Synchronized 优化
目录
前言
Java synchronized 是一种机制,可以保证多个线程在访问共享资源时的同步性。synchronized 关键字可以用于方法或代码块上,当一个线程获取了这个对象的锁后,其他线程如果也要获取这个锁的话就必须等待该线程释放锁。这样可以保证共享资源的访问顺序和正确性,避免数据竞争和死锁等问题。
重点
?
同步的重点在于确保多线程环境下的数据一致性和程序正确性。当多个线程同时访问共享资源时,如果没有适当的同步机制,可能会导致数据损坏、不一致的结果以及其他并发问题。以下是同步的重点:
互斥访问: 同步的主要目标是防止多个线程同时访问共享资源,从而避免数据损坏。通过使用锁机制,只有一个线程能够获得对资源的访问权,其他线程必须等待。
防止竞态条件: 竞态条件是指多个线程竞争同时修改共享数据的情况,可能导致不可预测的结果。同步确保在任何时刻只有一个线程能够修改共享资源,从而避免竞态条件。
确保原子性操作: 在某些情况下,需要确保某个操作是原子性的,即不可分割的。同步可以用来保证这些操作的原子性,以防止其他线程在操作进行过程中对其进行干扰。
保护临界区: 临界区是指包含对共享资源进行访问或修改的代码块。同步确保在任何时刻只有一个线程能够进入临界区,防止多个线程同时执行可能引起问题的代码。
避免死锁: 同步的设计需要注意避免死锁,即多个线程因为互相等待对方释放资源而无法继续执行的情况。合理的同步设计和锁的使用是避免死锁的关键。
一、?轻量级锁
轻量级锁是为了解决在多线程环境中对同一数据进行并发访问时的性能问题而设计的一种锁优化机制。它主要针对的是线程交替执行同步块的场景,而不是真正的多线程竞争。轻量级锁的设计思想是尽量减小锁的操作对性能的影响,避免使用传统的重量级锁(如synchronized)时引入的较大性能开销。
轻量级锁的基本思路是,在没有线程竞争的情况下,通过将对象头中的一部分空间作为锁存储线程ID,从而避免了传统锁中使用互斥量(mutex)的开销。如果多个线程同时尝试获取锁,会升级为重量级锁,以保证数据的正确性。
以下是一个简单的Java代码示例,演示了轻量级锁的使用:
public class LightWeightLockExample {
private static class Counter {
private int count = 0;
public void increment() {
synchronized (this) { // 这里的锁是轻量级锁
count++;
}
}
public int getCount() {
synchronized (this) {
return count;
}
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
// 创建两个线程,分别对计数器进行操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
// 启动线程
thread1.start();
thread2.start();
// 等待两个线程执行完毕
thread1.join();
thread2.join();
// 输出最终计数结果
System.out.println("Final Count: " + counter.getCount());
}
}
?
在上述代码中,Counter类包含了一个计数器变量 count,并提供了两个方法 increment 和 getCount。increment 方法在对 count 进行操作时使用了 synchronized 关键字,这意味着它使用了轻量级锁。两个线程分别调用 increment 方法对计数器进行增加,最终输出计数结果。
需要注意的是,轻量级锁的具体实现是依赖于具体的JVM实现的。在不同的JVM中,轻量级锁的表现可能有所不同,但它的基本思想是一致的。
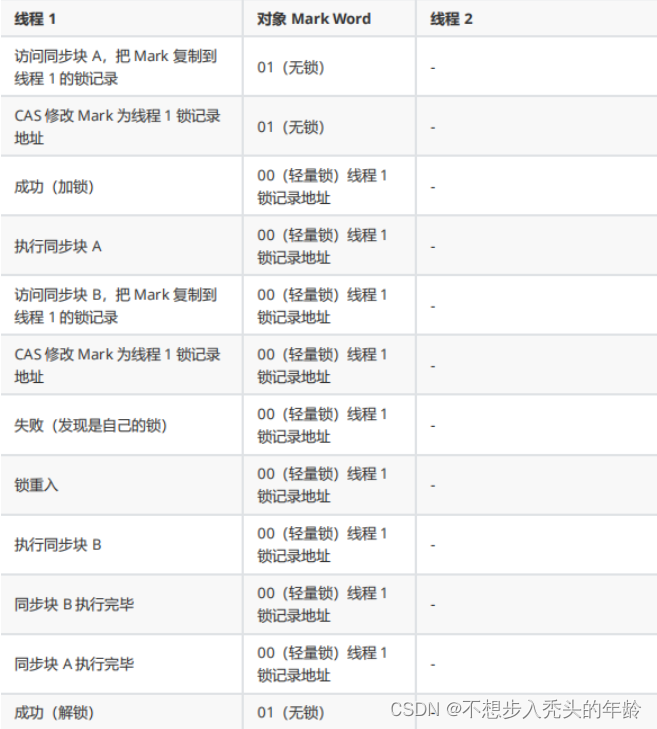
二、锁膨胀?
