diffusers-load adapters
2023-12-18 06:28:10
一、DreamBooth(待补充)
二、Textual inversion(待补充)
三、Lora

from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")

pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora", weight_name="cereal_box_sdxl_v1.safetensors")
prompt = "bears, pizza bites"
image = pipeline(prompt).images[0]
image


from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
pipeline.unet.load_attn_procs("jbilcke-hf/sdxl-cinematic-1", weight_name="pytorch_lora_weights.safetensors")
# use cnmt in the prompt to trigger the LoRA
prompt = "A cute cnmt eating a slice of pizza, stunning color scheme, masterpiece, illustration"
image = pipeline(prompt).images[0]
image
注意区分load_lora_weights和unet.load_attn_procs的区别,这里我觉得还是推荐用load_lora_weights

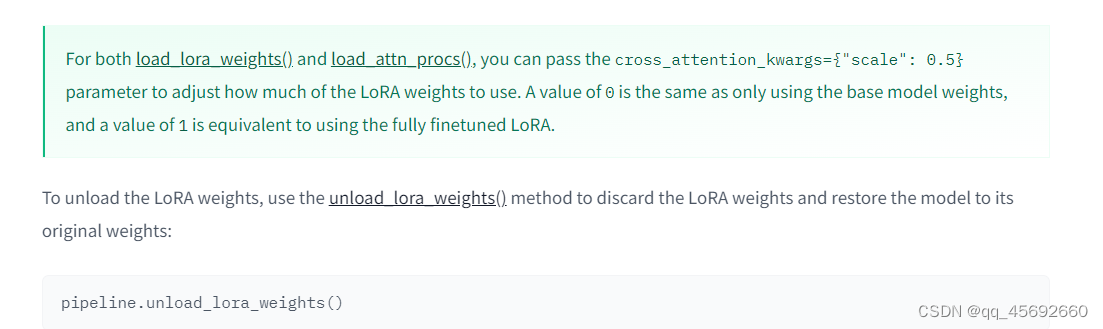
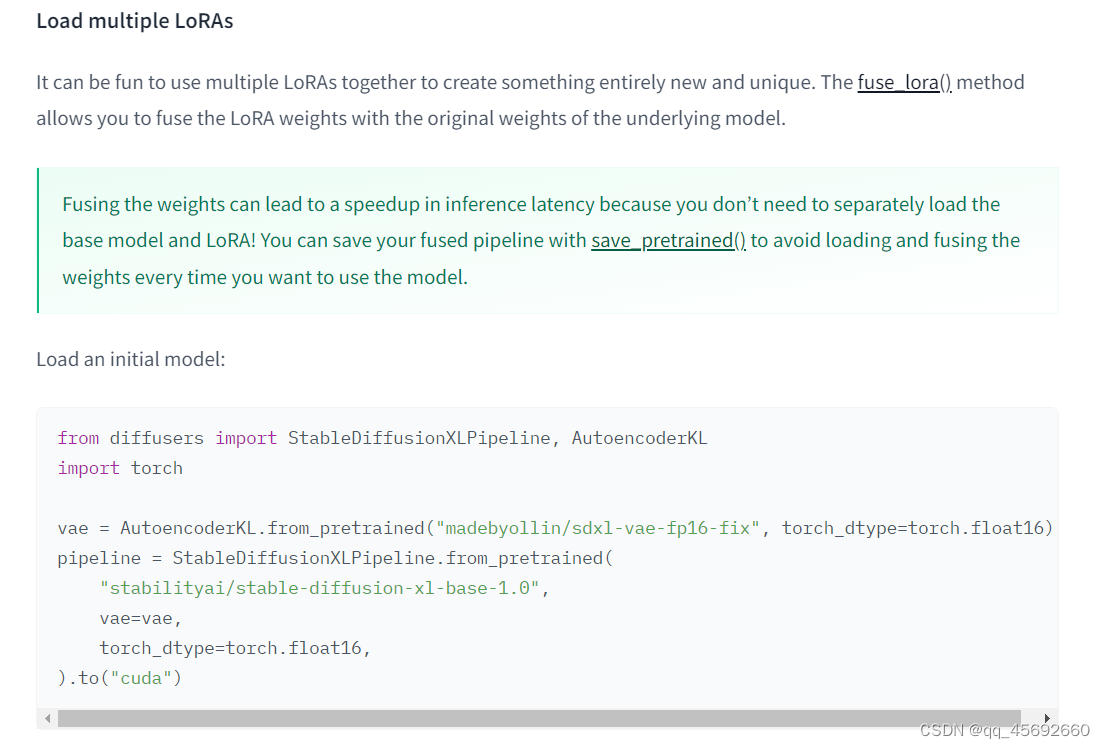

这里说的无法取消多个lora权重的融合,不是很理解,还需要继续去看diffuser的底层代码

from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora", weight_name="cereal_box_sdxl_v1.safetensors", adapter_name="cereal")
prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration"
image = pipeline(prompt, num_inference_steps=30, cross_attention_kwargs={"scale": 1.0}).images[0]
image
四、IP-Adapter(待补充)
文章来源:https://blog.csdn.net/qq_45692660/article/details/135052239
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!