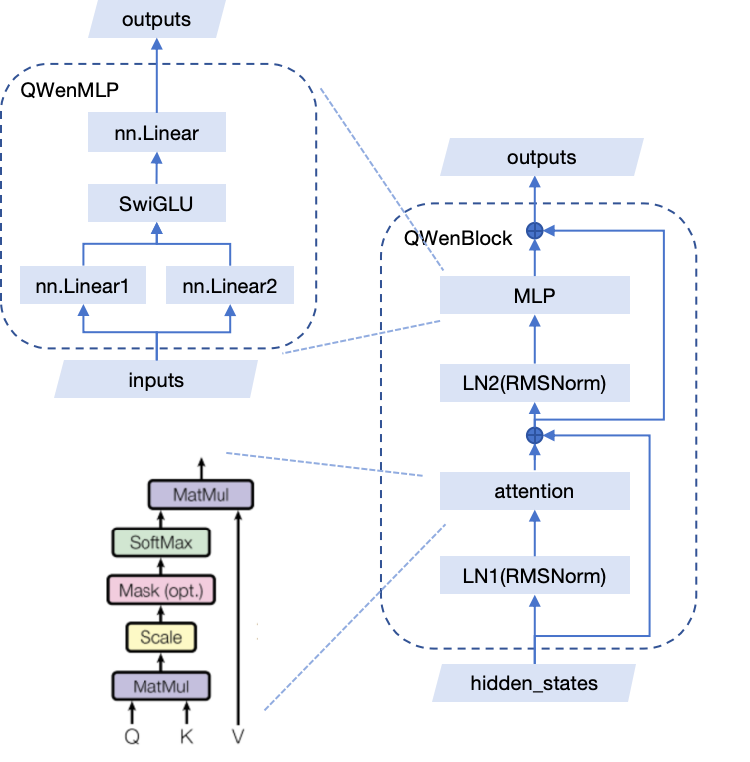
模型结构
QwenBlock
打印模型
## 用了Qlora
PeftModelForCausalLM(
(base_model): LoraModel(
(model): QWenLMHeadModel(
(transformer): QWenModel(
(wte): Embedding(151936, 4096)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0-31): 32 x QWenBlock(
(ln_1): RMSNorm()
(attn): QWenAttention(
(c_attn): Linear4bit(
in_features=4096, out_features=12288, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(c_proj): Linear4bit(
in_features=4096, out_features=4096, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(rotary_emb): RotaryEmbedding()
(attn_dropout): Dropout(p=0.0, inplace=False)
)
(ln_2): RMSNorm()
(mlp): QWenMLP(
(w1): Linear4bit(
in_features=4096, out_features=11008, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=11008, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(w2): Linear4bit(
in_features=4096, out_features=11008, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=11008, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(c_proj): Linear4bit(
in_features=11008, out_features=4096, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=11008, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
)
)
)
(ln_f): RMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=151936, bias=False)
)
)
)
head对应的数据类型
base_model.model.transformer.h.7.ln_1.weight torch.float32
base_model.model.transformer.h.7.attn.c_attn.weight torch.uint8
base_model.model.transformer.h.7.attn.c_attn.bias torch.bfloat16
base_model.model.transformer.h.7.attn.c_attn.lora_A.default.weight torch.bfloat16
base_model.model.transformer.h.7.attn.c_attn.lora_B.default.weighttorch.bfloat16
base_model.model.transformer.h.7.attn.c_proj.weight torch.uint8
base_model.model.transformer.h.7.attn.c_proj.lora_A.default.weight torch.bfloat16
base_model.model.transformer.h.7.attn.c_proj.lora_B.default.weight torch.bfloat16
base_model.model.transformer.h.7.ln_2.weight torch.float32
base_model.model.transformer.h.7.mlp.w1.weight torch.uint8
base_model.model.transformer.h.7.mlp.w1.lora_A.default.weight torch.bfloat16
base_model.model.transformer.h.7.mlp.w1.lora_B.default.weight torch.bfloat16
base_model.model.transformer.h.7.mlp.w2.weight torch.uint8
base_model.model.transformer.h.7.mlp.w2.lora_A.default.weight torch.bfloat16
base_model.model.transformer.h.7.mlp.w2.lora_B.default.weight torch.bfloat16
base_model.model.transformer.h.7.mlp.c_proj.weight torch.uint8
base_model.model.transformer.h.7.mlp.c_proj.lora_A.default.weight torch.bfloat16
base_model.model.transformer.h.7.mlp.c_proj.lora_B.default.weight torch.bfloat16
源码分析
QWenBlock
class QWenBlock(nn.Module):
def __init__(self, config):
super().__init__()
hidden_size = config.hidden_size
self.bf16 = config.bf16
self.ln_1 = RMSNorm(
hidden_size,
eps=config.layer_norm_epsilon,
)
self.attn = QWenAttention(config)
self.ln_2 = RMSNorm(
hidden_size,
eps=config.layer_norm_epsilon,
)
self.mlp = QWenMLP(config)
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
rotary_pos_emb: Optional[List[torch.Tensor]] = None,
registered_causal_mask: Optional[torch.Tensor] = None,
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
):
layernorm_output = self.ln_1(hidden_states)
attn_outputs = self.attn(
layernorm_output,
rotary_pos_emb,
registered_causal_mask=registered_causal_mask,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0]
outputs = attn_outputs[1:]
residual = hidden_states
layernorm_input = attn_output + residual
layernorm_output = self.ln_2(layernorm_input)
residual = layernorm_input
mlp_output = self.mlp(layernorm_output)
hidden_states = residual + mlp_output
if use_cache:
outputs = (hidden_states,) + outputs
else:
outputs = (hidden_states,) + outputs[1:]
return outputs
forword函数的参数:
- hidden_states:一个可选的元组,包含了上一层的输出张量,形状为(batch_size, sequence_length, hidden_size)
- rotary_pos_emb:一个可选的列表,包含了旋转位置编码张量,形状为(batch_size, sequence_length, hidden_size)
- registered_causal_mask:一个可选的张量,用于注册因果掩码,防止模型看到未来的信息。形状为(batch_size, sequence_length, sequence_length)。
- layer_past:一个可选的元组,包含了上一层的注意力键值对张量,用于实现缓存机制,加速生成过程。形状为(2, batch_size, num_heads, sequence_length, head_dim)。
- attention_mask:一个可选的浮点张量,用于对输入序列进行掩码,忽略无效的位置或填充部分。形状为(batch_size, sequence_length)或(batch_size, 1, 1, sequence_length)。