锁膨胀是指在多线程环境下,一开始使用了较轻量的锁,但随着线程竞争的增加,锁会逐渐升级为更重量级的锁。锁膨胀的目的是在高并发的情况下更好地平衡性能和线程安全。Java中的锁膨胀通常表现为从偏向锁到轻量级锁,再到重量级锁的升级过程。
以下是锁膨胀的一般过程:
-
偏向锁(Biased Locking): 当对象被创建时,它的锁状态为偏向锁。此时假定只有一个线程会访问该对象,因此将该线程的ID记录在对象头中,这样在未发生竞争时,线程访问对象时无需进行同步操作。偏向锁适用于只有一个线程访问对象的情况。
-
轻量级锁(Lightweight Locking): 当有多个线程尝试获取同一对象的锁时,偏向锁会升级为轻量级锁。轻量级锁使用CAS(Compare and Swap)操作来尝试获取锁,避免了传统的互斥量的开销。如果CAS操作失败,表示存在竞争,则升级为重量级锁。
-
重量级锁(Heavyweight Locking): 当轻量级锁无法满足多线程的并发需求时,锁会进一步升级为重量级锁。重量级锁使用操作系统提供的互斥量机制,确保在任何时刻只有一个线程能够获取锁,从而保证数据的正确性。
以下是一个简单的Java代码示例,演示了锁膨胀的过程:
public class LockEscalationExample {
private static class Counter {
private int count = 0;
public synchronized void increment() { // 初始为偏向锁,然后升级为轻量级锁,最后可能升级为重量级锁
count++;
}
public int getCount() {
synchronized (this) {
return count;
}
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
// 创建两个线程,分别对计数器进行操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
// 启动线程
thread1.start();
thread2.start();
// 等待两个线程执行完毕
thread1.join();
thread2.join();
// 输出最终计数结果
System.out.println("Final Count: " + counter.getCount());
}
}
在这个例子中,Counter类的 increment 方法使用了 synchronized 关键字,最初是偏向锁。但由于多个线程并发访问,最终可能升级为轻量级锁,甚至进一步升级为重量级锁,以确保数据的一致性。需要注意的是,锁膨胀的过程是由JVM自动管理的,程序员不需要手动介入。
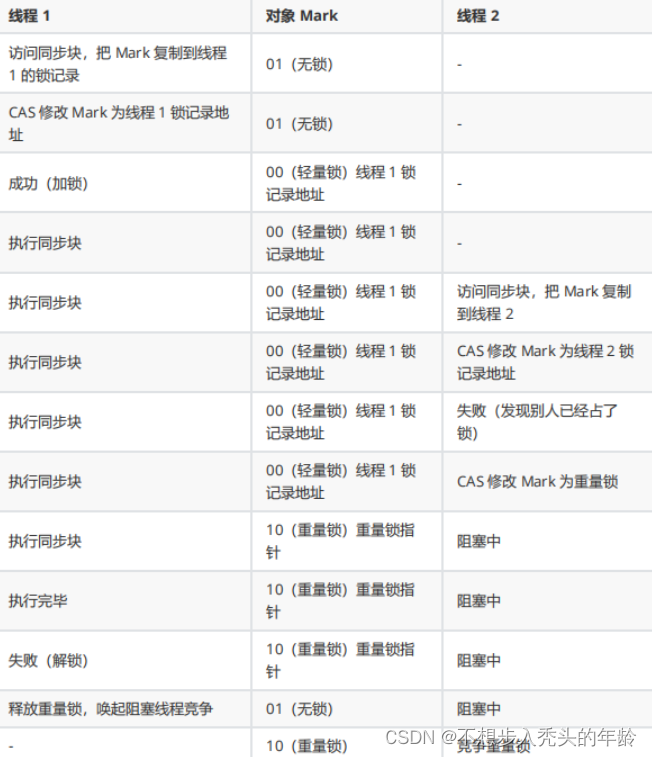
三、重量锁
重量级锁(Heavyweight Lock)是一种用于多线程同步的锁机制,通常是通过互斥量(mutex)来实现。当多个线程竞争同一资源时,重量级锁能够确保在任何时刻只有一个线程能够访问共享资源,从而避免数据的不一致性和竞态条件。
重量级锁的主要特点包括:
-
互斥量: 重量级锁通常使用操作系统提供的互斥量机制,这是一种在操作系统层面上实现的同步机制。在Java中,
synchronized关键字就是使用重量级锁来实现同步的一种方式。 -
阻塞等待: 当一个线程获得了重量级锁后,其他线程如果尝试获得相同的锁,它们会被阻塞,直到持有锁的线程释放锁。这种阻塞等待的机制确保了对共享资源的互斥访问。
-
高开销: 由于涉及到操作系统层面的互斥量操作,重量级锁的开销相对较高。这包括线程的上下文切换、内核态和用户态的切换等。
下面是一个简单的Java代码示例,演示了重量级锁的使用:
public class HeavyweightLockExample {
private static class Counter {
private int count = 0;
public synchronized void increment() { // 使用synchronized关键字,引入重量级锁
count++;
}
public int getCount() {
synchronized (this) {
return count;
}
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
// 创建两个线程,分别对计数器进行操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
// 启动线程
thread1.start();
thread2.start();
// 等待两个线程执行完毕
thread1.join();
thread2.join();
// 输出最终计数结果
System.out.println("Final Count: " + counter.getCount());
