什么是索引下推?
什么是索引下推
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,用于优化数据查询。
不使用索引条件下推优化时存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件。
当使用索引条件下推优化时,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。
索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
换句话说:索引下推能减少回表查询次数,提高查询效率。
索引下推优化的原理
我们先简单了解一下MySQL大概的架构:
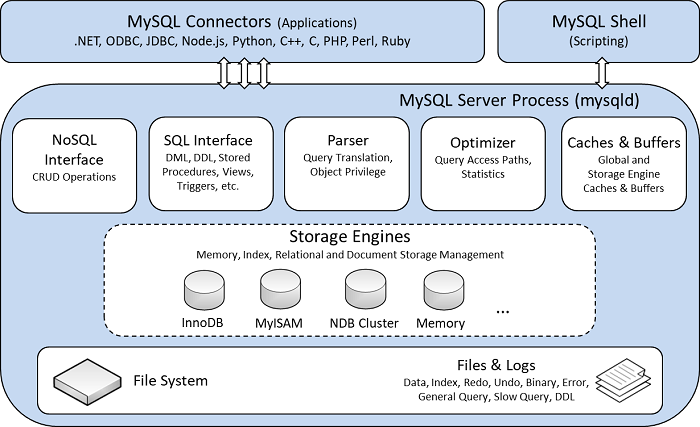
MySQL从上至下分为以下几层:
-
MySQL服务层:包括NoSQL和SQL接口、查询解析器、优化器、缓存和Buffer等组件。
-
存储引擎层:各种插件式的表格存储引擎,实现事务、索引等各种存储引擎相关的特性。
-
文件系统层: 读写物理文件。
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
我们来具体看一下,在没有使用ICP的情况下,MySQL的查询:
-
获取下一行,首先读取索引信息,然后根据索引将整行数据读取出来。
-
然后通过where条件判断当前数据是否符合条件,符合返回数据。
使用ICP的情况下,查询过程:
-
获取下一行的索引信息。
-
检查索引中存储的列信息是否符合索引条件,如果符合将整行数据读取出来,如果不符合跳过读取下一行。
-
用剩余的判断条件,判断此行数据是否符合要求,符合要求返回数据。
索引下推适用条件
?
-
需要整表扫描的情况。比如:range, ref, eq_ref, ref_or_null 。
-
适用于InnoDB 引擎和 MyISAM 引擎的查询。(5.6版本不适用分区表查询,5.7版本后可以用于分区表查询)。
-
对于InnDB引擎只适用于二级索引,因为InnDB的聚簇索引会将整行数据读到InnDB的缓冲区,这样一来索引条件下推的主要目的减少IO次数就失去了意义。因为数据已经在内存中了,不再需要去读取了。
-
引用子查询的条件不能下推。
-
调用存储过程的条件不能下推,存储引擎无法调用位于MySQL服务器中的存储过程。
-
触发条件不能下推。
EXPLAN分析
?
当使用explan进行分析时,如果使用了索引条件下推,Extra会显示Using index condition。并不是Using index。
因为并不能确定利用索引条件下推查询出的数据就是符合要求的数据,还需要通过其他的查询条件来判断。
索引下推的具体实践
理论比较抽象,我们来上一个实践。使用一张用户表tuser,表里创建联合索引(name, age)。

如果现在有一个需求:检索出表中名字第一个字是张,而且年龄是10岁的所有用户。那么,SQL语句是这么写的:
select * from tuser where name like '张%' and age=10;
假如你了解索引最左匹配原则,那么就知道这个语句在搜索索引树的时候,只能用 张,找到的第一个满足条件的记录id为1。

那接下来的步骤是什么呢?
没有使用ICP
在MySQL 5.6之前,存储引擎根据通过联合索引找到name likelike '张%' 的主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
我们看一下示意图:

可以看到需要回表两次,把我们联合索引的另一个字段age浪费了。
使用ICP
而MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到,由于联合索引中包含列,所以存储引擎直接再联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。
我们看一下示意图:

可以看到只回表了一次。
除此之外我们还可以看一下执行计划,看到Extra一列里 Using index condition,这就是用到了索引下推。
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | tuser | NULL | range | na_index | na_index | 102 | NULL | 2 | 25.00 | Using index condition |相关系统参数
索引条件下推默认是开启的,可以使用系统参数optimizer_switch来控制器是否开启。
查看默认状态:
切换状态:
set ="index_condition_pushdown=off";
set ="index_condition_pushdown=on";
思考
索引下推优化技术其实就是充分利用了索引中的数据,尽量在查询出整行数据之前过滤掉无效的数据。
由于需要存储引擎将索引中的数据与条件进行判断,所以这个技术是基于存储引擎的,只有特定引擎可以使用。并且判断条件需要是在存储引擎这个层面可以进行的操作才可以,比如调用存储过程的条件就不可以,因为存储引擎没有调用存储过程的能力。
参考:
1、《 MySQL技术内幕? InnoDB存储引擎》
2、《MySQL实战45讲》
更多精彩内容,关注我们▼▼

?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!