- head_mask:一个可选的浮点张量,用于对注意力头进行掩码,随机删除一些头以增加模型的鲁棒性。形状为(num_heads,)或(1, 1, num_heads, 1)。
- encoder_hidden_states:一个可选的张量,用于实现编码器-解码器结构时,传递编码器的输出给解码器。形状为(batch_size, encoder_sequence_length, hidden_size)。
- encoder_attention_mask:一个可选的浮点张量,用于实现编码器-解码器结构时,对编码器输出进行掩码。形状为(batch_size, encoder_sequence_length)或(batch_size, 1, 1, encoder_sequence_length)。
- use_cache:一个可选的布尔值,用于指示是否使用缓存机制。
- output_attentions:一个可选的布尔值,用于指示是否输出注意力权重张量。
RMSNorm
QWenMLP
class QWenMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.w1 = nn.Linear(
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
)
self.w2 = nn.Linear(
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
)
ff_dim_in = config.intermediate_size // 2
self.c_proj = nn.Linear(ff_dim_in, config.hidden_size, bias=not config.no_bias)
def forward(self, hidden_states):
a1 = self.w1(hidden_states)
a2 = self.w2(hidden_states)
intermediate_parallel = a1 * F.silu(a2)
output = self.c_proj(intermediate_parallel)
return output
QWenAttention
class QWenAttention(nn.Module):
def __init__(self, config, layer_number=None):
super().__init__()
self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)
self.seq_length = config.seq_length
self.hidden_size = config.hidden_size
self.split_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.use_flash_attn = config.use_flash_attn
self.scale_attn_weights = True # scale_attn_weights:布尔标志,表示是否对注意力权重进行缩放
self.projection_size = config.kv_channels * config.num_attention_heads # projection_siz:投影的大小
assert self.projection_size % config.num_attention_heads == 0
self.hidden_size_per_attention_head = (
self.projection_size // config.num_attention_heads
)
self.c_attn = nn.Linear(config.hidden_size, 3 * self.projection_size)
self.c_proj = nn.Linear(
config.hidden_size, self.projection_size, bias=not config.no_bias
)
self.is_fp32 = not (config.bf16 or config.fp16)
if (
self.use_flash_attn
and flash_attn_unpadded_func is not None
and not self.is_fp32
):
self.core_attention_flash = FlashSelfAttention(
causal=True, attention_dropout=config.attn_pdrop
)
self.bf16 = config.bf16
self.use_dynamic_ntk = config.use_dynamic_ntk
self.use_logn_attn = config.use_logn_attn
logn_list = [
math.log(i, self.seq_length) if i > self.seq_length else 1
for i in range(1, 32768)
]
logn_tensor = torch.tensor(logn_list)[None, :, None, None]
self.register_buffer("logn_tensor", logn_tensor, persistent=False)
self.attn_dropout = nn.Dropout(config.attn_dropout_prob)
self.softmax_in_fp32 = config.softmax_in_fp32 if hasattr(config, 'softmax_in_fp32') else False
self.use_cache_quantization = config.use_cache_quantization if hasattr(config, 'use_cache_quantization') else False
self.use_cache_kernel = config.use_cache_kernel if hasattr(config,'use_cache_kernel') else False
cache_dtype = torch.float
if self.bf16:
cache_dtype=torch.bfloat16
elif config.fp16:
cache_dtype = torch.float16
self.cache_qmax = torch.tensor(torch.iinfo(torch.uint8).max, dtype=cache_dtype)
self.cache_qmin = torch.tensor(torch.iinfo(torch.uint8).min, dtype=cache_dtype)
if config.use_cache_quantization and config.use_cache_kernel:
from .cpp_kernels import cache_autogptq_cuda_256
try:
self.cache_kernels = cache_autogptq_cuda_256
except ImportError:
self.cache_kernels = None
注意力计算
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights: # 对注意力权重进行缩放
attn_weights = attn_weights / torch.full(
[],
value.size(-1) ** 0.5,
dtype=attn_weights.dtype,
device=attn_weights.device,
)
query_length, key_length = query.size(-2), key.size(-2)
causal_mask = self.bias[
:, :, key_length - query_length : key_length, :key_length
]
mask_value = torch.finfo(attn_weights.dtype).min
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(
attn_weights.device
)
attn_weights = torch.where(
causal_mask, attn_weights.to(attn_weights.dtype), mask_value
)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
attn_weights = attn_weights.type(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
if head_mask is not None:
attn_weights = attn_weights * head_mask
attn_output = torch.matmul(attn_weights, value)
attn_output = attn_output.transpose(1, 2)
return attn_output, attn_weights
RotaryEmbedding
待补充
参考文献:
文章来源:https://blog.csdn.net/Elvira521yan/article/details/135210133
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!