}
}
?在这个例子中,Counter类的 increment 方法和 getCount 方法都使用了 synchronized 关键字,这意味着它们都会引入重量级锁,以确保对计数器的操作是线程安全的。这样,每次只有一个线程能够执行 increment 或 getCount 中的同步代码块,确保了对计数器的互斥访问。
四、偏向锁
偏向锁是Java中用于提高单线程访问同步块性能的锁优化机制。它假设在大多数情况下,锁是由同一个线程多次获得的,因此可以为第一次获取锁的线程提供一种特殊的优化。
以下是偏向锁的主要特点:
-
偏向线程: 当一个线程第一次进入同步块时,偏向锁会记录该线程的ID,并将对象头中的偏向线程字段设为该线程的ID。此时这个线程处于偏向模式。
-
无竞争情况下的快速获取: 在偏向模式下,当同一个线程再次进入同步块时,不需要进行任何额外的同步操作,因为偏向线程已经被记录。这使得同一个线程多次获得锁的情况下,不会引入额外的性能开销。
-
竞争时的撤销: 当有其他线程尝试获取同一把锁时,偏向锁就不能满足“偏向”了。此时,会撤销偏向模式,升级为轻量级锁。这个过程会涉及到CAS(Compare and Swap)操作,确保多个线程之间的竞争是公平的。
-
减小锁撤销的概率: 为了减小锁撤销的概率,JVM会在撤销偏向锁时判断是否有其他线程访问过这个对象。如果没有,就直接将对象头的偏向线程字段置为0,不进行锁升级,以避免不必要的开销。
以下是一个简单的Java代码示例,演示了偏向锁的使用:
public class BiasedLockExample {
private static class Counter {
private int count = 0;
public synchronized void increment() { // 初始为偏向锁
count++;
}
public int getCount() {
synchronized (this) {
return count;
}
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
// 创建两个线程,分别对计数器进行操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
counter.increment();
}
});
// 启动线程
thread1.start();
thread2.start();
// 等待两个线程执行完毕
thread1.join();
thread2.join();
// 输出最终计数结果
System.out.println("Final Count: " + counter.getCount());
}
}
在这个例子中,Counter类的 increment 方法和 getCount 方法都使用了 synchronized 关键字,最初是偏向锁。由于在这个例子中只有一个线程在访问同步块,因此偏向锁会提高性能,避免了多线程竞争的开销。
五、其他优化
除了偏向锁之外,Java虚拟机还有其他一些锁优化策略和技术,以提高多线程程序的性能。以下是一些常见的锁优化技术:
-
轻量级锁(Lightweight Lock): 在多线程并发访问时,轻量级锁通过CAS(Compare and Swap)操作来避免传统锁的互斥开销,以提高性能。如果轻量级锁获取失败,会升级为重量级锁。
-
自旋锁(Spin Lock): 自旋锁是一种避免线程阻塞的锁机制。当一个线程尝试获取锁时,如果锁已经被其他线程占用,该线程不会立即阻塞,而是会进行一定次数的自旋等待,期望其他线程能够尽快释放锁。
-
适应性自旋锁: 为了更好地适应不同的运行环境,一些虚拟机实现引入了适应性自旋锁,它可以动态地调整自旋等待的次数,以根据当前运行环境的负载情况来提高性能。
-
锁消除: 编译器对代码进行优化时,可以通过静态分析来判断某些锁不会被多个线程同时访问,从而将锁操作直接消除,减少同步的开销。
-
锁粗化: 锁粗化是将多个连续的同步操作合并为一个大的同步块,以减少同步的次数,提高性能。这样可以避免频繁地进入和退出同步块造成的开销。
-
分段锁: 在一些数据结构中,可以使用分段锁来代替全局锁,将数据分成多个段,每个段独立加锁,从而提高并发度,减小锁的争用。
这些优化技术并非独立的,往往在实际应用中会综合使用,根据具体的应用场景和性能需求选择合适的锁策略。锁优化是多线程编程中的一个重要方面,通过有效地使用这些技术,可以提高程序的并发性能。需要注意的是,过度的锁优化可能导致复杂性增加,因此在选择和应用锁优化技术时需要谨慎权衡。
我的其他博客
什么情况下会产生StackOverflowError(栈溢出)和OutOfMemoryError(堆溢出)怎么排查-CSDN博客
在多线程中sleep()和wait()的区别(详细)-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!